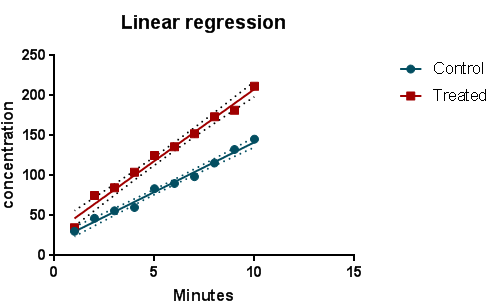
طراحی مدل رگرسیون خطی Linear Regression با گراف پد پریسم
چه پیش خواهد آمد؟ سوالی است که بشر از ابتدای خلقت به دنبال پاسخ به آن بوده است. پیشبینی و درک پدیدههای آینده از مهمترین مفاهیم مورد بررسی انسانها بوده است و خواهد بود.
جالب است که بدانیم علم با طراحی مدلهای آیندهنگر و پیشبین، البته که نه به صورت قطعی بلکه به صورت احتمالی و با درصدی از درستی، به این سوال پاسخ داده است. رگرسیون در انواع مدلهای آن، تلاشی است برای پاسخ به سوال در آینده چه میشود و ساختن یک معادله آماری جهت درک و پیشبینی آینده.

ما در این آموزش به دنبال آن هستیم که فرایند طراحی و ایجاد یک مدل رگرسیون خطی با استفاده از نرمافزار GraphPad Prism را مورد بررسی قرار دهیم. گراف پد نرمافزاری بسیار کارآمد و پرکاربرد جهت انجام طیف متنوعی از تحلیلهای آماری میباشد.
شروع کار: نرمافزار گراف پد خود را باز کنید.
ما در این آموزش از جدیدترین نسخه گراف پد پریسم یعنی شماره 7 استفاده میکنیم. کار با ورژنهای پایینتر مشابه است. هنگامی که نرمافزار را باز میکنید از قسمت سمت چپ با عنوان New Table & Graph تحلیل XY را انتخاب کنید. اگر میخواهید روی دادههای اصلی خود کار کنید در کادر Enter/import data در بخش X: بسته به اینکه دادههای کمیت مستقل شما چه اندازههایی هستند (اعداد حسابی، تاریخ، زمان) یک گزینه را انتخاب کنید. در بخش Y: نیز با توجه به اینکه دادههای کمیت وابسته چگونه جمعآوری شده و دارای تکرار هستند یا خیر، یک گزینه را انتخاب کنید.
به صورت پیشفرض نرمافزار گراف پد، دادههای X و یا کمیت مستقل را اعداد و دادههای Y و یا کمیت وابسته را یکبار تکرار، در نظر میگیرد.
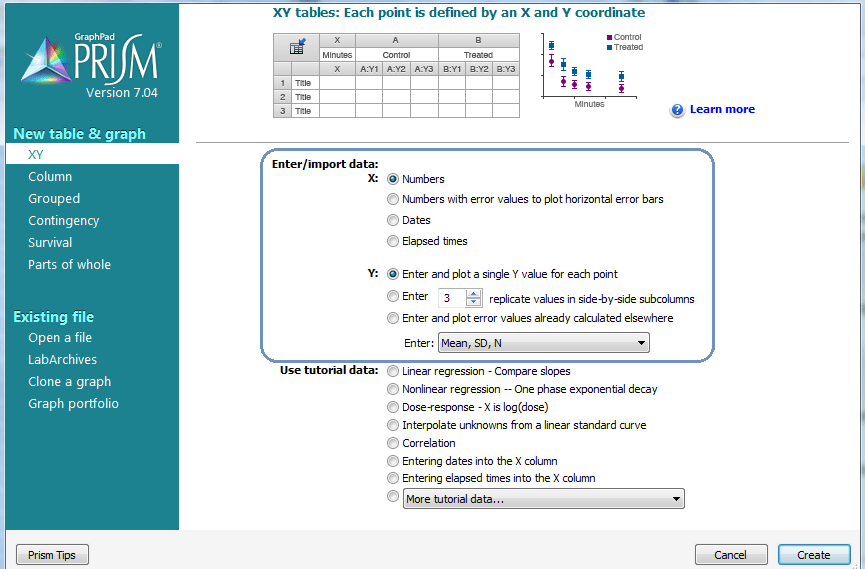
چنانچه تمایل دارید بر روی دادههای آموزشی نرمافزار گراف پد طراحی مدل رگرسیون خطی را انجام دهید، در کادر Use tutorial data گزینه Linear Regression – Compare slopes را انتخاب کنید.
