رگرسیون لجستیک چندگانه Multiple Logistic Regression نرم افزار گراف پد
یکی از تحلیلهایی که در ورژنهای جدید گراف پد (8 به بعد) قرار گرفته است، مدلهای رگرسیون لجستیک Logistic Regression است.
همانگونه که میدانیم وقتی Variable پاسخ ما یعنی Y دو حالتی باشد (بله یا خیر، موفقیت یا شکست، رخداد یا عدم رخداد) و بخواهیم بین پاسخ با Variableهای مستقل یعنی Xها ارتباط و مدلبندی ایجاد کنیم، از مدلهای رگرسیون غیرخطی با نام لجستیک استفاده میکنیم.

در زمینه تئوریهای رگرسیون لجستیک، بحثهای زیادی وجود دارد. شما را به خواندن و مطالعه این لینک در سایت گراف پد توصیه میکنم.
یک توضیح کوتاه اینکه مدل رگرسیون لجستیک هنگامی که تنها دارای یک کمیت مستقل یعنی یک X باشد، آن را رگرسیون لجستیک ساده مینامیم. به همین ترتیب وقتی تعداد کمیتهای مستقل بیشتر از یک باشد، یعنی چندین X داشته باشیم، آن را مدل رگرسیون لجستیک چندگانه میگوییم.
ما در آموزش قبلی و در این لینک به ارایه توضیحات درباره رگرسیون لجستیک ساده Simple Logistic Regression با استفاده از نرمافزار گراف پد، پرداختیم. در ادامه و در مثال زیر با استفاده از نرمافزار گراف پد پریسم، به ارایه و انجام تحلیل رگرسیون لجستیک چندگانه Multiple Logistic Regression میپردازیم.
این مثال با نام Multiple logistic regression در دسته تحلیلهای Multiple variables و در بخش Start with sample data to follow a tutorial قرار دارد. فایل مثال را میتوانید از اینجا دانلود کنید.
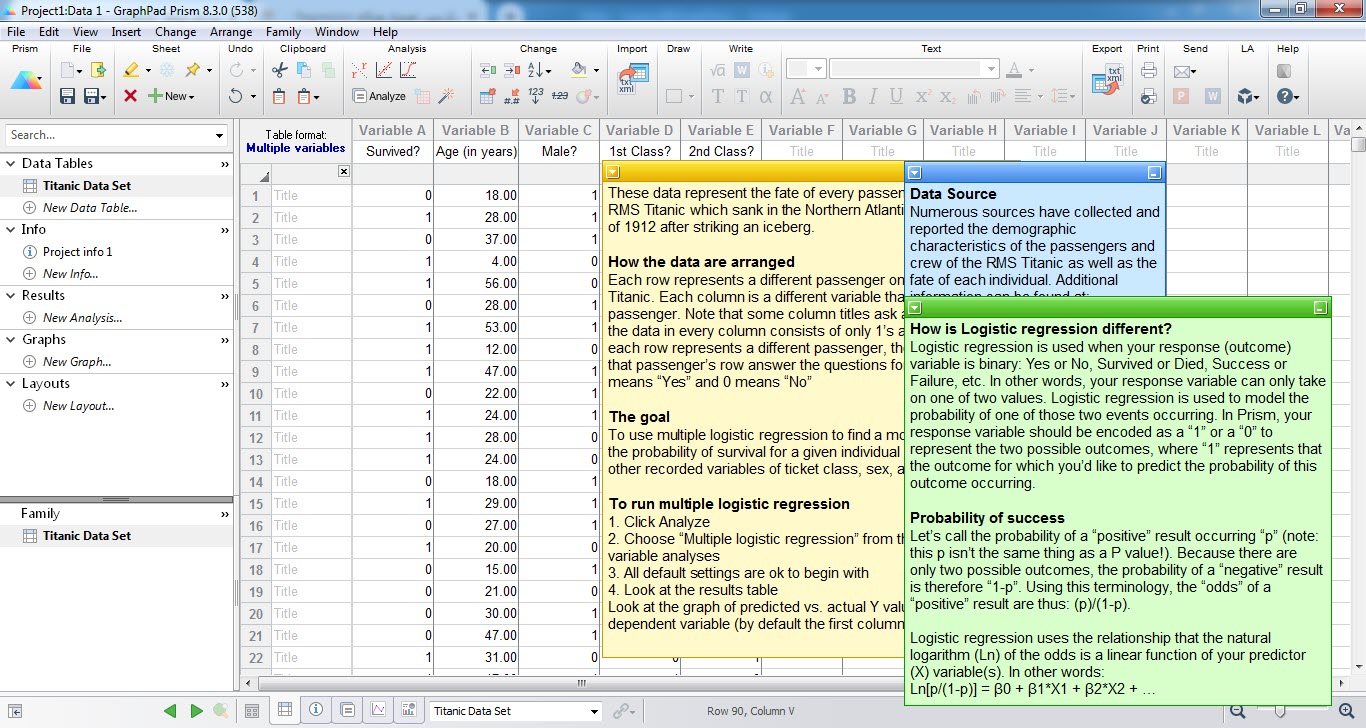
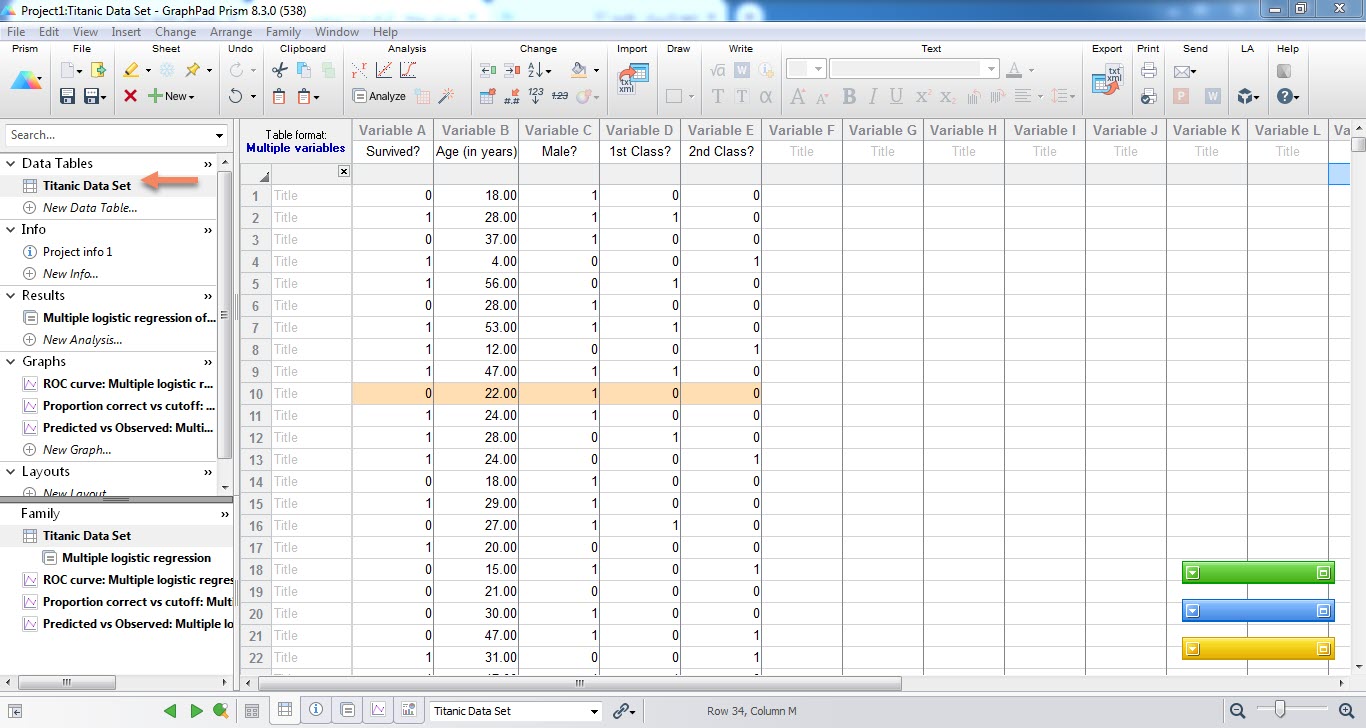
وقتی مثال را Create میکنیم با دادههای زیر روبهرو میشویم. همانگونه که مشاهده میکنید دادهها در چندین ستون بیان شدهاند. ستون با نام Survived همان کمیت پاسخ Y مدل رگرسیون لجستیک است. کد صفر بیانگر مرگ و کد 1 زنده ماندن را نشان میدهد.
همچنین میتوانید چهار X تحت عناوین Age سن، Male که کد صفر زن و کد یک مرد را نشان میدهد، 1st Class و 2nd Class که نوع بلیط هر فرد را بیان میکند (صفر منفی و 1 مثبت) را مشاهده کنید. در این مثال یافتههای مربوط به 1314 فرد آمده است.
همانگونه که بالاتر نیز اشاره کردیم، هنگامی که کمیت پاسخ ما به صورت دو حالتی باشد، از مدلهای رگرسیون لجستیک استفاده میکنیم. در این مثال نیز Y به حالتهای یک، یعنی زنده ماندن و صفر به معنای مرگ، کدبندی شده است.
نکتهای که در این زمینه نرم افزار گراف پد به آن اشاره میکند (در پنجره سبزرنگ Note نیز نوشته شده است.) این است که کدهای کمیت Y به صورت 0 و 1 نوشته شود. کد 1 به معنای مثبت و رخداد و کد 0 به معنای منفی و عدم رخداد، بیان شود.
بنابراین آنچه که در رگرسیون لجستیک به دنبال آن هستیم این است که احتمال 1 شدن و یا همان رخداد و در این مثال زنده ماندن را پیشبینی کنیم. به اختصار احتمال رخداد را با p نشان میدهیم. البته این p با مقدار احتمال P value که سطح معناداری و پذیرش یا رد فرض صفر را نشان میدهد، کاملاً متفاوت است.
به نسبت p/1-p نسبت (شکست/پیروزی) یا (منفی/مثبت) نیز گفته میشود. یک توضیح تئوری کوچک اینکه در مدل رگرسیون لجستیک، لگاریتم این نسبت با Xها رابطه خطی دارد، یعنی
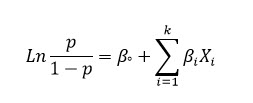
اگر طرفین معادله بالا را نمایی کنیم، به روابط زیر میرسیم.

