تحلیل الگوها Analyze Patterns در جانهی چندگانه (Multiple Imputation)
Analyze Patterns – Multiple Imputation
هنگامی که میخواهیم به تحلیل الگوها Analyze Patterns بپردازیم، لازم است ابتدا دربارهی Multiple Imputation که اصطلاحاً به آن جانهی چندگانه میگوییم، صحبت کنیم. ابزار کار ما در این مقاله نرمافزار SPSS خواهد بود و با استفاده از این نرمافزار به بیان مطلب میپردازیم. خب، ابتدا بیایید ببینیم Multiple Imputation چیست و چه کاربردی دارد.

جانهی چندگانه یا Multiple Imputation روش و ابزاری است که به ما امکان میدهد بتوانیم به جای دادههای گمشده مطالعه خود، بهترین مقادیر ممکن را جایگزاری کنیم. البته به این شرط که بخواهیم دادههای گمشده خود را با اعداد واقعی جانهی کنیم. اگر هدف ما گزارش حجم و تعداد دادههای گمشده نیز باشد، خب لازم نیست از این روش و یا هر روش جایگزین دیگری استفاده کنیم.
هدف از جانهی چندگانه، جایگزاری مقادیر ممکن برای دادههای گمشده Missing Value است. هنگامی که با نرمافزار SPSS این کار را انجام میدهیم، نرمافزار چندین مجموعه “کامل” از دادهها را ایجاد میکند. در این دادههای کامل، مقادیر گمشده با روشهای مناسب جایگزاری شده و یافتههای توصیفی از آنچه رخ داده است، به ما نمایش داده میشود.
خوب است بدانیم تحلیل Multiple Imputation بر روی انواع دادهها انجام میشود. در این تحلیل، دادهها میتوانند به صورتهای زیر باشند.
- دادههای اسمی Nominal
هنگامی میتوان یک کمیت Variable را از نوع اسمی در نظر گرفت که چهار عمل اصلی ریاضی یعنی جمع، منها، ضرب و تقسیم بر روی آن قابل اعمال نباشد. همچنین دادهها دارای ترتیب و کمتر و بیشتر بودن نیز نباشند. مثالهایی از این نوع میتوانند دادههای جنسیت، واحدهای مختلف بیمارستان، نژاد و تنوع مذهبی باشد.
- دادههای ترتیبی Ordinal
چنانچه نتوان چهار عمل اصلی ریاضی یعنی جمع، منها، ضرب و تقسیم را بر روی دادهها در نظر گرفت، با این حال آنها دارای ترتیب، رتبه و ماهیت کمتر و بیشتر بودن باشند، آنها را از نوع دادههای ترتیبی میدانیم. مثالهایی از این نوع میتوانند دادههای سطوح مختلف رضایت، انواع طیفهای لیکرت در پرسشنامهها و رتبههای تحصیلی باشد.
- دادههای عددی Scale
دادههایی که چهار عمل اصلی ریاضی بر روی قابل انجام است و در نتیجه دارای ماهیت کمتر و بیشتر بودن نیز هستند، در رده دادههای از نوع عددی Scale قرار میگیرند. این دادهها با یک متریک و ابزار سنجش معنادار، قابل اندازهگیری هستند. مثالهایی از این نوع میتوانند دادههای سن، درآمد، بیان ژن، غلظتهای مختلف یک دارو و میزان پاسخ به آنها باشد.
یک نکته مهم در Multiple Imputation این است که این آنالیز نه فقط بر روی دادههای عددی Scale بلکه بر روی دادههای اسمی و ترتیبی نیز قابل انجام است. بنابراین چنانچه دادههایی داریم که مثلاً اسمی هستند (به عنوان مثال جنسیت) و یا ترتیبی هستند (به عنوان مثال پاسخ به میزان رضایت از یک واحد شغلی) و برخی از آنها را به هر دلیلی در اختیار نداریم به خوبی میتوانیم جهت جانهی دادهها از این روش و ابزارهای موجود در آن استفاده کنیم.
در تصویر زیر میتوانید نحوه نمایش انواع مختلف دادهها در نرمافزار SPSS را مشاهده کنید.
هنگامی که با نرمافزار SPSS کار میکنیم، تحلیلهای Multiple Imputation شامل دو ماژول و منو جداگانه است. در تصویر زیر میتوانید آنها را ببینید.

یکی از آنها با نام Analyze Patterns و دیگری با نام Impute Missing Data Values. در این مقاله به عنوان Analyze Patterns خواهیم پرداخت. در این لینک میتوانید دربارهی Impute Missing Data Values چیزهای بیشتری ببینید.