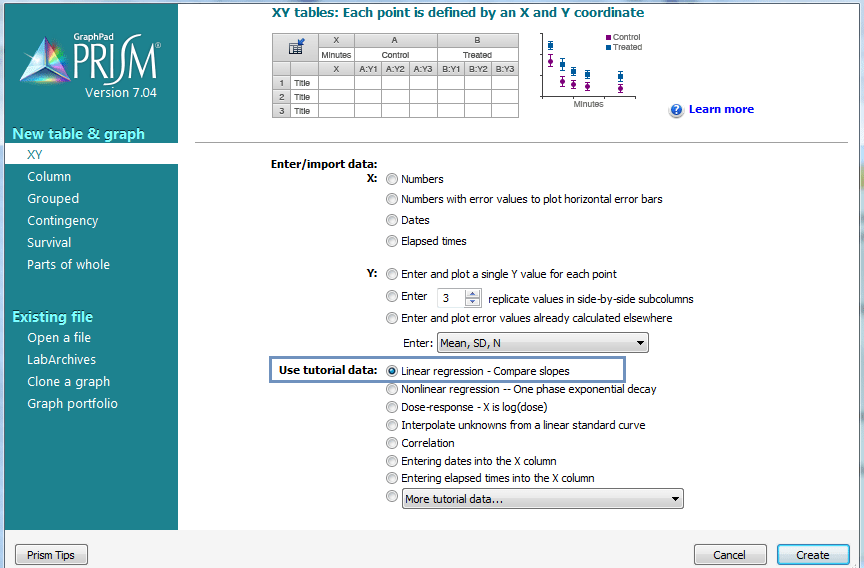
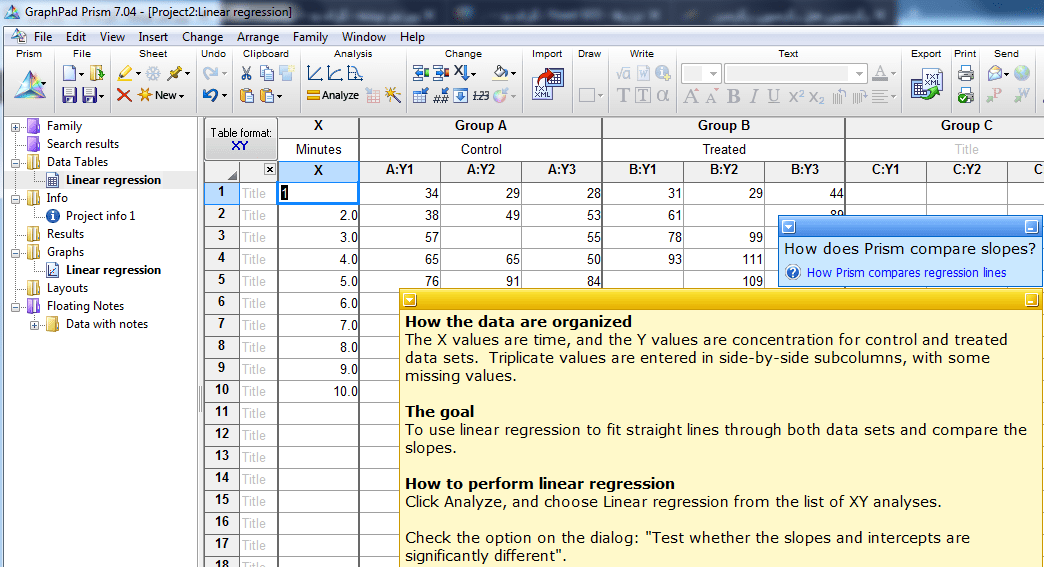
ما کار ارایه تحلیل رگرسیون خطی، را بر دادههای آموزشی نرمافزار انجام میدهیم. در دادههای آموزش رگرسیون نرمافزار، چگونگی مقایسه شیب مدلهای رگرسیونی نیز بررسی میشود. دکمه Create را بزنید. جدول داده زیر باز خواهد شد.
