ضریب همبستگی C، فی Phi و کرامر Cramer’s V
توضیحات برگرفته شده از کتاب روش های پیشرفته آماری و کاربردهای آن
همبستگی به مفهوم ارتباط میان دو یا چند کمیت با یکدیگر است و ضریب همبستگی مقدار عددی این ارتباط را بیان میکند. وقتی از ضریب همبستگی در جامعه صحبت میکنیم با مفهوم پارامتری آن روبهرو هستیم که آن را با نماد ρ نشان میدهیم و وقتی از جامعه نمونهگیری میشود، براورد نمونهای آن را با r نمایش میدهیم.

هر چقدر قدر مطلق ضریب همبستگی به عدد یک نزدیکتر باشد (در جهت مثبت یا در جهت منفی) ارتباط بین کمیتها بیشتر و کاملتر است. وقتی اندازه عددی ضریب همبستگی به مقادیر مثبت یک نزدیک است به معنای وجود ارتباط قوی و مستقیم است، به نحوی که افزایش یک کمیت افزایش کمیت دیگر را در پی دارد و یا کاهش آن سبب کاهش کمیت دیگر میشود.
به همینترتیب اندازه عددی ضریب همبستگی نزدیک به مقادیر منفی یک به معنای وجود یک ارتباط قوی و وارون است که اندازههای عددی دو کمیت در جهت عکس یکدیگر رفتار میکنند. اندازههای عددی نزدیک به صفر نیز بدان معنا است که تغییرات یک کمیت، اطلاع کمی درباره تغییرات کمیت دیگر در اختیار ما قرار میدهد. نکتهای که باید در این میان به آن توجه کرد این است که ضریب همبستگی صفر و یا نزدیک صفر را نباید به مفهوم استقلال کمیتها از یکدیگر دانست. هر چند که ضریب همبستگی دو کمیت مستقل از یکدیگر، همواره صفر است.
انواع ضرایب همبستگی
همان گونه که میدانیم مشاهدات در چهار دستهی اسمی Nominal، رتبهای Ordinal، فاصلهای Interval و نسبتی Ratio طبقهبندی میشوند. خوب است این نکته را بدانید که نرمافزار SPSS به دادههای از نوع فاصلهای و نسبتی اصطلاحاً Scale میگوید. براساس این دستهبندیها انواع مختلف همبستگی بین کمیتها و دادهها معرفی میشوند. در واقع مبنای ایجاد و معرفی ضرایب همبستگی مختلف تا حد زیادی متأثر از ماهیت و مقیاس اندازهگیری میان کمیتها است. من در این متن قصد دارم به یکی از مهمترین انواع ضرایب همبستگی یعنی پیرسن Pearson بپردازم.
ضریب همبستگی C، فی و کرامر
Contingency Coefficient, Phi and Cramer’s V
انواع مختلف ضرایب همبستگی برای مشاهدات اسمی، رتبهای و فاصلهای را میتوان براساس نوع مشاهدات از طریق مسیر زیر در نرمافزار SPSS مشاهده کرد.
Analyze → Descriptive statistics → Crosstabs
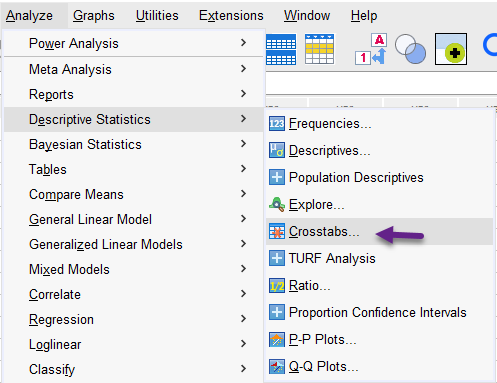
این ضرایب در گزینهی Statistics قابل مشاهده میباشند. ما به صورت مختصر به معرفی برخی از ضرایب میپردازیم. دقت کنید که این ضرایب بیشتر در جداول توافقی و بررسی دو کمیت، مورد استفاده قرار میگیرند. ما از محاسبات عددی چگونگی یافتن مقادیر این ضرایب خودداری میکنیم و برای این منظور از نرمافزار استفاده میکنیم. تصویر زیر را ببینید.
