تحلیل مدل رگرسیون پواسن Poisson Regression با نرمافزار گراف پد
یکی از تحلیلهایی که در ورژنهای جدید گراف پد (8 به بعد) قرار گرفته است، مدلهای رگرسیون پواسن Poisson Regression است.
این مدل در دادههایی مورد استفاده قرار میگیرد که Y و یا همان پاسخ و کمیت وابسته ما دارای توزیع پواسن Poisson Distribution باشد و بخواهیم بین Y و کمیتهای مستقل X، یک ارتباط رگرسیونی به دست بیاوریم.
در زمینه تئوریهای رگرسیون پواسن، بحثهای زیادی وجود دارد. با این حال سعی میکنم در ابتدای متن، توضیحات مختصری درباره آن بیان کنم.
میدانیم که توزیع احتمال پواسن با پارامتر λ به صورت زیر است.
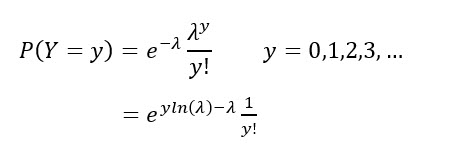
در دادههایی که دارای توزیع پواسن هستند، میانگین و واریانس آنها برابر بوده و به اندازه همان پارامتر توزیع پواسن یعنی λ است.
رابطهی متصل به y را که شامل پارامترهای مدل (یعنی λ) است، نگاه کنید. این رابطه را پارامتر طبیعی توزیع پواسن مینامیم. در این توزیع رابطه، (ln (λ را پارامتر طبیعی مینامیم.
جالب است که بدانید مدل رگرسیون پواسن از مفهوم پارامتر طبیعی توزیع پواسن ساخته میشود. در واقع کمیت پاسخ y در مدل رگرسیون پواسن، همان پارامتر طبیعی توزیع پواسن است. یعنی
y = f ( x1 , x2 , …,xk ) + ε → ln (λ) = f ( x1 , x2 , …,xk ) + ε
که در آن λ پارامتر توزیع پواسن است و x1 , x2 ,…, xk کمیتهای رگرسیونی هستند که با استفاده از ابزار تابعی f به کمیت پاسخ y متصل شده و بین آنها ارتباط برقرار میشود. ε نیز به عنوان خطا و اشتباه در پیشبینی، استفاده میشود.
با تعریف تابع f به صورت خطی، مدل رگرسیون غیرخطی پواسن به صورت زیر تعریف میشود.
ln (λ) = ß0 + ß1x1 + ß2x2 + … + ßkxk + ε
در این مدل جنس کمیت پاسخ از نوع «پارامتر» است و ارتباط بین این پارامتر با کمیتهای مستقل X را به دست میدهد. رابطه بالا را میتوانیم به صورت زیر نیز بنویسیم
λ = eß0 + ß1x1 + ß2x2 + … + ßkxk + ε
مدل به دست آمده که از آن با نام مدل رگرسیون پواسن یاد میشود به خوبی میتواند تاثیر هر یک از کمیتها را بر پارامتر لاندا اندازه بگیرد و تاثیر معنادار یا غیرمعنادار کمیتها را ارزیابی کند.
حال در ادامه بیایید به مثال نرمافزار GraphPad Prism در زمینه مدل رگرسیون پواسن بپردازیم.
این مثال با نام Poisson regression در دسته تحلیلهای Multiple variables و در بخش Start with sample data to follow a tutorial قرار دارد. فایل مثال را میتوانید از اینجا دانلود کنید.
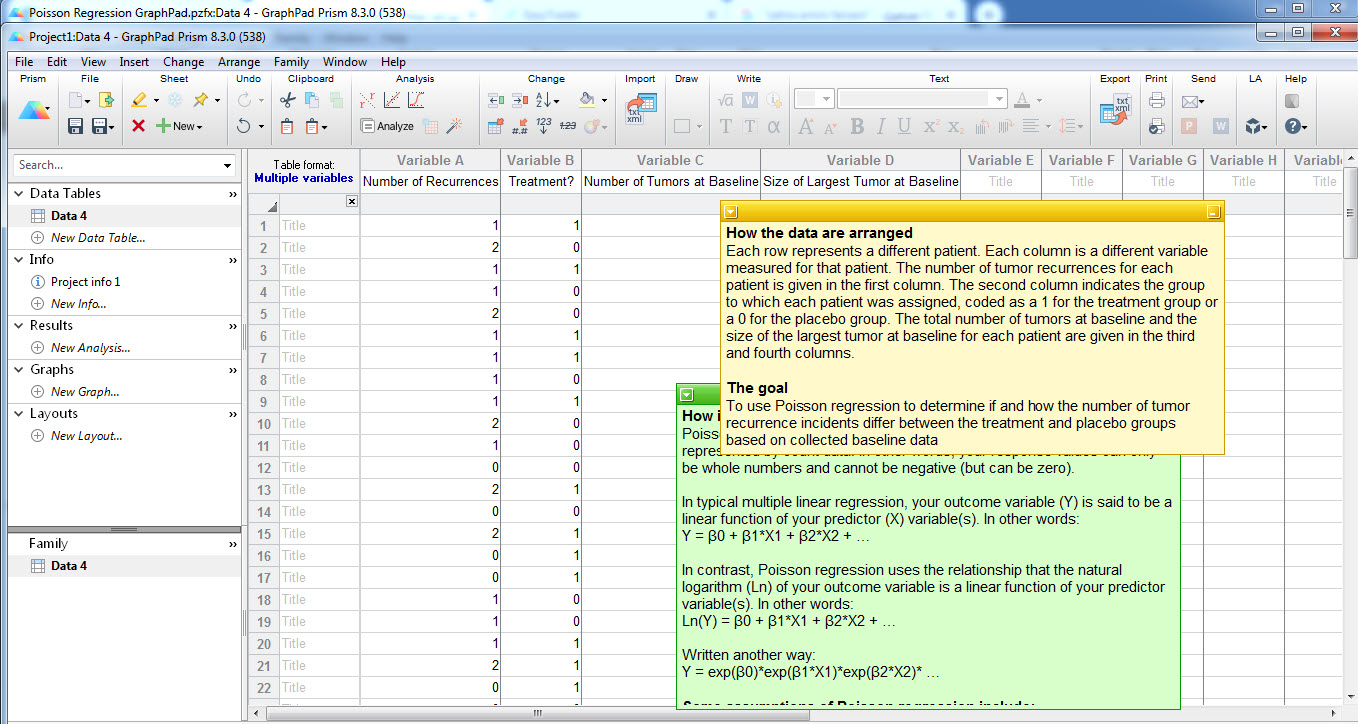
وقتی مثال را Create میکنیم با دادههای زیر روبهرو میشویم. همانگونه که مشاهده میکنید دادهها در چهار ستون بیان شدهاند. ستون با نام Number of Recurrences همان کمیت پاسخ Y مدل رگرسیون پواسن است که خود دارای توزیع پواسن است و تعداد عود تومور به ازای هر بیمار را نشان میدهد.
ستون Treatment نشان میدهد فرد در گروه درمان با کد 1 و یا در گروه کنترل با کد صفر قرار دارد.
ستون Number of Tumors at Baseline و Size of Largest Tumor at Baseline به ترتیب نشاندهندهی تعداد و اندازه بزرگترین تومور هر فرد در ابتدای مطالعه میباشند.
در این مثال یافتههای مربوط به 100 فرد آمده است.
همانگونه که بالاتر نیز اشاره کردیم، هنگامی که کمیت پاسخ ما دارای توزیع پواسن باشد، از مدلهای رگرسیون پواسن استفاده میکنیم. در این مثال به دنبال به دست آوردن ارتباط بین Number of Recurrences با نوع گروه درمانی، تعداد و سایز تومور ابتدای مطالعه هستیم.
نکتهای که در این زمینه نرم افزار گراف پد به آن اشاره میکند (در پنجره سبزرنگ Note نیز نوشته شده است.) این است که رگرسیون پواسن در مواردی که کمیت پاسخ ما شمارشی count data و البته غیرمنفی باشد بوده و به تعداد پیشامدها اشاره میکند، مورد استفاده قرار میگیرد.
جهت انجام رگرسیون پواسن، در شیت دادهها، بر روی منوی Analyze کلیک کنید تا پنجره Analyze Data به صورت زیر برای ما باز شود.