به کارتان میآید: کارگاه آموزشی نحوه کار با نرمافزار گراف پد پریسم
دادههای خود را مشاهده کنید.
دادهها در یک برگه با نام Linear regression از فولدر Data Tables قرار گرفتهاند. همانگونه که از توضیحات نوشته شده در کادر زرد رنگ Note برمیآید، دادهها در دو ستون اصلی آمدهاند. یکی ستون X با نام Minutes که بیانگر زمان و به عنوان کمیت مستقل و دیگری ستون Y با دو زیرگروه Control و Treated هر کدام با سه بار تکرار، به عنوان کمیت وابسته مجموعه دادههای غلظت هستند.
هدف مطالعه آن است که به هر کدام از زیرگروههای Control و Treated یک مدل رگرسیون خطی برازش دهیم و بتوانیم شیب مدلها را با یکدیگر مقایسه کنیم. مقایسه شیبها به ما این امکان را میدهد تا بتوانیم دریابیم در کدامیک از گروههای کنترل و درمان، ارتباط قویتری بین زمان و غلظت وجود دارد. رسم نمودارهای رگرسیونی نیز در مراحل انجام کار خواهد بود.
مدل رگرسیون خطی طراحی کنید.
جهت انجام تحلیل رگرسیون به سادگی به منوی بالای صفحه به نام Analyze بروید.

پنجره Analyze Data باز خواهد شد. در کادر XY analyses تحلیل Linear regression را انتخاب کنید. دکمه OK را بزنید.
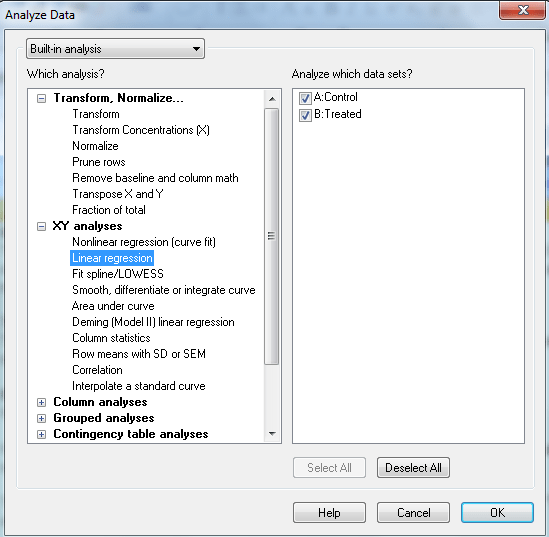
پنجره Parameters: Linear Regression باز میشود. گزینه Interpolate مواردی به کار میآید که برای چند سطر X اندازهای به دست نیاورده باشیم، اما مقادیر Y آنها مشخص است. انتخاب این گزینه سبب میشود با استفاده از دادههای موجود برای این مقادیر نامعلوم نیز برازش مدل رگرسیون انجام شود. در این مثال با دادههای خالی در ستون X مواجه نیستیم و تمام سطرها پُر و اندازهگیری شده است. بنابراین آن را علامت نمیزنیم.
