رگرسیون لجستیک باینری Binary Logistic Regression در نرمافزار SPSS
حتماً تا به حال با مواردی مواجه شدهاید که میخواهید تاثیر یک یا چند عامل را بر روی کمیتی که دو حالتی است و تنها دو مقدار میپذیرد، (مثلاً بله یا خیر، مثبت یا منفی) بررسی کنید. به عنوان مثال یک محقق میخواهد به چگونگی تاثیر ورزش بر درمان ضایعات استخوان افراد سالمند، بپردازد.
او میتواند جهت انجام این تحقیق دو گروه از افراد را که یک گروه ضایعات استخوان آنها با انجام تمرینات ورزشی بهبود یافته و گروهی که با وجود انجام تمرینات ورزشی بهبودی حاصل نشده، در نظر بگیرد. سپس با بررسی مولفههای مختلف مانند مدت زمان ورزش، نوع فعالیت ورزشی، سن و جنسیت فرد مورد بررسی، مکان و محل انجام فعالیت، سابقه بیماری، نوع و میزان تغذیه روزانه و …. تاثیر هر کدام از این عوامل را بر روی بهبودی ضایعات استخوان بسنجد.

به این ترتیب کمیت پاسخ ما به صورت دو حالتی حاصل نشدن بهبودی و یا ایجاد بهبودی، تعریف میشود. در اینصورت ارتباط میان کمیت دو حالتی و مولفههای مستقلی که در بالا از آنها نام بردیم، با استفاده از یک مدل رگرسیون به نام رگرسیون لجستیک باینری Binary Logistic Regression (BLR)، برقرار میشود. در این مطالعات ما به کمیت دو حالتی، کمیت وابسته Dependent Variable (DV) که با کدهای صفر و یک نشان داده میشود و به کمیتهای مستقل، Independent Variable (IV) میگوییم.
در واقع دو هدف اصلی در یک مدل رگرسیون لجستیک باینری، مورد نظر است.
-
- چگونگی رابطه و میزان تاثیر کمیتهای مستقل یعنی Xها را بر روی کمیت وابسته Y مطالعه میکنیم.
- با در اختیار داشتن Xها، بتوانیم به پیشبینی احتمال وقوع کمیت وابسته پردازیم.
- فرض صفر. معادله و مدل رگرسیونی ایجاد شده مناسب است.
- فرض مقابل. معادله و مدل رگرسیونی ایجاد شده مناسب نیست.
- Classification Table
- Variables in the Equation
- Casewise List
چنانچه علاقمند هستید، مطالب بیشتری دربارهی رگرسیون لجستیک و تئوریهای آن بدانید، به شما پیشنهاد کتاب روشهای پیشرفته آماری و کاربردهای آن – فصل نهم را میدهم. من در این مقاله به دنبال آموزش رگرسیون لجستیک آن هم از نوع باینری یعنی هنگامی که کمیت وابسته فقط دارای دو حالت صفر و یک است، میباشم. این کار را با استفاده از نرمافزار SPSS انجام میدهیم. بنابراین از بیان مطالب نظری صرفنظر میکنم و به مباحث کار با نرمافزار میپردازم.
مدل آماری رگرسیون لجستیک باینری به صورت زیر است.
$ \displaystyle \ln \left( {\frac{p}{{1-p}}} \right)={{b}_{0}}+{{b}_{1}}{{x}_{1}}+{{b}_{2}}{{x}_{2}}+….+{{b}_{k}}{{x}_{k}}$
توضیح این مطلب که مدل چگونه به دست میآید را میتوانید به تفصیل در همان کتاب روشهای پیشرفته آماری و فصل نهم آن مشاهده کنید.
در این مدل P همان احتمال رخدادن کمیت وابسته است. بنابراین آن چیزی که در رگرسیون لجستیک مورد پیشبینی قرار میگیرد، از جنس احتمال Probability است. در واقع ما با استفاده از X ها میتوانیم رابطه بین رخدادن یک پیشامد با همان X ها و همچنین احتمال وقوع آن را به دست بیاوریم.
رابطه بالا را میتوانیم به صورت زیر بنویسید.
$ \displaystyle p=\frac{{\exp \left\{ {{{b}_{0}}+\sum\limits_{{i=1}}^{k}{{{{b}_{i}}{{x}_{i}}}}} \right\}}}{{1+\exp \left\{ {{{b}_{0}}+\sum\limits_{{i=1}}^{k}{{{{b}_{i}}{{x}_{i}}}}} \right\}}},\begin{array}{*{20}{c}} {} & {0\le p\le 1} \end{array}$
مدل بالا با نام رگرسیون لجستیک باینری یاد میشود و به خوبی میتواند تاثیر هر یک از X ها را بر شانس وقوع کمیت پاسخ اندازه بگیرد و تاثیر معنادار یا غیرمعنادار آنها را ارزیابی کند. البته در این زمینه بحثهای تئوری زیادی وجود دارد که همانگونه که گفتم ما از آنها صرفنظر میکنیم. برای فهم کاملتر این مدل از مثال زیر استفاده میکنیم. این مثال به شما کمک خواهد کرد تا بتوانید مدلهای رگرسیون لجستیک را شناخته و نتایج حاصل از آن را بیان کنید.
