جانهی دادههای گمشده Impute Missing Data Values
Impute Missing Data Values – Multiple Imputation
من در مقاله قبلی به موضوع تحلیل الگوها Analyze Patterns پرداختم. در این مقاله دربارهی Impute Missing Data Values در جانهی چندگانه (Multiple Imputation) که در آنالیز دادههای گمشده Missing Value استفاده میشود، صحبت میکنم. ابزار کار ما در این مقاله نرمافزار SPSS خواهد بود و با استفاده از این نرمافزار به بیان مطلب میپردازیم. خب، ابتدا بیایید ببینیم Multiple Imputation چیست و چه کاربردی دارد.

جانهی چندگانه یا Multiple Imputation روش و ابزاری است که به ما امکان میدهد بتوانیم به جای دادههای گمشده مطالعه خود، بهترین مقادیر ممکن را جایگزاری کنیم. البته به این شرط که بخواهیم دادههای گمشده خود را با اعداد واقعی جانهی کنیم. اگر هدف ما گزارش حجم و تعداد دادههای گمشده نیز باشد، خب لازم نیست از این روش و یا هر روش جایگزین دیگری استفاده کنیم.
هدف از جانهی چندگانه، جایگزاری مقادیر ممکن برای دادههای گمشده Missing Value است. هنگامی که با نرمافزار SPSS این کار را انجام میدهیم، نرمافزار چندین مجموعه “کامل” از دادهها را ایجاد میکند. در این دادههای کامل، مقادیر گمشده با روشهای مناسب جایگزاری شده و یافتههای توصیفی از آنچه رخ داده است، به ما نمایش داده میشود.
خوب است بدانیم تحلیل Multiple Imputation بر روی انواع دادهها انجام میشود. در این تحلیل، دادهها میتوانند به صورتهای زیر باشند.
- دادههای اسمی Nominal
هنگامی میتوان یک کمیت Variable را از نوع اسمی در نظر گرفت که چهار عمل اصلی ریاضی یعنی جمع، منها، ضرب و تقسیم بر روی آن قابل اعمال نباشد. همچنین دادهها دارای ترتیب و کمتر و بیشتر بودن نیز نباشند. مثالهایی از این نوع میتوانند دادههای جنسیت، واحدهای مختلف بیمارستان، نژاد و تنوع مذهبی باشد.
- دادههای ترتیبی Ordinal
چنانچه نتوان چهار عمل اصلی ریاضی یعنی جمع، منها، ضرب و تقسیم را بر روی دادهها در نظر گرفت، با این حال آنها دارای ترتیب، رتبه و ماهیت کمتر و بیشتر بودن باشند، آنها را از نوع دادههای ترتیبی میدانیم. مثالهایی از این نوع میتوانند دادههای سطوح مختلف رضایت، انواع طیفهای لیکرت در پرسشنامهها و رتبههای تحصیلی باشد.
- دادههای عددی Scale
دادههایی که چهار عمل اصلی ریاضی بر روی قابل انجام است و در نتیجه دارای ماهیت کمتر و بیشتر بودن نیز هستند، در رده دادههای از نوع عددی Scale قرار میگیرند. این دادهها با یک متریک و ابزار سنجش معنادار، قابل اندازهگیری هستند. مثالهایی از این نوع میتوانند دادههای سن، درآمد، بیان ژن، غلظتهای مختلف یک دارو و میزان پاسخ به آنها باشد.
یک نکته مهم در Multiple Imputation این است که این آنالیز نه فقط بر روی دادههای عددی Scale بلکه بر روی دادههای اسمی و ترتیبی نیز قابل انجام است. بنابراین چنانچه دادههایی داریم که مثلاً اسمی هستند (به عنوان مثال جنسیت) و یا ترتیبی هستند (به عنوان مثال پاسخ به میزان رضایت از یک واحد شغلی) و برخی از آنها را به هر دلیلی در اختیار نداریم به خوبی میتوانیم جهت جانهی دادهها از این روش و ابزارهای موجود در آن استفاده کنیم.
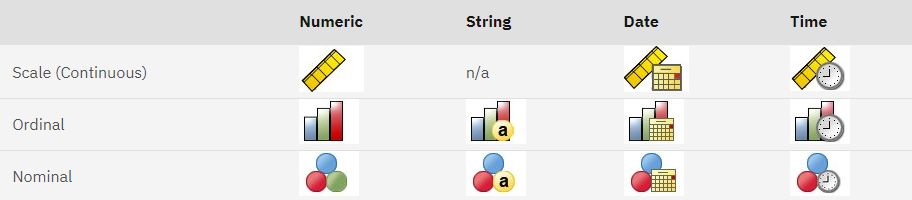
در تصویر زیر میتوانید نحوه نمایش انواع مختلف دادهها در نرمافزار SPSS را مشاهده کنید.
هنگامی که با نرمافزار SPSS کار میکنیم، تحلیلهای Multiple Imputation شامل دو ماژول و منو جداگانه است. در تصویر زیر میتوانید آنها را ببینید.