گزینههای طراحی مدل رگرسیون خطی
در گزینه Compare آزمون مقایسه شیب مدلهای رگرسیونی قرار دارد. انتخاب این گزینه سبب میشود، نرمافزار بررسی کند که آیا ضرایب رگرسیونی در مدل Control و Treated با یکدیگر اختلاف معناداری دارند یا خیر؟ این گزینه را انتخاب میکنیم.

در گزینه Graphing options رسم دو نمودار دیده شده است. یکی گراف با فاصله اطمینان مشخص برای منحنی برازش و دیگری نمودار باقیماندهها. درباره نمودار باقیماندهها این نکته را از تئوریهای تحلیل رگرسیون میدانیم که مدلی مناسب است که باقیماندههای آن اطراف خط صفر بدون هیچگونه نظم خاصی و به تصادف پراکنده شده باشند. هر دو گزینه را انتخاب میکنیم.

گزینه Constrain مدل رگرسیون خطی را مجبور میکند که از یک نقطه تعیین شده عبور کند. به عنوان مثال با فعال کردن این گزینه به صورت پیشفرض، نرمافزار نقطه X=0 و Y=0 را محل شروع خط رگرسیونی در نظر میگیرد. این کار چندان توصیه نمیشود، باید اجازه داد تا منحنی رگرسیون بهترین برازش خود را انتخاب کند. انتخاب این گزینه تنها در موارد خاص که به دنبال محدود کردن خط برازش رگرسیونی هستیم، توجیهپذیر است.
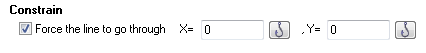
گزینه Replicates در مواردی که در کمیت وابسته یعنی Y به ازای هر مقدار X تکرار داریم، بسیار به کار میآید. دکمه Consider each replicate Y value as an individual point به معنای آن است که نرمافزار، هر تکرار را به عنوان یک نقطه مجزا در معادله وارد خواهد کرد و با در نظر گرفتن تمام تکرارها مدل رگرسیون را برازش میدهد.
دکمه Only consider the mean Y value of each point میانگین تکرارها را در هر سطر وارد معادله رگرسیونی میکند و براساس این میانگین به دست آمده به ازای هر سطر، مدل رگرسیونی را برازش میدهد. به نظر من انتخاب تکرارها، کار را با دقت بیشتری همراه خواهد کرد. گراف پد پریسم به صورت پیشفرض با گزینه میانگین تکرارها کار میکند.
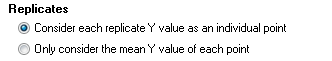
تنظیمات بیشتر در طراحی مدل رگرسیون خطی
گزینه Also calculate تنظیمات بیشتری برای مشاهده نتایج مدل رگرسیونی دارد. دکمه Test departure from linearity with replicates test مسئولیت انجام آزمون فاصله دادهها از خط مستقیم رگرسیون را بر عهده دارد. این کار با استفاده از آزمون تکرار انجام میشود. انتخاب دکمهی Consider each replicate Y value as an individual point در Replicates سبب میشود که در اینجا Replicates test انجام شود. اگر در بالا دکمهی Only consider the mean Y value of each point را انتخاب میکردیم در اینجا آزمون Run test انجام میشده است. توجه به این نکته مهم است که نه فقط در پریسم بلکه در هر نرمافزار آماری دیگری نیز، چنانچه دادههایی به نرمافزار داده شود، به هر حال محاسبه مدل رگرسیونی انجام خواهد شد و یک مدل آماری به دست خواهد آمد. اما موضوع مهم درست بودن مدل به دست آمده است. استفاده از یک آزمون replicates در اینجا به ما کمک خواهد کرد، بدانیم آیا خط مستقیم رگرسیونی به دست آمده صحیح است؟
دو گزینه پایینی نیز به ترتیب مقادیر فاصله اطمینان 95% برای Y و X به ازای اندازههای تعیینشده، به دست میدهند.