مثال رگرسیون لجستیکExample
به منظور بررسی برخی از عوامل محیطی تاثیرگذار در بروز بیماریهای ریوی از قبیل فیبروز، آسم، سل ریوی و یا سرطان ریه، یک بررسی بر روی 37 بیمار و 63 فرد سالم انجام شده است. در این تحقیق از افراد خواسته شده است به سوالاتی در زمینهی ورزش کردن، مصرف لبنیات و سبزیجات، مصرف سیگار، وضعیت محیطی محل کار، وضعیت جسمانی و عوامل مستعد بیماری، پاسخ دهند. فایل دیتا این مقاله را میتوانید از اینجا Binary Logistic Regression دریافت کنید.
نکتهبه این مطلب بسیار مهم توجه کنید که هنگامی که میخواهید از مدل رگرسیون لجستیک استفاده کنید، باید از هر دو گروه افراد یعنی افرادی که پدیده مورد بررسی بر روی آنها رخداده است و افرادی که پدیده مورد بررسی بر روی آنها رخ نداده است، استفاده کنید. در این مثال به معنای آن است که هم باید از افراد سالم نمونهگیری شود و هم از افراد بیمار. در این تحقیق به دنبال آن هستیم که میزان و چگونگی تاثیر این کمیتها را بر روی وجود و یا عدم وجود بیماریهای ریوی بررسی کنیم.
ما در این مطالعه به دنبال تعیین میزان تاثیر هر یک از این عوامل بر روی رخداد بیماریهای ریوی و همچنین ساختن مدلی جهت پیشبینی آینده هستیم. در تصویر زیر بخشی از فایل دیتا را مشاهده میکنید.
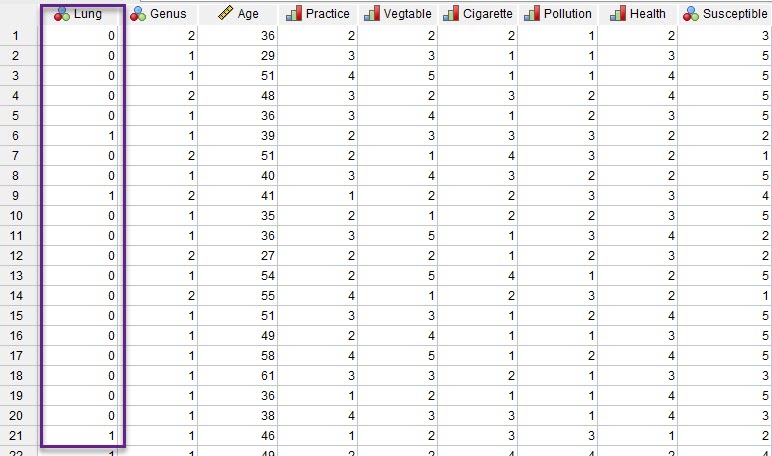
دادههای مثال تحلیل رگرسیون لجستیک با SPSS همانگونه که در تصویر بالا مشاهده میکنیم، ستون با نام Lung که بیانگر وقوع یا عدم وقوع بیماریهای ریوی است با کدهای صفر و یک مشخص شده است.
به این نکته توجه کنید که نحوهی وارد کردن دادهها به صورت کدهایی است که برای هر گزینه در نظر گرفته میشود. به عنوان مثال در سوال اصلی که بیانگر وجود یا عدم وجود بیماری است، چنانچه پیشامد مورد نظر را وجود بیماری ریوی در فرد مورد مطالعه قرار دهیم کد صفر یعنی پیشامد رخ نداده و فرد بیمار نیست و کد یک به معنای رخ دادن پیشامد و بیمار بودن فرد است.
حال به منظور یافتن مدل رگرسیون خطی در نرمافزار SPSS از مسیر زیر استفاده میکنیم.
Analyze → Regression → Binary Logistic
مسیر انجام رگرسیون لجستیک باینری در نرمافزار SPSS تنظیمات نرمافزارSetting
هنگامی که به مسیر بالا در نرمافزار SPSS میرویم، پنجره زیر با نام Logistic Regression برای ما باز میشود.