یکی از آنها با نام Analyze Patterns و دیگری با نام Impute Missing Data Values. همانگونه که بیان کردیم در این مقاله به موضوع Impute Missing Data Values خواهیم پرداخت.
مثال جانهی دادههای گمشده
Impute Missing Data Values Example
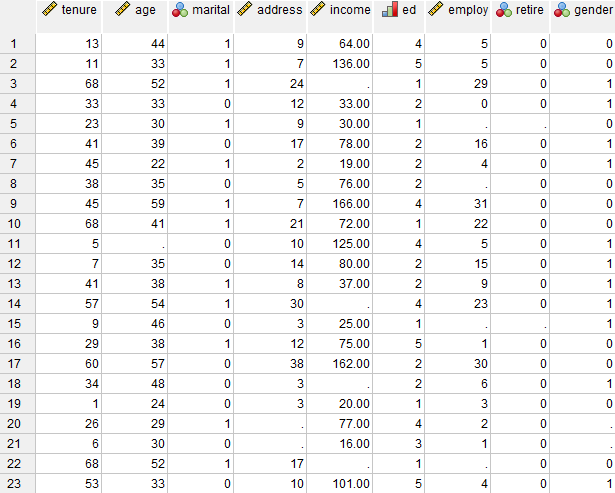
یک ارایهدهنده خدمات مخابراتی میخواهد الگوهای استفاده از خدمات را در پایگاه داده مشتریان خود بهتر درک کند. آنها دادههای کاملی از مشتریان خود دارند، اما اطلاعات جمعیتی جمعآوری شده توسط شرکت دارای تعدادی مقادیر گمشده است. در این مثال تحلیل الگوهای Analyze Patterns مقادیر از دست رفته، میتواند به تعیین مراحل بعدی جانهی، کمک کند. فایل مثال با نام Impute Missing Data Values را میتوانید از این لینک دریافت کنید. در تصویر زیر بخشی از فایل دیتا مثال را مشاهده میکنید.
از مسیر زیر در نرمافزار SPSS جهت تحلیل جانهی دادههای گمشده استفاده میکنیم.
Analyze → Multiple Imputation → Impute Missing Data Values
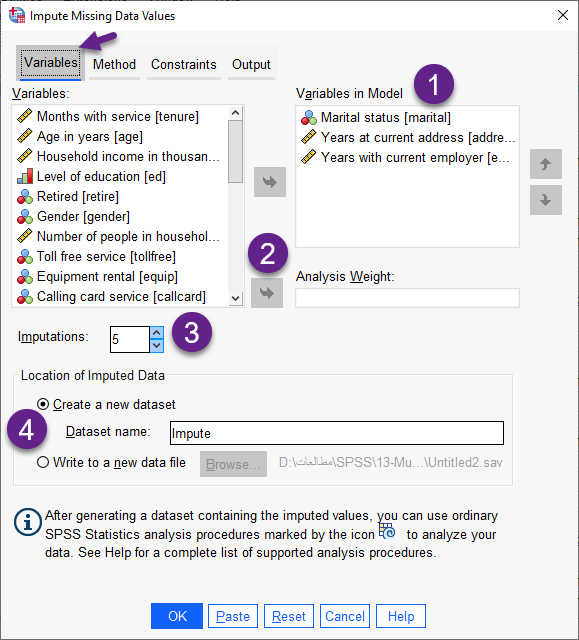
در این صورت پنجره زیر با نام Impute Missing Data Values برای ما باز میشود. این پنجره از تنظیمات نرمافزار دارای چندین تب است. از تب با نام Variables شروع میکنیم.
-
Variables
من پنجره بالا را شمارهگزاری کردهام و در ادامه به ترتیب شمارهها به توضیح هر بخش میپردازم.
1 در کادر Variables in Model کمیتهایی را که میخواهید جانهی دادههای گمشده را برای آنها انجام دهید، قرار دهید. به عنوان مثال من میخواهم برای کمیتهای marital، employ و address جایگزاری دادههای گمشده را انجام دهم.
2 چنانچه در فایل دیتا، Variable وزندهی کننده وجود داشته باشد، آن را در کادر Analysis Weight قرار میدهیم.
3 در این بخش تعداد جانهی و جایگزاریها را مشخص کنید. به صورت پیشفرض این عدد بر روی 5 قرار دارد. این کار باعث میشود، فرایند جایگزاری دادههای گمشده پنج بار تکرار شود.
4 هنگامی که با استفاده از SPSS و منوی Impute Missing Data Values کار میکنیم، نرمافزار یک فایل دیتا جدید شامل نتایج جایگزاری برای دادههای گمشده، میسازد. در این بخش نرمافزار از ما میخواهد که یک نام دلخواه برای این فایل دیتا جدید بنویسیم.