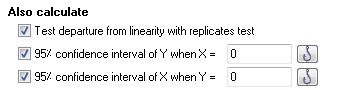
گزینه Range برای شروع و پایان مدل رگرسیونی، تصمیم میگیرد. پیشفرض نرمافزار انتخاب Auto خواهد بود. با اینحال اگر در نظر داشته باشیم، میتوانیم به جای کار با تمام اندازههای کمیت مستقل X، مدل را از یک مقدار خاص X شروع و با مقدار تعیین شده دیگری، پایان دهیم. به این نکته توجه کنید که تمام این تنظیمات و گزینهها از نقاط قوت نرمافزار گراف پد پریسم به حساب میآید. کمتر نرمافزار آماری را میتوان یافت که چنین به جزئیات توجه کند.

در گزینه Output کادری به نام Show table of XY coordinate قرار دارد. انتخاب این دکمه سبب میشود، برگهای با نام Line در فولدر Results نرمافزار ایجاد شود. در این برگه پیشبینی مقادیر Y در دو گروه Control و Treated به ازای مقادیر X آمده است. نحوه ساختن برگه Line به این صورت است که مدل رگرسیون خطی ابتدا طراحی میشود (برگه Tabular results) و سپس مقادیر پیشبینی به دست میآید.
در شکل زیر میتوانید بخشی از برگه Line را ببینید.
در گزینه Output چگونگی نمایش مقدار احتمال P-value و تعداد اعشار آن نیز قابل تنظیم است.
به کارتان میآید: کارگاه آموزشی نحوه کار با منوها و برگههای گراف پد
مشاهده نتایج مدل رگرسیون خطی
به این ترتیب پنجره تنظیمات مدل رگرسیون خطی با نرمافزار گراف پد پریسم به پایان میرسد. OK کنید. نتایج در فولدر Results پنجره Navigator Panel قابل مشاهده است. همچنین میتوانید در فولدر Graphs نمودارهای مرتبط با تحلیل رگرسیون را ببینید.

تحلیل نتایج برگهی Tabular results
جهت تحلیل نتایج از برگهی Tabular results شروع میکنیم. نتایج این برگه به صورت کامل به ارایه تحلیل رگرسیون خطی و نتایج به دست آمده از دادهها میپردازد. برگه Tabular results دارای چند بخش است. ما به صورت جداگانه هر یک را توضیح میدهیم. از بخش Best-fit values ± SE شروع میکنیم.
در این بخش براورد پارامترهای مدل رگرسیونی به همراه انحراف معیار هر پارامتر به ازای گروههای Control و Treated آمده است. Slope همان ضریب رگرسیونی مدل یعنی β1 است. Y-intercept عرض از مبدا مدل یعنی β0 را نشان میدهد. به وضوح 1/Slope نیز وارون شیب و ضریب رگرسیونی را نشان میدهد که در برخی از مطالعات به جای خود شیب کاربرد دارد. اما X-intercept چیست؟ پاسخ بسیار ساده است. Y-intercept و یا همان β0 بیانگر مقدار Y است وقتی X صفر باشد. پس X-intercept نشاندهنده مقدار X است وقتی Y برابر صفر باشد.
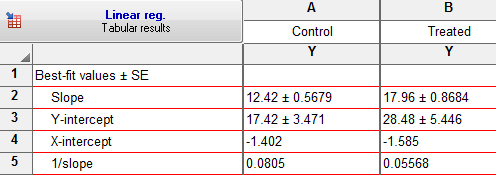
توجه به مقادیر ضریب رگرسیونی نشان میدهد که تاثیر زمان بر روی غلظت در گروه درمان بیشتر بوده است. ضریب رگرسیونی آن برابر با 17.96 به دست آمده است. این ضریب در گروه کنترل 12.42 براورد شده است.