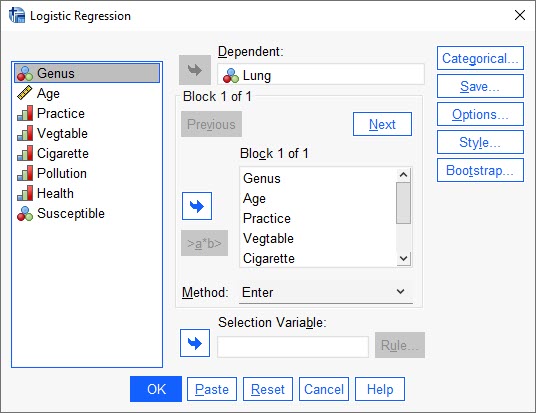
پنجره Logistic Regression در نرمافزار SPSS از آنجا که به دنبال به دست آوردن رابطه بین بیماری ریوی و عوامل اثرگزار بر آن و همچنین پیشبینی احتمال وقوع این بیماری هستیم، Lung به عنوان کمیت وابسته Dependent و سایر Xها به عنوان کمیتهای مستقل Independent تعریف میشوند.
در پنجره Logistic Regression تبها و گزینههای مختلفی وجود دارد که من سعی میکنم به بیان مهمترین آنها بپردازم.
Categorical
در تب
 میتوانیم نتایج و خروجیهای نرمافزار در مدل رگرسیون لجستیک باینری BLR را به تفکیک هر کدام از گروههای تشکیل دهنده یک Variable و در مقایسه با یک گروه رفرنس به دست بیاوریم.
میتوانیم نتایج و خروجیهای نرمافزار در مدل رگرسیون لجستیک باینری BLR را به تفکیک هر کدام از گروههای تشکیل دهنده یک Variable و در مقایسه با یک گروه رفرنس به دست بیاوریم.به عنوان مثال فرض کنید میخواهیم نتایج به تفکیک جنسیت و میزان ورزش هفتگی، تفکیک شود. البته این کار را میتوانیم فقط بر روی کمیتهای اسمی و رتبهای انجام دهیم. تصویر زیر را ببینید.
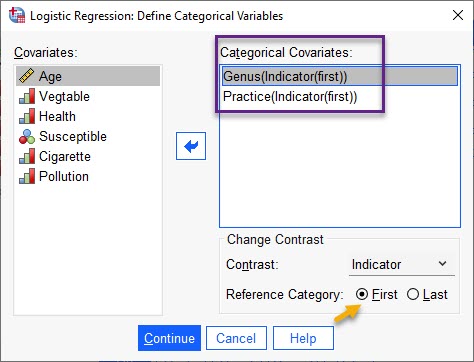
پنجره Define Categorical Variables در تصویر بالا، Genus و Practice در کادر Categorical Covariates قرار گرفتهاند. Reference Category نیز کد First قرار داده شده است. به معنای اینکه در هر کدام از کمیتهای جنسیت و ورزش، اولین کد، رفرنس قرار داده شده و سایر گروهها با آن مقایسه میشوند. ما این کدها را در پنجره Variable View تعریف کردهایم.
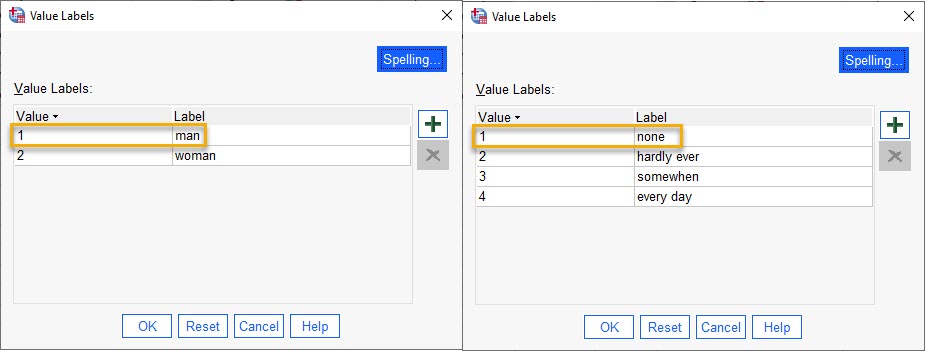
کدهای تعریف شده برای جنسیت و ورزش و گروه رفرنس به عنوان مثال در کمیت جنسیت، مردان رفرنس هستند و در کمیت ورزش، گروهی که ورزش نمیکنند، رفرنس هستند و نتایج سایر گروهها با این گروه مقایسه میشوند.
Save
تب دیگر در پنجره Logistic Regression با نام
 قرار دارد. ما با استفاده از گزینههای این تب میتوانیم، خروجیهای بیشتری از نتایج خود داشته باشیم. اغلب این خروجیها در پنجره دیتا نرمافزار SPSS قرار میگیرند. در تصویر زیر آن را ببینید.