به عنوان مثال من میخواهم یک فایل دیتا جدید با نام Impute شامل دادههای گمشده و دادههای جایگزاری شده، ساخته شود.
با این حال چنانچه بخواهیم به جای ساختن یک فایل دیتا جدید، دادههای جانهی شده بر روی یک فایل از قبل وجود داشته، قرار بگیرند، گزینهی Write to a new data file را انتخاب میکنیم. با استفاده از دکمهی Browse میتوانیم فایل را از روی سیستم خود انتخاب کنیم.
تب بعدی تنظیمات نرمافزار با نام Method دیده میشود. با این حال به نظرم لازم است در ابتدا دربارهی مفهومی به نام الگوی دادههای گمشده Missing data pattern مطالعه کنید. علاقمند بودید مقاله آموزشی (الگوهای دادههای گمشده) در سایت گراف پد را مشاهده کنید.
-
Method
با استفاده از تب Method مشخص میکنیم که چگونه و با چه روشی دادههای گمشده، جایگزاری شوند. به صورت پیشفرض در این تب، گزینهی Automatic فعال است. من در ادامه سعی کردهام به بیان هر کدام از روشها بپردازم.
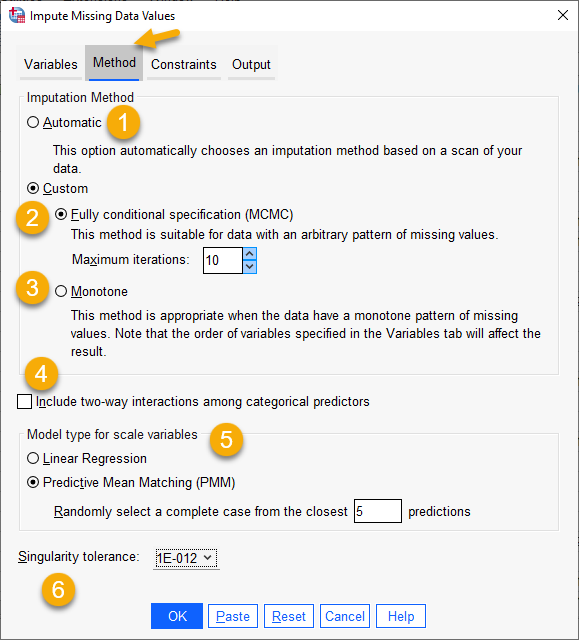
1 با انتخاب گزینهی Automatic، نرمافزار دادهها را اسکن میکند (به معنای فراخوانی فایل دیتا موجود) و اگر دادهها یک الگوی یکنواخت Monotone Pattern از مقادیر گم شده را نشان دهند از روش یکنواخت استفاده میکند. در غیر این صورت از روش مشخصات کاملا مشروط Fully Conditional Specification (FCS) استفاده میشود. اگر مطمئن هستید که از کدام روش میخواهید استفاده کنید، میتوانید گزینهی Custom را در ادامه انتخاب کنید.
2 گزینهی Fully conditional specification (MCMC) به معنای مشخصات کاملاً مشروط است. این یک روش تکراری زنجیره مارکوف مونت کارلو Markov chain Monte Carlo (MCMC) است که میتواند هنگامی که الگوی دادههای گمشده دلخواه است (یکنواخت یا غیر یکنواخت) استفاده شود.
به موضوع Fully Conditional Specification (FCS) علاقمند بودید، میتوانید این لینک را ببینید.
برای هر تکرار و برای هر کمیت، روش مشخصات کاملاً شرطی (FCS) Fully Conditional Specification یک مدل یک بعدی Univariate (به معنای یک کمیت وابسته) را با استفاده از کمیتهای موجود در مدل به عنوان پیشبینیکننده (Xها)، برازش میدهد. سپس مقادیر گمشده را برای مدل نسبت میدهد.
در اینجا یک کادر با نام حداکثر تکرار Maximum iterations که به صورت پیشفرض بر روی 10 قرار دارد، دیده میشود. این بخش تعداد تکرارها یا «گامها» را مشخص میکند که توسط زنجیره مارکوف استفاده شده توسط روش FCS انجام میشود. اگر روش FCS به طور خودکار انتخاب شده باشد، از تعداد پیش فرض 10 تکرار استفاده میکند. هنگامی که شما FCS را انتخاب میکنید، میتوانید تعداد تکرار دلخواه خود را مشخص کنید. چنانچه زنجیره مارکوف همگرا نشده باشد، ممکن است لازم باشد تعداد تکرارها را افزایش دهید. در تب Output که در ادامه به آن میپردازیم، میتوانید دادههای تاریخچه تکرار FCS را ذخیره کنید و آن را برای ارزیابی همگرایی ترسیم کنید.
3 در اینجا گزینهی Monotone دیده میشود. این یک روش غیر تکراری است که فقط زمانی میتوان از آن استفاده کرد که دادهها دارای الگوی یکنواخت مقادیر گم شده باشند.
