آزمون ناپارامتری علامت Sign Test در نرمافزار SPSS
Sign Test
آزمون ناپارامتری علامت نمونههای جفتی Paired-Samples Sign Test که به اختصار به آن آزمون علامت Sign Test گفته میشود، کاربردی همانند آزمون ناپارامتری رتبه علامت دار ویلکاکسون دارد و معادل آزمون پارامتری تی وابسته Dependent T-Test است. از آنجایی که این آزمون نرمال بودن دادهها را در نظر نمیگیرد، هنگامی میتوان از آن استفاده کرد که این فرض نقض شده باشد و استفاده از آزمون t وابسته نامناسب باشد.

همانند آزمون ویلکاکسون از آزمون علامت نیز برای مقایسه میانه دو مجموعه از نمرات که از یک شرکت کننده به دست میآیند میتوان استفاده کرد. یا هنگامی که بخواهیم اختلاف اندازهها از یک نقطه زمانی به نقطه زمانی دیگر را بررسی کنیم. با این حال یک تفاوت در کاربرد آزمون ویلکاکسون یا علامت وجود دارد.
نکته. به هنگام بیان پیشفرضهای آزمون ویلکاکسون گفتیم که توزیع اختلافها بین دو گروه مرتبط باید به شکل متقارن Symmetrical باشد. موضوعی که در آزمون علامت وجود دارد این است که این آزمون حتی بدون متقارن بودن توزیع دادههای اختلاف بین گروههای مرتبط نیز به خوبی کار میکند.
مثلاً میتوانید از آزمون Sign برای درک اینکه آیا تفاوتی در میانه مصرف روزانه سیگار افراد، قبل و بعد از یک برنامه هیپنوتیزم درمانی ۶ هفتهای وجود دارد یا خیر، استفاده کرد. در این مثال کمیت وابسته «مصرف روزانه سیگار» و کمیت مستقل گروههای مرتبط، «قبل» و «بعد از» برنامه هیپنوتیزم درمانی هستند.
همانگونه که میدانیم انجام هر آزمون و تحلیل آماری نیاز به برقراری تعدادی پیش فرض و چارچوبهای آنالیز دارد. بنابراین در ابتدا مناسب است دربارهی این موضوع صحبت کنیم.
پیش فرضهای آزمون علامت
Assumptions
قبل از اینکه بخواهیم دربارهی انجام آزمون علامت در نرمافزار SPSS صحبت کنیم، پیش فرضهای مختلفی را توضیح میدهیم که لازم است دادههای شما با آنها مطابقت داشته باشند تا Sign Test نتیجه معتبری به شما بدهد. این پیش فرضها به صورت زیر هستند.
- پیش فرض (1)
کمیت وابسته شما باید در مقیاس ترتیبی یا پیوسته اندازهگیری شود. نمونههایی از کمیتهای ترتیبی شامل طیف لیکرت (مثلاً مقیاس 5 گزینهای از کاملاً موافقم تا کاملاً مخالفم). نمونههایی از کمیتهای پیوسته عبارتند از زمان (اندازهگیری شده بر حسب ساعت)، هوش (اندازهگیری شده با استفاده از نمره IQ)، عملکرد در یک آزمون (از 0 تا 100)، وزن (بر حسب کیلوگرم).
- پیش فرض (2)
کمیت مستقل شما باید از دو دسته، “گروههای مرتبط Related Groups” یا “جفتهای همسان Matched Pairs” تشکیل شده باشد. گروههای مرتبط نشان میدهد که در هر دو گروه افراد مشابهی وجود دارد. دلیل اینکه امکان وجود موضوعات یکسان در هر گروه وجود دارد این است که هر موضوع در دو بار روی کمیت وابسته اندازهگیری شده است.
به عنوان مثال، ممکن است عملکرد 10 نفر را در آزمون املا (کمیت وابسته) قبل و بعد از اینکه آنها تحت یک روش آموزشی کامپیوتری برای بهبود املا قرار گرفتند، اندازهگیری کرده باشید. دوست دارید بدانید که آیا آموزش کامپیوتر عملکرد املایی آنها را بهبود میبخشد؟ گروه مرتبط اول شامل نمرات املا افراد (قبل از) آموزش کامپیوتری و گروه دوم مرتبط از همان افراد، اما اکنون در پایان آموزش کامپیوتری است.