به این ترتیب میتوانیم مقدار p یا همان احتمال رخداد پیشامد مورد نظر را به دست بیاوریم.
خُب، حال به مثال خود بپردازیم. هدف ما در این مثال، به دست آوردن و پیشبینی احتمال زنده ماندن با استفاده از Xهای مدل یعنی سن، جنسیت، درجه 1 و درجه 2 نوع بلیط میباشد. این کار با استفاده از Logistic Regression قابل انجام است.
در واقع در این مثال ما یک Y و چند X داریم. به همین دلیل به آن Multiple Logistic Regression گفته میشود. اگر فقط یک کمیت مستقل X داشته باشیم، آنگاه مطالعه ما Simple Logistic Regression نامیده میشد.
جهت انجام رگرسیون لجستیک، در شیت دادهها که با نام Titanic Data Set نامیده میشود، بر روی منوی Analyze کلیک کنید تا پنجره Analyze Data به صورت زیر برای ما باز شود.
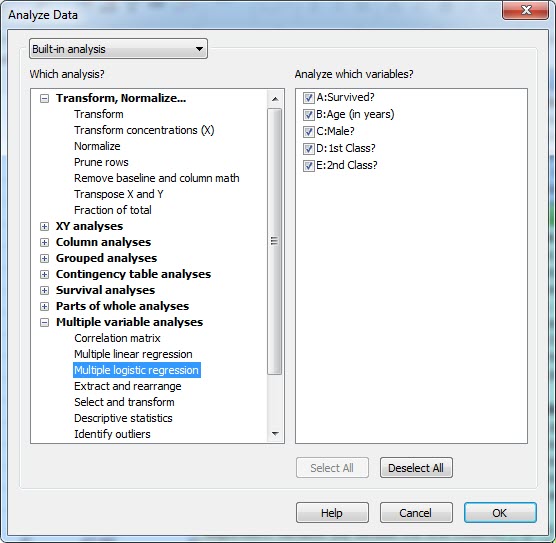
در آنجا و از کادر Multiple variable analyses گزینه Multiple logistic regression را انتخاب میکنیم. پنجره Parameters Multiple Logistic Regression به صورت زیر برای ما باز میشود.
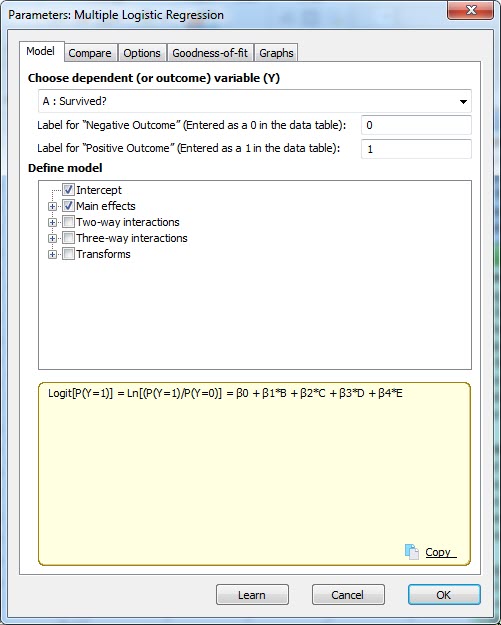
البته میتوانستیم در همان شیت دادهها به صورت مستقیم وارد پنجره Parameters Multiple Logistic Regression نیز شویم. برای اینکار در بالای منوی Analyze بر روی ابزارک Multiple logistic regression کلیک میکنیم.

در ادامه به توضیح بخشها و گزینههای مختلف پنجره Parameters Multiple Logistic Regression که جهت انجام تحلیل رگرسیون لجستیک چندبعدی، استفاده میشود، میپردازیم.
- Model
در این تب و در کادر choose dependent (or outcome) variable Y مشخص میکنیم که کمیت پاسخ که مقادیر صفر و یک را دربر میگرفت، کدام است. به سادگی و بر مبنای شیت دادهها میدانیم که نام آن Survived میباشد. کد صفر به معنای نتیجه منفی Negative outcome و کد یک به معنای نتیجه مثبت Positive outcome شناخته میشود.
در کادر Define model میتوانیم نوع مدل رگرسیون لجستیک خود را انتخاب کنیم. میدانیم که هر مدل رگرسیونی میتواند علاوه بر داشتن ضریب ثابت یا همان Intercept و اثرات اصلی Main effects ، شامل اثرات متقابل چند طرفه Interactions نیز باشد. چنانچه تمایل داشته باشیم میتوانیم این اثرات متقابل را نیز به مدل رگرسیونی خود اضافه کنیم.
بر مبنای مدل انتخاب شده در بخش Define model، در کادر زردرنگ پایین میتوانید معادله مدل رگرسیون لجستیک را مشاهده کنیم. به عنوان مثال مدلی که شامل ضریب ثابت و اثرات اصلی باشد به شکل زیر خواهد بود.
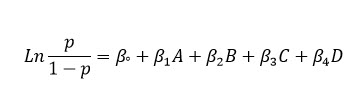
میدانیم که منظور از C، B، A و D به ترتیب همان 1st Class، Male، Age و 2nd Class است.
- Compare
این تب از آن موارد به درد بخور و خاص نرمافزار گراف پد است. با استفاده از آن میتوانیم به مقایسه بین چند منحنی رگرسیونی بپردازیم و پارامترهای به دست آمده از هر مدل را با هم مقایسه کنیم.
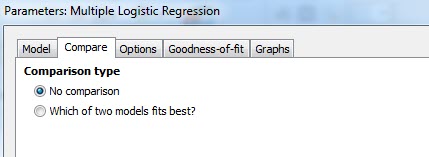
از آنجا که در این مثال تنها یک منحنی رگرسیونی داریم، پس همان گزینه پیشفرض No comparison را میپذیریم. اگر به دنبال مقایسه بین دو منحنی رگرسیونی بودیم گزینه which of two models fits best را انتخاب میکنیم.
- Options
در این تب به انتخاب تنظیمات و گزینههای مختلف تحلیل رگرسیون لجستیک چندگانه، میپردازیم. بخشهای مختلف آن را مشاهده میکنیم.
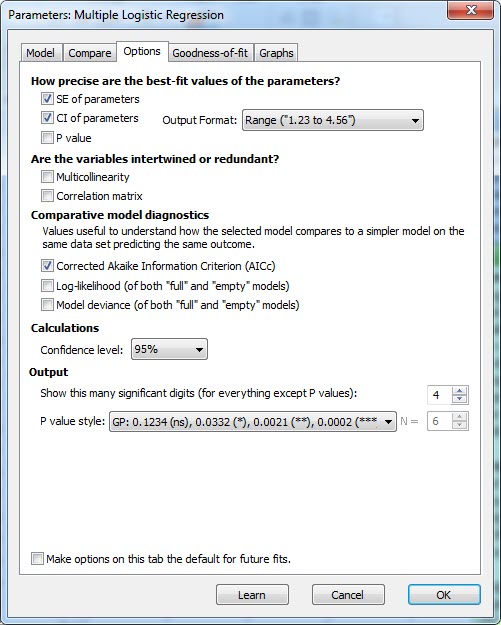
در ابتدا بخشی با نام How precise are the best-fit values of the parameters قرار دارد. در اینجا میتوانیم برای پارامترهای مدل لجستیک، انحراف معیار، فاصله اطمینان و مقدار احتمال به دست بیاوریم. ما این گزینهها را انتخاب میکنیم.

بخش دیگر تب Options با نام Are the variables intertwined or redundant مشاهده میشود.