یک الگوی یکنواخت زمانی وجود دارد که بتوانید کمیتها را به گونهای مرتب کنید که اگر کمیتی مقدار گم شده داشته باشد، همه کمیتهای بعدی نیز دارای مقادیر گم شده باشند. هنگام تعیین این روش به عنوان یک متد سفارشی، مطمئن شوید که Variableهای لیست را به ترتیبی مشخص کنید که یک الگوی یکنواخت را نشان دهد.
4 در اینجا گزینهی Include two-way interactions دیده میشود. هنگامی که روش جانهی خودکار انتخاب میشود، مدل جایگزاری برای هر کمیت شامل یک ضریب ثابت و اثرات اصلی برای Variableهای پیش بینی، خواهد بود. هنگام انتخاب این گزینه، از نرمافزار میخواهیم که همه اثرات متقابل دو طرفه را در بین کمیتهای پیشبینیکننده طبقهای categorical قرار دهد.
5 Model type for scale variables شامل دو گزینه به نامهای Linear Regression و Predictive Mean Matching (PMM) میباشد. این گزینه هنگامی استفاده میشود که کمیتهای دارای دادههای گمشده از نوع عددی Scale باشد.
انتخاب گزینهی Linear Regression سبب میشود هنگامی که روش جایگزاری Automatic انتخاب میشود، از رگرسیون خطی به عنوان مدل Univariate برای جانهی دادههای گمشده استفاده شود.
همچنین میتوانید گزینهی Predictive Mean Matching (PMM) را که به آن تطبیق میانگین پیشبینی کننده گفته میشود، به عنوان مدل جانهی برای Variable های عددی انتخاب کنید. PMM گونهای از رگرسیون خطی است که از قابل قبول بودن مقادیر جانهی شده اطمینان میدهد. برای PMM، عدد جایگزاری شده بر اساس مقدار تعریف شده از نزدیکترین (k) پیشبینی کننده کاملاً تصادفی است که در آن (k) یک عدد صحیح مثبت با مقدار پیش فرض 5 است.
به این نکته توجه کنید که رگرسیون لجستیک همیشه به عنوان مدل Univariate برای جایگزاری دادههای گمشده طبقهای استفاده میشود.
6 ماتریسهای منفرد (یا غیر معکوس)Singular Matrices دارای ستونهای خطی وابسته هستند که میتواند مشکلات جدی برای الگوریتم تخمین ایجاد کند. حتی ماتریسهای نزدیک به منفرد نیز میتوانند به نتایج ضعیفی منجر شوند، گزینهی Singularity tolerance که میتوان نام آن را تحمل تکینگی قرار داد، ماتریسی را که مقدار انتخاب شده برای آن کمتر از تحمل است به عنوان یک تکین در نظر میگیرد.
-
Constraints
تب بعدی در تنظیمات پنجره Impute Missing Data Values با نام محدودیتها Constraints دیده میشود. با استفاده از این تب میتوانیم دادهها را ارزیابی کنیم. نقش یک Variable را هنگام جانهی دادههای گمشده محدود کنیم. دامنه مقادیر قابل قبول برای یک کمیت عددی را محدود کنیم. همچنین میتوانیم تحلیل را به Variableهایی با کمتر از حداکثر درصد مقادیر گمشده تعیین شده، محدود کنیم. در ادامه بیایید بخشهای مختلف این تب را مرور کنیم.
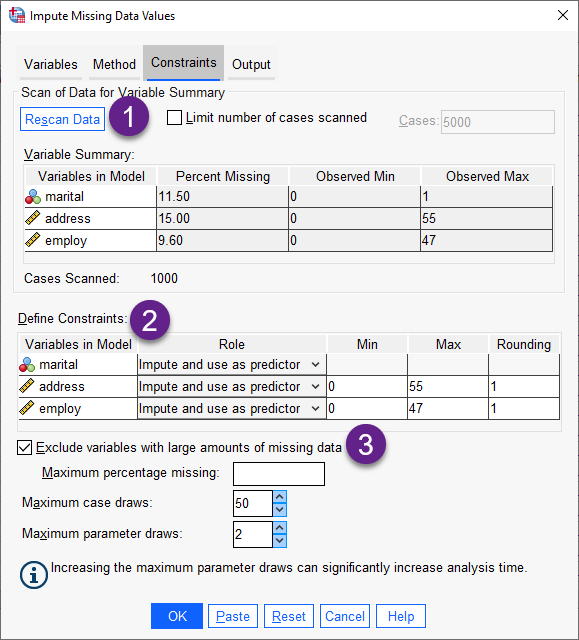
1 دکمه Scan Data به ما این امکان را میدهد که لیست کمیتهای انتخاب شده تحلیل، درصد دادههای گمشده شده، کمترین و بیشترین عدد مشاهده شده، به ازای هر کدام از کمیتها را نشان دهد. نتایج میتوانند بر اساس همه موارد یا محدود به اسکن n مورد اول، همانطور که در کادر متنی Cases مشخص شده است، باشد.
