تحلیل مولفه های واریانس Variance Components با نرمافزار SPSS
Variance-Components
هنگامی که از یک مدل آنالیز واریانس و یا کوواریانس با اثرات تصادفی Random Effects و یا یک مدل آمیخته Mixed Model استفاده میکنیم، با مفهومی به نام مولفههای واریانس که به آن Variance Components گفته میشود، روبهرو میشویم. من در این مقاله قصد دارم به این موضوع و نحوهی به دست آوردن نتایج آن با استفاده از نرمافزار SPSS بپردازم.

Variance Components همانگونه که از نام آن برمیآید به بیان میزان پراکندگی و تنوعپذیری فاکتور(های) تصادفی موجود در مدل Random Factors و همچنین پراکندگی و واریانس خطای تصادفی Random Error در مدل تصادفی و یا مدل آمیخته، اشاره میکند.
به بیان سادهتر اینکه، همانگونه که میدانیم یک مدل تصادفی و یا آمیخته دارای دو نوع خطا میباشد. یک خطا، خطای اندازهگیری و براورد است که در همهی مدلهای آنالیز واریانس و یا کوواریانس (و در حالت کلیتر همهی مدلهای خطی) وجود دارد. ما به این خطا خطای تصادفی و یا Random Error میگوییم.
خطای دیگر به خطای انتخاب تصادفی گروههای Random Factor از جامعهی بزرگتر خود مربوط میشود. به یاد بیاورید که در یک مدل اثرات تصادفی و یا آمیخته، گروههای Independent Variable به صورت تصادفی از یک مجموعه بزرگتر انتخاب میشوند.
مفهوم مولفههای واریانس در همین جا خود را نشان میدهد. این مفهوم و اندازههای به دست آمده از آن بیان میکند که چه درصد و حجمی از واریانس و پراکندگی مدل مربوط به خطای تصادفی Random Error و چه درصدی مربوط به انتخاب تصادفی است.
از Variance Components برای ارزیابی اینکه چه مقدار از تنوعپذیری Variation مطالعه را میتوان به هر اثر (فاکتور) تصادفی نسبت داد، استفاده میکنیم. در هر فاکتور تصادفی، مقادیر عددی بالاتر Variance Components نشان میدهد که این فاکتور به بیان و برازش تنوع بیشتری در کمیت پاسخ Response کمک میکند.
مثال تحلیل مولفههای واریانس
Example
فرض کنید میخواهیم به بررسی عوامل اثرگزار بر میزان هزینه و خرید افراد مختلف از شعبههای مختلف یک فروشگاه در کل کشور بپردازیم. ما میخواهیم دریابیم چه فاکتورهایی بر هزینه پرداخت شده افراد، موثر است. در این مطالعه عواملی مانند مکان و اندازه فروشگاه، جنسیت افراد، نحوه خرید افراد، ارایه کوپنهای تخفیف و درآمد افراد خریدار، اندازهگیری شده و تاثیر آنها بر میزان خرید افراد مورد بررسی قرار گرفته است.
در تصویر زیر میتوانید بخشی از فایل دیتا این مثال را مشاهده کنید. از اینجا میتوانید دادهها و نتایج را دریافت کنید.
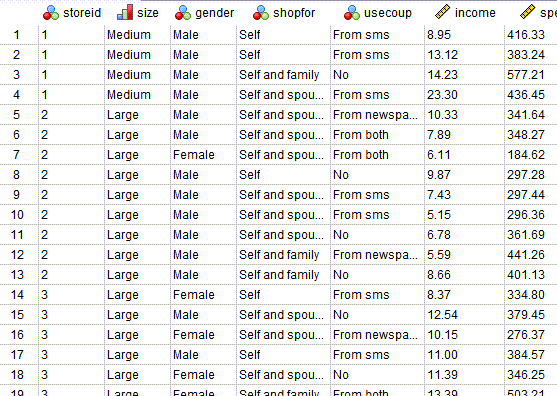
در این دادهها ستون با نام spent به عنوان پاسخ و کمیت وابسته مطالعه Dependent Variable به بیان میزان هزینه پرداختی و اندازه خرید فرد، میپردازد.
