رگرسیون لجستیک چند جمله ای Multinomial Logistic Regression در SPSS
Multinomial Logistic Regression
میدانیم که رگرسیون در حالت کلی به صورت رابطه Y = f(X) تعریف میشود. در این رابطه میخواهیم با استفاده از تابع f بین Xها به عنوان Independent Variable و Y به عنوان Dependent Variable یک ارتباط و مدل به دست بیاوریم. در این مدل ما قصد داریم با استفاده از DV ها به پیشبینی مقادیر عددی برای IV بپردازیم.

رگرسیون چند جمله ای که نام کاملتر آن رگرسیون لجستیک چند جمله ای است، هنگامی به کار میرود که کمیت پاسخ یا همان Y دارای اندازههای اسمی Nominal مانند رشتههای تحصیلی، گروههای خونی و یا اسامی سلولی باشد.
به عنوان مثال در نظر بگیرید مدیر یک مدرسه میخواهد بررسی کند چه عواملی بر علاقه دانشآموزان برای اینکه کلاسهای فوق برنامه (مانند ورزش، نقاشی، موسیقی و ….) را انتخاب کنند، اثرگزار است. او میخواهد بداند آیا سن دانشآموز و پایه تحصیلی آنها بر انتخاب کلاس فوق برنامه تاثیر دارد یا خیر.
در این مطالعه، کلاس فوق برنامه به عنوان کمیت پاسخ یا همان Y مطرح است. سن و پایه تحصیلی دانشآموزان نیز به صورت کمیتهای مستقل یا همان Xها وارد مطالعه میشوند. از آنجا که پاسخ (نوع کلاس) یک کمیت اسمی است، مدیر مدرسه از رگرسیون لجستیک چند جمله ای یا همان Multinomial Logistic Regression در این مطالعه استفاده میکند.
تحلیلهای جایگزین
Binary Logistic Regression
اگر کمیت پاسخ تنها دارای دو گروه باشد، مثلا شکست یا پیروزی، سالم یا بیمار. در این صورت مدل رگرسیونی ما لجستیک باینری Binary Logistic Regression خواهد بود. در این زمینه علاقمند بودید میتوانید لینک (رگرسیون لجستیک باینری Binary Logistic Regression در نرمافزار SPSS) را ببینید.
Ordinal Logistic Regression
اگر کمیت پاسخ تنها دارای بیشتر از دو گروه رتبهای Ordinal باشد، به عنوان مثال ردههای کم، متوسط، زیاد. در این صورت مدل رگرسیونی ما لجستیک ترتیبی Ordinal Logistic Regression خواهد بود. در این زمینه میتوانید لینک (رگرسیون لجستیک ترتیبی Ordinal Logistic Regression در نرمافزار Minitab) را مشاهده کنید.
Poisson Regression
اگر کمیت پاسخ قابل شمارش و تعداد رخداد یک پیشامد باشد، به عنوان مثال تعداد نقصها در یک سیستم یا تعداد تصادفات. در این صورت مدل رگرسیونی ما پواسن Poisson Regression خواهد بود. علاقمند بودید لینک (تحلیل مدل رگرسیون پواسن Poisson Regression با نرمافزار گراف پد) را ببینید.
مسیر انجام تحلیل رگرسیون چند جمله ای
SPSS
مسیر انجام آنالیز رگرسیون لجستیک چند جملهای در نرمافزار SPSS به صورت زیر است.
Analyze→ Regression → Multinomial Logistic
مثال رگرسیون چند جمله ای
Example
مدیر یک مدرسه میخواهد روشهای مختلف تدریس را ارزیابی کند. او دادههای 30 دانشآموز را با پرسیدن موضوع مورد علاقه آنها و همچنین روش تدریس در کلاس درس، جمعآوری میکند.
از آنجا که کمیت پاسخ یعنی موضوع مورد علاقه دانشآموزان، گروهبندی شده است و ترتیب خاصی ندارند، مدیر مدرسه از رگرسیون لجستیک چند جملهای استفاده میکند. او میخواهد بداند چگونه سن دانشآموزان و روش تدریس (نشان دادن یا توضیح دادن) با علاقه دانش آموزان در درس (ریاضی، علوم و هنر) در ارتباط است.