قرار دارد. ما با استفاده از گزینههای این تب میتوانیم، خروجیهای بیشتری از نتایج خود داشته باشیم. اغلب این خروجیها در پنجره دیتا نرمافزار SPSS قرار میگیرند. در تصویر زیر آن را ببینید.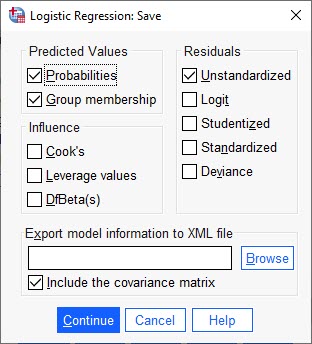
پنجره Save در رگرسیون لجستیک باینری BLR من در این پنجره از نرمافزار خواستهام مقادیر پیشبینی شده Predicted Values برای احتمال وقوع پیشامد (در این مثال بیماریهای ریوی) یعنی گزینه Probabilities و همچنین گزینه Group membership را به دست دهد. درباره کاربرد این گزینه در ادامه و به هنگام بیان نتایج، بیشتر صحبت خواهیم کرد.
به همین ترتیب از نرمافزار خواستهایم باقیماندههای Residuals مدل رگرسیونی را برای ما نشان دهد. البته من حالت غیراستاندارد شده Unstandardized را انتخاب کردهام. به سادگی میتوانستیم سایر گزینهها مانند باقیماندههای استاندارد شده Standardized را نیز انتخاب کنیم.
Options
بر روی تب
 بزنید تا پنجره زیر برایتان باز شود.
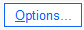
بزنید تا پنجره زیر برایتان باز شود.پنجره Options در BLR من گزینههای مختلف پنجره Options را که بیشتر با آنها سروکار داریم، مشخص کردهام. در ادامه به توضیه هر یک میپردازم.
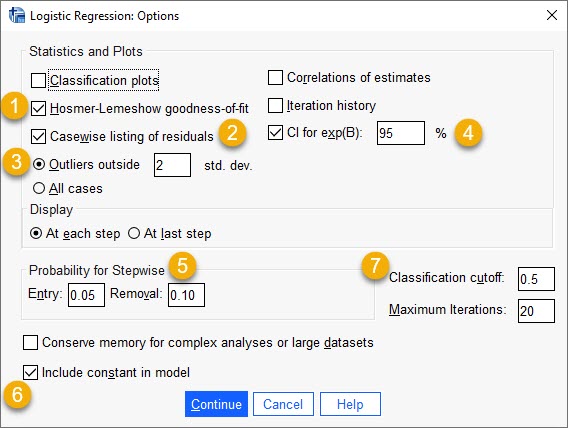
1- آزمون Hosmer-Lemeshow goodness of Fit در رده آزمونهای نیکویی برازش قرار میگیرد. با استفاده از این گزینه میتوانیم فرضیهی مناسب بودن مدل برازش شده و اصطلاحاً نیکویی برازش را تست کنیم.
2 و 3- با استفاده از گزینه Casewise listing of residuals میتوانیم آمارههایی درباره باقیماندههای مدل BLR به دست بیاوریم. یافتن آمارهها میتواند بر روی همه افراد باشد و یا فقط بر روی بخشی از آنها. به عنوان مثال من در اینجا از نرمافزار خواستهام فقط برای باقیماندههایی که دو برابر انحراف معیار همه باقیماندهها است، نمایش داده شود. همچنین انتخاب این گزینه به شناسایی دادههای پرت Outliers مطالعه کمک خواهد کرد.
4- با انتخاب گزینه CI for exp(B) 95% میتوانیم فواصل اطمینان 95 درصد برای ضرایب رگرسیون لجستیک براورد شده را به دست بیاوریم.
5- معیارهای ورود و خروج Variableها به مدل BLR در اینجا قابل تنظیم شدن است. علاقمند بودید در این زمینه لینک (انتخاب روشهای ورود کمیتهای مستقل به مدل رگرسیونی) را بخوانید. هنگامی که از روش گام به گام Stepwise برای ورود X ها به مدل رگرسیونی استفاده میکنیم، این معیارها قابل استفاده خواهند بود. ما در اینجا انتخاب کردهایم که X های با P-value کمتر از 0.05 وارد مدل رگرسیونی شوند و X های با P-value بزرگتر از 0.1 از مدل رگرسیونی خارج شوند.
6- معمولاً به صورت پیشفرض، ضریب ثابت یا همان $ \displaystyle {{{b}_{0}}}$ در یک مدل رگرسیونی، قرار دارد. در اینجا نیز نرمافزار این گزینه را برای ما انتخاب کرده است.