آزمون علامت همچنین در مواردی که همه افراد تحت دو شرایط متفاوت قرار میگیرند، استفاده میشود. این شرایط معمولاً مداخله، درمان یا کارآزمایی نامیده میشوند. به عنوان مثال، 30 شرکتکننده تحت یک برنامه هیپنوتیزم درمانی (شرایط A) و برنامه دارویی (شرایط B) قرار میگیرند تا مشخص کنند کدامیک در درمان افسردگی موثرتر است.
- پیش فرض (3)
مشاهدات زوجی برای هر فرد باید از فرد دیگر مستقل باشد. یعنی اندازههای به دست آمده یک شرکت کننده، نمیتواند بر اندازههای شرکت کننده دیگر تاثیر بگذارد.
- پیش فرض (4)
توزیع اختلافها بین دو گروه مرتبط، کافی است پیوسته Continuous Distribution باشد.
مثال آزمون علامت Sign Test
Example
محققی میخواهد فرمول جدیدی را برای یک نوع نوشیدنی ورزشی که عملکرد دویدن را بهبود میدهد، آزمایش کند. به جای یک نوشیدنی معمولی و فقط کربوهیدراتی، این نوشیدنی ورزشی جدید حاوی یک مخلوط جدید کربوهیدرات و پروتئین است. محقق میخواهد بداند که آیا این نوشیدنی جدید کربوهیدرات-پروتئین منجر به تفاوت در عملکرد دویدن در مقایسه با نوشیدنی ورزشی فقط کربوهیدراتی میشود یا خیر.
برای انجام این کار، محقق 20 شرکتکننده را انتخاب کرد که هر کدام دو آزمایش را انجام دادند که در آنها باید تا حد امکان روی تردمیل بدوند. در یکی از آزمایشها، آنها نوشیدنی حاوی کربوهیدرات و در آزمایش دیگر نوشیدنی حاوی پروتئین کربوهیدرات را مصرف کردند. همچنین مسافتی که در هر دو آزمایش دویدند ثبت شد.
در تصویر زیر میتوانید بخشی از دادهها را مشاهده کنید. فایل این مثال را از اینجا Sign Test دریافت کنید.
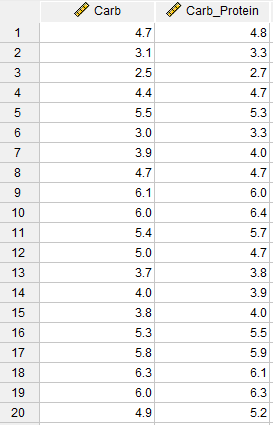
در دادههای بالا میزان دویدن افراد با نوشیدن کربوهیدرات در ستون با نام Carb و میزان دویدن افراد با نوشیدن کربوهیدرات_پروتئین در ستون Carb_Protein آمده است. محقق میخواهد تعیین کند که آیا تفاوتی در مسافت دویدن بین دو آزمایش و به عبارت دیگر تفاوت عملکردی بین دو نوشیدنی ورزشی وجود دارد یا خیر. از نظر آماری، محقق میخواهد بداند که آیا میانه تفاوت بین امتیازات کربوهیدرات و کربوهیدرات_پروتئین 0 (صفر) است یا خیر.
هنگامی که میخواهیم با نرم افزار SPSS تحلیل ناپارامتری علامت را انجام دهیم لازم است دادهها را در دو ستون کنار هم بنویسیم.
خب حال موضوعی که وجود دارد و من در پیش فرض شماره (4) به آن پرداختم، این است که توزیع اختلاف بین گروهها، پیوسته Continuous Distribution باشد. این مطلب به سادگی و با به دست آوردن اختلافها دیده میشود.