تحلیل الگوها
Analyze Patterns
از مسیر زیر در نرمافزار SPSS جهت تحلیل الگوهای دادههای گمشده استفاده میکنیم.
Analyze → Multiple Imputation → Analyze Patterns
در این صورت پنجره زیر با نام Analyze Patterns برای ما باز میشود.
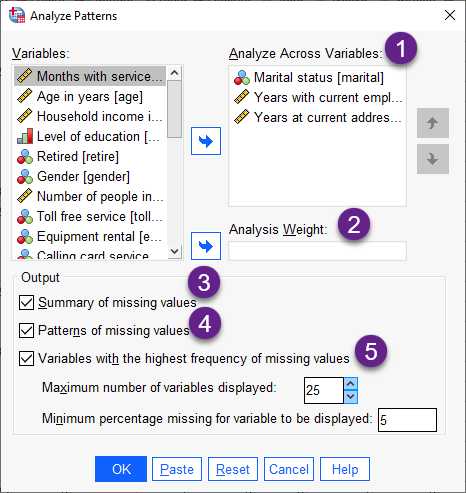
من پنجره بالا را شمارهگزاری کردهام و در ادامه به ترتیب شمارهها به توضیح هر بخش میپردازم. خروجی نرمافزار مربوط به هر بخش نیز بیان شده است.
1 در کادر Analyze Across Variables کمیتهایی را که میخواهید الگوهای دادههای گمشده را برای آنها انجام دهید، قرار دهید. به عنوان مثال من میخواهم برای کمیتهای marital، employ و address تحلیل الگوهای گمشده انجام دهم.
2 چنانچه در فایل دیتا، Variable وزندهی کننده وجود داشته باشد، آن را در کادر Analysis Weight قرار میدهیم.
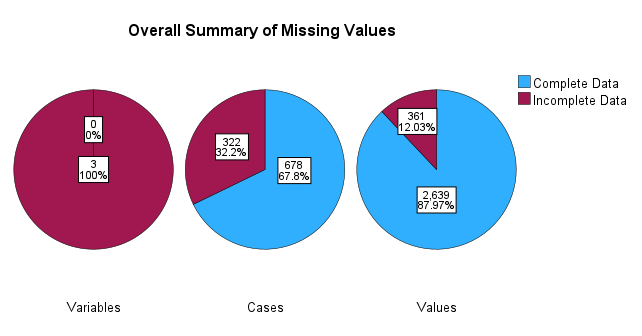
3 در این بخش دربارهی خروجیها و نتایج تحلیل، چندین گزینه قرار گرفته است. انتخاب گزینهی Summary of missing values سبب میشود چند نمودار دایرهای که بیانگر تعداد و درصد کمیتهای موجود در تحلیل و همچنین دادههای گمشده است، برای ما نشان داده شود.
در تصویر زیر میتوانید خروجی نرمافزار SPSS در این مثال را مشاهده کنید.
همانگونه که در گراف بالا دیده میشود از بین سه کمیت انتخاب شده، هر سه اصطلاحاً Incomplete Data یعنی دارای داده گمشده هستند. نمودار دایرهای با عنوان Cases نشان میدهد از مجموع 1000 فرد مورد بررسی، 322 نفر دارای حداقل یک داده گمشده در یکی از سه Variable مورد بررسی بودهاند. به همین ترتیب برای 678 نفر داده گمشدهای ثبت نشده است.
نمودار دایرهای Values بیان میکند تمام دادههای (خانههای فایل دیتا) موجود در این سه Variable برابر با 3000 خانه بوده است (سه کمیت بر روی 1000 نفر). از این تعداد، 361 خانه دارای مقدار گمشده بوده است. این عدد نشان میدهد برخی افراد مورد بررسی دارای بیش از یک عدد گمشده در این سه کمیت بودهاند. همچنین برای 2639 خانه نیز مقدار عددی واقعی در فایل دیتا مشاهده شده است.
4 انتخاب گزینه Patterns of missing values باعث میشود الگوهای جدولبندی شده دادههای گمشده نمایش داده شود. هر الگو که به آن Pattern گفته میشود، مربوط به گروهی از افراد (Cases) با الگوی یکسان دادههای ناقص و کامل در کمیتهای تحلیل است.
ابتدا بیایید گراف به دست آمده از این گزینه، در خروجیهای نرمافزار را ببینیم. در ادامه دربارهی آن صحبت میکنیم.
