پیش فرض های انجام تحلیل و آنالیز کوواریانس
در تحلیل آماری استنباطی مفهوم آنالیز کوواریانس Analysis of Covariance یا همان ANCOVA وجود دارد که به حذف اثرات کمیتهای مداخله گر Intervener Variables به منظور بیان نتایج با دقت بیشتر، میپردازد. در واقع آنکوا ANCOVA مدل تعمیم یافته آنوا ANOVA و همچنین مدلهای رگرسیونی است.
آنالیز کوواریانس مدل پیشرفتهتر آنالیز واریانس میباشد، هنگامی که از تحلیلهای رگرسیونی نیز استفاده میکنیم. تحلیل کوواریانس مناسبترین آزمون و روش آماری برای طرح پیش آزمون و پس آزمون دو گروهی میباشد. چنانچه به موضوعات و روشهای مختلف تحلیل کوواریانس علاقمند هستید، خوب است این لینک را ببینید. (انواع آنالیز کوواریانس را به خوبی یاد بگیریم.)

آنچه میخواهم در این مقاله صحبت کنم، پیشفرضهای انجام تحلیل کوواریانس است. در واقع ارایه آنالیز کوواریانس، نیاز به برقراری و تایید تعدادی پیشفرض در دادهها دارد. هنگامی که تصمیم میگیریم دادههای خود را با استفاده از ANCOVA تحلیل کنیم، باید مطمئن شویم که دادهها واقعاً میتوانند با استفاده از آنالیز کوواریانس تحلیل شوند و از 9 پیش فرضی که جهت ارایه یک نتیجه معتبر لازم است، تایید میگیرند.
بررسی این پیش فرضها کمی زمان بیشتری به آنالیز میافزایند و از شما میخواهند هنگام بررسی تنظیمات و تحلیل دادهها، روی چند دکمه دیگر در SPSS کلیک کنید و کمی بیشتر در مورد دادههای خود فکر کنید، نگران نباشید، کار سختی نیست.
قبل از اینکه شما را با این 9 فرض آشنا کنیم، تعجب نکنید اگر هنگام تحلیل دادههای خود با استفاده از SPSS، یک یا چند مورد از این فرضیات نقض شد (برآورده نشود). در واقع هنگامی که با دادههای دنیای واقعی کار میکنیم، (به جای نمونههای کتاب درسی، که به شما نشان میدهند چگونه یک آنالیز کوواریانس را زمانی که همه چیز خوب پیش میرود، انجام دهید.) این اتفاق عادی است و برای همه رخ میدهد. با این حال، نگران نباشید. حتی اگر دادههای شما برخی از پیش فرضها را تایید نکند، معمولاً راهی برای آن وجود دارد.
پیشفرضهای آنالیز کوواریانس
Assumptions
ابتدا، اجازه دهید نگاهی به این 9 فرض بیندازیم. دربارهی هر کدام از آنها توضیح خواهیم داد. من بررسی پیشفرضها را استفاده از یک مثال که در تحلیل آنالیز کوواریانس از آن استفاده کردیم، انجام میأهیم. از اینجا میتوانید فایل این مثال را دریافت کنید. آموزش آنالیز کوواریانس را نیز میتوانید از این لینک ببینید. (آنالیز کوواریانس ANCOVA با نرمافزار SPSS)
پیشفرض 1
کمیت وابسته Dependent Variable و کمکی Covariate باید در مقیاس پیوسته Scale اندازهگیری شوند. به عنوان مثال زمان تجدیدنظر (برحسب ساعت)، هوش (با استفاده از نمره IQ)، عملکرد امتحان (از 0 تا 100)، وزن (برحسب کیلوگرم) و غیره. میتوانید کمیتهای کمکی طبقهای داشته باشید به عنوان مثال، جنس و یا تحصیلات، با این حال به این نکته توجه کنید که در این صورت تحلیل به عنوان آنالیز کوواریانس گفته نمیشود.