در این بخش دربارهی درهم تنیدگی Intertwined کمیتهای مستقل Xها در یکدیگر و احتمالاً زاید بودن Redundant آنها، صحبت میشود. با استفاده از بررسی همخطی چندگانه Multicollinearity و ماتریس همبستگی Correlation Matrix این موارد ارزیابی میشود.
یک توضیح کوتاه اینکه همخطی به معنای وجود ارتباط قوی و همبستگی بالا در بین Xهای مدل است. هر چند همخطی در همه مدلهای رگرسیونی وجود دارد اما شدت آن، یک نقیصه به حساب میآید. زیرا وقتی دو یا چند X با یکدیگر همخطی بالایی دارند، دیگر لزومی به آمدن همه آنها در مدل رگرسیونی نیست و زاید هستند.
به هرحال ما در این مثال هم در پی محاسبهی هم خطی و هم ماتریس همبستگی هستیم.
در بخش با نام Comparative model diagnostics آمارهها و معیارهایی جهت ارزیابی مدل قرار دارد. شاخص اطلاع آکائیک اصلاح شده AICc ، لگاریتم درستنمایی Log-likelihood و انحراف مدل Model deviance از جمله این معیارها هستند.

این معیارها به مقایسه بین مدل انتخاب شده در تب Model و بخش Define model، با یک مدل ساده بدون ضرایب رگرسیونی و تنها شامل ضریب ثابت، میپردازد.
به هنگام بیان نتایج میگوییم که انتظار داریم مقادیر این آمارهها در مدل انتخاب شده نسبت به مدل بدون ضرایب رگرسیونی، کمتر باشد.
در بخش calculations به سادگی میتوانیم ضریب اطمینان فاصله اطمینان را مشخص کنیم. به صورت پیشفرض بر روی 95 درصد قرار دارد.

در بخش Output نیز میتوانیم تعداد رقمهای اعشار برای مقدار احتمال P value و قالب نمایش آن را انتخاب کنیم.

- Goodness-of-fit
در این تب انواع آمارهها و معیارهای مناسبت مدل و نیکویی برازش وجود دارد. بخشهای مختلف آن را مشاهده میکنیم.
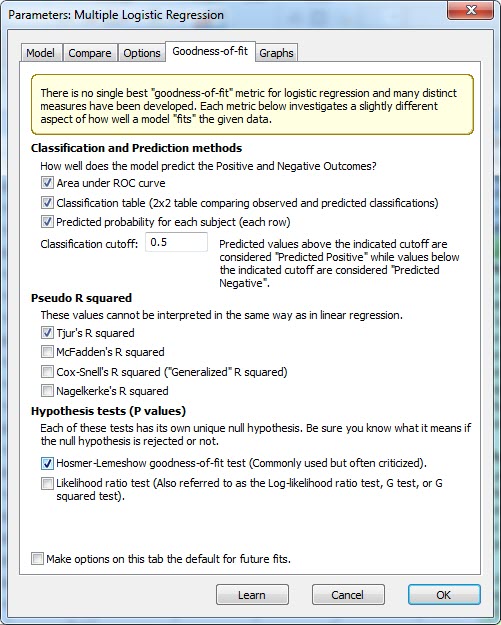
مواردی نظیر رسم منحنی راک ROC Curve ، جدول تعداد پیشبینی – مشاهده و به دست آوردن احتمال برازش شده (زنده ماندن) به ازای هر فرد، در بخش Classification and Prediction methods قرار دارد.
همچنین میتوان Cutoff مدل که به صورت پیشفرض در تحلیلهای رگرسیون لجستیک بر روی عدد 0.5 قرار دارد را ویرایش کرد. نرمافزار اندازههای احتمال کمتر از این عدد را به عنوان یک پیشامد منفی (مرگ) و اندازههای احتمال بیشتر از این عدد را به عنوان پیشامد مثبت (زنده ماندن) در نظر میگیرد.
در بخش Pseudo R square میتوان چندین ضریب تعیین مختلف جهت سنجش مناسب بودن مدل به دست آمده را انتخاب کرد. نرمافزار به صورت پیشفرض Tjur’s R square را انتخاب کرده است.
در بخش Hypothesis tests P values با استفاده از آزمون Hosmer-lemeshow نیز به بررسی نیکویی برازش مدل لجستیک به دست آمده، میپردازیم. فرض صفر در این آزمون صحت مدل انتخاب شده است. نتایج این آزمون را میتوانیم در خروجیهای گراف پد مشاهده کنیم. آزمونی با نام نسبت درستنمایی نیز در این بخش قرار دارد.
در نهایت اینکه در تب Goodness-of-fit پیشفرضهای نرمافزار را میپذیریم.
- Graphs
انواع گرافهای قابل رسم در تحلیل رگرسیون لجستیک چندگانه در تب Graphs دیده میشود. نرمافزار به صورت پیشفرض نمودار Predicted vs Observed که گرافی جهت بررسی فراوانی موارد پیشبینیشده در برابر موارد مشاهده شده و نمودار ROC Curve که با استفاده از آن میتوانیم میزان درستی پیشبینی مدل رگرسیون لجستیک براورد شده را به دست بیاوریم، انتخاب کرده است.