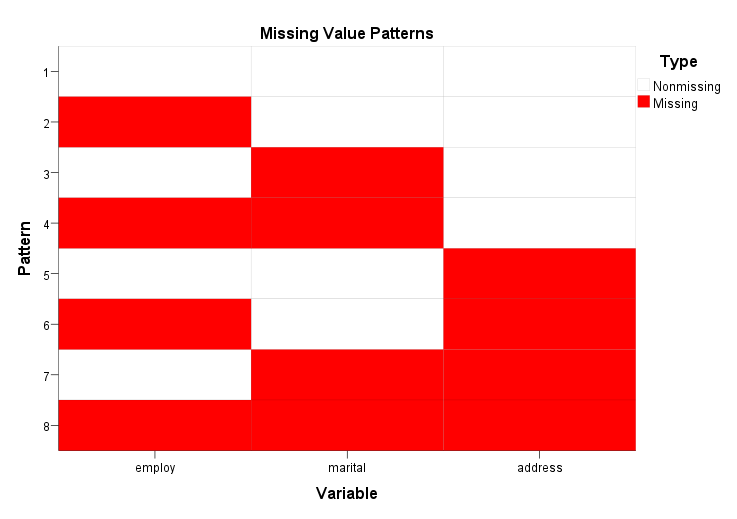
ما در این گراف تعداد 8 الگو یا همان Pattern داریم. پاسخ به این سوال ساده است که چرا 8 الگو؟ پاسخ این است وقتی که سه کمیت (marital، employ و address) داریم، طبیعی است که هشت الگو داشته باشیم. بیایید آنها را بشماریم.
1- الگو شماره 1 شامل افرادی در هر سه کمیت است که فاقد داده گمشده هستند.
2- الگو شماره 2 افرادی هستند که فقط در کمیت employ داده گمشده دارند و در سایر کمیتها دادهها کامل هستند.
3- الگو شماره 3 افرادی هستند که فقط در کمیت marital داده گمشده دارند و در سایر کمیتها دادهها کامل هستند.
4- الگو شماره 4 افرادی هستند که در کمیتهای employ و marital داده گمشده دارند و در کمیت address دادهها کامل هستند.
5- الگو شماره 5 افرادی هستند که فقط در کمیت address داده گمشده دارند و در سایر کمیتها دادهها کامل هستند.
6- الگو شماره 6 افرادی هستند که در کمیتهای employ و address داده گمشده دارند و در کمیت marital دادهها کامل هستند.
7- الگو شماره 7 افرادی هستند که در کمیتهای marital و address داده گمشده دارند و در کمیت employ دادهها کامل هستند.
8- الگو شماره 8 نیز افرادی هستند که در هر سه کمیت marital، employ و address داده گمشده دارند.
شاید اگر از من بپرسید میگویم رسم این گراف توسط SPSS یک چیز اضافی است و مطلب خاصی برای ما ندارد. ما به طور طبیعی میدانیم بر مبنای تعداد کمیتهایی که در آنالیز قرار میدهیم، تعداد مشخصی الگو دریافت خواهیم کرد. در واقع نرمافزار SPSS میتوانست به جای این گراف رنگی، صرفاً یک جدول سادهتر که بیانگر تعریف هر الگو است، ارایه دهد.
با این حال نمودار ستونی که بعد از این گراف رنگی در خروجیهای نرمافزار قرار دارد، برای ما مفیدتر و کاربردیتر خواهد بود. آن را ببینید.
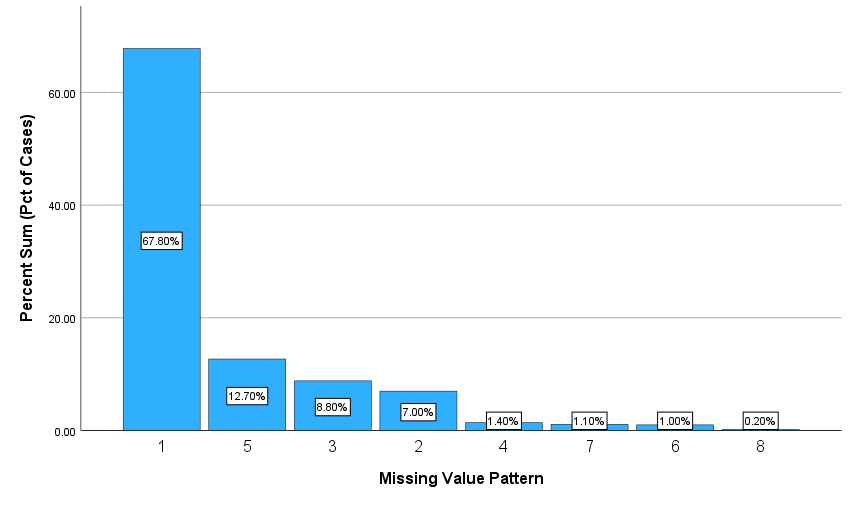
نمودار ستونی بالا به ما نشان میدهد هر کدام از الگوهای هشت گانه که در بالا نام بردم، چه حجم و درصدی از افراد را در بر میگیرد. به عنوان مثال این نمودار ستونی نشان میدهد، 67.8% افراد در الگوی شماره 1 (هیچکدام از آنها دارای داده گمشده در سه کمیت نیستند) قرار میگیرند.