این یافته بسیار مهم و راهگشا است. به عنوان مثال هنگامی که بر روی دکمه Scan Data در این مثال میزنیم، متوجه میشویم کمیت marital دارای 11.5% داده گمشده است.
2 کادر با نام Define Constraints دیده میشود. در این کادر میتوانیم به ازای هر کمیت، محدودیتهای مدنظر خود را اعمال کنیم.
Role. این ستون به شما امکان میدهد تعیین کنید Variableهای قرار گرفته در تحلیل، به عنوان جانهی شده (و/یا) پیشبینیکننده در نظر گرفته شوند. خوب است این نکته را بدانیم که هر کمیت تحلیل، میتواند به عنوان یک وابسته (جانهیشده) و پیشبین در مدل جایگزاری در نظر گرفته شود.
Min and Max. این ستونها به شما امکان را می دهند که کمینه و بیشینه قابل قبول برای کمیتهای عددی Scale را مشخص کنید. اگر یک مقدار جایگزاری شده خارج از این محدوده قرار گیرد، مدل جانهی، مقدار دیگری را تولید میکند تا زمانی که یکی را در محدوده قابل قبول پیدا کند. به این نکته توجه کنید که این ستونها هنگامی در دسترس هستند که متد رگرسیون خطی در تب Method انتخاب شده باشد.
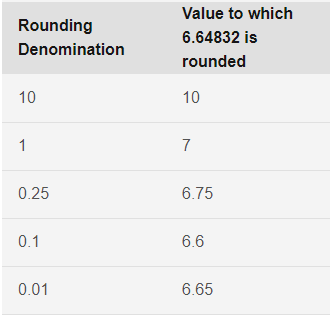
Rounding. برخی از Variableهای تحلیل، ممکن است عددی Scale باشند. ما در این ستون میتوانیم آنها را به دلخواه خود گرد کنیم. این ستون به شما امکان میدهد کوچکترین واحد مورد نظر را مشخص کنید. به عنوان مثال، برای به دست آوردن مقادیر صحیح، باید 1 را در این ستون قرار دهید. برای بدست آوردن مقادیر گرد شده به نزدیکترین صدم، باید 0.01 را مشخص کنید. به طور کلی، مقادیر به نزدیکترین مضرب عدد صحیح تعیین شده برای گرد شدن، تبدیل میشوند. به عنوان مثال جدول زیر نشان میدهد چگونه مقادیر مختلف گرد کردن بر روی یک مقدار جانهی شده 6.64823 (قبل از گرد کردن) عمل میکنند.
3 در اینجا گزینه با نام Exclude variables with large amounts of missing data دیده میشود.
با استفاده از این گزینه میتوانیم کمیتهایی را که تعداد زیادی داده گمشده دارند، حذف کنید. به طور معمول، Variableهای تحلیل بدون در نظر گرفتن تعداد مقادیر گمشده آنها به عنوان پیشبینی کننده، در نظر گرفته میشوند. در اینجا میتوانید کمیتهایی را که دارای درصد بالایی از مقادیر گم شده هستند حذف کنید. به عنوان مثال، اگر شما 50 را به عنوان حداکثر درصد گمشده مشخص کنید، کمیتهایی که بیش از 50 درصد داده گمشده دارند، جانهی نشده و از آنها به عنوان پیش بینی کننده در مدلهای جایگزاری استفاده نمیشود.
Maximum case draws. اگر در کادر Define Constraints کمینه یا بیشینه برای مقادیر ورودی کمیتهای عددی مشخص شده باشد (به Min و Max این کادر مراجعه کنید)، این روش سعی میکند به تعداد تعیین شده در این کادر تکرار کند تا مقادیری را برای یک مورد به دست آورد تا زمانی که مجموعهای از مقادیر را در محدودههای قابل قبول پیدا کند.
Maximum parameter draws. اگر مجموعهای از مقادیر در تعداد مشخص شده هر مورد به دست نیاید، فرایند جانهی دادههای گمشده، مجموعه دیگری از پارامترهای مدل را طراحی میکند و فرآیند تولید مورد را تکرار میکند. در اینجا به نرمافزار میگویمم حداکثر تا چند بار فرایند طراحی مدل بر مبنای پارامترها را تکرار کند. در نهایت اگر مجموعهای از مقادیر در محدودهها در تعداد مشخص شده موارد و طراحی پارامترها به دست نیاید، خطا رخ میدهد و فرایند جانهی انجام نمیشود.
به این نکته توجه کنید که افزایش این مقادیر میتواند زمان پردازش را در سیستم شما افزایش دهد.
-
Output
1 کادر با نام Display دیده میشود. در این کادر میتوانیم نحوه نمایش خروجیها در نرمافزار SPSS را کنترل کنیم. خلاصهای از جایگزاری نتایج همیشه نشان داده میشود. این نتایج شامل جداول مربوط به مشخصات جایگزاریها، تکرارها (برای روش مشخصات کاملاً شرطی FCS)، کمیتهای وابسته جانهی، کمیتهای وابسته حذف شده و دنباله جانهی است. در این زمینه هنگام مشاهده خروجیهای نرمافزار بیشتر میتوان توضیح داد.