در آنجا و از کادر Multiple variable analyses گزینه Multiple linear regression را انتخاب میکنیم. پنجره Parameters Multiple Linear Regression به صورت زیر برای ما باز میشود.
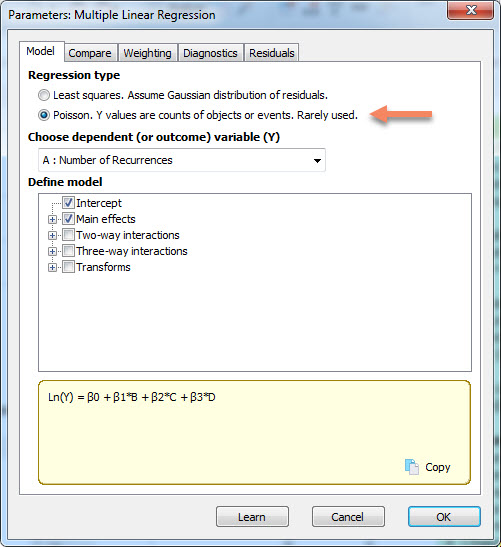
از تب Model و کادر Regression type گزینه Poisson. Y values are counts of objects or events. Rarely used را انتخاب میکنیم.
البته میتوانستیم در همان شیت دادهها به صورت مستقیم وارد پنجره Parameters Multiple Linear Regression نیز شویم. برای اینکار در بالای منوی Analyze بر روی ابزارک Multiple Linear regression کلیک میکنیم.
در ادامه به توضیح بخشها و گزینههای مختلف پنجره Parameters Multiple Linear Regression که جهت انجام تحلیل رگرسیون پواسن، استفاده میشود، میپردازیم.
- Model
در این تب و در کادر choose dependent (or outcome) variable Y مشخص میکنیم که کمیت پاسخ، کدام است. به سادگی و بر مبنای شیت دادهها میدانیم که نام آن Number of Recurrences میباشد. به صورت پیشفرض نیز همین ستون قرار گرفته است.
در کادر Define model میتوانیم نوع مدل رگرسیون پواسن خود را انتخاب کنیم. میدانیم که هر مدل رگرسیونی میتواند علاوه بر داشتن ضریب ثابت یا همان Intercept و اثرات اصلی Main effects ، شامل اثرات متقابل چند طرفه Interactions نیز باشد. چنانچه تمایل داشته باشیم میتوانیم این اثرات متقابل را نیز به مدل رگرسیونی خود اضافه کنیم.
بر مبنای مدل انتخاب شده در بخش Define model، در کادر زردرنگ پایین میتوانید معادله مدل رگرسیون پواسن را مشاهده کنیم.
- Compare
این تب از آن موارد به درد بخور و خاص نرمافزار گراف پد است. با استفاده از آن میتوانیم به مقایسه بین چند منحنی رگرسیونی بپردازیم و پارامترهای به دست آمده از هر مدل را با هم مقایسه کنیم.
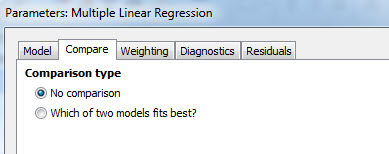
از آنجا که در این مثال تنها یک منحنی رگرسیونی داریم، پس همان گزینه پیشفرض No comparison را میپذیریم. اگر به دنبال مقایسه بین دو منحنی رگرسیونی بودیم گزینه which of two models fits best را انتخاب میکنیم.
- Weighting
در این تب میتوانیم به وزندهی کمیت پاسخ Y بپردازیم. بر این اساس Y میتواند به معادلات دیگری تبدیل شود و سپس مدل رگرسیونی بر آن Y جدید تبدیل شده انجام گیرد. از آنجایی که ما از مدل رگرسیون پواسن استفاده کردهایم، گزینههای این بخش غیرفعال هستند.

- Diagnostics
در این تب انواع آمارهها و معیارهای مناسبت مدل و نیکویی برازش وجود دارد. بخشهای مختلف آن را مشاهده میکنیم.

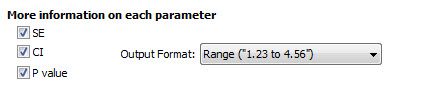
در ابتدا بخشی با نام More information on each parameter قرار دارد. در این بخش میتوانیم سه آمارهی SE خطای استاندارد، CI فواصل اطمینان و مقدار احتمال P value به ازای هر کدام از Xهای مدل را به دست آوریم. کادر Output Format نحوه نمایش اعداد را برای ما نشان میدهد.
در ادامه بخشی با نام Are the variables intertwined or redundant مشاهده میشود.
![]()
در این بخش دربارهی درهم تنیدگی Intertwined کمیتهای مستقل Xها در یکدیگر و احتمالاً زاید بودن Redundant آنها، صحبت میشود. با استفاده از بررسی همخطی چندگانه Multicollinearity و ماتریس همبستگی Correlation Matrix این موارد ارزیابی میشود.
یک توضیح کوتاه اینکه همخطی به معنای وجود ارتباط قوی و همبستگی بالا در بین Xهای مدل است. هر چند همخطی در همه مدلهای رگرسیونی وجود دارد اما شدت آن، یک نقیصه به حساب میآید. زیرا وقتی دو یا چند X با یکدیگر همخطی بالایی دارند، دیگر لزومی به آمدن همه آنها در مدل رگرسیونی نیست و زاید هستند.
به هرحال ما در این مثال هم در پی محاسبهی هم خطی و هم ماتریس همبستگی هستیم.
در بخش با نام How to quantify goodness-of-fit انواع آمارهها جهت سنجش میزان مناسب بودن مدل رگرسیون پواسن آمده است. به صورت پیشفرض نرمافزار Pseudo R square را انتخاب کرده است.