به همین ترتیب نشان داده میشود که 12.7% افراد در الگوی شماره 5 (فقط در کمیت address داده گمشده دارند و در سایر کمیتها دادهها کامل هستند) قرار میگیرند. نمودار ستونی همچنین نشان میدهد 0.2% افراد در هر سه کمیت دارای داده گمشده هستند (الگوی شماره 8).
بنابراین گراف بالا به صورت کاربردی و مفید به ما نشان میدهد فراوانی هر کدام از الگوها به چه تعداد است. این مطلب به ما در مقاله بعدی که به موضوع نحوه جانهی و قرار دادن دادههای گمشده با نام Impute Missing Data Values میپردازد، کمک میکند.
5 انتخاب گزینه Variables with the highest frequency of missing values سبب میشود در خروجیهای نرمافزار جدولی با نام Variable Summary قرار گیرد. ابتدا بیایید این جدول را ببینیم تا بتوان دربارهی این گزینه در تنظیمات نرمافزار صحبت کرد.
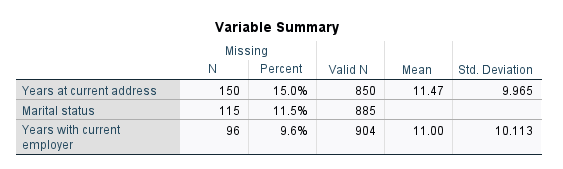
در این جدول میتوانید تعداد و درصد دادههای گمشده و همچنین تعداد دادههای موجود و صحیح را مشاهده کنید. جدول همیشه به ترتیب از کمیت با بیشترین درصد دادههای گمشده تا کمترین دادههای گمشده مرتب میشود. به عنوان مثال جدول Variable Summary بالا نشان میدهد در کمیت address تعداد 150 داده گمشده (15%) و 850 داده صحیح وجود دارد. به همین ترتیب در کمیت employ تعداد 96 داده گمشده (9.6%) و 904 داده صحیح دیده میشود.
برای کمیتهایی که عددی یعنی Scale هستند، نرمافزار SPSS آمارههای توصیفی شامل میانگین و انحراف معیار دادههای موجود صحیح را نیز ارایه میکند. به عنوان مثال برای کمیت address میانگین و انحراف معیار دادههای موجود (850 نفر) به ترتیب برابر با 11.47 و 9.965 به دست آمده است.
حال که متوجه شدیم این جدول چیست، درک تنظیمات نرمافزار SPSS در گزینهی با نام Variables with the highest frequency of missing values ساده خواهد بود.
گزینهی Maximum number of variables displayed به ما میگوید بیشترین تعداد کمیتهایی که در جدول Variable Summary نمایش داده شوند، چه تعداد باشد. به عنوان مثال وقتی در اینجا عدد 25 نوشته شده است، یعنی یافتههای مربوط به حداکثر 25 کمیت در جدول Variable Summary نشان داده شوند.
گزینهی Minimum percentage missing for variable to be displayed حداقل درصد دادههای گمشده در یک Variable چقدر باشد تا آن کمیت در جدول Variable Summary نمایش داده شود. به عنوان مثال وقتی در این گزینه عدد 5 نوشته میشود به معنای آن است که کمیتهای با حداقل 5 درصد داده گمشده در جدول Variable Summary بیایند. بنابراین اگر در یک کمیت مثلاً 3-4 درصد دادهها گمشده باشند، این کمیت در جدول Variable Summary نمایش داده نمیشود.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2023). Analyze Patterns in Multiple Imputation Studies. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/analyze-patterns-multiple-imputation-spss/.php
For example, if you viewed this guide on 12th January 2023, you would use the following reference
GraphPad Statistics (2023). Analyze Patterns in Multiple Imputation Studies. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/analyze-patterns-multiple-imputation-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.