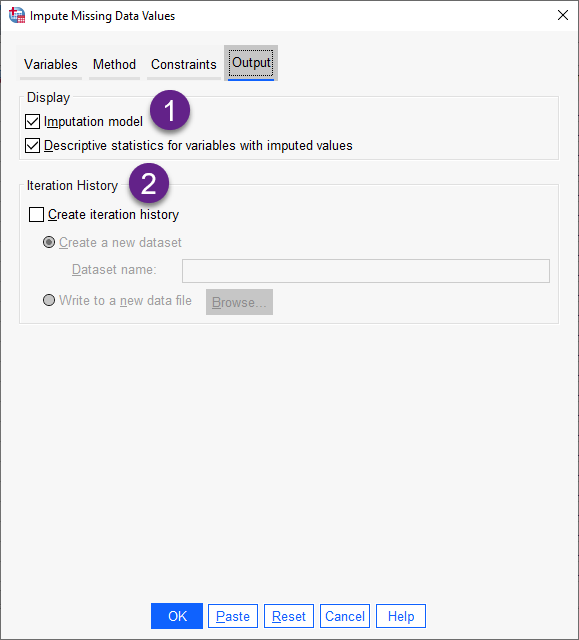
Imputation model. انتخاب این گزینه سبب میشود در خروجی نرمافزار، مدل جانهی، Variableهای وابسته و پیشبینی کننده، نوع و اثرات مدل و تعداد دادههای جایگزاری شده، نمایش داده شود.
Descriptive statistics. انتخاب این گزینه آمارههای توصیفی مربوط به کمیتهای وابسته که مقادیر برای آنها جانهی شده است را نشان میدهد. این خروجی برای کمیتهای عددی شامل میانگین، تعداد، انحراف معیار، کمینه و بیشینه قبل و بعد از جانهی است. همچنین برای کمیتهای طبقهبندی، شامل تعداد و درصد میباشد.
2 کادر با نام Iteration History که به آن تاریخچه تکرار دیده میشود. هنگامی که از روش جایگزاری مشخصات کاملاً شرطی FCS استفاده میشود، می توانید مجموعه دیتایی را درخواست کنید که شامل دادههای تاریخچه تکرار برای روش FCS باشد. این مجموعه داده شامل میانگین و انحرافات استاندارد به وسیله تکرار و جانهی برای هر کمیت وابسته عددی است.
برای این فایل دیتا جدید میتوانید یک نام انتخاب کنید و یا آن را در یک فایل دیتا از قبل موجود در سیستم خود، فراخوان کنید.
حال بیایید در ادامه به نتایج و خروجیهای به دست آمده با استفاده از نرمافزار SPSS بپردازیم. نکته اینکه من در تب Method گزینه Automatic را انتخاب کردم.
نتایج و خروجیهای نرمافزار
Results
هنگامی که OK میکنیم خروجیها و نتایج زیر در Output نرمافزار به دست میآید. در ادامه به ترتیب به توضیح هر کدام از نتایج و جدولها به دست آمده از تحلیل جانهی دادههای گمشده، میپردازیم.
در ابتدا جدول Imputation Specifications دیده میشود. در تصویر زیر نتایج این جدول را ببینید.
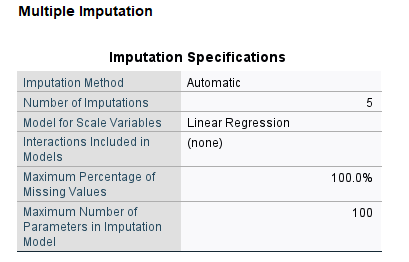
در این جدول درباره ویژگیها و مشخصات فرایند جانهی دادههای گمشده توضیح داده شده است. این جدول نشان میدهد از روش جانهی Automatic استفاده شده است. تعداد مدلهای جایگزاری 5 بار تکرار شده است و از مدل رگرسیون خطی برای جایگزاری در کمیتهای عددی استفاده شده است. اثرات متقابل در مدل وجود نداشته است، همهی دادههای گمشده جایگزاری شده و حداکثر تعداد پارامتر موجود در مدل نیز تعداد 100 پارامتر است.
در جدول Imputation Constraints مشخصات مربوط به محدودیتهای مدل جانهی، آمده است.
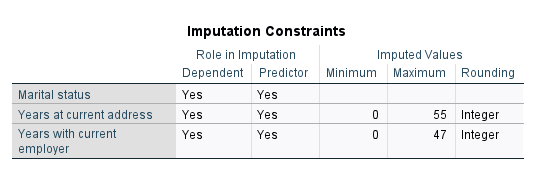
این جدول نشان میدهد هر سه کمیت Marital، address و employer هم دارای نقش Dependent و هم نقش Predictor هستند. کمینه و بیشینه قابل قبول و همچنین نحوه نمایش عدد صحیح مربوط به هر کمیت، آمده است. همانگونه که میدانیم این نتایج همان تنظیماتی است که ما در تب Constraints قرار دادیم.