همه گزینههای بخش Normality tests. Are the residuals Gaussian غیرفعال است. این مطلب به دلیل آن است که در تحلیل رگرسیون پواسن، بررسی نرمال بودن باقیماندهها وجود ندارد.

در بخش calculations به سادگی میتوانیم ضریب اطمینان فاصله اطمینان را مشخص کنیم. به صورت پیشفرض بر روی 95 درصد قرار دارد.

در بخش Output نیز میتوانیم تعداد رقمهای اعشار برای مقدار احتمال P value و قالب نمایش آن را انتخاب کنیم.

- Residuals
انواع گرافهای قابل رسم در تحلیل رگرسیون پواسن در تب Residuals دیده میشود. نرمافزار به صورت پیشفرض نمودار Residual plot که گرافی جهت بررسی باقیماندهها در برابر مقادیر Y پیشبینی شده است را رسم میکند. با استفاده از این گراف میتوانیم میزان درستی پیشبینی مدل رگرسیون پواسن براورد شده را به دست بیاوریم. خوب است بقیه گرافها را نیز انتخاب کنیم.
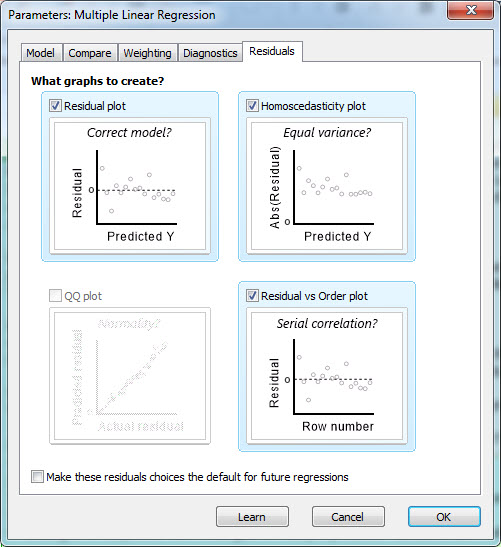
در پایان با OK کردن میتوانیم تمام نتایج و نمودارهای رسم شده در تحلیل رگرسیون پواسن را مشاهده کنیم.
ابتدا به بررسی شیت نتایج که با نام Multiple lin. reg در فولدر Results پنجره راهبری سمت چپ نرمافزار قرار دارد، میپردازیم.
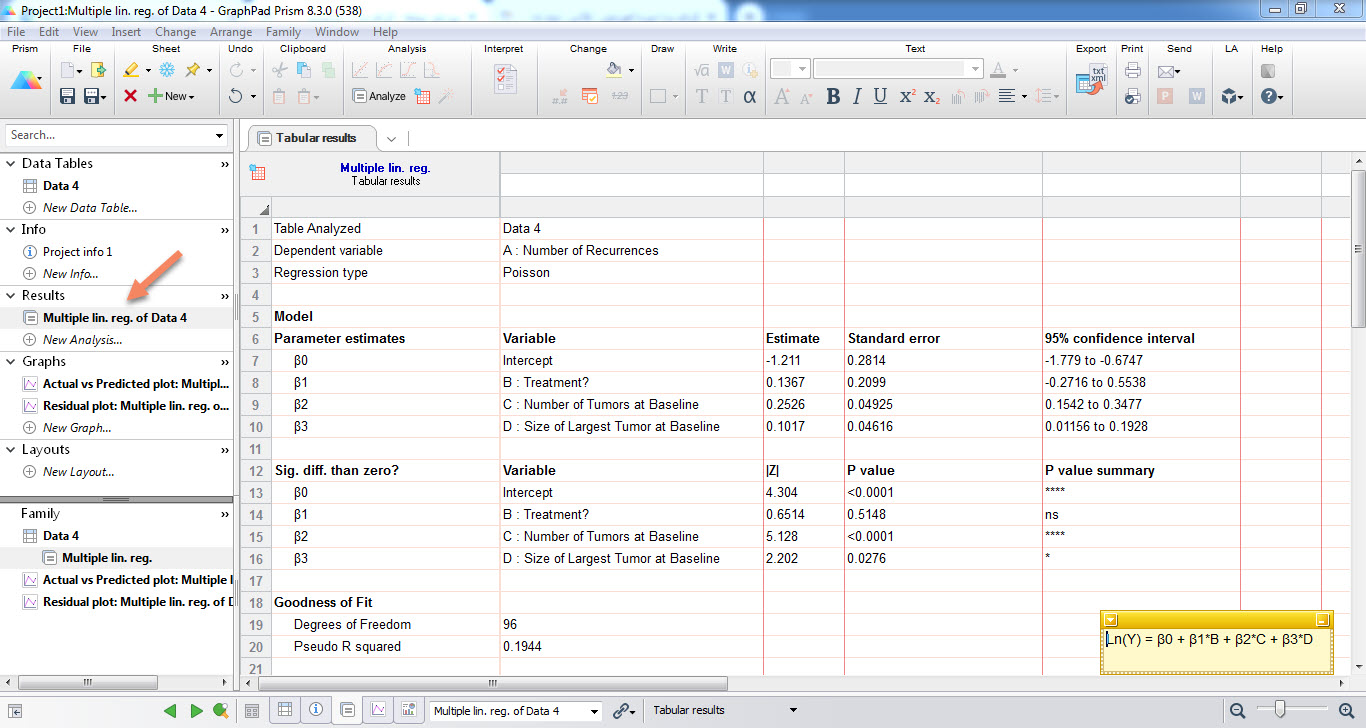
در این شیت میتوانیم بر مبنای تنظیماتی که در نرمافزار قرار دادیم، تمام تحلیلهای انجام شده رگرسیون پواسن را مشاهده کنیم. خطوط اولیه نوشته شده در نتایج بیان میکند که کمیت وابسته Dependent variable همان تعداد عود تومور Number of Recurrences است. نوع رگرسیون استفاده شده که همان Poisson است، دیده میشود.
ما در ادامه بخشهای مختلف صفحه نتایج را بیان میکنیم.
- Model
این بخش مهمترین نتایج تحلیل رگرسیون پواسن را شامل میشود. براورد پارامترهای β3 ، β2 ، β1 ، β0 مدل پواسن که به ترتیب ضریب ثابت، درمان، تعداد تومور و اندازه بزرگترین تومور میباشند، در این بخش قرار گرفته است. مثبت شدن هر سه ضریب، بیانگر وجود ارتباط مستقیم بین درمان، تعداد و اندازه بزرگترین تومور با تعداد دفعات عود تومور میباشد.