در بخش 95% Confidence Intervals نیز یک فاصله اطمینان 95 درصد به ازای هر کدام از پارامترهای برازش شده به دست آمده است.
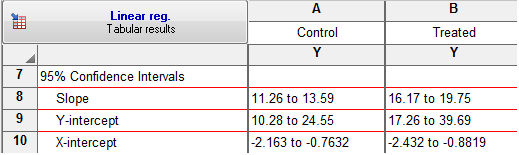
کادر Goodness of Fit اندازههای ارزیابی مدل را در خود قرار داده است. R square نشان میدهد چه درصدی از دادهها با استفاده از مدل به دست آمده تحت پوشش قرار گرفتهاند. بدیهی نزدیک به 100 بودن این مقدار نشاندهنده بهتر بودن مدل رگرسیون برازش شده است.
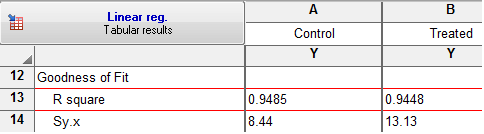
در بخش ?Is slope significantly non-zero معنادار بودن ضریب رگرسیونی در هر گروه آزمون شده است. سوال این بوده است که آیا شیب اختلاف معناداری با غیر صفر بودن دارد؟ پاسخ مثبت به این سوال به معنای آن است که وجود ضریب رگرسیونی به دست آمده در مدل لازم و معنادار است. نتایج در تصویر زیر دیده میشود.
نتیجه به دست آمده بیانگر معنادار بودن شیب در مدل است.
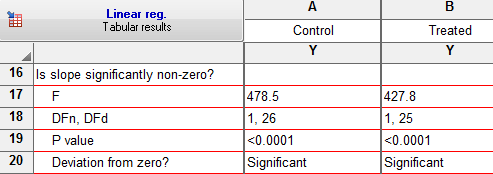
در بخش Replicates test for lack of fit نتایج دکمه Test departure from linearity with replicates test در گزینه Also calculate آمده است. به یاد داشته باشید در آنجا گفتیم که این آزمون بررسی میکند آیا دادهها از خط مستقیم رگرسیون فاصله دارند یا خیر. نتیجه به دست آمده نشان میدهد پاسخ این سوال منفی است و دادهها یک خط رگرسیونی مناسب را میسازند.
در کادر Equation معادله آماری رگرسیون آمده است. همانگونه که میبینید در گروه Control معادله به صورت Y = 12.42*X + 17.42 و در گروه Treated به صورت Y = 17.96*X + 28.48 به دست آمده است.
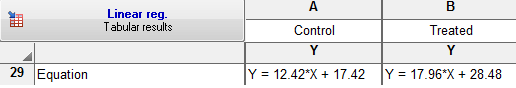
در کادر Data نیز اطلاعاتی درباره تعداد دادههای X، تعداد تکرار در هر سطر Y، تعداد دادههای موجود و واقعی جهت برازش مدل و تعداد دادههای بدون مقدار Missing بیان شده است. همانگونه که دیده میشود در گروه Control دو عدد و در گروه Treated سه عدد گمشده هستند.
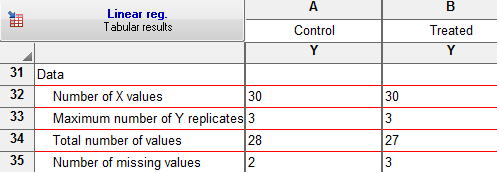
تحلیل نتایج برگهی Line
درباره این برگه از نتایج، توضیحاتی در بالا ارایه دادیم. به اختصار بیان میکنیم که نتایج به دست امده در برگه Line به پیشبینی مدل رگرسیون به دست آمده به ازای مقادیر خاص X میپردازد. این پیشبینی در هر گروه در سه ستون Mean که مقدار پیشبینی را نشان میدهد، Error+ که کران بالای خطای پیشبینی و Error- که کران پایین خطای پیشبینی را نشان میدهد، آمده است.