مدیر مدرسه از درس مورد علاقه به عنوان کمیت پاسخ (Y) استفاده میکند. گروهبندیهای کمیت پاسخ به صورت اسمی یعنی ریاضی، علوم و هنر هستند، بنابراین کمیت پاسخ اسمی یا همان Nominal است. کمیتهای مستقل و پیشبینی کننده نیز سن و روش تدریس خواهند بود.
برای مدلسازی رابطه بین پیشبینی کنندهها (Xها) و پاسخ (Y) از رگرسیون لجستیک چند جمله ای Multinomial Logistic Regression استفاده میشود.
فایل دیتای این مثال و نتایج به دست آمده با استفاده از نرمافزار SPSS را میتوانید از اینجا دریافت کنید.
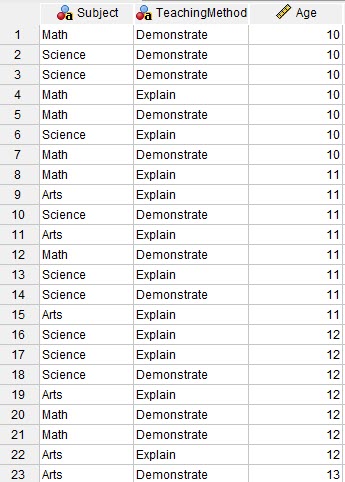
در تصویر زیر میتوانید بخشی از دادهها را مشاهده کنید.
همانگونه که بالاتر گفتیم با استفاده از مسیر زیر، به انجام آنالیز Multinomial Logistic Regression در نرمافزار SPSS میپردازیم.
Analyze→ Regression → Multinomial Logistic
پس از رفتن به این مسیر، پنجره Multinomial Logistic Regression برای ما باز میشود.
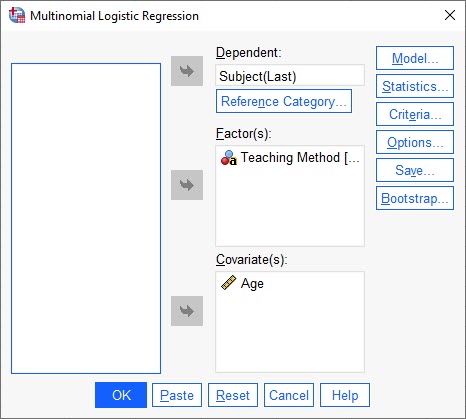
در این پنجره، ستون Subject که همان موضوعات مورد علاقه دانشآموز است، را به عنوان Dependent تعریف میکنیم. ستون Teaching Method که بیانگر روش تدریس دانشآموزان است را به عنوان Factor و Age را در کادر Covariate قرار میدهیم.
در پنجره Multinomial Logistic Regression، تب ![]() را ببینید.
را ببینید.
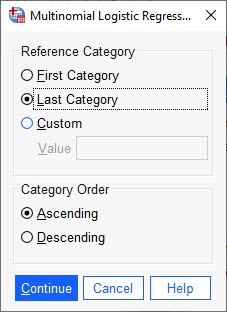
در این پنجره انتخاب میکنیم که گروه مرجع در کمیت وابسته (یعنی موضوعات مورد علاقه) کدام گروه (هنر، ریاضی، علوم) باشد. به عنوان مثال، نرمافزار SPSS به صورت پیشفرض بر روی Last Category قرار دارد. به معنای اینکه از نظر حروف الفبا، آخرین گروه یعنی Science به عنوان مرجع قرار داده میشود و سایر گروهها با آن مقایسه میشوند. در این تب، به دلخواه میتوانیم گروه دیگری را به عنوان رفرنس، قرار دهیم.
پنجره Multinomial Logistic Regression، تبهای مختلفی دارد که ما معمولاً همان تنظیمات پیشفرض آنها را میپذیریم و به آنها در این مقاله کاری نداریم.
با این حال بر روی تب ![]() بزنید تا وارد پنجره زیر شوید.
بزنید تا وارد پنجره زیر شوید.