علاوه بر براورد پارامترها، خطای استاندارد و فواصل اطمینان 95 درصد به ازای هر پارامتر نیز در جدول بالا آمده است. خوبی فواصل اطمینان این است که با استفاده از آنها و حتی بدون داشتن مقادیر احتمال P value، میتوانیم تاثیر معناداری یا عدم معنادار آن پارامتر بر پاسخ (در اینجا تعداد دفعات عود تومور) را به دست آوریم.
در این زمینه توضیح اینکه اگر فواصل اطمینان شامل عدد صفر باشند، نتیجه میگیریم آن پارامتر تاثیر معنادار بر Y یا همان پاسخ ندارد. به عنوان مثال در اینجا فاصله اطمینان پارامتر درمان Treatment عدد صفر را در بر دارد. بنابراین نتیجه میگیریم درمان بر عود تومور اثر معنادار ندارد.
اگر هر دو کران فاصله اطمینان از عدد صفر کمتر و منفی باشند، بیانگر وجود ارتباط معنادار آن هم از نوع وارون بین آن X با Y است. در این مثال فاصله اطمینان با هر دو کران منفی، دیده نمیشود.
اگر هر دو کران فاصله اطمینان از عدد صفر بیشتر و مثبت باشند، بیانگر وجود ارتباط معنادار از نوع مستقیم بین آن X با Y است. به عنوان مثال در اینجا تعداد و اندازه بزرگترین تومور، دارای فواصل اطمینان مثبت هستند و بنابراین بر عود تومور تاثیر مستقیم افزایشی و معنادار دارد.
به این ترتیب با استفاده از اعداد به دست آمده برای پارامترها میتوانیم تعداد دفعات عود تومور برای هر فرد را محاسبه کنیم. مدل رگرسیون پواسن در مثال ما به صورت زیر خواهد بود.
λ = e-1.211 + 0.1367x1 + 0.2526x2 + 0.1017x3
با استفاده از این مدل میتوانیم با قرار دادن Xهای دلخواه به ازای هر فرد حتی خارج از این مطالعه، تعداد دفعات عود تومور او را محاسبه کنیم.
- Sig. diff. than zero
آمارهی Z به همراه مقدار احتمال P value آزمون، به ازای هر کدام از Xهای مدل، در این بخش بیان شده است.

آنجه که به وضوح دیده میشود و در بخش بالا فواصل اطمینان نیز به آن اشاره شد، این است که کمیتهای تعداد تومور (P value < 0.0001) و اندازه بزرگترین تومور (P value = 0.0276) دارای تاثیر معنادار افزایشی بر تعداد دفعات عود تومور هستند. اما درمان بر تعداد دفعات عود تومور تاثیر معنادار ندارد (P value = 0.5148).
- Goodness of Fit
همانگونه که میدانیم R square که در فارسی به آن ضریب تعیین میگوییم عددی بین صفر تا یک است و نشاندهندهی آن است که مدل رگرسیونی به دست آمده تا چه اندازه میتواند پراکندگی دادههای واقعی را تحت پوشش خود قرار دهد. در واقع ضریب تعیین میتواند ابزاری جهت سنجش قدرت پیشبینیکنندگی و خوب بودن مدل باشد. هر چه عدد R square به مقادیر یک نزدیکتر باشد، بیانگر بهتر بودن مدل رگرسیون به دست آمده است.

اما هنگامی که با مدل رگرسیون پواسن روبهرو هستیم R square با نام Pseudo و یا شبه ضریب تعیین نامیده میشود. دلیل این نامگزاری تفاوت بین نحوه به دست آوردن ضریب تعیین در یک مدل رگرسیون خطی با رگرسیون غیرخطی پواسن است که نرمافزار گراف پد در تنظیمات خود به آن نیز اشاره کرده است. همانگونه که در جدول بالا مشاهده میکنید اندازه عددی Pseudo R square برابر با 0.1944 به دست آمده است.
این عدد چندان کم است و نشان میدهد مدل رگرسیون پواسن به دست آمده فقط میتواند 19.44 درصد پراکندگی دادهها را تحت پوشش خود قرار دهد.
- Multicollinearity
ما در پنجره Parameters Multiple Linear Regression و در تب Diagnostics در بخش Are the variables intertwined or redundant به هنگام تنظیمات مدل، گزینههای Multicollinearity و Correlation Matrix را جهت به دست آوردن نتایج همخطی و ماتریس همبستگی، فعال کردیم. در جدول زیر میتوانید نتایج هم خطی بین Variableها را مشاهده کنید.