7- یکی از جداول و نتایج مهم در تحلیل BLR، جدول با نام Classification Table است. در این جدول میتوانیم حساسیت Sensitivity و ویژگی Specificity مطالعه خود را به دست بیاوریم. این کار با استفاده از قرار دادن نقطه برش Cutoff انجام میشود. در این زمینه خوب است لینک (منحنی ROC ، نقطه برش ، حساسیت و ویژگی) را ببینید. در ادامه و به هنگام بیان نتایج تحلیل BLR در این زمینه بیشتر صحبت میکنیم.
خب، حال OK میکنیم تا بتوانیم به بیان و توضیح نتایج و خروجیهای نرمافزار SPSS در تحلیل رگرسیون لجستیک بپردازیم.
نتایج تحلیل رگرسیون لجستیک باینریOutput & Results
در ابتدای نتایج و خروجیهای نرمافزار، جدول با نام Case Processing Summary قرار دارد. در این جدول تعداد دادههای مورد تحلیل و گمشده که بر روی آنها آنالیزی انجام نشده است، بیان میشود.
جدول Case Processing Summary نرمافزار SPSS تحلیل BLR را در دو مرحله و Block انجام میدهد. بلوک ابتدایی به مرحلهای اشاره میکند که هیچکدام از X ها وارد مدل نمیشوند. تصویر زیر را ببینید.
جدول ضرایب رگرسیونی در بلوک صفر با این حال، ما نتایج مرحله نهایی را بیان میکنیم. در جدول زیر با نام Model Summary مناسب بودن مدل ایجاد شده و میزان توضیح مدل BLR ایجاد شده توسط کمیتهای مستقل، به دست آمده است.

جدول Model Summary در نتایج این جدول ضرایب تعیین Cox & Snell R Square و Nagelkerke R Square به ترتیب برابر با 0.518 و 0.707 به دست آمده است. این اعداد تاحدی بیانگر، خوب و مناسب بودن مدل رگرسیونی است. نتایج به دست آمده نشان میدهد به ترتیب حدود 51 و 71 درصد احتمال رخداد بیماریهای ریوی توسط کمیتهای مستقل سن، جنسیت، ورزش، مصرف سبزیجات، سیگار، آلودگی محیط کار، وضعیت جسمانی و استعداد بروز بیماری، توضیح داده میشود. همانگونه که میدانیم این عدد بین صفر تا یک قرار دارد و هر چه به یک نزدیکتر باشد، نشان میدهد مدل ایجاد شده بهتر و بیشتر میتواند تغییرات کمیت پاسخ را بیان کند.
به یاد داشته باشید ما در تب Options آزمون Hosmer-Lemeshow goodness of Fit را مطرح کردیم. در ادامه نتایج این آزمون به دست آمده است.

جدول Hosmer-Lemeshow goodness of Fit همانند تمام آزمونهای نیکویی برازش Goodness of Fit فرض صفر، نیکو بودن برازش (مناسب بودن مدل) و فرض مقابل عدم نیکو بودن برازش ( مناسب نبودن مدل) است. بنابراین فرضیهها به صورت زیر است.
آمارهی این آزمون دارای توزیع کای- اسکور است که مقدار آن برابر با 13.445 به دست آمده است. همچنین مقدار احتمال به دست آمده یعنی P-value = 0.097 نشان میدهد که فرض نیکو و مناسب بودن مدل رگرسیون لجستیک برازش شده بر دادهها، پذیرفته میشود.
جدول با نام Classification Table از مهمترین نتایج در تحلیل BLR است. همانگونه که قبلاً نیز اشاره کردیم با استفاده از آن میتوانیم حساسیت Sensitivity و ویژگی Specificity مطالعه خود را در یک Cutoff خاص که معمولاً 0.5 در نظر گرفته میشود، به دست بیاوریم.
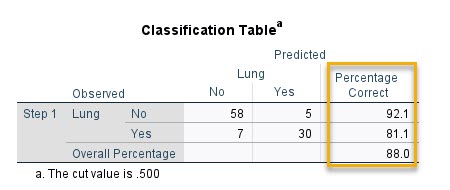
Classification Table در مدل رگرسیون لجستیک حال بیایید به توضیح این جدول بپردازیم. در سطرها، تعداد موارد مثبت و منفی مشاهده شده آمده است. همانگونه که میبینید 37 مثبت و 63 منفی. در ستونها نیز تعداد موارد مثبت و منفی پیشبینی شده به دست آمده است. این تعداد بر مبنای همان نقطه برش 0.5 است. به معنای اینکه برای فردی که احتمال رخداد بیماری، کمتر از 0.5 باشد، آن فرد سالم (No) و برای فردی با احتمال رخداد بالاتر از 0.5 فرد بیمار (Yes)، گزارش میشود.