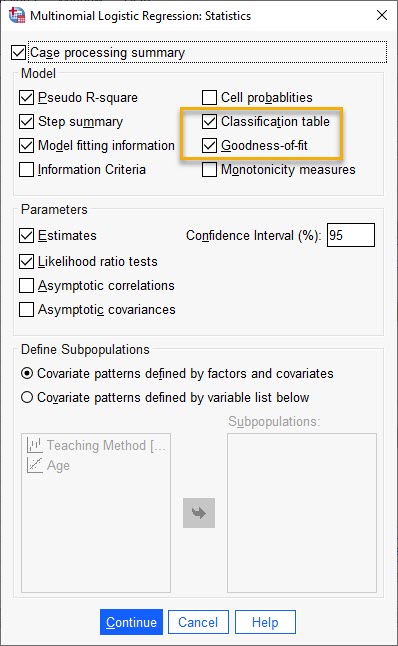
در این پنجره، علاوه بر گزینههای انتخاب پیشفرض SPSS، گزینههای Classification table و Goodness-of-fit را انتخاب میکنیم.
بر روی تب ![]() بزنید. پنجره زیر برای ما باز میشود.
بزنید. پنجره زیر برای ما باز میشود.
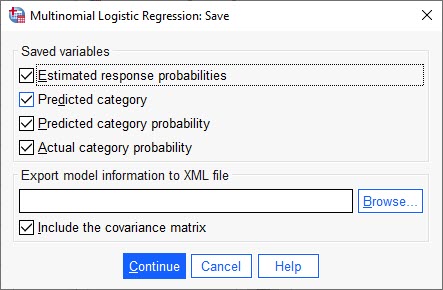
در این پنجره از نرمافزار میخواهیم، خروجیهایی مانند احتمالهای پاسخ براورد شده، طبقه پیش بینی شده، احتمال طبقه پیش بینی شده و احتمال گروه واقعی را برای ما به دست بیاورد. این نتایج در همان فایل دیتا، قابل مشاهده خواهند بود. در ادامه دربارهی آنها بیشتر صحبت میکنیم.
در مرحلهی بعد Continue کرده و سپس OK میکنیم. با انجام این کار نتایج و خروجیهای نرمافزار برای ما به دست میآید. در ادامه به بیان آنها میپردازیم.
نتایج تحلیل رگرسیون لجستیک چند جمله ای
SPSS Output
در ابتدا جدول زیر با نام Case Processing Summary مشاهده میشود. در این جدول به ازای هر کدام از سطوح مختلف کمیت پاسخ یعنی Subject فراوانی آنها آمده است.
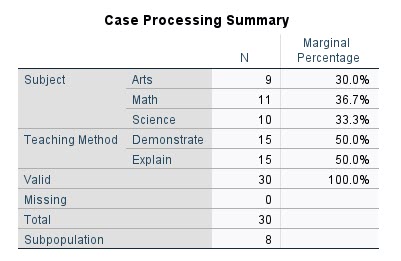
نتایج جدول بالا نشان میدهد از مجموع 30 دانشآموز، 10 نفر به علوم و 11 نفر به ریاضیات علاقمند هستند. همچنین 9 نفر نیز به هنر علاقمند است. همچنین در 15 نفر روش تدریس، توضیح دادن و برای 15 نفر دیگر نشان دادن بوده است.
ما در این مطالعه، علاقمندی به علوم را به عنوان رفرنس در نظر گرفتهایم و بقیه را نسبت به آن ارزیابی میکنیم. به سادگی در تنظیمات نرمافزار میتوانیم یک موضوع دیگر را به عنوان رفرنس قرار دهیم. این مطلب را در تب Reference Category میتوانید انجام دهید.
- Model Fitting Information
جدول بعدی در نتایج نرمافزار با نام Model Fitting Information قرار دارد. آن را ببینید.
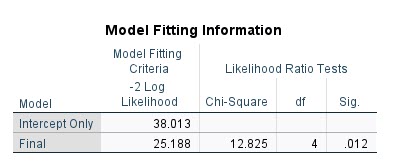
این نکته را میدانیم که هر کجا در نرمافزار ستونی با نام Sig میآید، فرضیهای آزمون شده است. در اینجا فرضیه مورد آزمون که نتایج آن در سطر Final آمده است، صفر بودن همه ضرایب رگرسیونی است. به معنای اینکه هیچکدام از کمیتهای مستقل (در این مثال سن و روش تدریس) تاثیر معنادار بر علاقمندی دانشآموزان ندارند.
نتیجه به دست آمده P-value = 0.012 بیانگر رد این فرضیه و معنادار بودن حداقل یکی از کمیتهای مستقل بر علاقمندی است.