هم خطی با آمارهای به نام فاکتور تورم واریانس Variance Inflation Factor (VIF) سنجیده میشود. اندازه VIFها نشان میدهد با همبسته بودن کمیتها به یکدیگر، واریانس ضریب رگرسیونی براورد شده به چه میزان افزایش مییابد.
اگر VIF نزدیک به یک باشد، همخطی بین آن X با کمیتهای دیگر وجود ندارد، اما اگر VIFها از یک بزرگتر باشند، همخطی بین آن X با کمیتهای دیگر وجود دارد. وقتی VIF > 5 باشد، ضریب رگرسیونی به دست آمده برای آن جمله، مناسب نیست و معمولاً آن X را حذف میکنیم.
همانگونه که در جدول بالا دیده میشود VIFها چندان بالا نیست و نزدیک به یک قرار دارد. به این ترتیب میتوان گفت که بین آنها هم خطی وجود ندارد.
در جدول بالا ستون دیگری با نام R2 with other variables دیده میشود. اعداد به دست آمده برای هر کمیت نشان میدهد که اگر آن X نقش Y را در یک مدل رگرسیونی داشته باشد و سپس بین آن X که دیگر Y شده است و سایر X ها یک مدل رگرسیونی برقرار کنیم، در آن صورت، ضریب تعیین این مدل رگرسیونی چقدر خواهد بود.
به عنوان مثال عدد 0.0197 برای اندازه تومور بیان میکند که اگر یک مدل رگرسیونی بین اندازه تومور از یک طرف و درمان و تعداد تومور از طرف دیگر برقرار کنیم، ضریب تعیین یا همان R2 این مدل رگرسیونی جدید حدود 1.97 درصد خواهد بود.
همانگونه که میدانیم R2 عددی بین صفر و یک است و هرچقدر به یک نزدیکتر باشد، نشاندهندهی وجود ارتباط قویتر بین کمیت پاسخ Y با سایر کمیتهای مستقل Xها میباشد.
در جدول بالا R2 ها چندان بالا نیست. تعداد تومور که دارای کمترین ضریب تعیین است، عدد VIF آن نیز کمترین مقدار در مقایسه با سایر کمیتها شده بود. این مطلب نشان میدهد تعداد تومور ارتباط خیلی ضعیفی با سایر Xها یعنی درمان و اندازه تومور دارد. این اتفاق خوب است. در واقع در مدلهای رگرسیونی مطلوب آن است که بین Xها همخطی وجود نداشته باشد و اندازههای VIF آن نزدیک به یک و R2 with other variables در اطراف صفر باشد.
- Correlation matrix
در ادامه مباحث هم خطی که در بالا به آن اشاره کردیم، نرمافزار گراف پد ماتریس همبستگی بین کمیتهای مستقل را نیز رسم کرده است. این ماتریس که آرایههای آن عدد ضریب همبستگی بین هر X با X دیگر میباشد، نشان میدهد ارتباط جفتی بین کمیتهای مستقل با یکدیگر چگونه است.

به عنوان مثال عدد 0.1425- نشان میدهد ارتباط بین درمان و اندازه تومور وارون و منفی و حدود 14 درصد میباشد. این مطلب نشان میدهد افرادی که درمان کردهاند دارای سایز تومور کوچکتری بودهاند. برای بقیه Xها نیز عدد ضریب همبستگی به دست آمده است.
- Data summary
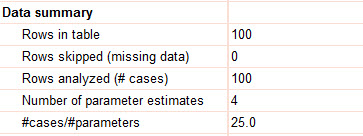
در این بخش خلاصهای از دادههای مثال رگرسیون پواسن را مشاهده میکنید. جدول زیر بیان میکند که 100 سطر (فرد) مورد بررسی قرار گرفته است. داده گمشده Missing data که شامل افراد دارای عدم پاسخ است، در این مثال دیده نمیشود. بنابراین 100 نفر در این مطالعه آنالیز شدهاند.
499 فرد کد 1 یعنی زنده ماندن و 814 نفر دارای کد صفر به معنای مرگ، بودهاند.
تعداد چهار پارامتر یعنی همان پارامترهای β3 ، β2 ، β1 ، β0 که به ترتیب بیانگر ضریب ثابت، درمان، تعداد تومور و اندازه تومور میباشند، براورد شده است. نسبت تعداد افراد به پارامترها یعنی 100/4 برابر با 25.0 به دست آمده است.
آنچه در این مثال همچنان باقی مانده است، مشاهده و رسم گرافهای متناظر با تحلیل رگرسیون پواسن میباشد. در فولدر Graphs پنجره سمت چپ میتوان عناوین چهار شیت از نمودارهای رسم شده در این مثال را مشاهده کرد.