پیشفرض 2
کمیت مستقل Independent Variable باید از دو یا چند گروه طبقهبندی شده مستقل تشکیل شده باشد. به عنوان مثال جنسیت، سطح فعالیت بدنی (مثلاً چهار گروه کم تحرک، کم، متوسط و بالا)، حرفه و شغل (پنج گروه جراح، پزشک، پرستار، دندانپزشک، درمانگر)،
پیشفرض 3
مشاهدات و افراد باید از یکدیگر مستقل باشند. به عنوان مثال، در هر گروه باید افراد متفاوتی وجود داشته باشد و هیچ فردی در بیش از یک گروه نباشد. البته این مطلب بیشتر به نحوه طراحی مطالعه مربوط است، با این حال یک فرض مهم برای آنالیز کوواریانس است. اگر این فرض در مطالعه شما تایید نشود، باید به جای آزمون کوواریانس، از آزمون آماری دیگری مانند طرح اندازه گیری مکرر Repeated Measure استفاده کنید.
پیشفرض 4
هیچ نقطه پرت Outlier Data معناداری نباید وجود داشته باشد. به عنوان مثال، در یک مطالعه بر روی 100 نفر، میانگین نمره هوش دانش آموزان 108 شده است. حال یک دانش آموز امتیاز 156 داشته است، که بسیار غیرمعمول است و حتی ممکن است او را در 1٪ نمرات برتر IQ در سطح جهان قرار دهد. ما به این نمره، داده پرت میگوییم. مشکل دادههای پرت این است که میتوانند تأثیر منفی بر نتایج آنالیز کوواریانس داشته باشند و اعتبار نتایج را کاهش دهند. با استفاده از رسم نمودارهای جعبهای که آموزش آن را میتوانید در این لینک ببینید (رسم Box Plot با استفاده از نرمافزار SPSS) میتوانیم به شناسایی و یافتن دادههای پرت، اقدام کنیم. در این زمینه میتوانید این آموزش را هم ببینید. (تشخیص داده پرت با استفاده از Grubbs’ Test در Minitab)
پیشفرض 5
باقیماندهها یا همان Residuals باید برای هر دسته از کمیتهای مستقل به طور تقریبی نرمال باشند(Approximately Normally). در اینجا یک نکته بسیار مهم وجود دارد. آنالیز کوواریانس نسبت به نقض شدن فرض نرمال بودن باقیماندهها اصطلاحا استوار Robust است. به این معنی که این فرض میتواند تا حدی نقض شود و همچنان آنالیز کوواریانس نتایج معتبری ارایه دهد.
سوال شاید سوال کنید در یک تحلیل کوواریانس، باقیماندههای مدل را از کجا میتوانم به دست بیاورم. در این زمینه میتوانید این لینک را ببینید. (چگونه آنالیز کوواریانس را با نرمافزار SPSS انجام دهم؟) با این حال در ادامه در این زمینه صحبت میکنیم و روش به دست آوردن باقیماندههای مدل کوواریانس را بیان میکنیم.
هنگامی که میخواهیم با استفاده از پنجره Univariate و یا Multivariate آنالیز کوواریانس انجام دهیم، تب Save وجود دارد. در تب Save پنجره با نام Univariate Save برای ما باز میشود.

در این پنجره گزینههای Unstandardized برای Predicted Value و Residuals را انتخاب میکنیم. با استفاده از این گزینهها میتوانیم به ازای هر فرد، عدد براورد شده برای Dependent Variable و همچنین مقدار خطای براورد را مشاهده کنیم. در کادر Residuals خوب است گزینه Standardized را هم انتخاب کنیم. با استفاده از آنها میتوانیم پیشفرضهای انجام آنالیز کوواریانس را بررسی کنیم. این یافتهها به عنوان یک ستون جدید به فایل دیتا اضافه میشود. در تصویر زیر میتوانید آنها را ببینید.