- Goodness-of-Fit
همانند تمام آزمونهای نیکویی برازش Goodness of Fit فرض صفر، نیکو بودن برازش (مناسب بودن مدل) و فرض مقابل عدم نیکو بودن برازش ( مناسب نبودن مدل) است. بنابراین فرضیهها به صورت زیر است.
- فرض صفر. معادله و مدل رگرسیونی ایجاد شده مناسب است.
- فرض مقابل. معادله و مدل رگرسیونی ایجاد شده مناسب نیست.
در جدول زیر با نام Goodness-of-Fit نتیجه این فرضیه را ببینید.
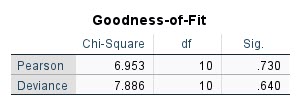
بر مبنای این جدول، روشها و آزمونهای نیکویی برازش Pearson و Deviance مورد بررسی قرار گرفته است. بیایید در ادامه به توضیح آنها بپردازیم.
آزمون پیرسون و همچنین Deviance تناقض و تفاوت بین مدل فعلی برازش شده بر دادهها و مدل کامل را ارزیابی میکند. فرض صفر در این آزمونها، نیکو بودن و مناسب بودن مدل برازش شده است. نتیجه به دست آمده بر مبنای آزمون نیکویی برازش پیرسن و مقدار احتمال به دست آمده، بیانگر تایید فرض صفر است و نشان میدهد، مدل به دست آمده مناسب است (P-Value = 0.730).
این نتیجه برای آزمون Deviance نیز برقرار است. بر مبنای مقدار احتمال به دست آمده نتیجه میگیریم مدل به دست آمده مناسب است (P-Value = 0.640).
- Pseudo R-Square
در ادامه نتایج نرمافزار SPSS در تحلیل مدل رگرسیون چند جمله ای، جدول زیر با نام Pseudo R-Square را ببینید.
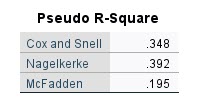
ما در هر مدل رگرسیونی عدد متناظر برای ضریب تعیین یا همان R Square را به دست میآوریم. بر مبنای این آماره میتوانیم بگوییم که X ها تا چه اندازهای از Y را میتوانند بیان کرده و توضیح دهند.
در یک مدل رگرسیونی چند جمله ای نیز با مفهومی به نام شبه ضریب تعیین که Pseudo R-Square نامیده میشود، روبهرو هستیم. در جدول بالا اعداد به دست آمده برای Pseudo R-Square بیان شدهاند. این اعداد بیانگر مناسب بودت تقریبی مدل برازش شده هستند.
- Likelihood Ratio Tests
نتایج ارایه شده در جدول آزمونهای نسبت درستنمایی Likelihood Ratio Tests، همانطور که در ادامه نشان داده شده است، از اهمیت بسیار بیشتری برخوردار است.
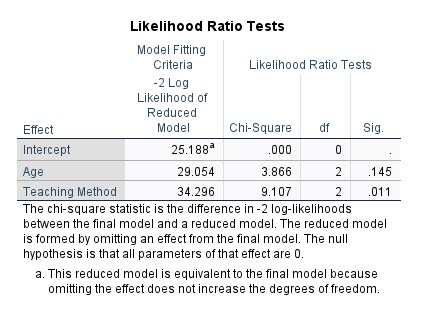
در این جدول تاثیر جداگانه هر کدام از کمیتهای مستقل یعنی Age و Teaching Method بر علاقمندی دانشآموزان به دست آمده است. نتایج این جدول بیشتر برای کمیتهای مستقل اسمی (در اینجا Teaching Method) مفید است، به دلیل اینکه تنها جدولی در مدل رگرسیون لجستیک چند جمله ای است که تاثیر کلی یک کمیت اسمی را در نظر میگیرد.
از نتایج جدول Likelihood Ratio Tests بر میآید که سن تاثیر معنادار بر علاقمندی دانشآموزان ندارد (P-value = 0.145). با این حال روش تدریس بر علاقمندی دانشآموزان موثر است (P-value = 0.011).
- Parameter Estimates
مهمترین جدول هر تحلیل رگرسیونی را میتوان جدول پارامترها Parameter Estimates عنوان کرد. در تصویر زیر میتوانید نتایج این جدول را مشاهده کنید.