عوامل و فاکتورهای مورد بررسی در این مثال عبارتند از آی دی و کد مکان فروشگاه، اندازه و سایز فروشگاه در سه رده Medium, Small و Large، جنسیت فرد خریدار، نحوه خرید فرد (به تنهایی، همراه با همسر و یا همراه با خانواده)، نحوه دریافت کوپن تخفیف (بدون تخفیف، از طریق روزنامه، پیامک) و درآمد خانوار.
از آنجا که در این مطالعه هم فاکتورها با اثرات ثابت (جنسیت، سایز فروشگاه، نحوه خرید، کوپن تخفیف) و هم اثر تصادفی (مکان فروشگاه) وجود دارد به این مطالعه Mixed Model گفته میشود. وجود یک کووریت با نام درآمد خانوار میتواند این مطالعه را از نوع آنالیز کوواریانس آمیخته قرار دهد. در موضوع مدلهای آمیخته علاقمند بودید این لینک را در سایت گراف پد ببینید.
یک نکته اینکه، ما به مولفه مکان فروشگاه که در ستون با نام storeid یک فاکتور تصادفی میگوییم. دلیل این مطلب هم آن است که فروشگاهها و شعبههای قرار گرفته در این مطالعه، از جامعه بزرگ همهی تعداد فروشگاهها در کل کشور به تصادف انتخاب شده است. از آنجا که این فاکتور، نمونه تصادفی از یک کل است و از آن کل به تصادف انتخاب شده است، بنابراین نتایج به دست آمده بر مبنای این فاکتور را میتوانیم به آن مجموعه بزرگتر تعمیم دهیم. همانگونه که میدانیم Random Factor این قابلیت را دارد که به مجموعه بزرگتری که از آن میآید، گسترش یابد.
در این مقاله هدف ما تحلیل مولفههای واریانس و دریافتن این نکته است که فاکتور تصادفی مطالعه یعنی مکان فروشگاه چه درصد و حجمی از واریانس و پراکندگی کمیت پاسخ میزان هزینه را در بر دارد. در واقع میخواهیم دریابیم مکان فروشگاه تا چه حدی میتواند تنوع و تفاوت میزان خرید افراد از شعبههای مختلف فروشگاه را بیان کند. هنگامی که ما فاکتوری را به عنوان اثر تصادفی در نظر میگیریم، هر چقدر این عدد بزرگتر باشد، نشان میدهد که مکان فروشگاه تاثیرگزاری بیشتری بر میزان خرید افراد دارد و میتواند تنوعپذیری Variation بیشتری از خرید افراد را بیان کند.
به این نکته توجه کنید، هنگامی که میخواهیم در یک فروشگاه زنجیرهای مواد غذایی که دارای شعبههای مختلفی در سراسر کشور است، رابطه بین رفتار خرید مشتری و مقدار هزینه شده را بررسی کنیم، تنوع زیادی از یک شعبه به شعبه دیگر وجود دارد که توانایی و دقت ما را در برآورد اثرات رفتار خرید مشتری بر مقدار هزینه، کاهش میدهد. با افزودن مکان فروشگاه به عنوان یک اثر تصادفی، میتوانید میزان خطا و پراکندگی غیرقابل توضیح را کاهش دهید و در نتیجه دقت برآوردهای خود را از سایر اثرات موجود در مدل افزایش دهید.
نتایج تحلیل مولفههای واریانس
Results
حال بیایید به انجام تحلیل مولفههای واریانس، بپردازیم. از مسیر زیر در نرمافزار SPSS جهت تحلیل Variance Components، استفاده میکنیم.