چنانچه علاقمند باشیم و به نظر مناسب نیز است میتوانیم گراف proportion correct vs cutoff که بر مبنای نقاط برش مختلف، میزان درستی مدل را نشان میدهد، به دست بیاوریم. پس ما آن را نیز انتخاب میکنیم.
در پایان با OK کردن میتوانیم تمام نتایج و نمودارهای رسم شده در تحلیل رگرسیون لجستیک چندگانه را مشاهده کنیم.
ابتدا به بررسی شیت نتایج که با نام Multiple logistic regression of Titanic Data Set در فولدر Results پنجره راهبری سمت چپ نرمافزار قرار دارد، میپردازیم.
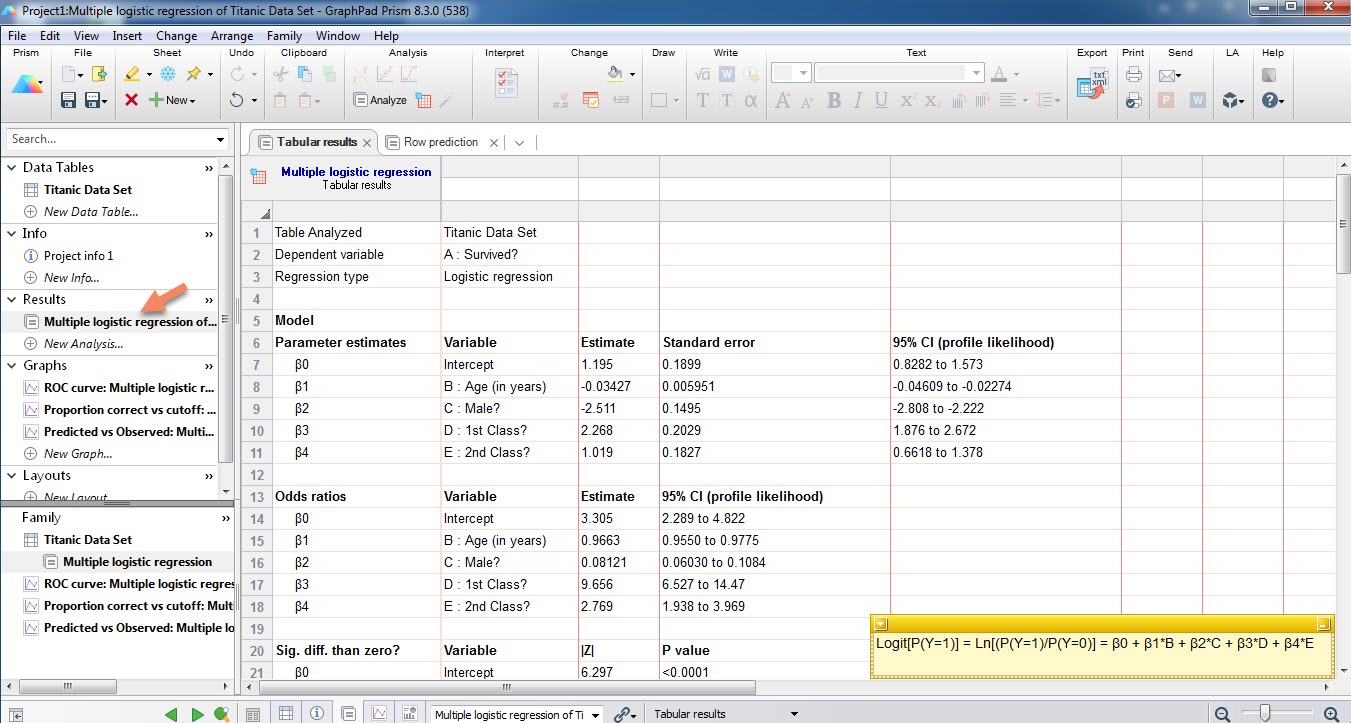
این شیت خود دارای دو زبانه با نامهای Tabular results و Row prediction است. بیایید قبل از هر چیز نتایج تب Row prediction را ببینیم.
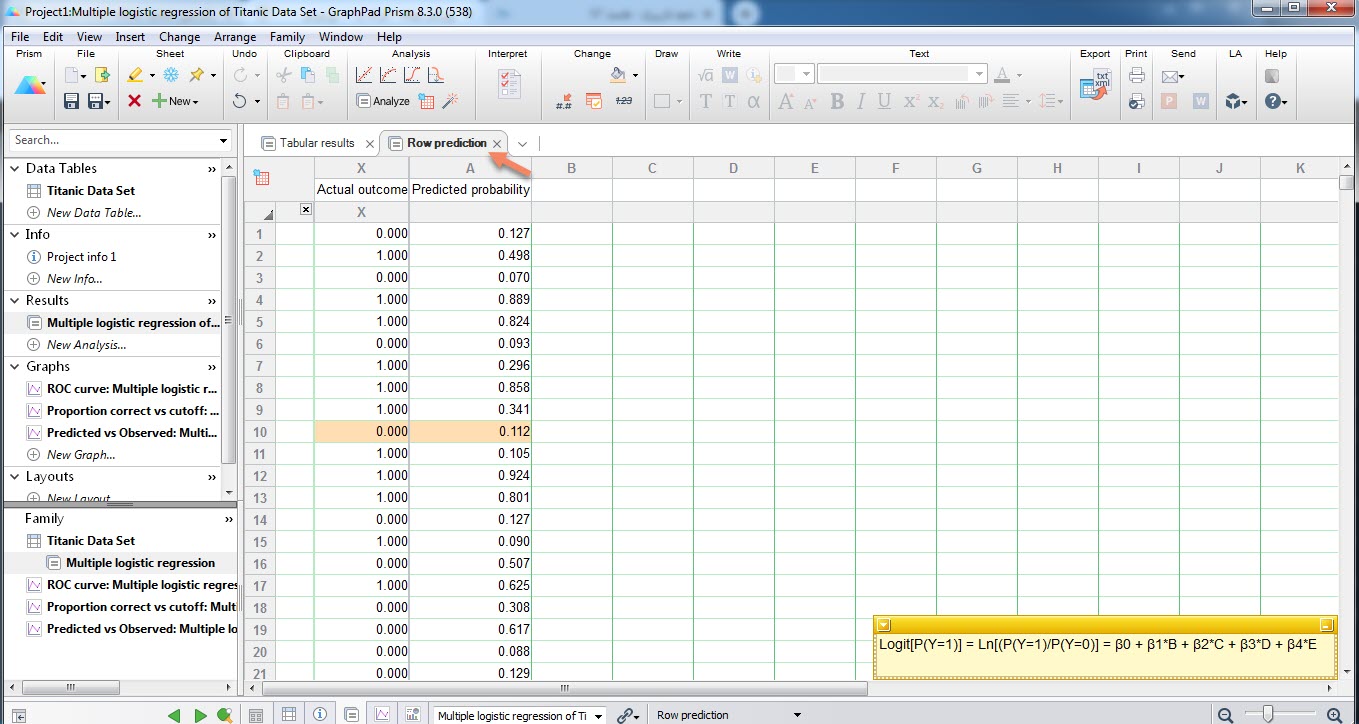
شیت Row prediction به این دلیل در خروجیها آمده است که ما در پنجره تنظیمات و تب Goodness-of-fit گزینه Predicted probability for each subject each row را فعال کردیم.
در این زبانه از شیت نتایج، به ازای هر فرد، احتمال رخداد پیشامد مورد نظر یعنی زنده ماندن به دست آمده است. به عنوان مثال برای فرد سطر دهم احتمال زنده ماندن برابر با 0.112 یا 11.2% به دست آمده است. به شیت دادهها بروید و Xهای این فرد را ببینید.
بر مبنای دادهها، این فرد یک مرد 22 ساله بوده است که نوع بلیط او درجه 1 و 2 نبوده است. مشاهده پاسخ Y نیز نشان میدهد این فرد زنده نمانده است.
در همان تب Row prediction به ازای بقیه افراد یعنی تمام 1314 نفر نیز میتوان احتمال زنده ماندن بر مبنای مدل رگرسیون لجستیک چندگانه برازش شده را مشاهده کرد.
حال به تب Tabular results بروید و به تفکیک نتایج مدل لجستیک را مشاهده کنید. در این تب بر مبنای تنظیماتی که در نرمافزار قرار دادیم، میتوان تمام تحلیلهای انجام شده را مشاهده کرد.
ما در ادامه بخشهای مختلف صفحه نتایج را بیان میکنیم.
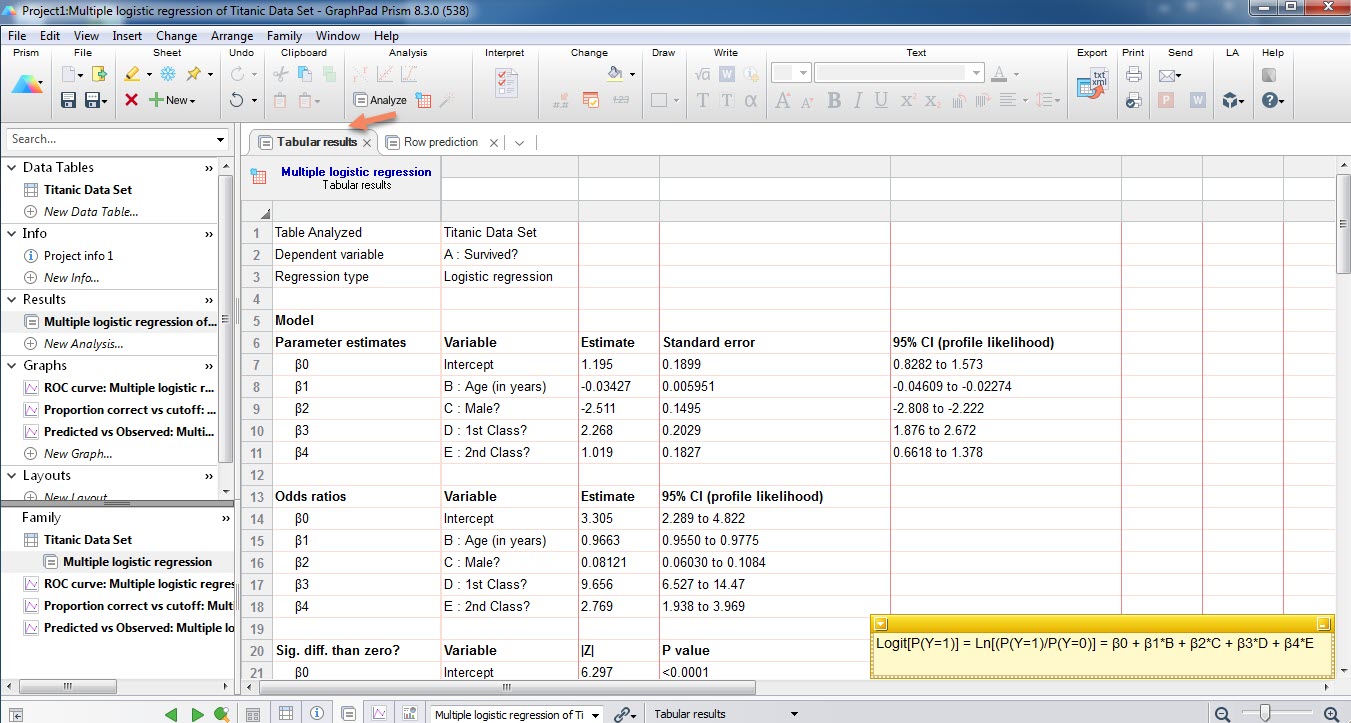
در ابتدا نام فایل دادهها Titanic Data Set، کمیت وابسته Survived? و نوع رگرسیون استفاده شده که همان Logistic regression است، دیده میشود.
- Model
این بخش مهمترین نتایج تحلیل رگرسیون لجستیک را شامل میشود. براورد پارامترهای β4 ، β3 ، β2 ، β1 ، β0 مدل لجستیک چندگانه که به ترتیب ضریب ثابت، سن، جنسیت (مرد)، بلیط درجه 1 و بلیط درجه 2 میباشند، در این بخش قرار گرفته است. منفی شدن β1 و β2 بیانگر وجود ارتباط وارون بین سن و مرد بودن با احتمال زنده ماندن، میباشد. به این معنا که هر چقدر سن فرد افزایش پیدا کند، احتمال زنده ماندن کمتر میشود. همچنین مرد بودن عامل منفی در زنده ماندن است.
به همین ترتیب مثبت شدن β3 و β4 نشان میدهد بین نوع بلیط و زنده ماندن ارتباط مستقیم وجود دارد. به این معنا که اگر فرد دارای بلیط درجه 1 و یا درجه 2 باشد، احتمال زنده ماندن او بیشتر میشود.