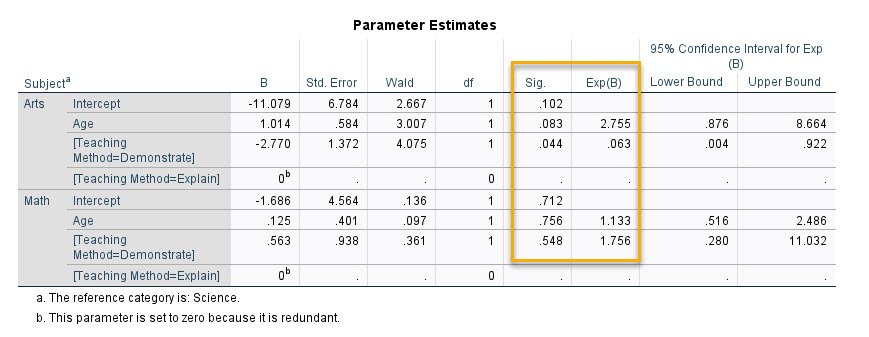
جدول بالا به دو بخش تقسیم میشود. یک بخش مربوط به هنر (Arts/Science) که در آن نسبت هنر به علوم بررسی میشود و بخش دیگر با نام ریاضی (Math/Science) است که در آن نسبت ریاضی به علوم بررسی میشود. در واقع ما همواره در حل هر مثال رگرسیون لجستیک چند جمله ای، به تعداد یکی کمتر از تعداد گروههای تشکیل دهنده کمیت اسمی پاسخ، بخش در خروجی نتایج نرمافزار خواهیم داشت.
همانگونه که در بالا نیز اشاره کردیم و در تب Reference Category آمده، علوم به عنوان رفرنس در نظر گرفته میشود که بقیه موضوعات نسبت به آن سنجیده میشوند.
در ادامه بیایید به توضیح و بیان یافتههای جدول بالا بپردازیم. ما در این مثال رگرسیون چند جمله ای، از دو کمیت مستقل یعنی Teaching Method و Age جهت براورد و مدلبندی یک کمیت اسمی یعنی علافه دانشآموز به موضوعات مختلف (در سه گروه علوم، ریاضی و هنر) استفاده کردیم.
اجازه دهید ابتدا از Math شروع کنیم.
Math
نتایج این بخش به بررسی علاقمندی دانشآموزان به ریاضی نسبت به علوم میپردازد.
نتایج جدول بالا در سطر Teaching Method را نگاه کنید. فقط برای Demonstrate آمده است (به دلیل اینکه نتایج Demonstrate نسبت به Explain است). عدد ضریب رگرسیونی یا همان B برابر با 0.563 شده است.
معمولا ما در مدلهای رگرسیون لجستیک (رگرسیون چند جمله ای یا ترتیبی یکی از آنها است) به جای تمرکز بر B، روی Exp(B) که در واقع همان Odds Ratio (OR) است، کار میکنیم. عدد Odds Ratio برای Demonstrate برابر با 1.756 شده است.
خب، حال این عدد چه چیزی را نشان میدهد؟
این عدد نشان میدهد روش تدریس اشاره کردن Demonstrate در مقایسه با روش توضیح دادن Explain، به اندازه 1.75 برابر علاقمندی به ریاضی (نسبت به علوم) را افزایش میدهد. بنابراین اگر به عنوان مثال به دنبال علاقمند کردن دانشآموزان به ریاضیات هستیم، بهتر است از روش تدریس اشاره کردن استفاده کنیم.
البته اگر به مقدار احتمال این سطر نگاه کنید، برابر با P-value = 0.548 شده است. به معنای اینکه در اینجا روش تدریس، عامل اثرگزار معناداری بر علاقهمندی دانشآموز به ریاضی (نسبت به علوم) نیست. فاصله اطمینان 95 درصد آن نیز عدد یک را در بردارد. کران پایین آن 0.28 و کران بالای آن 11.03 شده است.
کمیت مستقل دیگری که مورد بررسی قرار دادیم، سن بود. بیایید نتایج آن را نیز ببینیم.
ضریب رگرسیونی آن مثبت و OR آن برابر با 1.13 به دست آمده است. این عدد نشان میدهد افزایش یک واحد سن (سال) میتواند علاقه دانشآموز به ریاضی را به اندازه 1.13 برابر افزایش دهد. البته که این یافته نیز معنادار نیست (P-value = 0.756).
Arts
حال بیایید همه این نتایج را بار دیگر برای بخش دیگر جدول، یعنی هنر (Arts/Science) مرور کنیم. این بخش به بررسی علاقمندی دانشآموزان به هنر نسبت به علوم اشاره میکند.