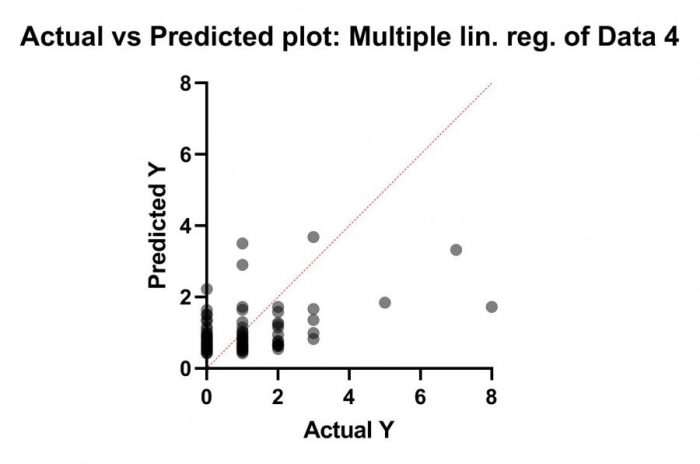
در ادامه به بررسی این گرافها میپردازیم. در ابتدا از گراف Actual vs Predicted plot: Multiple lin. reg شروع میکنیم. شکل آن را در زیر میتوانید ببینید.
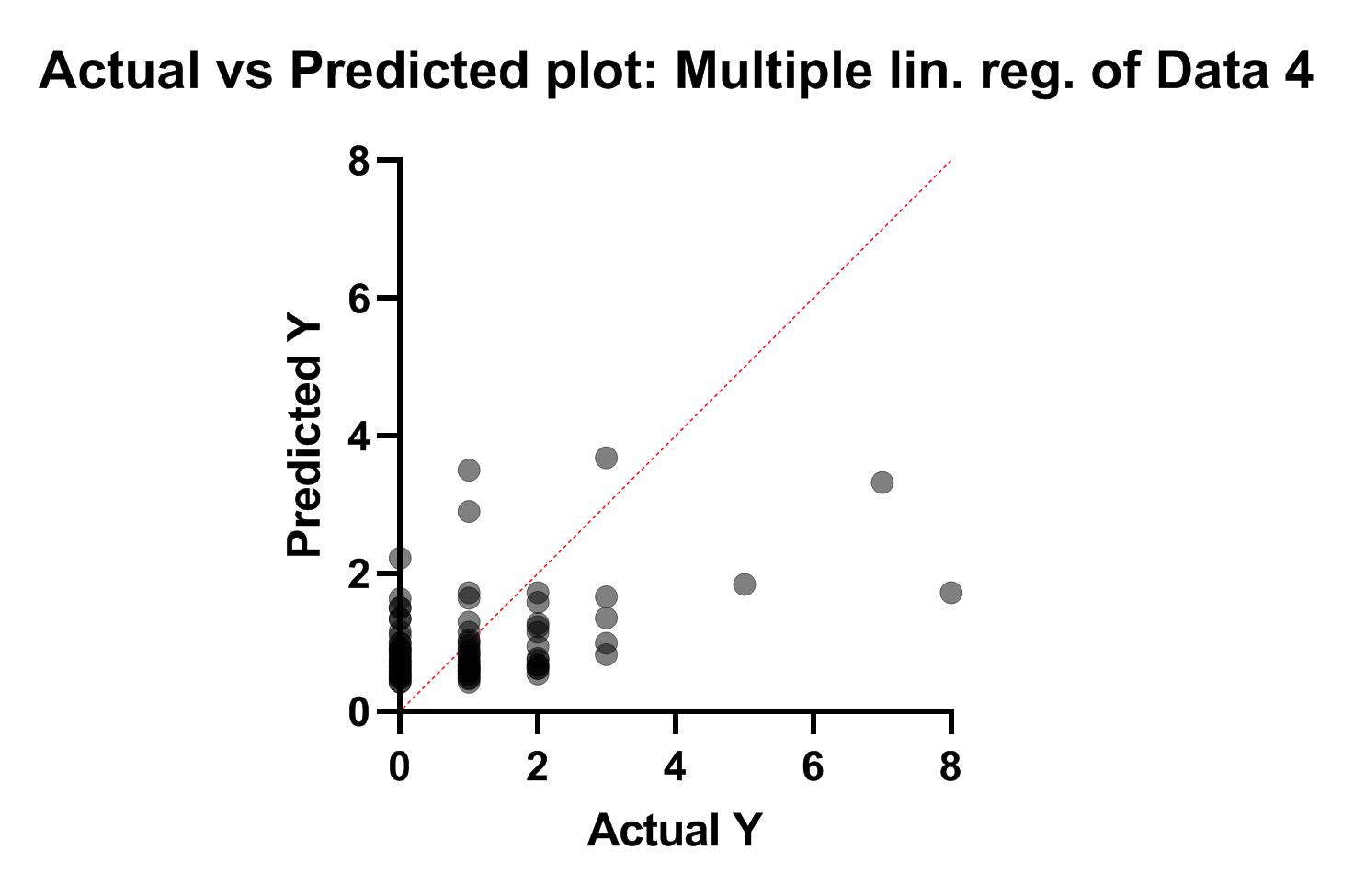
در این گراف محور عمودی مقادیر Y پیشبینی شده با استفاده از مدل رگرسیون پواسن است. به این معنا که بر مبنای Xهای هر فرد به دست آوردهایم تعداد دفعات عود تومور او چقدر میتواند باشد. هر دایره نیز بیانگر یک فرد میباشد.
در محور افقی نیز عدد واقعی تعداد دفعات عود تومور آمده است. دقت کنید که خط نیمساز نقاطی را نشان میدهد که اندازههای واقعی و پیشبینی شده با یکدیگر برابرند. این بهترین حالت برای مدل است که بیانگر خطای صفر پیشبینی میباشد. با این حال همانگونه که مشاهده میکنید، نقاط از خط نیمساز دور هستند، به معنای اینکه مدل به دست آمده چندان مناسب نیست.
چنانچه علاقمند باشیم اعداد پیشبینی شده Y برای تعداد عود تومور را به ازای هر فرد مشاهده کنیم، میتوانیم در گراف بالا بر روی یک دایره دلخواه برویم. اطلاعاتی درباره همان نقطه در صفحه گراف برای ما مشخص خواهد شد. به عنوان مثال میتوانیم ببینیم آن نقطه سطر چندم دادهها است، اندازه X آن (در اینجا مقدار واقعی تعداد دفعات عود تومور) چقدر است و اندازه Y یعنی پیشبینی تعداد دفعات عود تومور برای آن نقطه چقدر خواهد بود.
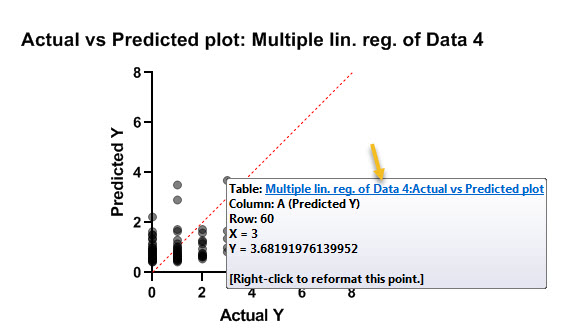
به همین ترتیب خط آبیرنگ با نام Multiple lin. reg. of Data: Actual vs Predicted plot در کادر بالا دیده میشود. اگر بر روی آن کلیک کنیم به صورت مستقیم به نتایج و شیت Results میرویم. در آنجا یک تب جدید با نام Actual vs Predicted plot ساخته شده است. در زیر میتوانید ببینید.
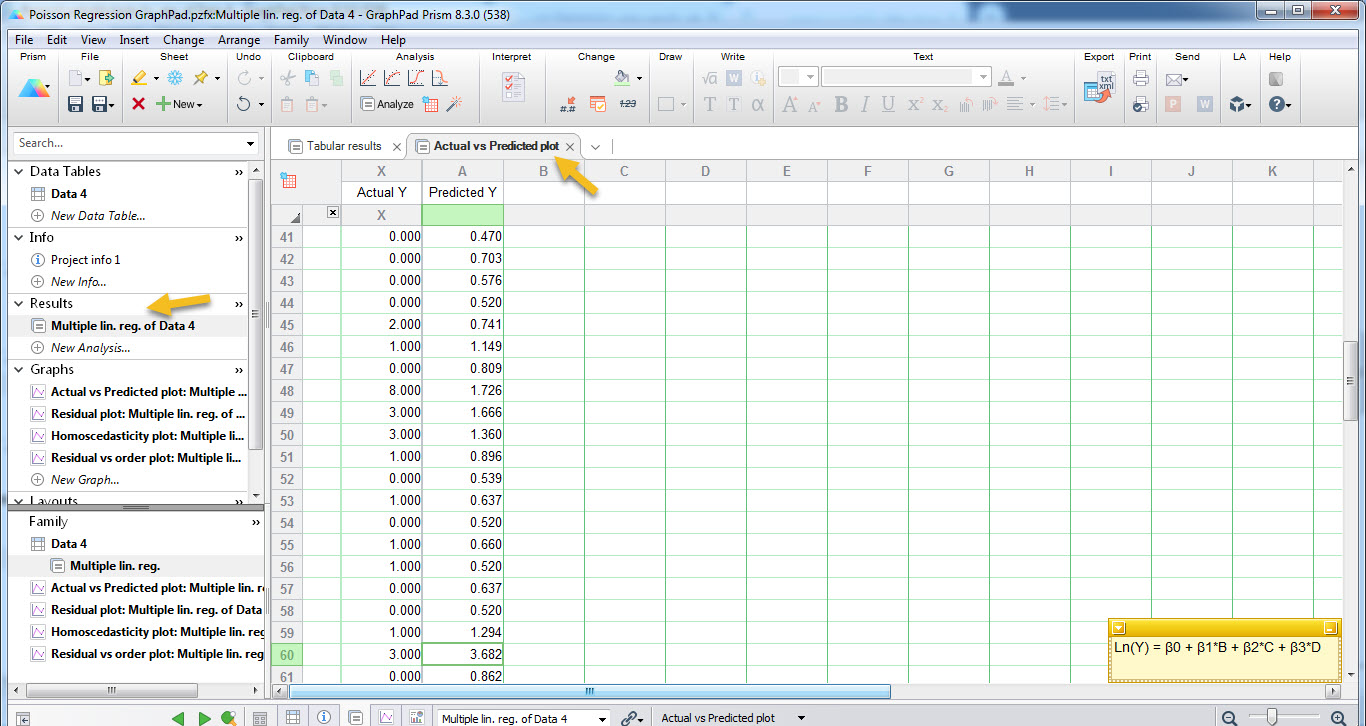
جالب توجه است که در این شیت از نتایج چند ستون دیده میشود. در ستون X با نام Actual Y عدد واقعی تعداد دفعات عود تومور به ازای هر فرد دیده میشود. در ستون دیگر با نام Predicted Y به ازای همان فرد، تعداد دفعات پیشبینی شده عود تومور توسط مدل رگرسیون پواسن، مشاهده میشود.
به عنوان مثال برای نفر شصتم، سه بار عود تومور اتفاق افتاده است. بر مبنای مدل به دست آمده، ما پیشبینی میکنیم که تعداد دفعات عود تومور او باید 3.682 باشد.
با استفاده از مدل به دست آمده که فرمول آن را در بالا نوشتیم و یکبار دیگر آن را تکرار میکنیم ↓
λ = e-1.211 + 0.1367x1 + 0.2526x2 + 0.1017x3
میتوانیم به ازای یک فرد خاص، تعداد دفعات عود تومور او را براورد کنیم.
به عنوان مثال فرض کنید فردی تحت درمان قرار گرفته است، تعداد تومور او در شروع مطالعه 4 و سایز بزرگترین تومور او 7 باشد، در این صورت بر مبنای مدل بالا میتوانیم، تعداد دفعات عود تومور او را به دست بیاوریم که تقریبا برابر با 1.9 دفعه میشود.
λ = e-1.211 + 0.1367*1 + 0.2526*4 + 0.1017*7
λ = e0.648 = 1.912 ⇒
حال به بررسی گراف دیگر با نام Residual plot: Multiple lin. reg. of Data بپردازیم.