علاوه بر براورد پارامترها، خطای استاندارد و فواصل اطمینان 95 درصد به ازای هر پارامتر نیز در جدول بالا آمده است. خوبی فواصل اطمینان این است که با استفاده از آنها و حتی بدون داشتن مقادیر احتمال P value، میتوانیم تاثیر معناداری یا عدم معنادار آن پارامتر بر روی زنده ماندن را به دست آوریم.
در این زمینه توضیح اینکه اگر فواصل اطمینان شامل عدد صفر باشند، نتیجه میگیریم آن پارامتر تاثیر معنادار بر Y یا همان پاسخ ندارد.
اگر هر دو کران فاصله اطمینان از عدد صفر کمتر و منفی باشند، بیانگر وجود ارتباط معنادار آن هم از نوع وارون بین آن X با Y است. به عنوان مثال در اینجا سن و جنسیت (مرد) دارای فواصل اطمینان منفی هستند. بنابراین بدون دیدن مقدار احتمال آنها میتوانیم نتیجه بگیریم ارتباط بین سن و جنسیت با زنده ماندن معنادار و واورن است.
اگر هر دو کران فاصله اطمینان از عدد صفر بیشتر و مثبت باشند، بیانگر وجود ارتباط معنادار از نوع مستقیم بین آن X با Y است. به عنوان مثال در اینجا داشتن بلیط درجه 1 و 2 دارای فواصل اطمینان مثبت هستند. بنابراین حتی بدون دیدن مقدار احتمال آنها میتوانیم نتیجه بگیریم ارتباط بین آنها با زنده ماندن معنادار و مستقیم است.
به این ترتیب با استفاده از اعداد به دست آمده برای همین پارامترها، میتوان احتمال زنده ماندن برای هر فرد را محاسبه کرد. به این ترتیب مدل رگرسیون لجستیک چندگانه در مثال ما به صورت زیر خواهد بود.

با استفاده از این مدل میتوانیم با قرار دادن Xهای دلخواه به ازای هر فرد حتی خارج از این مطالعه، احتمال زنده ماندن او را محاسبه کنیم.
- Odds ratios
نسبت بخت و یا همان Odds Ratio که به اختصار به آن OR نیز گفته میشود، از مهمترین نتایج تحلیل رگرسیون لجستیک به حساب میآید. در جدول زیر نسبت بختها به همراه فواصل اطمینان 95 درصد آنها، به ازای هر کدام از Xهای مدل بیان شده است.

نسبت بخت نشان میدهد هر پارامتر به چه اندازه بر مثبت شدن پاسخ، اثر گذار است. در این مثال به این معنا که هر کدام از عوامل سن، جنسیت و نوع بلیط، احتمال زنده ماندن را چند برابر افزایش یا کاهش میدهد.
برای شروع مثلاً از β4 و یا همان بلیط درجه دو شروع میکنیم. عدد OR براورد شده برای این X برابر با 2.769 به دست آمده است. این عدد حاصل نمایی شدن ضریب رگرسیونی β4 یعنی eβ4 = e1.019 = 2.769 میباشد. عدد 2.769 به دست آمده برای نسبت بخت بلیط درجه دو نشان میدهد، داشتن بلیط درجه دو میتواند احتمال زنده ماندن را 2.769 برابر (حدود 2.8 برابر) افزایش دهد.
به همین ترتیب OR به دست آمده برای بلیط درجه یک برابر با 9.656 شده است. این عدد نشان میدهد اگر فردی دارای بلیط درجه یک بوده است، احتمال زنده ماندن او حدود 9.7 برابر افزایش پیدا میکرده است.
نسبت بخت برای سن و جنسیت (مرد) کمتر از عدد یک به دست آمده است. این مطلب به دلیل منفی بودن ضریب رگرسیونی در این فاکتورها بوده است. (از دیدگاه ریاضی، وقتی یک عدد منفی نمایی شود نتیجه حاصل عددی بین صفر تا یک خواهد بود.) در این گونه موارد و هنگامی که OR از عدد یک کمتر است، به منظور فهم بهتر نتیجه به دست آمده، وارون OR را گزارش میکنیم.
به عنوان مثال برای جنسیت مرد، نسبت بخت برابر با 0.08121 به دست آمده است. این عدد حاصل عبارت ریاضی eβ2 = e-2.511 = 0.08121 میباشد.
به منظور فهم بهتر این عدد را وارون میکنیم، یعنی [pmath] (1/0.08121) = 12.31 [/pmath]. نتیجه به دست آمده نشان میدهد مرد بودن شانس زنده ماندن را به اندازه 12.31 برابر کاهش میدهد.
همین کار را برای سن نیز انجام میدهیم. OR آن برابر با 0.9663 شده است. این عدد حاصل عبارت ریاضی eβ1 = e-0.03427 = 0.9663 میباشد و نشان میدهد افزایش یک سال سن میتواند به اندازه [pmath] (1/0.9663) = 1.03 [/pmath] برابر شانس زنده ماندن را کم میکند.
در جدول بالا فواصل اطمینان 95 درصد برای OR نیز آمده است. همان تعاریفی که برای فواصل اطمینان ضرایب رگرسیونی داشتیم، اینجا نیز برقرار است. منتهی از آنجا که نمایی شده عدد صفر، یک خواهد بود (e0 = 1 )، مبنای ما به جای صفر، عدد یک خواهد بود.
یعنی اگر فاصله اطمینان نسبت بخت شامل عدد یک باشد، نشان میدهد آن فاکتور عامل موثر معناداری بر پاسخ (در این مثال زنده ماندن) نیست. اگر هر دو کران فاصله اطمینان کمتر از یک باشد بیانگر تاثیرگزاری وارون و معنادار بر پاسخ است و اگر هر دو کران فاصله اطمینان بیشتر از یک باشد بیانگر تاثیرگزاری مستقیم و معنادار بر پاسخ است.
- Sig. diff. than zero?
ما در نتایج قبلی به توضیح ضرایب رگرسیونی پرداختیم، با این حال در هر مدل رگرسیونی اعم از خطی و یا غیرخطی، این مطلب مورد سوال است که آیا وجود و تاثیر Variable مستقل X بر روی پاسخ Y معنادار است یا خیر؟ در این مثال و در رگرسیون لجستیک چنگانه نیز ما به دنبال پاسخ به این سوال هستیم که آیا کمیتهایی مانند سن، چنسیت و نوع بلیط بر روی احتمال زنده ماندن افراد، تاثیر معنادار داشته است یا خیر.

در بخش Sig. diff. than zero? که نتایج آن را در جدول بالا مشاهده میکنید، به این سوال پاسخ داده شده است. P value و مقدار احتمال به دست آمده برای هر کمیت، نشان میدهد همهی آنها دارای تاثیر معنادار بر احتمال زنده ماندن افراد داشتهاند. در بخشهای بالاتر اندازه افزایشی و یا کاهشی این تاثیر را بیان کردیم.
- Model diagnostics
چنانچه یادتان باشد در پنجره تنظیمات Parameters Multiple Logistic Regression و تب Options بخشی با نام Comparative model diagnostics که در آن آمارهها و معیارهایی جهت ارزیابی مدل قرار دارد، وجود داشت. در این بخش شاخص اطلاع آکائیک اصلاح شده AICc ، لگاریتم درستنمایی Log-likelihood و انحراف مدل Model deviance گزارش میشد.
این معیارها به مقایسه بین مدل انتخاب شده در تب Model و بخش Define model یعنی مدل شامل سن، جنست، بلیط درجه 1 و 2 با یک مدل ساده بدون ضرایب رگرسیونی و تنها شامل ضریب ثابت، میپرداخت.
همانگونه که در آنجا بیان کردیم، انتظار داریم مقادیر این آمارهها در مدل انتخاب شده نسبت به مدل بدون ضرایب رگرسیونی، کمتر باشد. حال در جدول زیر میتوانید نتایج این بخش را مشاهده کنید.