میتوانیم با استفاده از مسیر زیر، اختلافها را محاسبه میکنیم و در یک ستون جدید قرار میدهیم.
Transform → Compute Variable
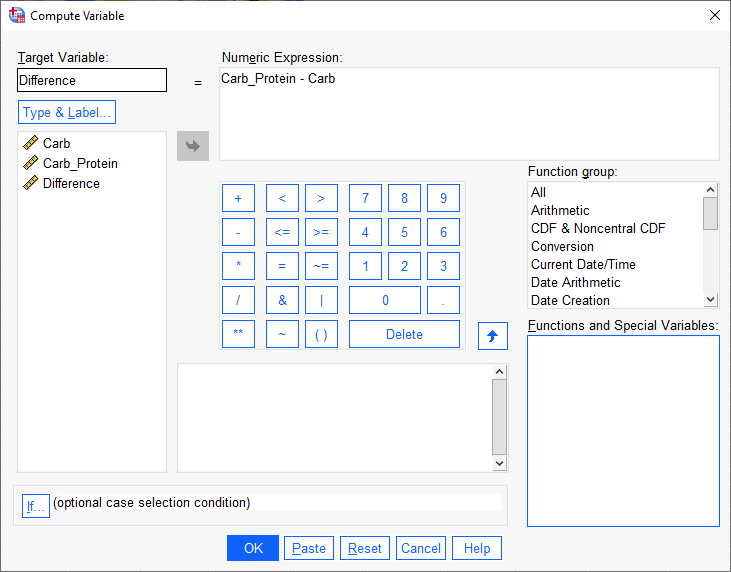
با انجام این کار یک ستون جدید با نام Difference به فایل دیتا اضافه شده است. این ستون بیانگر اندازه عددی اختلاف بین دادههای دویدن با کربوهیدرات و کربوهیدرات-پروتئین است.
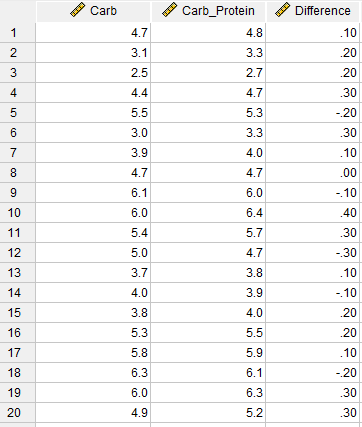
در مرحله بعد لازم است به بررسی پیوسته بودن توزیع در دادههای ستون Difference بپردازیم. مشاهده دادههای این ستون نشاندهنده پیوسته بودن اعداد است. با این حال میتوانیم، هیستوگرام دادهها را نیز رسم کنید. در لینک (رسم هیستوگرام Histogram با نرمافزار SPSS) میتوانید آموزش رسم هیستوگرام را مشاهده کنید.
من در شکل زیر هیستوگرام اختلاف دادههای دویدن با کربوهیدرات و کربوهیدرات-پروتئین را رسم کردهام.
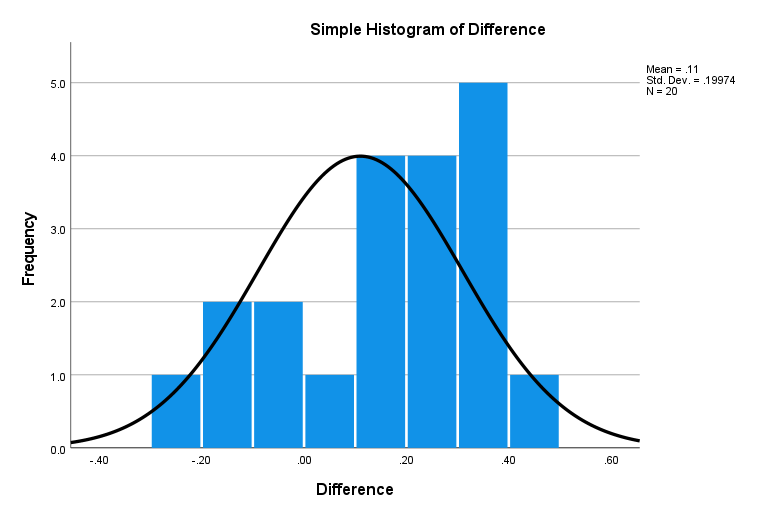
دادههای اختلاف به صورت پیوسته در رنجی از 0.1- تا 0.4+ قرار گرفتهاند. این هیستوگرام و دادههای مربوط به آن، مثال خوبی است که در اینجا آزمون ویلکاکسون مفید نیست (به دلیل عدم متقارن بودن توزیع دادهها) و در نتیجه بنابراین میگوییم که بهتر است از Sign Test جهت مقایسه میانه دادههای میزان دویدن با کربوهیدرات و کربوهیدرات-پروتئین، استفاده کنیم.