در جدول Imputation Models مدل رگرسیونی شامل اثرات (Predictor)، تعداد دادههای گمشده و تعداد مقادیر جایگزاری شده، آمده است.
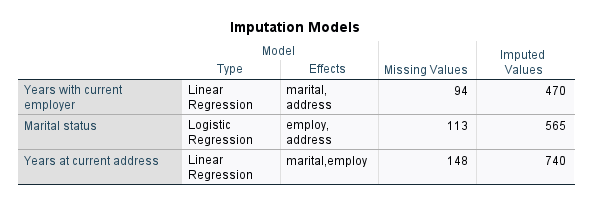
جدول بالا نشان میدهد برای کمیتهای عددی یعنی employer و address از مدل رگرسیون خطی استفاده کردهایم. در این مدلها پیشبینی کنندهها کمیتهای دیگر موجود در تحلیل قرار میگیرند. به عنوان مثال در کمیت employer هنگامی که از مدل رگرسیون خطی برای جایگزاری دادههای گمشده آن استفاده میکنیم، marital و address پیش بینی کننده هستند.
به همین ترتیب از آنجا که marital یک کمیت باینری است، از مدل رگرسیون لجستیک باینری جهت جایگزاری دادههای گمشده استفاده شده است. در این مدل غیرخطی، پیش بینی کننده ها employer و address هستند.
در جدول بالا تعداد دادههای گمشده هر کمیت به همراه تعداد موارد جایگزاری شده آمده است. از آنجا که ما فرایند جایگزاری را 5 بار تکرار کردهایم، به همین ترتیب به ازای هر داده گمشده، پنج عدد جایگزاری شده است. بنابراین فراوانیها در ستون Imputed Values پنج برابر فراوانی در ستون Missing Values است.
در ادامه آمارههای توصیفی به ازای هر کدام از کمیتهای موجود در تحلیل جانهی، به دست آمده است. برای کمیتهایی که Nominal و یا Ordinal هستند، آمارههای توصیفی به صورت فراوانی و درصد ارایه میشود. در کمیتهایی هم که Scale هستند، آمارههای توصیفی در قالب میانگین، انحراف معیار، کمینه و بیشینه به دست میآید.
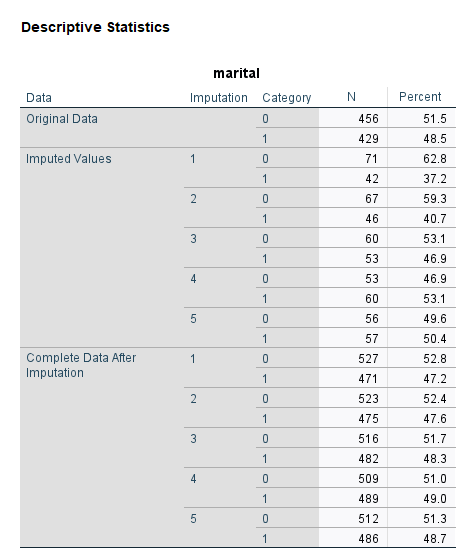
نکته مهم در این جداول این است که نتایج یک بار برای دادههای واقعی، یکبار برای دادههای جایگزاری شده و بار دیگر برای دادههای کامل شده، به دست میآیند. از آنجا که ما از نرمافزار خواستهایم فرایند جایگزاری را پنج بار تکرار کند، بنابراین همهی آمارههای توصیفی پنج بار تکرار میشوند.
جدول Descriptive Statistics بالا که برای کمیت marital به دست آمده است نشان میدهد در دادههای واقعی تعداد 456 (51.5 درصد) کد صفر و تعداد 429 مورد (48.5 درصد) کد یک وجود داشته است.
به خاطر داشته باشید این کمیت دارای 113 داده گمشده میباشد. نرمافزار از آنجا که کار جایگزاری را پنج بار تکرار کرده است، در هر بار تکرار این 113 داده گمشده را به گروههای صفر و یک تقسیم کرده است. مثلاً در تکرار بار اول تعداد 71 مورد (62.8 درصد) کد صفر و تعداد 42 مورد (37.2 درصد) کد یک تولید کرده است. به عنوان مثال دیگر در تکرار بار پنجم تعداد 56 مورد (49.6 درصد) کد صفر و تعداد 57 مورد (50.4 درصد) کد یک تولید کرده است.
به همین ترتیب در نهایت نشان داده است با جایگزاری دادههای گمشده، تعداد کل کدهای صفر و یک در هر مرحله چقدر است. به عنوان مثال ما در مییابیم که در تکرار بار پنجم تعداد 512 مورد (51.3 درصد) کد صفر و تعداد 486 مورد (48.7 درصد) کد یک برای کمیت marital وجود دارد.