در سطر اول آمارههای مربوط به مدل ساده و فقط شامل ضریب ثابت به دست آمده است. این مدل به صورت (p/1-p) = eβ0 است و ضرایب رگرسیونی در آن وجود ندارد.
در سطر بعدی آمارههای مدل کامل و شامل ضرایب رگرسیونی قرار گرفته است.
این آمارهها معمولاً بیان میکنند که استفاده از یک مدل رگرسیونی به چه میزان اطلاعات را از دست میدهد. بنابراین هر چقدر عدد آن کمتر باشد، نشان میدهد ان مدل بهتر است. همانگونه که مشاهده میشود، مدل شامل ضرایب رگرسیونی نسبت به مدل ساده، ارجحیت دارد و آمارههای اطلاع آکائیک اصلاح شده AICc ، لگاریتم درستنمایی Log-likelihood و انحراف مدل Model deviance آن کمتر است.
- Multicollinearity
ما در پنجره Parameters Simple Logistic Regression و در تب Options در بخش Are the variables intertwined or redundant به هنگام تنظیمات مدل، گزینههای Multicollinearity و Correlation Matrix را جهت به دست آوردن نتایج همخطی و ماتریس همبستگی، فعال کردیم. در جدول زیر میتوانید نتایج هم خطی بین Variableها را مشاهده کنید.
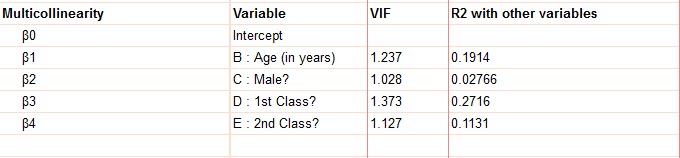
هم خطی با آمارهای به نام فاکتور تورم واریانس Variance Inflation Factor (VIF) سنجیده میشود. اندازه VIFها نشان میدهد با همبسته بودن کمیتها به یکدیگر، واریانس ضریب رگرسیونی براورد شده به چه میزان افزایش مییابد.
اگر VIF نزدیک به یک باشد، همخطی بین آن X با کمیتهای دیگر وجود ندارد، اما اگر VIFها از یک بزرگتر باشند، همخطی بین آن X با کمیتهای دیگر وجود دارد. وقتی VIF > 5 باشد، ضریب رگرسیونی به دست آمده برای آن جمله، مناسب نیست و معمولاً آن X را حذف میکنیم.
همانگونه که در جدول بالا دیده میشود VIFها چندان بالا نیست و نزدیک به یک قرار دارد. به این ترتیب میتوان گفت که بین آنها هم خطی وجود ندارد.
در جدول بالا ستون دیگری با نام R2 with other variables دیده میشود. اعداد به دست آمده برای هر کمیت نشان میدهد که اگر آن X نقش Y را در یک مدل رگرسیون خطی داشته باشد و سپس ما بین آن X که دیگر Y شده است و سایر X ها یک مدل رگرسیونی برقرار کنیم، در آن صورت، ضریب تعیین این مدل رگرسیونی چقدر خواهد بود.
به عنوان مثال عدد 0.1914 برای Age بیان میکند که اگر یک مدل رگرسیونی خطی بین Age از یک طرف و جنسیت، نوع بلیط درجه 1 و 2 از طرف دیگر برقرار کنیم، ضریب تعیین یا همان R2 این مدل رگرسیونی جدید حدود 19.14 درصد خواهد بود.
همانگونه که میدانیم R2 عددی بین صفر و یک است و هرچقدر به یک نزدیکتر باشد، نشاندهندهی وجود ارتباط قویتر بین کمیت پاسخ Y با سایر کمیتهای مستقل Xها میباشد.
در جدول بالا R2 ها چندان بالا نیست. جنسیت که دارای کمترین ضریب تعیین است، عدد VIF آن نیز کمترین مقدار در مقایسه با سایر کمیتها شده بود. این مطلب نشان میدهد جنسیت ارتباط خیلی ضعیفی با سایر Xها یعنی سن و نوع بلیط دارد. این اتفاق خوب است. در واقع در مدلهای رگرسیونی مطلوب آن است که بین Xها همخطی وجود نداشته باشد و اندازههای VIF آن نزدیک به یک و R2 with other variables در اطراف صفر باشد.
- Correlation matrix
در ادامه همان مباحث هم خطی که در بالا به آن اشاره کردیم، نرمافزار گراف پد ماتریس همبستگی بین کمیتهای مستقل را نیز رسم کرده است. این ماتریس که آرایههای آن عدد ضریب همبستگی بین هر X با X دیگر میباشد، نشان میدهد ارتباط جفتی بین کمیتهای مستقل با یکدیگر چگونه است.

به عنوان مثال عدد 0.5113- نشان میدهد ارتباط بین سن و بلیط درجه 1 وارون و منفی و اندازه آن حدود 51 درصد میباشد. برای بقیه Xها نیز عدد ضریب همبستگی به دست آمده است.
- Area under the ROC curve
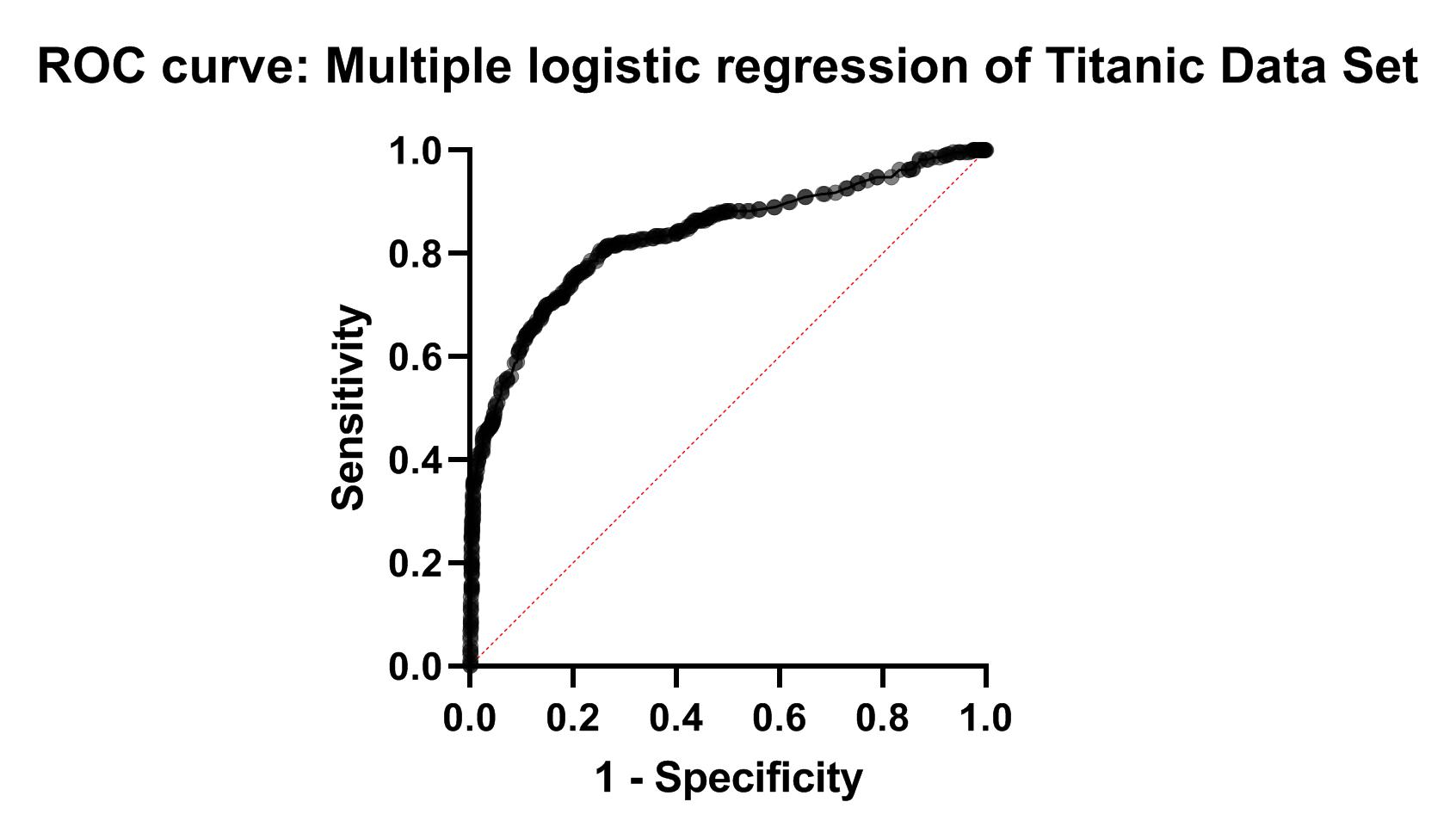
چنانچه خاطرتان باشد در پنجره Parameters Multiple Logistic Regression و به هنگام تنظیمات مدل، گزینههای Classification and prediction methods را جهت رسم منحنی راک فعال کردیم. در جدول زیر اندازه AUC و مساحت زیر منحنی ROC آمده است. در زمینه منحنی راک میتوانید این لینک را در سایت گراف پد ببینید.