جهت انجام تحلیل ناپارامتری آزمون علامت دو مسیر و رویه جداگانه در نرمافزار SPSS وجود دارد. من در ادامه هر یک را توضیح میدهم.

Analyze → Nonparametric Tests → Legacy Dialogs → 2 Related Samples
با استفاده از مسیر بالا، پنجره زیر با نام Two-Related-Samples Tests برای ما باز میشود.
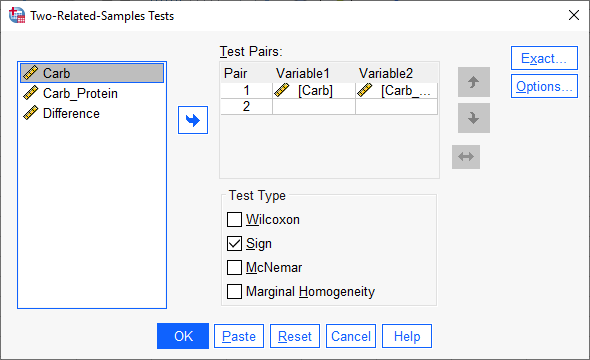
در این پنجره که مربوط به تنظیمات آزمونهای ناپارامتری دو نمونه وابسته در نرمافزار SPSS است، دادههای نوشیدنی کربوهیدرات و نوشیدنی کربوهیدرات-پروتئین در کادر Test Pairs قرار میگیرند. در کادر Test Type نیز گزینه Sign انتخاب شده است.
چنانچه علاقمند باشیم برخی از آمارههای توصیفی نیز برای ما ارایه شود، میتوانیم از دکمه ![]() وارد پنجره زیر شویم و گزینههای Descriptive و Quartiles را انتخاب کنیم.
وارد پنجره زیر شویم و گزینههای Descriptive و Quartiles را انتخاب کنیم.
خب، حال OK کنید و در ادامه نتایج و خروجیهای نرمافزار SPSS که با استفاده از مسیر بالا به انجام آزمون علامت پرداختیم را مشاهده کنید.
نتایج آزمون علامت
Results
در پنجره Output میتوانید خروجیهای آزمون ناپارامتری Sign Test را ببینید.
در ابتدای نتایج، جدول Descriptive Statistics آمده است. در تصویر زیر آن را میبینید.

آمارههای توصیفی این جدول به تفکیک دادههای دویدن با کربوهیدرات و کربوهیدرات-پروتئین به دست آمده است. به عنوان مثال جدول بالا نشان میدهد میانگین و انحراف معیار دویدن با کربوهیدرات به ترتیب برابر با 4.70 و 1.12 است. همین آمارهها برای دویدن با کربوهیدرات-پروتئین 4.81 و 1.10 به دست آمده است.
جدول بعدی در خروجیهای نرمافزار، با نام Ranks Table قرار دارد. در تصویر زیر آن را ببینید.