Analyze → General Linear model → Variance Components
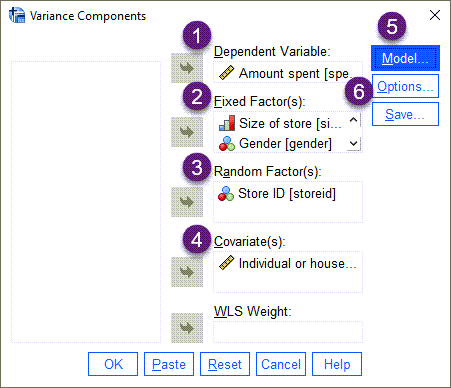
در این صورت پنجره زیر با نام Variance Components برای ما باز میشود.
من پنجره تنظیمات بالا را شمارهگزاری کردهام و به ترتیب به توضیح هر کدام میپردازم.
1 در کادر Dependent Variable که همان کمیت وابسته مطالعه است، ستون spent یعنی میزان هزینه پرداختی و خرید فرد، قرار میگیرد.
2 در کادر Fixed Factor(s) فاکتورهای دارای اثر ثابت یعنی سایز فروشگاه، جنسیت، نحوه خرید و کوپن تخفیف، قرار میگیرند.
3 در کادر Random Factor(s) فاکتور مکان فروشگاه یعنی Store ID که دارای اثر تصادفی بر پاسخ است، قرار گرفته است.
4 این مطالعه دارای یک کووریت یعنی میزان درآمد فرد نیز میباشد. به همین دلیل مولفه Income در کادر Covariate(s) قرار میگیرد.
5 حال وارد تب Model شوید. به این نکته توجه کنید که روش مولفههای واریانس بر اساس مدل خطی عمومی General Linear Model (GLM) است که در آن فاکتورها (اعم از ثابت و تصادفی) و همچنین کووریتها Covariates، در یک رابطه خطی با کمیت وابسته فرض میشوند. در این تب میتوانیم نحوه ورود فاکتورها به مدل خطی را مشخص کنیم. تصویر زیر را ببینید.
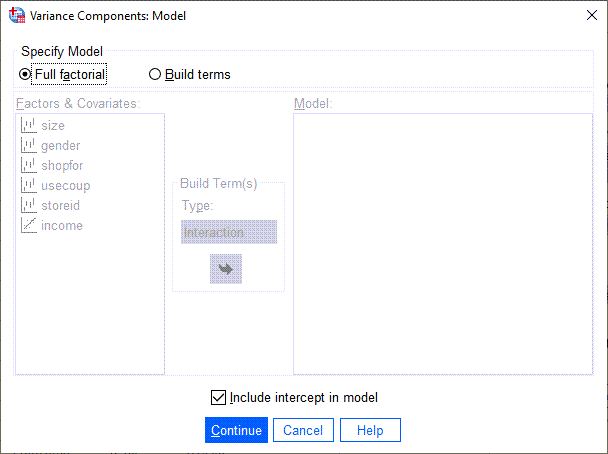
هنگامی که وارد تب Model میشویم، نرمافزار به صورت پیشفرض گزینه Full factorial را انتخاب کرده است. این گزینه به معنای این است که همهی اثرات اصلی Main Effects و اثرات متقابل Interaction Effects وارد مدل خطی میشوند. چنانچه بخواهیم مدل ما سادهتر باشد و فقط اثرات اصلی در آن وجود داشته باشد، گزینه Build terms را انتخاب میکنیم.
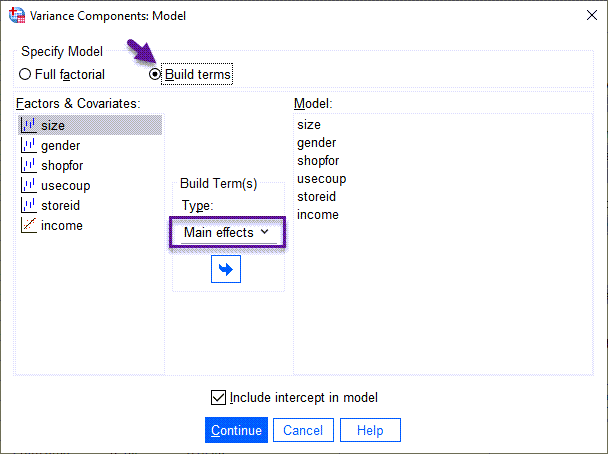
پس از آن از کادر Type در وسط صفحه، گزینهی Main effects را انتخاب کرده و کمیتهای موجود در مدل را از کادر Factors & Covariates به کادر Model انتقال میدهیم. Continue کرده تا دوباره به پنجره قبل بازگردیم.