در این نمودار میتوانیم باقیماندهها و یا همان خطاها به ازای هر فرد را مشاهده کنیم. توضیح اینکه باقیمانده به اختلاف بین مقدار واقعی تعداد دفعات عود و تعداد دفعات پیشبینی عود گفته میشود. مدل رگرسیونی خوب است که در گراف بالا نقاط به صورت تصادفی در اطراف خط صفر قرار گرفته باشند. در این مثال چنین چیزی به خوبی دیده نمیشود.
همانند گراف بالا با قرار دادن موس بر روی هر دایره، میتوانیم مختصات X یعنی عدد پیشبینی شده برای تعداد عود تومور و Y یعنی اندازه خطا را مشاهده کنیم.
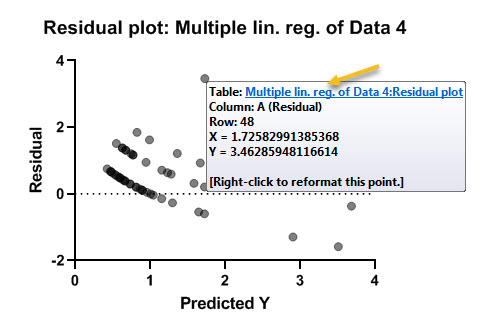
با کلیک کردن بر روی عبارت آبی رنگ Multiple lin. reg. of Data: residual plot میتوانیم در شیت نتایج تب دیگری با نام Residual plot به دست میآید. در تصویر زیر میتوانید آن را ببینید.