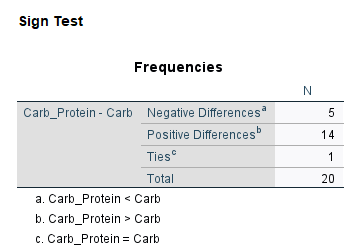
جدول بالا که از آن با نام جدول رتبهها Ranks Table یاد میشود، میانگین رتبه Mean Ranks و مجموع رتبهها Sum of Ranks را برای رتبههای منفی و مثبت را نشان میدهد. توضیح اینکه رتبه منفی به مواردی گفته میشود که میزان دویدن با نوشیدنی کربوهیدرات بیشتر باشد. در 5 فرد این اتفاق افتاده است. رتبه مثبت نیز به مواردی گفته میشود که دویدن با نوشیدنی کربوهیدرات-پروتئین بیشتر باشد. در 14 فرد این اتفاق افتاده است. برای 1 نفر نیز نتایج یکسان بوده است.
شاید برای شما این سوال پیش بیاید که منظور از رتبهها و میانگین و مجموع آنها چیست؟
من پاسخ به این سوال را به صورت کامل در کتاب روشهای پیشرفته آماری و کاربردهای آن دادهام. علاقمند بودید به فصل دهم این کتاب مراجعه کنید.
در نهایت در خروجیهای نرمافزار جدول دیگری با نام Test Statistics دیده میشود.

در این جدول میتوانیم به فرضیه برابر بودن میانه اندازه دویدن با کربوهیدرات و کربوهیدرات-پروتئین پاسخ دهیم.
نتیجه جدول بالا (در سطح معناداری پنج درصد) نشاندهنده عدم اختلاف معنادار میانه دویدن با کربوهیدرات و کربوهیدرات-پروتئین است (P-value = 0.064) به این ترتیب نتیجه میگیریم که استفاده از نوشیدنی شامل پروتئین، تاثیر معناداری بر افزایش میزان دویدن افراد مورد مطالعه نداشته است.
خب، حال بیایید از مسیر دیگری به بیان تحلیل ناپارامتری علامت بپردازیم. این مسیر در ورژنهای جدید نرمافزار SPSS قرار داده شده است و به نظر دارای نتایج و خروجیهای بیشتری است.

Analyze → Nonparametric Tests → Related Samples
هنگامی که از مسیر بالا جهت انجام آزمونهای ناپارامتری در نمونههای وابسته استفاده میکنیم، پنجره زیر با نام Nonparametric Tests Two or More Related Samples برای ما باز میشود. در تصویر زیر آن را ببینید.
ما با استفاده از این مسیر و پنجره تنظیمات بالا، نه فقط میتوانیم آزمون علامت که به بررسی دو گروه وابسته به یکدیگر میپردازد را انجام دهیم، بلکه قادر هستیم که آزمونهای ناپارامتری دارای بیشتر از دو گروه وابسته را نیز انجام دهیم. در ادامه به توضیح هر کدام از بخشها و تبهای این پنجره میپردازیم.
در این تب دو گزینه وجود دارد. انتخاب هر کدام به شما اجازه میدهد که هدف از آزمون ناپارامتری خود را مشخص کنید.
- Automatically compare observed data to hypothesized
با انتخاب این گزینه به نرمافزار اجازه میدهیم، بر مبنای نوع دادهها و تعداد گروههای وابسته، آزمون مناسب را انتخاب کند. بر این مبنا نرمافزار، آزمونهای McNemar’s, Cochran’s Q, Wilcoxon matched-pair Signed-Rank و Friedman’s 2-way ANOVA را انجام میدهد. معمولاً به صورت پیشفرض همین گزینه را میپذیریم.