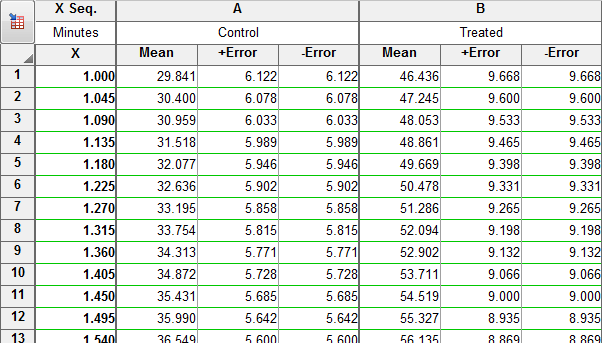
تحلیل نتایج برگهی Residual
باقیماندهها و یا همان Residual به اختلاف بین مقدار واقعی و مقدار پیشبینی شده توسط مدل، گفته میشوند. به عناون مثال همانگونه که در برگه جدول دادهها با نام Linear regression دیده میشود، در همان سطر اول به ازای X=1، مقدار Y در اولین تکرار برابر با 34 میباشد. مقدار پیشبینی شده که در برگه Line دیده میشود به ازای X=1 برابر با 29.841 برازش شده است. بنابراین اختلاف آنها 4.159 میشود که در اولین خانه برگه Residual دیده میشود. بقیه دادهها و نتایج در برگه باقیماندهها نیز به همین صورت به دست آمدهاند.
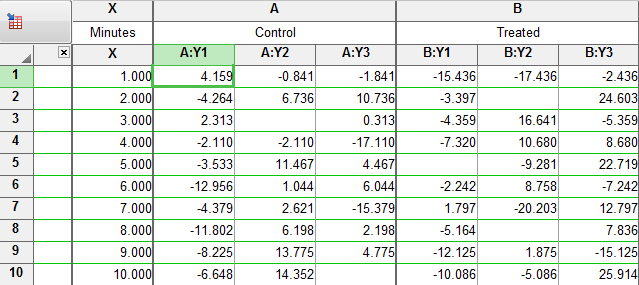
تحلیل نتایج برگهی ?Are lines different
همانگونه که از نام این برگه برمیآید، نتایج به سوال ابتدایی ما که در گزینه Compare تنظیمات مدل رگرسیون مطرح کردیم، میپردازد. سوال ما این بود که آیا شیبها در هر دو گروه کنترل و درمان همانند هستند و یا اینکه اختلاف معناداری با یکدیگر دارند.

نتایج به دست آمده نشان میدهد مقدار احتمال آزمون برابری ضرایب رگرسیونی برابر با 0.0001>P است. این مقدار به وضوح بیانگر رد فرض صفر برابری شیبها است. بنابراین میپذیریم که ضریب رگرسیونی در هر گروه متفاوت از یکدیگر میباشد و هر یک به مدل رگرسیونی گروه خود اشاره دارد. معنای دیگر این حرف ان است که خط رگرسیونی در گروههای Control و Treated با یکدیگر موازی نیستند. سادهتر اینکه تاثیر زمان بر غلظت در دو گروه از یکدیگر متفاوت است.
رسم گراف مدل رگرسیون خطی
در فولدر Graphs دو برگه با نامهای Linear regression و Residuals: Linear reg. of Linear regression دیده میشود.
هنگامی که روی برگه Linear regression کلیک میکنیم، پنجره زیر با نام Change Graph Type باز میشود.