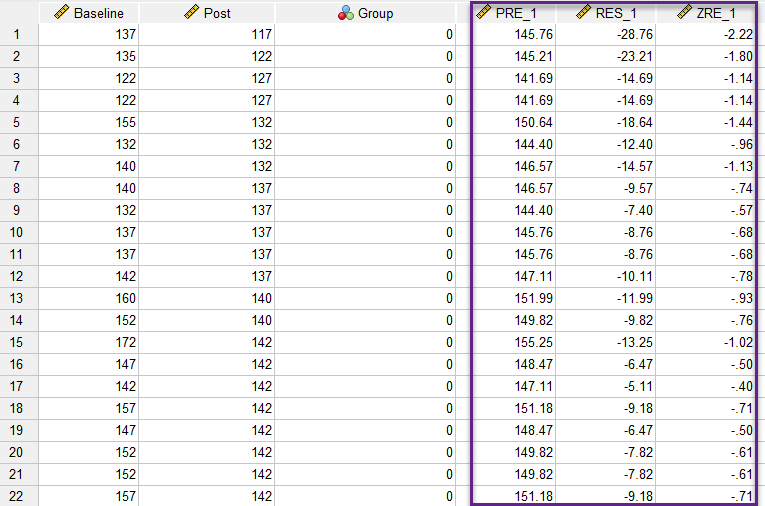
همانگونه که در تصویر بالا میبینید، ستونهای PRE عدد براورد شده برای Dependent Variable و همچنین RES یعنی مقدار خطای براورد که به آن باقیمانده گفته میشود را مشاهده کنیم. ستون ZRE هم همان باقیماندههای استاندارد شده است.
بر مبنای پیشفرض شماره پنج آنالیز کوواریانس باید ستون RES در هر کدام از گروههای Case و Control مثالا بالا، دارای توزیع نرمال باشد. در این زمینه و روش بررسی نرمال بودن دادهها این لینک را ببینید. (آزمون نرمال بودن دادهها Normality Test در نرمافزار SPSS)
پیشفرض 6
همگن بودن واریانس باقیماندههای مدل، یکی دیگر از پیشفرضهای تحلیل کوواریانس است. با استفاده از آزمون Levene میتوانید همگنی واریانس باقیماندهها را آزمایش کنید. جهت به دست آوردن این نتیجه هنگامی که میخواهیم با استفاده از پنجره Univariate و یا Multivariate آنالیز کوواریانس انجام دهیم، وارد تب Options میشویم. در این تب گزینه Homogeneity tests را انتخاب میکنیم.
با انتخاب گزینه Homogeneity tests در خروجی نتایج، جدول زیر برای ما به دست میآید. در جدول Levene’s Test of Equality of Error Variances آزمون لوین به منظور بررسی همگن بودن واریانس باقیماندههای مدل، آمده است. به عنوان مثال نتیجه به دست آمده نشان میدهد واریانس خطاها، همگن است (P-value = 0.362).

پیشفرض 7
پیش فرض شماره 7 میگوید Covariate باید به صورت خطی با کمیت وابسته DV در هر سطح از کمیت مستقل IV همبستگی داشته باشد. میتوانید این فرض را در SPSS با رسم نمودار پراکنش گروهی بین Covariate، اندازههای پس آزمون کمیت وابسته بر مبنای هر کدام از سطوح کمیت مستقل آزمایش کنید. جهت رسم انواع نمودارهای پراکنش میتوانید این لینک را ببینید. (رسم نمودارهای پراکنش با استفاده از نرمافزار SPSS)
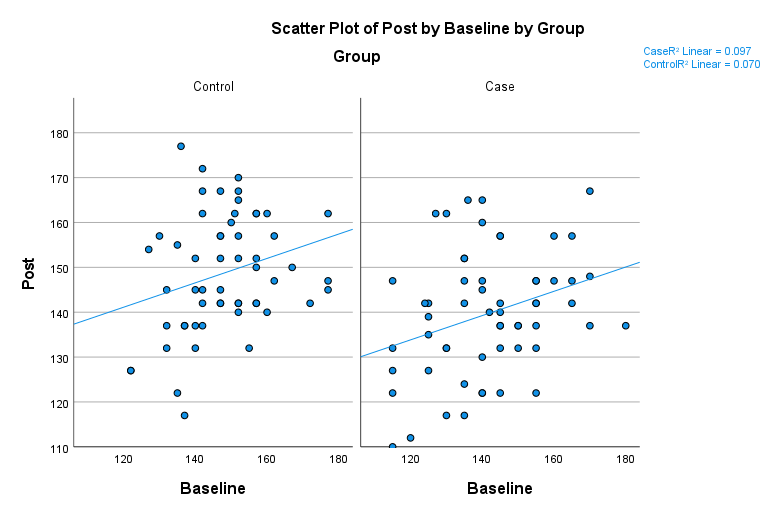
به عنوان مثال من نمودار پراکنش گروهی بین Covariate که در این مثال فشار خون قبل افراد بود و فشار خون بعد که به عنوان کمیت وابسته، مطرح بود بر مبنای هر کدام از سطوح کمیت مستقل (گروههای Case و Control) رسم کردهام.