- Customize analysis
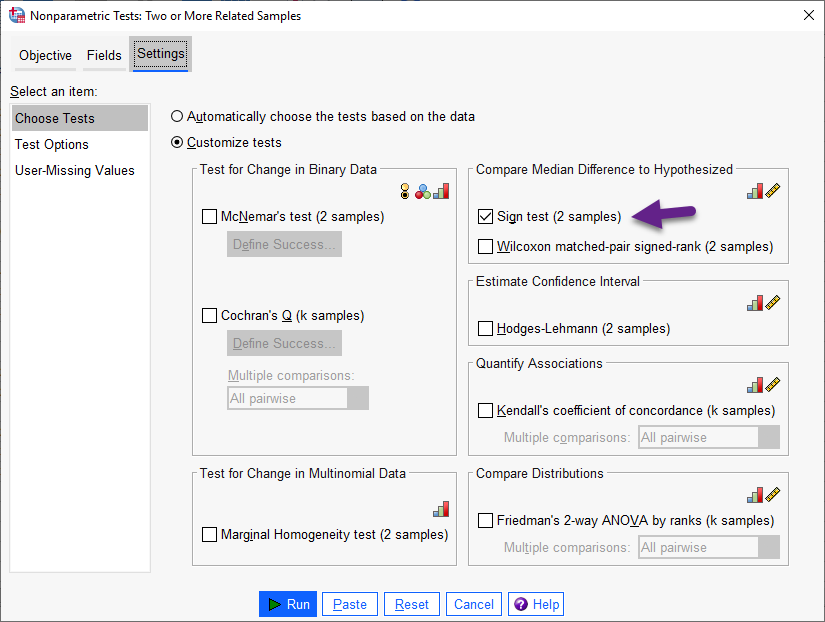
هنگامی که میخواهید تنظیمات آزمون را به صورت دستی در تب Settings اصلاح کنید، این گزینه را انتخاب کنید. انتخاب این گزینه به شما امکان میدهد تا کنترل دقیقی بر آزمونهای انجام شده و گزینههای آنها داشته باشید. سایر آزمونهای ناپارامتری موجود در برگه تنظیمات عبارتند از Sign test، Marginal Homogeneity، و یک فاصله اطمینان (براورد Hodges-Lehmann) نیز برای نمونههای با دو گروه موجود است. همه این موارد را میتوانید در تب Settings مشاهده کنید.
Fieldsبا استفاده از گزینههای این تب، کمیتهای وابسته را وارد نرمافزار میکنیم.
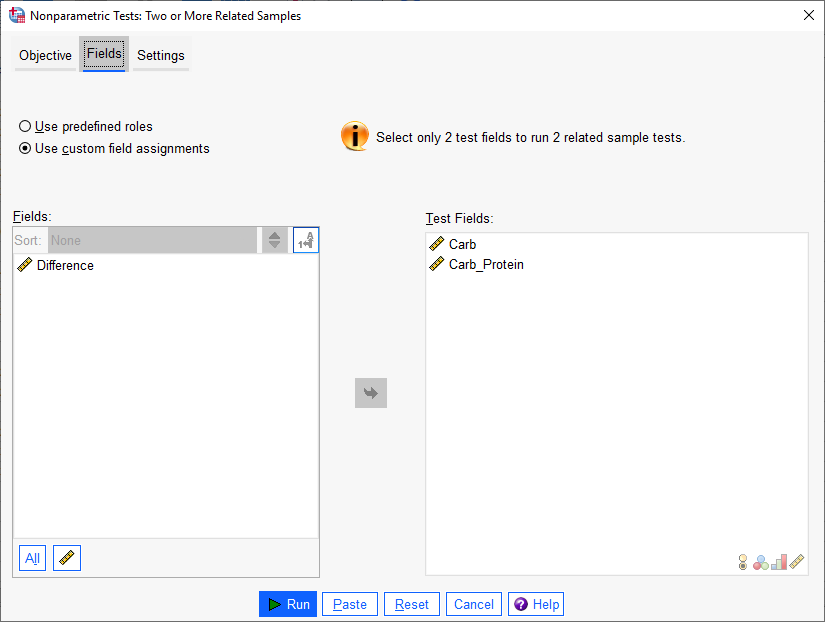
در کادر Test Fields اندازه دویدن با کربوهیدرات و کربوهیدرات-پروتئین، قرار میگیرد.
Settingsدر این تب میتوانیم انواع آزمونهای ناپارامتری قابل انجام برای نمونههای وابسته را مشاهده کنیم. هنگامی که در تب Objective گزینه Automatically compare observed data to hypothesized را انتخاب میکنیم، در تب Settings نیز به صورت پیشفرض گزینه Automatically choose the tests based on the data فعال است.