در این جدول نشان داده میشود، 58 نفر که فاقد بیماری بودهاند، مدل BLR نیز برای آنها عدم بیماری (احتمال رخداد بیماری کمتر از 0.5)، بیان کرده است. با این حال برای 5 نفر سالم، مدل، بیمار گزارش کرده است. بنابراین درصد درستی Percentage Correct برای افراد فاقد بیماری برابر با 92.1 درصد به دست میآید. رابطه زیر را ببینید.
$ \displaystyle Specificity=Percentage\begin{array}{*{20}{c}} {} & {Correc{{t}_{{\left( {Lung\_No} \right)}}}=\left( {\frac{{58}}{{58+5}}} \right)\times 100=92.1} \end{array}$
این رابطه بیانگر همان ویژگی Specificity (منفی صحیح) در تحلیلهای آماری است. بنابراین نتایج سطر اول جدول Classification، مقدار Specificity مطالعه را به ما نشان میدهد.
حال به سطر Lung (Yes) نگاه کنید. 30 نفر دارای بیماری بودهاند، مدل BLR نیز برای آنها بیماری (احتمال رخداد بیماری بیشتر از 0.5)، به دست آورده است. اما برای 7 نفر بیمار، مدل به اشتباه سالم گزارش کرده است. بنابراین درصد درستی Percentage Correct برای افراد دارای بیماری برابر با 81.1 درصد به دست آورده است. رابطه زیر را ببینید.
$ \displaystyle Sensitivity=Percentage\begin{array}{*{20}{c}} {} & {Correc{{t}_{{\left( {Lung\_Yes} \right)}}}=\left( {\frac{{30}}{{7+30}}} \right)\times 100=81.1} \end{array}$
این رابطه بیانگر حساسیت Sensitivity (مثبت صحیح) است. بنابراین نتایج سطر بعدی جدول Classification، مقدار Sensitivity مطالعه را نشان میدهد.
عدد Overall Percentage که در این مثال برابر با 88.0 درصد به دست آمده است، همان دقت (ACC) Accuracy مدل را نشان میدهد و از رابطه زیر به دست میآید.
$ \displaystyle Accuracy\text{ }=\left( {\frac{{58+30}}{{58+7+5+30}}} \right)\times 100=88.0$
در هر مدل رگرسیونی، مهمترین نتیجه و خروجی آن، جدول ضرایب است. من در تصویر زیر نتایج جدول Variables in the Equation را آوردهام.
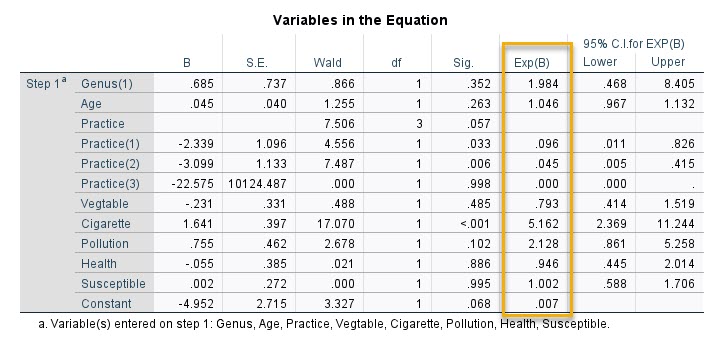
جدول Variables in the Equation در مدل رگرسیون لجستیک باینری در این جدول به ازای هر کدام از کمیتهای مستقل موجود در مدل، ضرایب رگرسیونی B، مقادیر احتمال Sig، نسبت بخت Exp(B) همراه با فواصل اطمینان برای نسبت بخت به دست آمده است.
به خاطر داشته باشید، ما برای کمیتهای جنسیت و ورزش نیز Categorical انجام دادیم. به عنوان مثال در کمیت جنسیت، مردان رفرنس هستند و در کمیت ورزش، گروهی که ورزش نمیکنند، رفرنس هستند و نتایج سایر گروهها با این گروه مقایسه میشوند.
ابتدا بیایید نتایج سطر با نام Genus(1) را نگاه کنیم. از آنجا که جنسیت، گروهبندی شده است و مردان نیز رفرنس هستند، بنابراین نتیجه به دست آمده دربارهی زنان است که در مقایسه با مردان بیان میشود. نتیجه به دست آمده بیانگر آن است که زنان نسبت به مردان 1.98 برابر بیشتر احتمال دچار شدن به بیماریهای ریوی را دارند، با این حال نتیجه معنادار به دست نمیآید (OR =1.98, P-value = 0.352).
افزایش سن نیز بر رخداد بیماریهای ریوی موثر است، هر چند این تاثیر معنادار به دست نمیآید (OR =1.05, P-value = 0.263).