همانگونه که در نمودار بالا میتوانید مشاهده کنید، همبستگی بین Covariate و DV هم در گروه Case و هم در گروه Control (سطوح مختلف IV) دیده میشود.
پیشفرض 8
یکی دیگر از پیشفرضهای انجام تحلیل کوواریانس برقرار بودن مفهومی به اسم هم واریانسی و یا Homoscedasticity است. در این زمینه توصیه میکنم حتماً مقاله آزمونهای ناهم واریانسی Heteroscedasticity Tests در نرم افزار SPSS را مطالعه کنید.
هم واریانسی به این معنا است که باید خطای مدل که به آن Residual و باقیمانده هم گفته میشود، دارای ثبات در واریانس باشد. مفهوم ثبات در واریانس هم به معنای این است که خطاهای مدل نباید با مقادیر عددی Independent Variable یا همان کمیتهای مستقل، مرتبط و وابسته باشند.
جهت بررسی فرضیه هم واریانسی و یا ناهم واریانسی Heteroscedasticity در نرمافزار SPSS چندین روش و آزمون آماری قرار گرفته است. جهت انجام این آزمونها، هنگامی که میخواهیم با استفاده از پنجره Univariate و یا Multivariate آنالیز کوواریانس انجام دهیم، وارد تب Options میشویم. در این تب کادر Heteroscedasticity Tests وجود دارد.
متداولترین آزمونهای بررسی ناهم واریانسی با نام بروش-پاگان Breusch-Pagan و آزمون وایت White’s tests شناخته میشوند. نرمافزار SPSS آزمونهای دیگری با نام F test و Modified Breusch-Pagan test را نیز انجام میدهد. من همه آنها را انتخاب کردهام. با Continue و سپس OK کردن میتوانید نتایج و خروجیهای نرمافزار SPSS را مشاهده کنید. من در تصویر زیر نتایج هر چهار آزمون ناهم واریانسی را آوردهام.

نتایج به دست آمده در هر چهار آزمون یعنی وایت، بروش-پاگان، آزمون F و بروش-پاگان اصلاح شده، بیانگر تایید فرض هم واریانسی باقیماندههای مدل آنالیز کوواریانس در این مثال ما است.
به عنوان مثال من در لینک زیر نمودار پراکنش بین باقیماندهها و مقادیر برازش شده Dependent Variable توسط مدل آنالیز کوواریانس را به دست آوردم. درباره نحوه به دست آوردن باقیمانده و یا مقادیر برازش شده در یک مدل انالیز کوواریانس، مطلب آنالیز کوواریانس ANCOVA با نرمافزار SPSS را ببینید. جهت رسم نمودار پراکنش نیز مقاله رسم نمودار پراکنش Scatter Plot با استفاده از نرمافزار SPSS را مشاهده کنید.
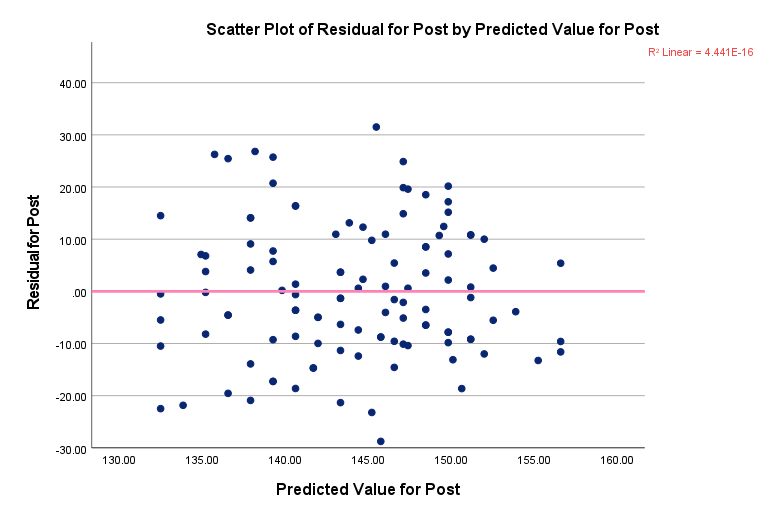
همانگونه که در گراف پراکنش بالا مشاهده میکنید بین اندازههای براورد شده و باقیمانده هیچگونه رابطهای دیده نمیشود و باقیماندهها به صورت تصادفی دز اطراف خط رگرسیونی قرار گرفتهاند.