همانگونه که قبلاً نیز گفتیم، انتخاب این گزینه سبب میشود که نرمافزار به صورت خودکار و بر مبنای نوع و تعداد گروههای وابسته، آزمون آماری ناپارامتری مناسب دادهها را برای ما انجام دهد.
با این حال انتخاب گزینه Customize tests باعث میشود، به دلخواه بتوانیم آزمون ناپارامتری مورد علاقه خود را انجام دهیم. در تصویر زیر این آزمونها را ببینید.
در تصویر بالا، من Sign Test را مشخص و انتخاب کردهام. هنگامی که Run میکنیم نتایج زیر به دست میآید.
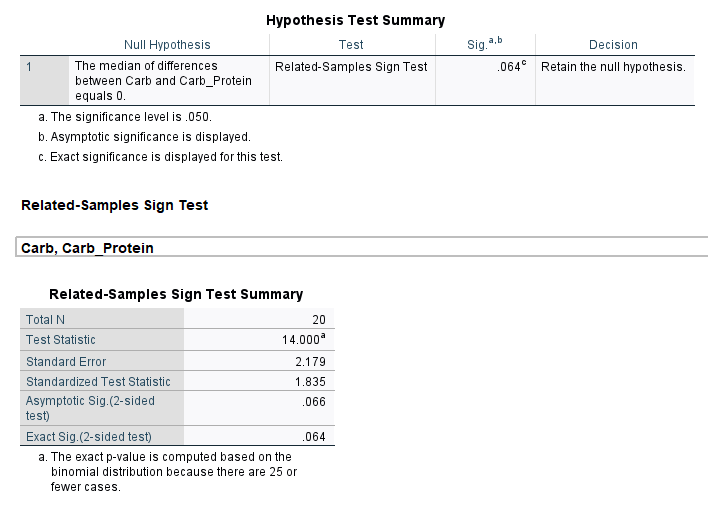
فرض صفر در این آزمون برابر بودن میانه دویدن با کربوهیدرات و کربوهیدرات-پروتئین است. نتیجه به دست آمده بیانگر عدم اختلاف معنادار بین میانه دویدن است (P-value = 0.064).
در گراف زیر نمودار فراوانی رتبههای منفی و مثبت، به دست آمده است.
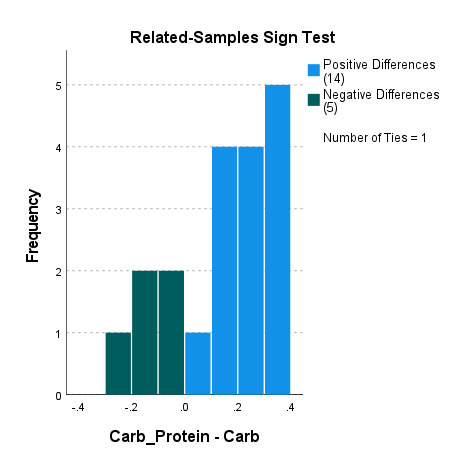
همانگونه که قبلاً بیان کردیم رتبه منفی به مواردی گفته میشود که میزان دویدن با نوشیدنی کربوهیدرات بیشتر باشد. در 5 فرد این اتفاق افتاده است. رتبه مثبت نیز به مواردی گفته میشود که دویدن با نوشیدنی کربوهیدرات-پروتئین بیشتر باشد. در 14 فرد این اتفاق افتاده است. برای 1 نفر نیز نتایج یکسان بوده است.
در همان تب Settings و از بخش Test Options میتوانیم به دلخواه خود سطح معناداری و فواصل اطمینان را قرار دهیم. نرمافزار SPSS به صورت پیشفرض این اعداد را به ترتیب 0.05 و 95.0 درصد قرار داده است.

چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2023). Non-parametric Sign Test in SPSS Software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/sign-test-spss/.php
For example, if you viewed this guide on 12th January 2023, you would use the following reference
GraphPad Statistics (2023). Non-parametric Sign Test in SPSS Software. Statistical tutorials and software guides. Retrieved January, 12, 2023, from https://graphpad.ir/sign-test-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.