6 حال وارد تب ![]() شوید . در این تب، متدها و روشهای براورد، که نرمافزار SPSS از آنها در تحلیل مولفههای واریانس استفاده میکند، قرار دارد. تصویر زیر را ببینید.
شوید . در این تب، متدها و روشهای براورد، که نرمافزار SPSS از آنها در تحلیل مولفههای واریانس استفاده میکند، قرار دارد. تصویر زیر را ببینید.
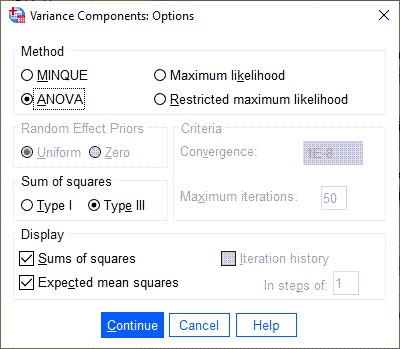
من در اینجا متد ANOVA را انتخاب کردهام. توضیح دربارهی اینکه هر کدام از متدها چیست و چگونه نتایج را به دست میآورد، توضیح مفصل است. علاقمند بودید به این لینک در سایت IBM مراجعه کنید. حال OK کنید. در ابتدا نتایج و خروجیهای نرمافزار آمده است.
در ابتدا جدول زیر با نام Factor Level Information مشاهده میشود. این یک جدول طولانی و البته توصیفی در این مثال است. من بخشی از این جدول را در تصویر زیر آوردهام.
با استفاده از نتایج این جدول میتوانیم سطوح و گروههای مختلف هر کدام از اثرات ثابت و تصادفی مطالعه را مشاهده کنیم. همانگونه که گفتم، این یک جدول توصیفی است.
در ادامه نتایج جدول ANOVA آمده است. در تصویر زیر آن را میبینید.
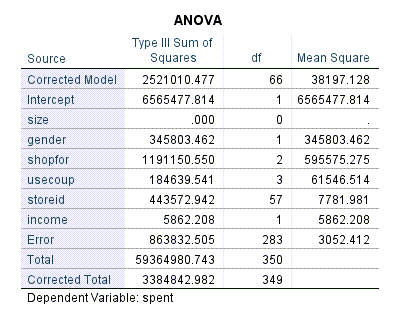
جدول ANOVA میانگین مربعات مشاهده شده Observed Mean Squares به ازای فاکتورهای ثابت و تصادفی را نشان میدهد. جالب توجه است که در این جدول مقادیر احتمال و آزمونهای معناداری به دست نیامده است. از آنجا که ما در این مقاله صرفاً به موضوع Variance Components میپردازیم و تحلیل واریانس مدنظر ما نیست، عدم وجود مقادیر احتمال جهت بررسی معناداری فاکتورها، برای ما اهمیتی ندارد.
همچنین در جدول زیر مجموع مربعات مورد انتظار که از آنها جهت براورد مولفههای واریانس استفاده میشود، به دست آمده است.
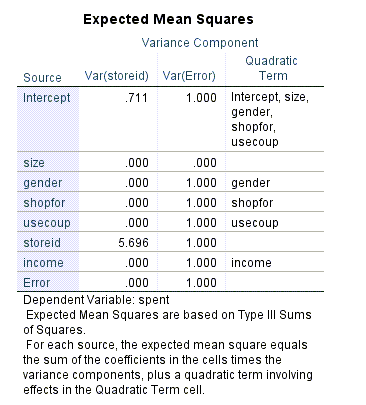
این جدول نتایجی دربارهی میانگین مربعات مورد انتظار را نشان میدهد. در این مثال، میانگین مربعات مورد انتظار برای storeid به صورت زیر است.