نتایج جدول بالا در سطر Teaching Method برای Demonstrate آمده است. عدد ضریب رگرسیونی برابر با 2.77- شده است. عدد Odds Ratio نیز برابر با 0.063 به دست آمده است. از آنجا که این عدد کوچکتر از یک است، برای فهم بهتر آن را وارون میکنیم که میشود 15.87
این عدد نشان میدهد روش تدریس توضیح دادن در مقایسه با روش اشاره کردن، 15.87 برابر علاقمندی به هنر (نسبت به علوم) را افزایش میدهد. بنابراین اگر به دنبال علاقمند کردن دانشآموزان به هنر هستیم، بهتر است از روش تدریس توضیح دادن استفاده کنیم.
مقدار احتمال آن برابر با P-value = 0.044 شده است. به معنای اینکه روش تدریس، عامل اثرگزار معناداری بر علاقهمندی دانشآموز به هنر (نسبت به علوم) است. فاصله اطمینان 95 درصد آن نیز بزرگتر از یک است. کران پایین آن 0.004 و کران بالای آن 0.922 شده است.
در ادامه نتایج کمیت مستقل سن آمده است. ضریب رگرسیونی سن، مثبت و OR آن برابر با 2.76 شده است. این عدد نشان میدهد افزایش یک واحد سن (سال) میتواند علاقه دانشآموز به هنر را به اندازه 2.76 برابر افزایش دهد. این یافته در سطح پنج درصد معنادار نیست (P-value = 0.083).
- Classification Table
جدول با نام Classification Table از مهمترین نتایج در تحلیل رگرسیون لجستیک چند جمله ای است. در تصویر زیر آن را ببینید.
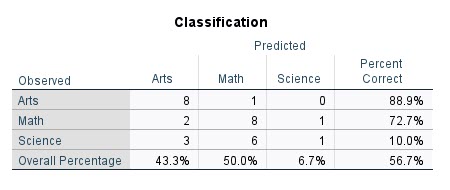
بر مبنای نتایج این جدول میتوانیم تعداد داتشآموزان علاقمند به هر موضوع، در برابر تعداد پیشبینی شده با استفاده از مدل رگرسیون چند جملهای را مشاهده کنیم.
به عنوان مثال 8 دانشآموز علاقمند به هنر، توسط مدل پیشبین نیز، علاقمند به هنر گزارش شدهاند. با حال یک دانشاموز علاقمند به هنر، به اشتباه در گروه علاقمند به ریاضی قرار گرفته است. در واقع درصد پیشبینی درست Percent Correct در بین علاقمندان به هنر برابر با 88.9% به دست آمده است.
در گروه دانشآموزان علاقمند به ریاضی که 11 نفر بودهاند، مدل رگرسیونی 8 نفر را به درستی پیشبینی کرده است. یعنی درصد درستی برای آنها 72.7% بوده است.
در گروه دانشآموزان علاقمند به علوم که 10 نفر بودهاند، مدل رگرسیونی فقط یک نفر را به درستی پیشبینی کرده است. درصد درستی برای آنها 10% بوده است.
چنانچه اعداد روی قطر را با هم جمع کنید، یعنی 17 = 1 + 8 + 8، در این صورت درصد درستی برای همه افراد برابر با 56.7 درصد به دست میآید.
فایل دادهها پس از تحلیل
Data File
به خاطر داشته باشید در تب ![]() خروجیهایی مانند احتمالهای پاسخ براورد شده، طبقه پیش بینی شده، احتمال طبقه پیش بینی شده و احتمال گروه واقعی را برای ما به دست بیاورد. این نتایج در فایل دیتا، قابل مشاهده هستند. در تصویر زیر بخشی از آنها را ببینید.
خروجیهایی مانند احتمالهای پاسخ براورد شده، طبقه پیش بینی شده، احتمال طبقه پیش بینی شده و احتمال گروه واقعی را برای ما به دست بیاورد. این نتایج در فایل دیتا، قابل مشاهده هستند. در تصویر زیر بخشی از آنها را ببینید.