همانگونه که در بحث فرضیههای آماری بیان کردیم، فرض صفر تفکر و ایده اولیه محقق از پژوهش خود میباشد، این فرض در پی پذیرش وضع موجود بوده و عدم ارتباط میان کمیتها را بیان میکند. فرضیه مربوط به ضرایب همبستگی به صورت زیر است.
$ \displaystyle {{H}_{0}}:\rho =0\begin{array}{*{20}{c}} {} & {vs} & {} \end{array}{{H}_{1}}:\rho \ne 0$
فرض صفر این آزمون عدم ارتباط میان کمیتها و فرض مقابل وجود ارتباط و ایجاد ساختار جدید را نشان میدهد. فراموش نکنیم که این آزمون میتواند علاوه بر تعریف دو دامنه (به صورت زیر) به صورت آزمون فرضیههای یکطرفه نیز تعریف شود.
بیایید این بحث را با استفاده از نرمافزار SPSS توضیح دهیم. فایل دیتای این مثال را میتوانید از اینجا دریافت کنید. در ادامه دربارهی این مثال توضیح میدهیم.
فرض کنید جدول زیر مربوط به تعداد تصادفات رانندگی در جادههای استان اصفهان در طی یکسال، برحسب نوع جادهها و تجهیزات راهنمایی و رانندگی مناسب و یا نامناسب و غیر کافی است.
| جدول توافقی نوع و وضعیت جاده | وضعیت جادهها از نظر تجهیزات راهنمایی و رانندگی | |||
| مناسب و کافی | نامناسب و غیرکافی | مجموع | ||
| نوع جادههای مورد مطالعه | بزرگراه | 44 | 108 | 152 |
| جاده اصلی | 36 | 50 | 86 | |
| جاده فرعی | 33 | 42 | 75 | |
| مجموع | 113 | 200 | 313 |
از آنجا که دادههای ما اسمی Nominal هستند، جهت به دست آوردن ضریب همبستگی بین نوع جادهها و وضعیت تجهیزات راهنمایی و رانندگی جادهها، میتوانیم از روشهای ضریب همبستگی احتمالی با نام Contingency Coefficient که به اختصار به آن ضریب همبستگی C گفته میشود و همچنین ضریب همبستگی فی و کرامر Phi and Cramer’s V، استفاده کنیم.
با این حال در گام ابتدایی لازم است، دادههای جدول بالا وارد نرمافزار شوند. ما آنها را به صورت تصویر زیر در SPSS نوشتهایم.
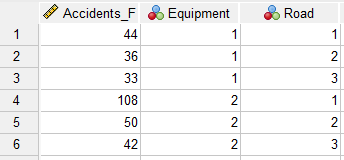
در مرحلهی بعد باید دادههای ستون Accidents_F را وزندهی کنیم. دربارهی روش و چگونگی وزندهی کردن دادهها در نرمافزار SPSS، این لینک را ببینید.
پس از وزندهی دادهها با استفاده از مسیر زیر که در بالا نیز اشاره کردیم، به یافتن ضرایب همبستگی C، فی و کرامر میپردازیم.
Analyze → Descriptive statistics → Crosstabs
پس از رفتن به مسیر بالا، پنجره زیر با نام Crosstabs برای ما باز میشود.

در کادر Row کمیت Road را قرار میدهیم. در کادر Column نیز Equipment را قرار میدهیم. البته این انتخاب دلخواه است و در تحلیل فرقی ندارد سطر و ستون را کدام Variable قرار دهیم.
چنانچه علاقمند باشیم، نموداری از دادهها نیز به دست بیاید میتوانیم گزینه Display clustered bar charts را انتخاب کنیم.
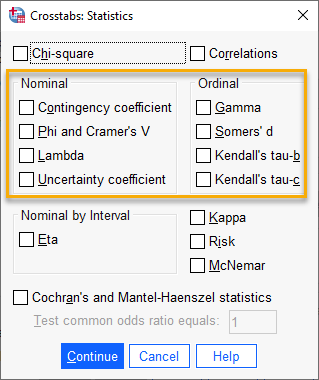
ما در این مثال به دنبال به دست آوردن ضرایب همبستگی مربوط به دادههای اسمی بودیم. لازم است آنها را انتخاب کنیم. این کار با استفاده از تب Statistics انجام میشود. بر روی آن میزنیم و وارد پنجره Crosstabs Statistics میشویم.