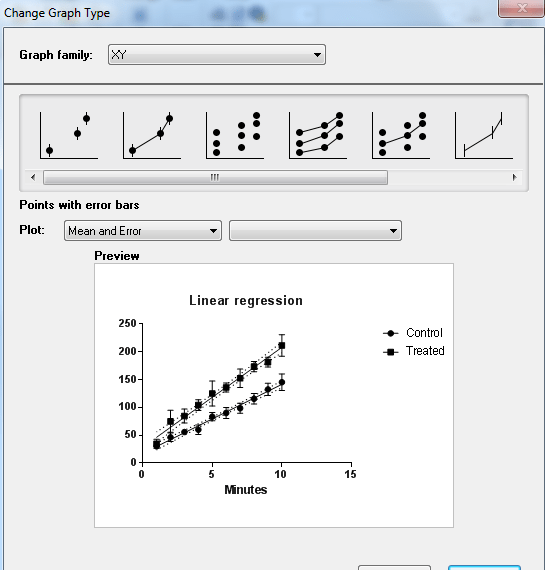
در این محیط میتوانید ویرایشهای دلخواه و مورد نیاز بر روی نحوه نمایش خط رگرسیون هر دو گروه را انجام دهید. اگر OK کنیم شکل زیر رسم خواهد شد.
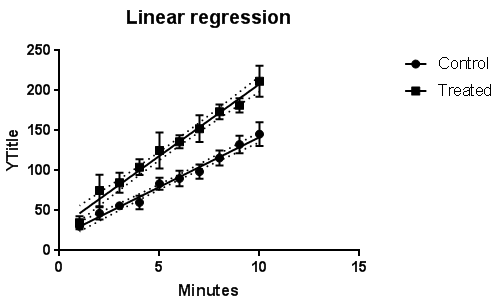
در گراف به دست آمده Error Bar به ازای هر نقطه، خط رگرسیونی و فاصله اطمینان 95 درصد برای خط رگرسیونی که با نقطه چین قابل مشاهده است، رسم شده است. با کلیک کردن بر روی گراف رسم شده و یا مراجعه به منوی Change در بالای صفحه میتوان، گراف را ویرایش کرد. به عنوان مثال ما در شکل زیر خط رگرسیونی بدون Error Bar را رسم کردهایم. کمی هم رنگها را ویرایش کردهایم.
برگه Residuals: Linear reg. of Linear regression به رسم نمودار از باقیماندهها در برابر X میپردازد. این برگه از آنجا ساخته شد که گزینه Graphing options را در تنظیمات طراحی نرمافزار، علامت زدیم. همانگونه که میدانید مدل رگرسیونی مناسب است که باقیماندههای آن در اطراف خط صفر به تصادف پراکنده شده باشند. در مثال ما گراف به دست آمده بیانگر این ویژگی است. بنابراین مدلهای رگرسیونی به دست آمده را مناسب میدانیم.
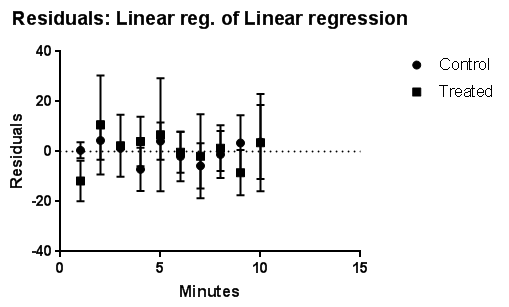
مانند گراف قبلی با کلیک کردن روی گراف و استفاده از منوی Change میتوان نحوه نمایش نمودار را ویرایش کرد.
به کارتان میآید: کارگاه آموزشی نحوه کار با منوها و برگههای گراف پد
در این آموزش آموختیم چگونه میتوان یک مدل رگرسیون خطی طراحی کرد، پارامترها را براورد و شیبها را با یکدیگر مقایسه کرد. مدلها را از ارزیابی و اندازه درستی آنها را به دست آورد. مقادیر پیشبینی را یافت و گرافهای مناسب را رسم نمود.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2019). Design of Linear Regression model with GraphPad Prism. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/regression-graphpad-prism/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2019). Design of Linear Regression model with GraphPad Prism. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/regression-graphpad-prism/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.