همانگونه که مشاهده میشود به ازای هر فرد میتوان مقدار عدد پیشبینی شده برای تعداد دفعات عود تومور و خطای پیشبینی را مشاهده کرد.
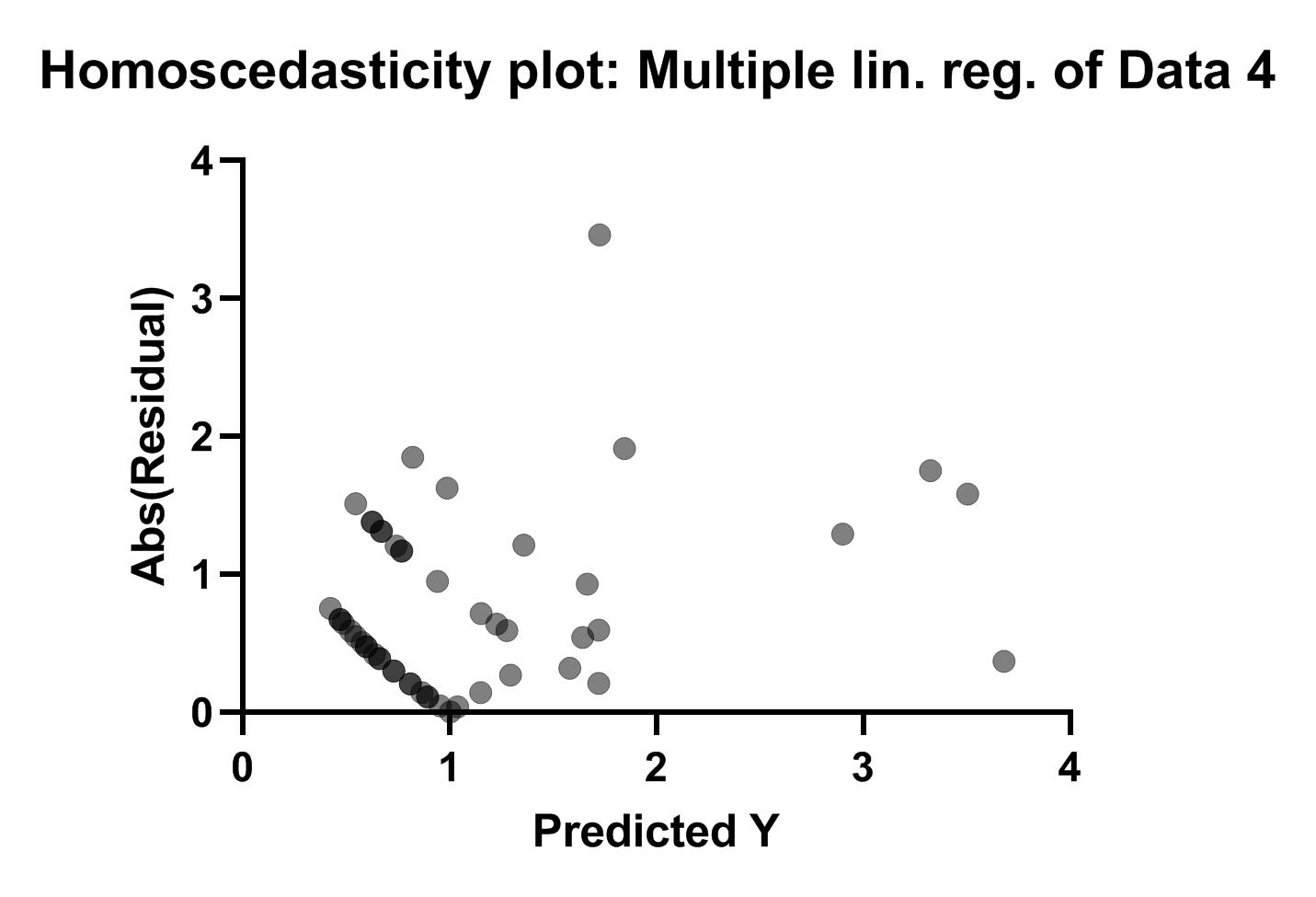
گراف دیگر با نام Homoscedasticity plot: Multiple lin. reg. of Data همان گراف بالا است با این تفاوت که قدر مطلق باقیماندهها در محور عمودی قرار گرفته است. این نکته لازم به ذکر است که باقیماندهها از آنجا که به صورت اختلاف بین مقدار مشاهده شده و عدد پیشبینی شده هستند، میتوانند به صورت مثبت و یا منفی باشند. یعنی در مواردی عدد واقعی بزگتر باشد و باقیمانده مثبت شود و در مواردی عدد پیشبینی شده بزرگتر باشد و باقیمانده منفی شود.
در شکل زیر میتوانید گراف را مشاهده کنید.
آخرین گراف با نام Residual vs order plot: Multiple lin. reg. of Data به دست آمده است. ابتدا شکل آن را ببینید.
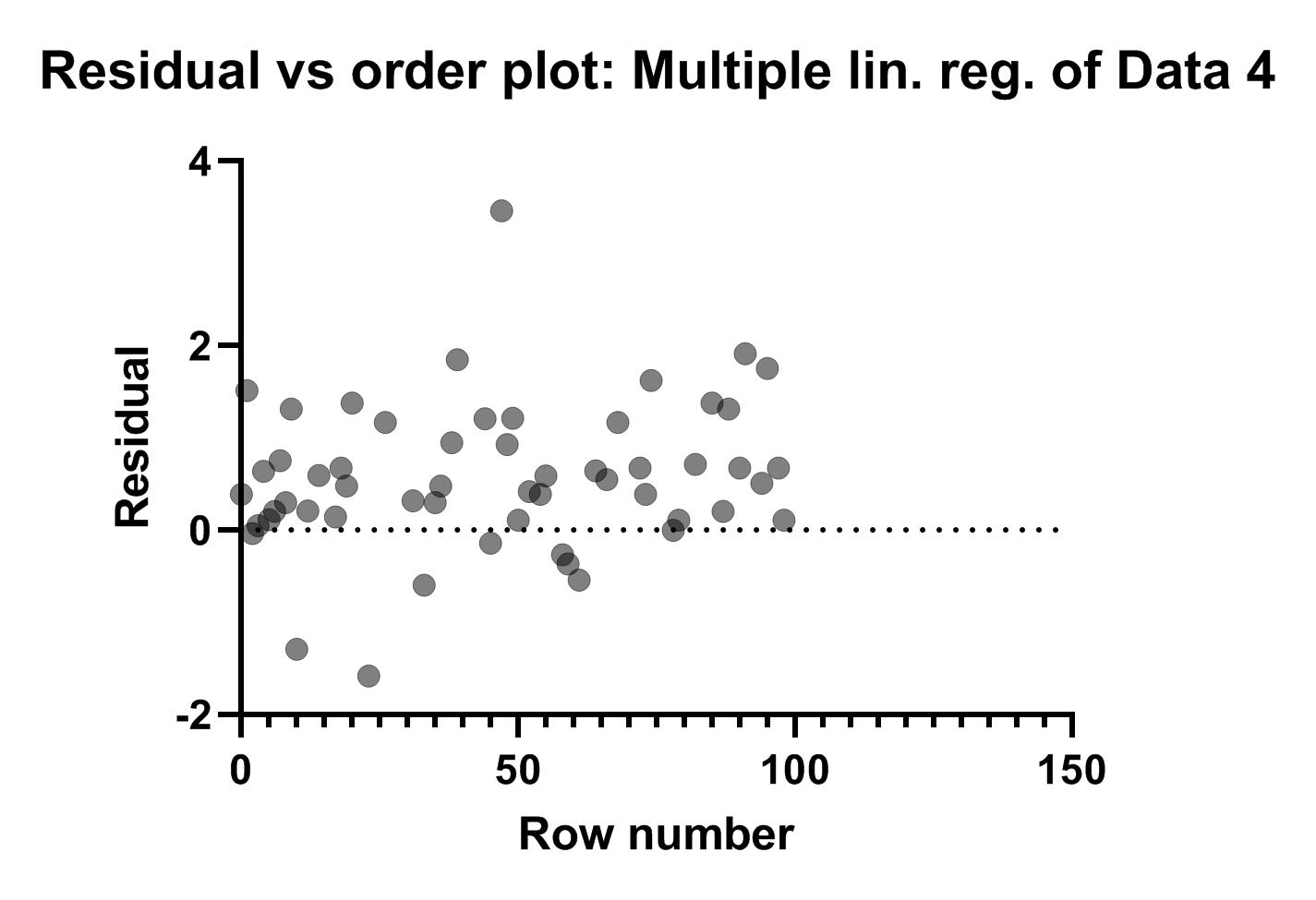
در این تصویر باقیماندهها در برابر ترتیب و ردیف افراد قرار گرفتهاند. به معنای اینکه از نفر ابتدا تا نفر صدم به ترتیب باقیمانده و خطای مدل پواسن به ازای هر کدام از آنها آمده است. همانند گرافهای بالا میتوانیم با قرار دادن موس بر یک نقطه، تب نتایج را مشاهده کنیم.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). Analysis of Poisson Regression model with GraphPad Prism software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/poisson-regression-prism/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). Analysis of Poisson Regression model with GraphPad Prism software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/poisson-regression-prism/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.