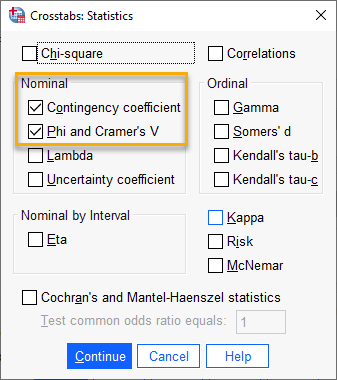
در این پنجره و در کادر Nominal، گزینههای Contingency Coefficient و Phi and Cramer’s V، را انتخاب میکنیم. خوب است بدانید که یکی از مسیرهای انجام تحلیل پرکاربرد کای دو Chi-square در همین پنجره است.
نتایج و خروجیهای نرمافزار
Output
Continue کرده و سپس OK میکنیم. به این ترتیب نتایج و خروجیهای زیر در Output نرمافزار SPSS به دست میآید.
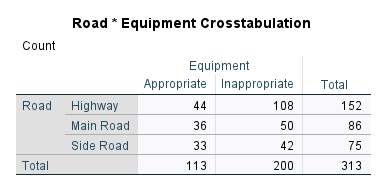
در جدول بالا می توانید فراوانی تعداد تصادفات براساس نوع جاده و وضعیت تجهیزات راهنمایی و رانندگی جاده را مشاهده کنید. این جدول در حال حاضر یافته مهمی برای ما ندارد و همان جدول توصیفی بالا است.
در ادامه و در جدول با نام Symmetric Measures اندازههای عددی ضریب همبستگی C به همراه فی Phi و کرامر Cramer’s V آمده است.

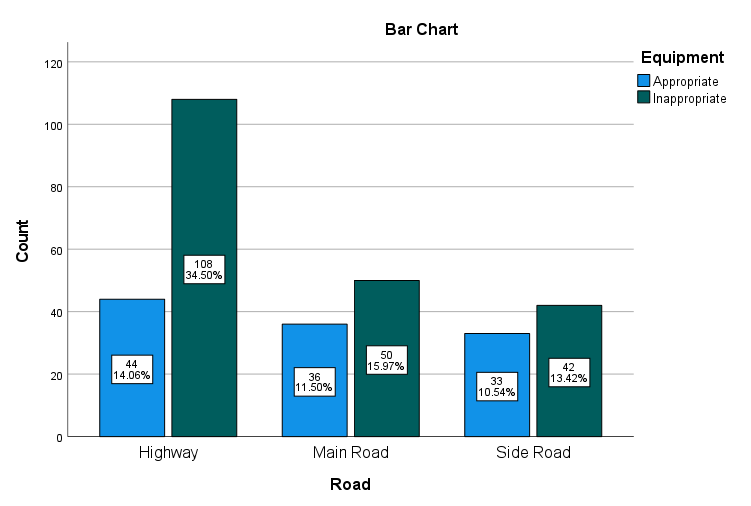
در این جدول عدد ضریب همبستگی فی، کرامر و Contingency به همراه مقدار احتمال معناداری تقریبی Approximate Significance آمده است. نتایج این جدول نشان میدهد رابطه بین نوع جاده و تجهیزات مثبت و معنادار است.
اندازهی عددی ارتباط بین کمیتهای نوع جادهها و تجهیزات جاده برابر با حدود 0.145 واحد است. مقدار احتمال تقریبی نیز معنادار و برابر با 0.036 شده است. این مطلب نشان میدهد که کمیتهای نوع جاده و تجهیزات جاده در یک جهت حرکت میکنند. یعنی اگر از بزرگراه به سمت جادههای فرعی حرکت کنیم و از تجهیزات مناسب به سمت تجهیزات نامناسب برویم، با افزایش احتمال تعداد تصادفات مواجه خواهیم بود.
علاوه بر جداول آماری، نرمافزار SPSS نمودار خوشه میلهای زیر را نیز برای ما به دست آورده است.
در این نمودار فراوانی و درصد فراوانی به ازای هر کدام از انواع جادهها و تجهیزات راهنمایی و رانندگی آنها، آمده است.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Contingency Coefficient, Phi and Cramer’s V analyzes using SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, https://graphpad.ir/contingency-coefficient-phi-cramers-v.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Contingency Coefficient, Phi and Cramer’s V analyzes using SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/contingency-coefficient-phi-cramers-v.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.