عدد حدود 0.8341 برای Area نشان میدهد مدل لجستیک به دست آمده میتواند تا حدود 83 درصد موارد مرگ یا زنده ماندن را به درستی پیشبینی کند. مقدار احتمال P value <0.001 به دست آمده، نشاندهنده این است که مدل لجستیک توانایی مناسبی جهت تشخیص مرگ یا زنده ماندن در بین افراد مورد بررسی را دارد.
در شکل زیر منحنی راک ROC Curve این مثال که در شیت با نام ROC curve: Multiple logistic regression of Titanic Data Set در فولدر Graphs پنجره راهبری نرمافزار قرار دارد، آمده است.
- Classification table
جدول تعداد پیشبینی – مشاهده، در ادامه آمده است. میدانیم که کد صفر به معنای مرگ و کد یک به معنای زنده ماندن میباشد. در جدول زیر سطرها، مشاهدات واقعی و ستونها پیشبینی مدل رگرسیون لجستیک به دست آمده را نشان میدهند.
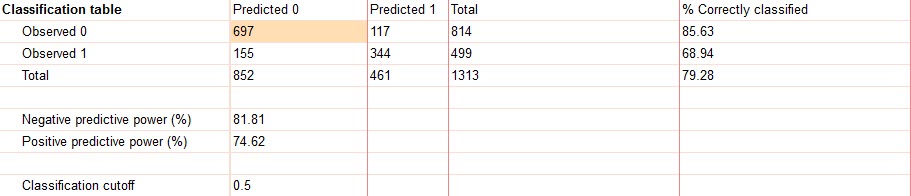
به عنوان مثال عدد 697 بیانگر آن است که 697 نفر که واقعاً دچار مرگ شدهاند، مدل نیز به خوبی پیشبینی مرگ کرده است. در 117 نفر مدل (به اشتباه) زنده ماندن پیشبینی کرده در حالیکه در واقعیت آنها دچار مرگ شدهاند. به این ترتیب در حالت کلی 814 نفر مردهاند و مدل در بین این افراد 85.63 درصد (697/814) به درستی پیشبینی کرده است.
همچنین از مجموع 1313 نفر تحت مطالعه 499 نفر زنده ماندهاند. مدل به درستی 344 نفر را زنده پیشبینی میکند (68.94 درصد) اما برای 155 نفر اشتباه در پیشبینی دارد.
در حالت کلی نیز مدل رگرسیون لجستیک چندگانه حدود 79.28 درصد درستی پیشبینی دارد.
توان پیشبینی منفی که حاصل تقسیم عدد 697 (تعداد افرادی که به درستی پیشبینی مرگ داشتهاند) بر 852 (تمام افرادی که بر مبنای مدل فوت کردهاند) برابر با 81.81 درصد به دست آمده است.
توان پیشبینی مثبت که حاصل تقسیم عدد 344 (تعداد افرادی که به درستی پیشبینی زنده ماندن داشتهاند) بر 461 (تمام افرادی که بر مبنای مدل زنده ماندهاند) برابر با 74.62 درصد به دست آمده است.
نکته. شاید تا به اینجا برای شما این سوال پیش آمده باشد که مدل چگونه یک فرد را زنده و یا مرده پیشبینی میکند؟ آنچه که مدل لجستیک به دست میدهد تنها احتمال زنده ماندن هر فرد است که ما آن را در شیت Row prediction دیدهایم، پس مدل از کجا حکم میکند که چند نفر زنده ماندهاند و چند نفر فوت کردهاند؟
این سوال خوبی است و پاسخ به آن در Classification cutoff قرار دارد. ما در تنظیمات نرمافزار و همانگونه که در خروجی دیده میشود عدد آن را 0.5 در نظر گرفتهایم. پاسخ دقیق به سوالا بالا این است که برای هر فردی که احتمال زنده ماندن آن (یعنی همان احتمال به دست آمده در شیت Row prediction) از عدد 0.5 کمتر باشد آن را بر مبنای مدل، فرد مرده در نظر میگیریم و اگر احتمال زنده ماندن او از 0.5 بیشتر باشد، آن فرد را بر مبنای مدل زنده در نظر میگیریم.
به این ترتیب از آنجا که احتمال زنده ماندن به دست آمده از مدل رگرسیون لجستیک در 852 نفر کمتر از 0.5 بوده و نرمافزار این تعداد افراد را مرده فرض میکند. به همین ترتیب احتمال زنده ماندن در 461 نفر بیشتر از 0.5 بوده، پس نرمافزار این تعداد افراد را زنده فرض میکند. به همین سادگی.
- Pseudo R square
همانگونه که میدانیم R square که در فارسی به آن ضریب تعیین میگوییم عددی بین صفر تا یک است و نشاندهندهی آن است که مدل رگرسیونی به دست آمده تا چه اندازه میتواند پراکندگی دادههای واقعی را تحت پوشش خود قرار دهد. در واقع ضریب تعیین میتواند ابزاری جهت سنجش قدرت پیشبینیکنندگی و خوب بودن مدل باشد. هر چه عدد R square به مقادیر یک نزدیکتر باشد، بیانگر بهتر بودن مدل رگرسیون به دست آمده است.
![]()
اما هنگامی که با مدل رگرسیون لجستیک روبهرو هستیم R square با نام Pseudo و یا شبه ضریب تعیین نامیده میشود. دلیل این نامگزاری تفاوت بین نحوه به دست آوردن ضریب تعیین در یک مدل رگرسیون خطی با رگرسیون غیرخطی لجستیک است که نرمافزار گراف پد در تنظیمات خود به آن نیز اشاره کرده است. همانگونه که در جدول بالا مشاهده میکنید اندازه عددی Tjur’s R square که گراف پد به صورت پیشفرض آن را در بخش Pseudo R square انتخاب کرده بود (در تب Goodness-of-fit میتوانیم سایر ضرایب تعیین را نیز مشاهده کنیم.) برابر با 0.3657 به دست آمده است.
این عدد چندان بالا نیست و نشان میدهد مدل رگرسیون لجستیک به دست آمده میتواند حدود 36.57 درصد پراکندگی دادهها را تحت پوشش خود قرار دهد.
- Hypothesis tests
یادتان باشد در پنجره تنظیمات رگرسیون لجستیک و در تب Goodness-of-fit بخش Hypothesis tests P values آزمون Hosmer-lemeshow را انتخاب کردیم. با استفاده از این آزمون به بررسی نیکویی برازش مدل لجستیک به دست آمده، میپردازیم. بیان کردیم که فرض صفر در این آزمون صحت مدل انتخاب شده است. نتایج این آزمون را میتوانیم در جدول زیر مشاهده کنیم.
![]()
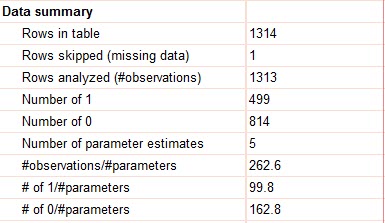
- Data summary
در این بخش خلاصهای از دادههای مثال رگرسیون لجستیک چندگانه را مشاهده میکنید. جدول زیر بیان میکند که 1314 سطر (فرد) مورد بررسی قرار گرفته است. یک فرد دارای داده گمشده Missing data که شامل افراد دارای عدم پاسخ است، در این مثال دیده میشود. بنابراین 1313 نفر در این مطالعه قرار گرفتهاند.
499 فرد کد 1 یعنی زنده ماندن و 814 نفر دارای کد صفر به معنای مرگ، بودهاند.
تعداد پنج پارامتر یعنی همان پارامترهای β4 ، β3 ، β2 ، β1 ، β0 که به ترتیب بیانگر ضریب ثابت، سن، جنسیت، بلیط درجه 1 و بلیط درجه 2 میباشند، براورد شده است. نسبت تعداد افراد به پارامترها یعنی 1313/5 برابر با 262.6 و نسبت تعداد افراد زنده و تعداد افراد مرده به تعداد پارامترهای براورد شده به ترتیب برابر با 99.8 و 162.8 است.
آنچه در این مثال همچنان باقی مانده است، مشاهده و رسم گرافهای متناظر با تحلیل رگرسیون لجستیک چندگانه میباشد. در فولدر Graphs پنجره سمت چپ میتوان عناوین سه شیت با نامهای ROC curve: Multiple logistic regression of Titanic Data Set و Proportion correct vs cutoff: Multiple logistic regression of Titanic Data Set و Predicted vs Observed: Multiple logistic regression of Titanic Data Set را مشاهده کرد.