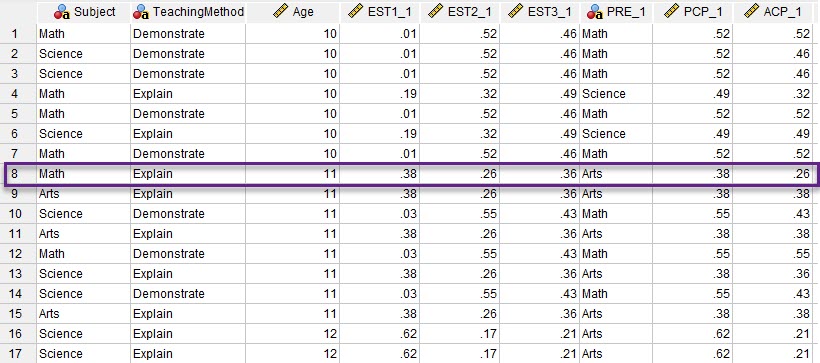
در این فایل ستونهای با نام EST2 ،EST1 و EST3 متناظر با گزینهی Estimated response probabilities در تب ![]() به دست آمدهاند. هر کدام از ستونهای EST به احتمال تعلق فرد به یکی از گروههای به ترتیب هنر، ریاضی و علوم، بیان میشوند. به عنوان مثال برای فرد دهم که خودش ابراز علاقه به ریاضی کرده است، احتمال علاقمندی به هنر برابر با 38%، به ریاضی 26% و علاقمندی به علوم 36% به دست آمده است. این نتایج از همان ستونهای EST2 ،EST1 و EST3 به دست میآید.
به دست آمدهاند. هر کدام از ستونهای EST به احتمال تعلق فرد به یکی از گروههای به ترتیب هنر، ریاضی و علوم، بیان میشوند. به عنوان مثال برای فرد دهم که خودش ابراز علاقه به ریاضی کرده است، احتمال علاقمندی به هنر برابر با 38%، به ریاضی 26% و علاقمندی به علوم 36% به دست آمده است. این نتایج از همان ستونهای EST2 ،EST1 و EST3 به دست میآید.
ستون دیگر با نام PRE در فایل دیتا وجود دارد. نتایج این ستون به دلیل انتخاب گزینه Predicted category در تب ![]() به دست آمده است. بر مبنای این ستون، هر فرد به یک موضوع مورد علاقه تعلق گرفته است. این تعلق بر مبنای بزرگترین احتمال در ستونهای EST2 ،EST1 و EST3 است. به عنوان مثال برای همان فرد دهم بیشترین احتمال عدد 38% مربوط به هنر بوده است. به همین دلیل این فرد بر مبنای مدل رگرسیون لجستیک چند جمله ای در گروه هنر قرار گرفته است.
به دست آمده است. بر مبنای این ستون، هر فرد به یک موضوع مورد علاقه تعلق گرفته است. این تعلق بر مبنای بزرگترین احتمال در ستونهای EST2 ،EST1 و EST3 است. به عنوان مثال برای همان فرد دهم بیشترین احتمال عدد 38% مربوط به هنر بوده است. به همین دلیل این فرد بر مبنای مدل رگرسیون لجستیک چند جمله ای در گروه هنر قرار گرفته است.
PCP ستون دیگر در فایل دیتا است. نتایج این ستون نیز به دلیل انتخاب گزینه Predicted category probability به دست آمدهاند. چنانچه دقت کنید دادههای این ستون همان بزرگترین عدد در ستونهای EST2 ،EST1 و EST3 است. به عبارت دیگر اعداد این ستون را میتوان، احتمال قرار گرفتن هر فرد در ستون PRE دانست.
در نهایت در فایل دیتا ستون ACP قرار دارد. نتایج این ستون به دلیل انتخاب گزینه Actual category probability به دست آمدهاند. فهم آن نیز بسیار ساده است. اعداد این ستون احتمال قرار گرفتن هر فرد در موضوع مورد علاقه واقعی و مشاهده شده یعنی همان موضوعی که خود دانشآموز بیان کرده است را نشان میدهد. به عنوان مثال فرد شماره هشت، به ریاضیات علاقه دارد. این مطلب از ستون Subject مشخص میشود. حال بر مبنای مدل چند جمله ای به دست میآید که احتمال اینکه این فرد علاقمند به ریاضی باشد برابر با 26% است.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2021). Multinomial Logistic Regression in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/multinomial-logistic-regression-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2021). Multinomial Logistic Regression in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/multinomial-logistic-regression-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.