فرایند جایگزاری دادههای گمشده و سپس به دست آوردن آمارههای توصیفی، این بار برای کمیت address انجام شده است.
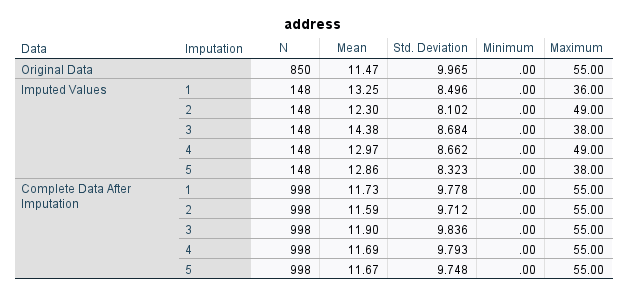
در ابتدا جدول بالا، آمارههای توصیفی برای 850 داده موجود به دست آمده است. این جدول نشان میدهد میانگین و انحراف معیار برای کمیت address در 850 مورد موجود به ترتیب برابر با 11.47 و 9.96 بوده است.
در هر تکرار، 148 داده گمشده جایگزاری شده است که آمارههای توصیفی دادههای جایگزاری شده مربوط به هر مرحله نیز به دست آمده است. مثلاً در مرحله چهارم که 148 مقدار جایگزاری شده است، میانگین موارد جایگزاری شده برابر با 12.97 بوده است.
در پایان این جدول نیز میتوانید آمارههای توصیفی برای همهی دادهها (دادههای موجود قبلی به همراه دادههای جایگزاری شده جدید) را مشاهده کنید.
مشابه جدول بالا برای کمیت employ نیز به دست آمده است. آن را در ادامه ببینید.
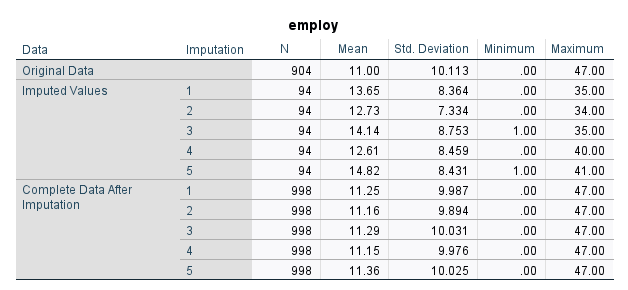
در این جدول نیز آمارههای توصیفی یکبار برای دادههای موجود (904 مورد)، یکبار برای دادههای جایگزاری شده (در پنج مرحله تکرار فرایند جانهی) و در نهایت برای دادههای تکمیل شده (904 مورد قبلی همراه با 94 داده جایگزاری شده) به دست آمده است.
به خاطر داشته باشید ما در تنظیمات و در تب Variables از نرمافزار خواستیم که دادههای جایگزاری شده را در یک فایل دیتا جدید شامل نتایج جایگزاری برای دادههای گمشده همراه با دادههای موجود قبلی، برای ما بسازد. نام این فایل را نیز Impute گذاشتیم.
هنگامی که در پنجره تنظیمات OK میکنیم، یک فایل دیتا جدید با همین نام برای ما ساخته میشود. من در تصویر زیر بخشهایی از این فایل را آوردهام.
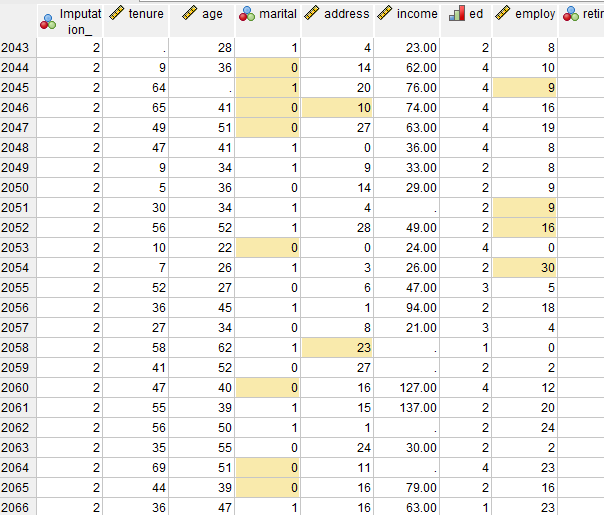
نرمافزار خانههای جایگزاری شده را با رنگ برای ما مشخص کرده است. دادهها در هر مرحلهی جایگزاری نیز زیر هم نوشته شده است.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2023). Impute Missing Data Values in Multiple Imputation Studies. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/impute-missing-data-values-spss/.php
For example, if you viewed this guide on 12th January 2023, you would use the following reference
GraphPad Statistics (2023). Impute Missing Data Values in Multiple Imputation Studies. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/impute-missing-data-values-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.