به این اتفاق هم واریانسی یا همان Homoscedasticity گفته میشود و به معنای این است که باقیمانده و یا همان Residual ها از ثبات واریانس برقرار است. همان گونه که بیان کردم، این مطلب یکی از پیشفرضهای انجام آنالیز کوواریانس است.
پیشفرض 9
آخرین پیش فرض جهت انجام تحلیل کوواریانس، همگنی شیبهای رگرسیونی است، به این معنی که هیچ اثر متقابلی بین Covariate و Independent Variable وجود نداشته باشد و Interaction بین آنها معنادار نباشد. بهطور پیشفرض، SPSS عبارت تعاملی یا همان اثر متقابل بین Covariate و Independent Variable را در روش GLM به دست نمیدهد تا بتوان اثر آن را بر روی Dependent Variable آزمون کرد. آن را آزمایش کنید. بنابراین، لازم است در تنظیمات نرمافزار کمی دخالت کنیم.
جهت بررسی اثر متقابل بین Covariate و Independent Variable، هنگامی که میخواهیم با استفاده از پنجره Univariate و یا Multivariate آنالیز کوواریانس انجام دهیم، وارد تب Model میشویم. در این صورت پنجره زیر با نام Univariate Model برای ما باز میشود.
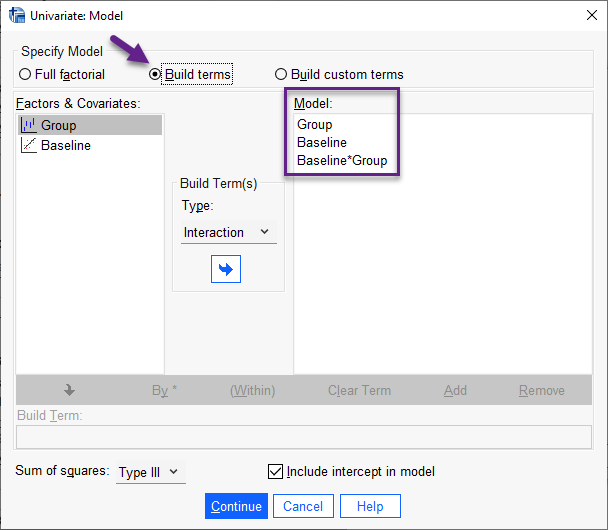
در این پنجره و از کادر Specify Model گزینه Build terms را انتخاب میکنیم. در کادر Factors & Covariates کمیتهای Group و Baseline قرار دارند. ما آنها را با استفاده از کادر وسط Build Term(s) و گزینه Main effects به کادر Model انتقال میدهیم. اثر متقابل بین Group و Baseline را نیز با استفاده از گزینه Interaction به کادر Model انتقال میدهیم. به این ترتیب علاوه بر بررسی اثرات اصلی یعنی Group و Baseline، اثر متقابل بین آنها یعنی Group*Baseline نیز بررسی خواهد شد.
در جدول زیر اثر متقابل بین Group*Baseline آمده است.
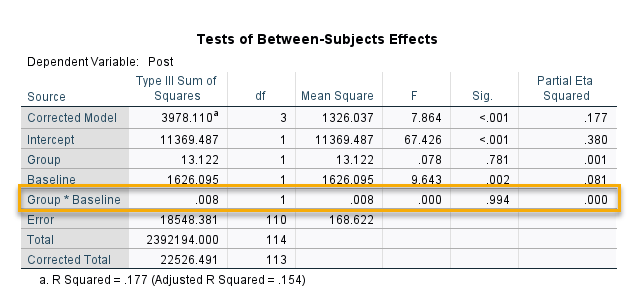
همانگونه که میبینید، اثر متقابل معنادار نیست و بنابراین فرضیه عدم معناداری اثر متقابل بین Covariate و Independent Variable تایید میشود.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Assumptions of analysis of covariance. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/ancova-assumptions/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Assumptions of analysis of covariance. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/ancova-assumptions/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.