$ \displaystyle \begin{array}{l}EMS\left( {storeid} \right)=5.696\times Var\left( {storeid} \right)+Var\left( {Error} \right)\\\\EMS\left( {Error} \right)=Var\left( {Error} \right)\end{array}$
از جدول ANOVA میدانیم که میانگین مربعات مشاهده شده برای storeid عبارت است از 7781.98 و به همین ترتیب میانگین مربعات مشاهده شده برای عبارت خطا برابر با 3052.41 است.
در ادامه نتایج و خروجیهای نرمافزار SPSS جدول Variance Estimates که ما در این مقاله به دنبال براورد پارامترهای آن بودیم، به دست آمده است.

برای به دست آوردن براوردهای واریانس نمایش داده شده در جدول بالا، کافی است میانگین مربعات مشاهده شده را با میانگین مربعات مورد انتظار برابر قرار داده و سپس واریانس را به دست آورید. به معادلات زیر دقت کنید.
$ \displaystyle \begin{array}{l}EMS\left( {storeid} \right)=7781.98=5.696\times Var\left( {storeid} \right)+Var\left( {Error} \right)\\\\EMS\left( {Error} \right)=3052.41=Var\left( {Error} \right)\end{array}$
حل کردن این معادله نشان میدهد $ \displaystyle Var\left( {Error} \right)=3052.41$ و $ \displaystyle Var\left( {storeid} \right)=830.26$ خواهد بود. این اعداد همان نتایجی است که در جدول Variance Estimates دیده میشود.
خب حال بیایید به موضوع اصلی این مقاله یعنی به دست آوردن مقدار تنوعپذیری Variation مطالعه مبتنی بر اثر تصادفی مکان فروشگاه، بپردازیم.
قبلاً و در ابتدای متن بیان کردیم که براورد مولفههای واریانس نشان میدهد چه درصد و حجمی از واریانس و پراکندگی مدل مربوط به خطای تصادفی Random Error و چه درصدی مربوط به انتخاب تصادفی است.
پاسخ به این سوال در جدول Variance Estimates که براوردهای واریانس را برای هر یک از مولفههای واریانس نمایش میدهد، قرار دارد. از نتایج این جدول میتوانید به منظور مشخص کردن میزان دربردارندگی هر جز یعنی خطای تصادفی Random Error و انتخاب تصادفی (مربوط به اثر تصادفی، در این مثال مکان فروشگاه، در کل واریانس استفاده کنید.
در این مثال $ \displaystyle Var\left( {Error} \right)=3052.41$ و $ \displaystyle Var\left( {storeid} \right)=830.26$ به دست آمده است.
بنابراین، اثر تصادفی مکان فروشگاه (830.26+3052.41) / 830.26 = 21.38 درصد از واریانس و پراکندگی مطالعه را توضیح میدهد. بقیه پراکندگی و تنوعپذیری یعنی 78.62 درصد، به خطای تصادفی تعلق دارد.
این نتیجه نشان میدهد در حالی که اثر تصادفی مکان فروشگاه، حدود 21 درصد از پراکندگی تصادفی Random Variation هزینه پرداخت شده توسط مشتریان را به خود اختصاص میدهد، بیشتر پراکندگی به دلیل خطای تصادفی Random Error است. در نهایت به دست آوردیم که با افزودن مکان فروشگاه به عنوان یک اثر تصادفی، میتوانیم میزان خطا و پراکندگی غیرقابل توضیح یعنی همان خطای تصادفی را کاهش دهیم و در نتیجه دقت برآوردهای خود از سایر اثرات موجود در مدل را افزایش دهیم.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2024). Analysis of variance components with SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/variance-components-spss/.php
For example, if you viewed this guide on 12th January 2024, you would use the following reference
GraphPad Statistics (2024). Analysis of variance components with SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2024, from https://graphpad.ir/variance-components-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.