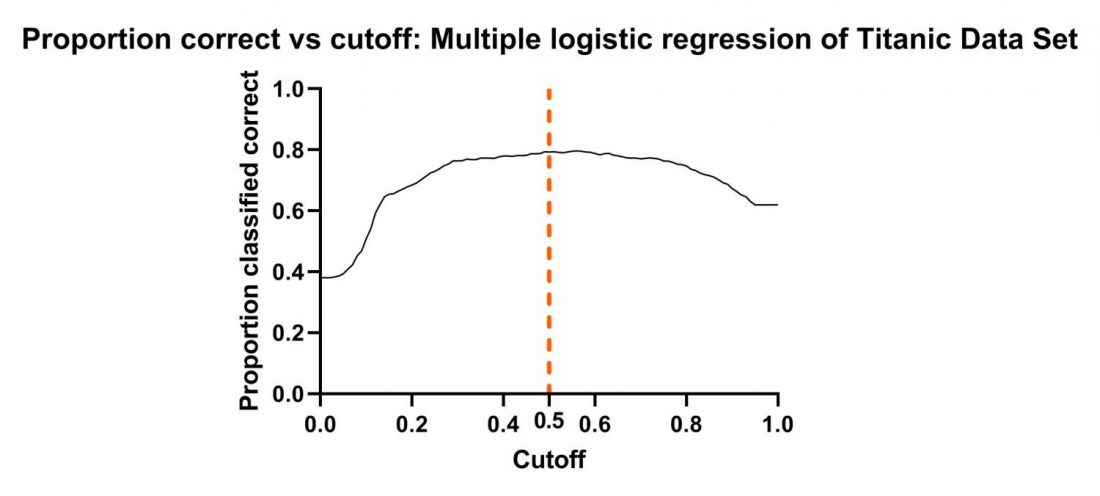
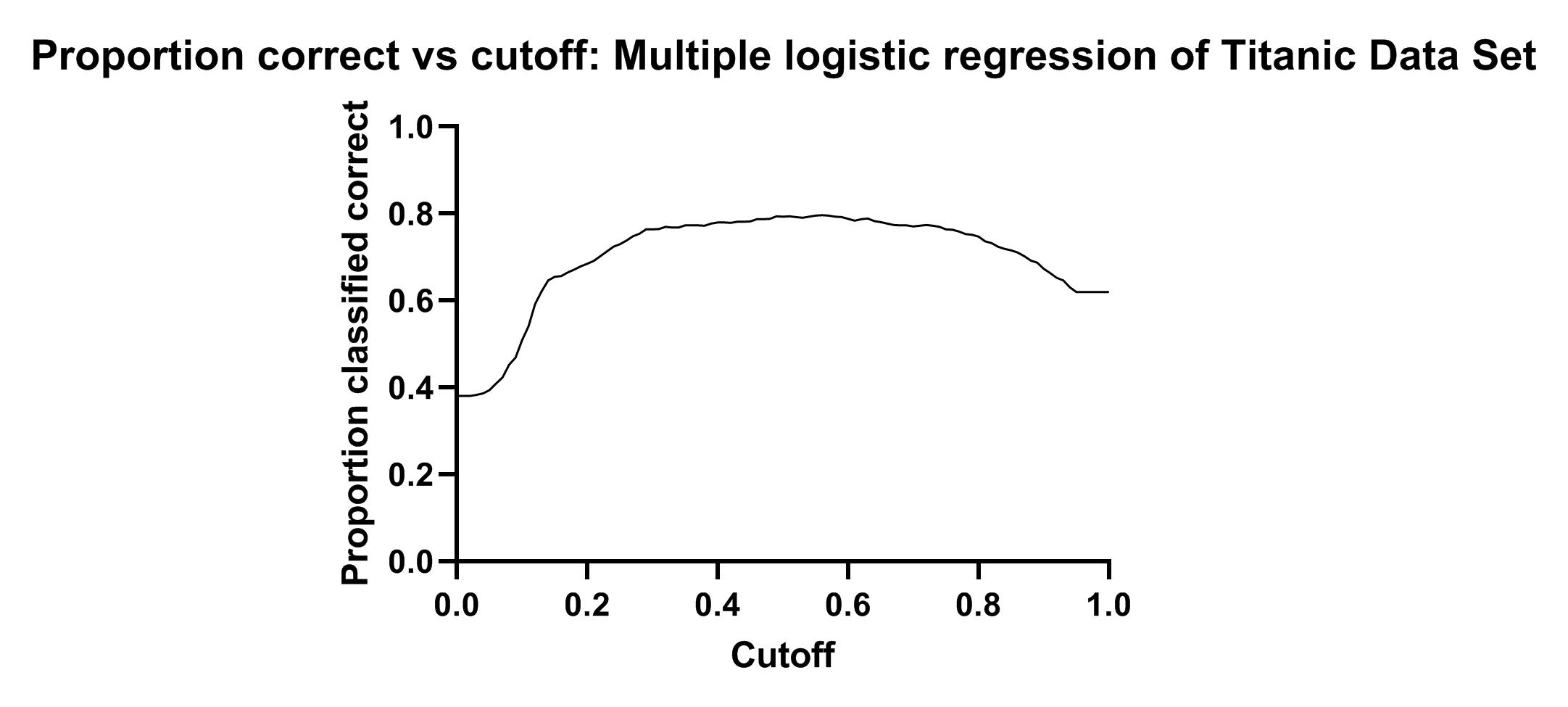
در بالا و به هنگام بیان نتایج سطح زیر منحنی راک از گراف ROC curve: Multiple logistic regression of Titanic Data Set صحبت کردیم. در ادامه با کلیک بر روی شیت Proportion correct vs cutoff: Multiple logistic regression of Titanic Data Set گراف زیر برای ما باز میشود.
یادتان باشد در بالا و در نتایج Classification table نسبت درستی پیشبینی مدل به ازای مشاهدات با کدهای صفر و یک را بیان کردیم. در همانجا گفتیم که معیار ما جهت قرار گرفتن یک فرد در گروه افراد زنده مانده یا فوت شده، عدد Classification cutoff و مقایسه آن با احتمال زنده ماندن هر فرد (به دست آمده در شیت Row prediction) است.
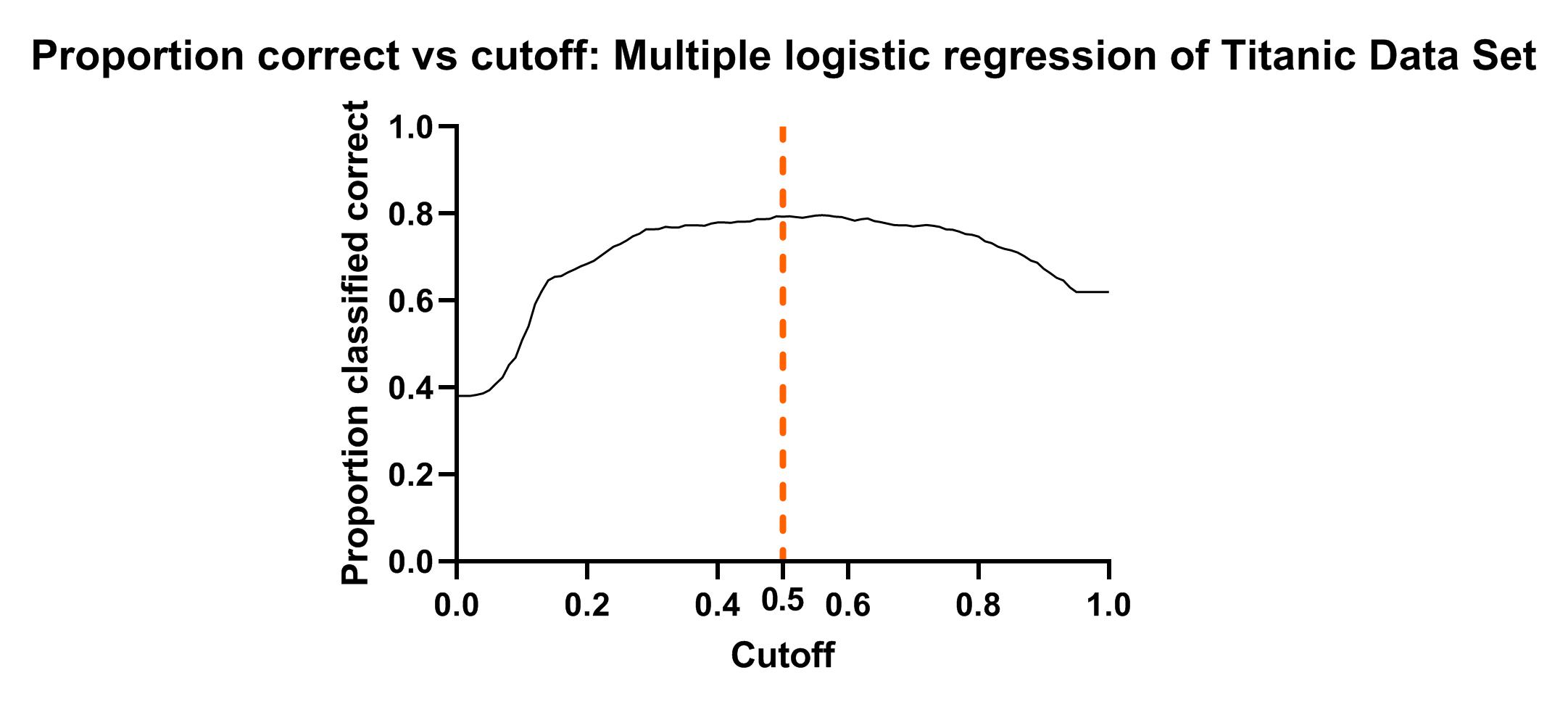
گراف بالا به ازای Cutoffهای مختلف، درصد درستی (Total) مدل رگرسیون لجستیک را برای ما به دست میدهد. ما در گراف زیر Cutoff مثال خودمان که برابر با 0.5 قرار دادیم را مشخص کردهایم.
همچنین در فولدر Graphs شیت دیگری با نام Predicted vs Observed: Multiple logistic regression of Titanic Data Set دیده میشود. گراف آن را در شکل زیر میبینید.

در این گراف محور عمودی، احتمال پیشبینی شده زنده ماندن توسط مدل لجستیک به دست آمده است. در محور افقی نیز دو گروه افراد فوت شده (کد صفر) و زنده مانده (کد یک) دیده میشود. شکل رسم شده نیز فراوانی افراد را نشان میدهد.
به عنوان مثال در کد صفر، احتمالهای نزدیک به صفر عریضتر و پهنتر است. به همین ترتیب در همین کد، احتمالهای نزدیک به یک، باریکتر مشاهده میشود. این مطلب به درستی نشان میدهد که در افراد فوت شده، نرمافزار به خوبی توانسته است تعداد افراد بیشتری را دارای احتمال زنده ماندن نزدیک به صفر نشان دهد و افراد کمی بودهاند که نرمافزار به اشتباه، احتمال زنده ماندن آنها را زیاد بیان کرده است. در بخش Classification table دیدیم که نسبت درستی پیشبینی برای این افراد حدود 85.63 درصد به دست آمده بود.
در کد یک یعنی افراد زنده مانده، اوضاع به خوبی کد صفر نبوده است. به نظر میرسد در این مثال پیشبینی احتمال مرگ یا زنده ماندن، در افراد فوت شده نسبت به افراد زنده مانده، بهتر انجام شده است.
به هر حال در بین افراد زنده مانده، گراف احتمالهای نزدیک به یک پهنتر است. احتمالهای نزدیک به صفر، باریکتر مشاهده میشود. اما خیلی هم باریک نیست. در حالیکه برای داشتن یک مدل خوب باید گراف در قسمت نزدیک به صفر، باریکتر باشد. همانگونه که در بخش Classification table دیدیم نسبت درستی پیشبینی برای افراد زنده مانده چندان بالا نبود و 68.94 درصد به دست آمده بود.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). Multiple Logistic Regression in GraphPad Prism software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/multiple-logistic-regression-prism/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). Multiple Logistic Regression in GraphPad Prism software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/multiple-logistic-regression-prism/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.