ما ورزش کردن را نیز Categorical کردیم، به نحوی که گروهها در مقایسه با افرادی که ورزش نمیکنند مقایسه میشود. این نتیجه در قالب سطرهای Practice به دست آمده است. دقت کنید ضریب بتا برای همه آنها منفی است. این مطلب نشان میدهد افرادی که ورزش میکنند، نسبت به آنهایی که اصلا ورزش نمیکنند، کمتر در معرض خطر ابتلا به بیماریهای ریوی قرار دارند. نتایج برای Practice (1) یعنی به ندرت و Practice (2) یعنی گاهی اوقات، معنادار شده است.
در مواردی که عدد Exp(B) یا همان OR منفی میشود، ما برای فهم بهتر از وارون عدد OR جهت بیان نتایج استفاده میکنیم. در اینجا مثلا به دست میآوریم افرادی که گاهی اوقات ورزش میکنند نسبت به آنهایی که اصلا ورزش نمیکنند 22.2 برابر شانس کمتری برای دچار به بیماریهای ریوی دارند $ \displaystyle \left( {\frac{1}{{OR}}=\frac{1}{{0.045}}=22.2} \right)$.
به همین ترتیب میتوانیم برای بقیه کمیتها نیز تحلیل کنیم. به عنوان مثال دیگر مصرف سیگار میتواند شانس وقوع بیماریهای ریوی را 5.16 برابر افزایش دهد. این نتیجه معنادار نیز هست (OR =5.16, P-value < 0.001).
به یاد داشته باشید در پنجره Options، از نرمافزار خواستیم با استفاده از گزینه Casewise listing of residuals آمارههایی درباره باقیماندههای مدل BLR به دست بیاورد. در جدول Casewise List میتوانیم این نتایج را ببینیم.
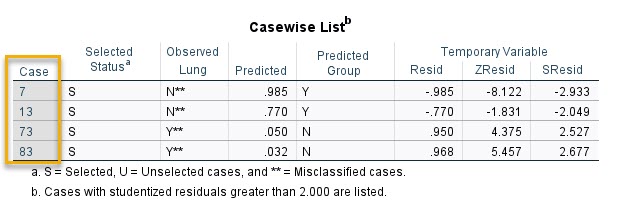
جدول Casewise List در این جدول میتوانید شماره افراد و Case هایی را که از نظر نرمافزار، Outliers به حساب میآیند، مشاهده کنید. در ستون با نام Observed Lung مثبت یا منفی یودن، بیماریهای ریوی در این افراد مشخص شده است. به عنوان مثال برای افراد شمارههای 7 و 13 نتیجه منفی و برای افراد با شمارههای 73 و 83 نتیجه مثبت گزارش شده است. شمارههای افراد را میتوانید در همان فایل دیتا SPSS خود ببینید.
در ستون Predicted احتمال رخداد بیماری برای هر کدام از این Case ها به دست آمده است. این کار با استفاده از همان مدل BLR انجام میشود. در ستون Predicted Group نیز نتیجه قرار گرفتن در گروه مثبت یا منفی (بر مبنای مدل BLR) به دست آمده است. چنانچه دقت کنید نتایج برازش شده بر مبنای مدل رگرسیون لجستیک، کاملاً وارون نتایج مشاهده شده است. یعنی برای افراد شمارههای 7 و 13 نتیجه مثبت و برای افراد با شمارههای 73 و 83 نتیجه منفی پیشبینی شده است. به همین دلیل ما این افراد را به عنوان دادههای پرت شناسایی میکنیم و شاید بهتر باشد آنها را از مدل کنار بگزاریم.
به ستون SResid هم نگاه کنید. همه اعداد این ستون از 2 بزرگتر هستند. به یاد بیاورید که در گزینه Casewise listing of residuals از نرمافزار خواستهام فقط برای باقیماندههایی که دو برابر انحراف معیار همه باقیماندهها است، نتایج گزارش شود.
فایل دیتا پس از تحلیل BLRData File
حال بیایید به فایل دیتا، پس از تحلیل نگاهی بیندازیم. در تصویر زیر آن را ببینید.
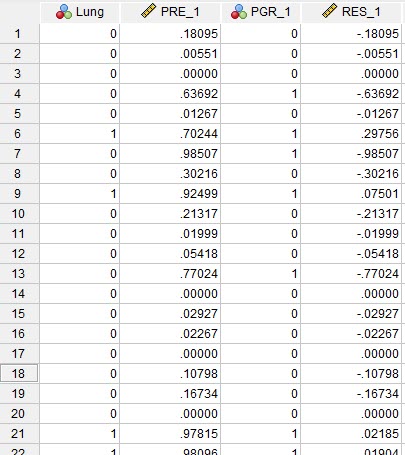
فایل دیتا پس از تحلیل رگرسیون لجستیک به یاد داشته باشید ما در تب Save از نرمافزار خواستیم مقادیر پیشبینی شده Predicted Values احتمال وقوع پیشامد، گزینه Group membership و همچنین باقیماندههای Residuals مدل رگرسیونی را برای ما نشان دهد. در اینجا، این نتایج به ازای هر Case به دست آمده است.
ستون با نام PRE، احتمال رخداد پیشامد (بیماری ریوی) را برای هر فرد، بیان کرده است. مثلا برای فرد اول احتمال رخداد بیماری برابر با 0.18 به دست آمده است.
در ستون PGR، افراد با کدهای صفر (منفی، عدم بیماری) و یک (مثبت، وجود بیماری) دستهبندی شدهاند. این نتایج بر مبنای ستون قبلی یعنی PRE به دست میآید. به نحوی که هر فردی که احتمال رخداد بیماری برای او بالاتر از 0.5 به دست بیاید در گروه مثبت (یک) و هر فردی که احتمال رخداد بیماری برای او کمتر از 0.5 به دست بیاید در گروه منفی (صفر) قرار میگیرد. بر مبنای نتایج همین ستون است که Classification Table در خروجیهای نتایج رگرسیون لجستیک، به دست میآید.
ستون دیگر با نام RES، همان باقیماندههای مدل رگرسیون لجستیک باینری هستند. خیلی هم ساده به دست میآیند. اختلاف بین ستون Lung و PRE را ببینید.
نکتهدر پنجره Logistic Regression بخشی با عنوان Method دیده میشود. در تصویر زیر آن را ببینید.
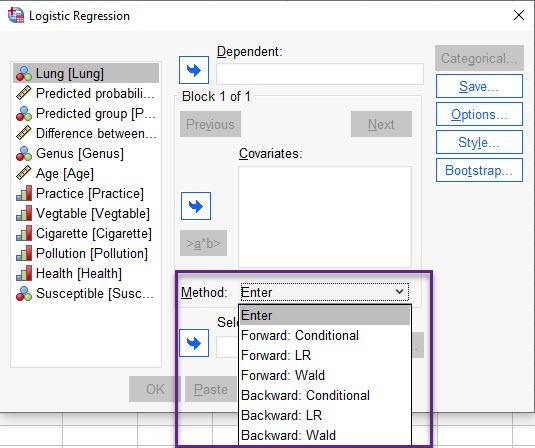
کادر Method در پنجره Logistic Regression با استفاده از این بخش میتوانیم دربارهی نحوه ورود X ها به مدل رگرسیونی تصمیم بگیریم. علاقمند بودید در این زمینه لینک (انتخاب روشهای ورود کمیتهای مستقل به مدل رگرسیونی) را بخوانید.
در همین پنجره Logistic Regression بخش دیگری با نام Selection Variable وجود دارد. در تصویر زیر آن را ببینید.
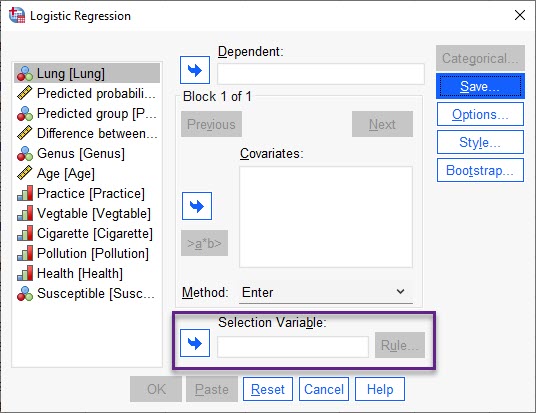
کادر Selection Variable با استفاده از این بخش، میتوانیم تحلیل رگرسیون لجستیک خود را صرفاً بر روی دادههایی خاصی انجام دهیم. در واقع شرطی بر روی دادهها قرار دهیم که تحلیل تنها بر روی دادههایی که آن شرط را دارند، انجام شود. در این زمینه علاقمند بودید لینک (Selection Variable در مدلهای رگرسیونی) را ببینید.
در این مقاله به موضوع طراحی رگرسیون لجستیک باینری Binary Logistic Regression در نرمافزار SPSS پرداختیم. این کار با استفاده از بیان مثال و انجام تحلیل BLR بر روی آن، نوشته شد. براورد پارامترهای رگرسیونی، مفاهیم نسبت بخت Odds Ration، نتایج Classification Table و تنظیمات نرمافزار، مورد بررسی قرار گرفت.چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Binary Logistic Regression in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/binary-logistic-regression-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Binary Logistic Regression in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/binary-logistic-regression-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.