وزن دهی موردها و مشاهدات Weight Cases در نرمافزار SPSS
توضیحات برگرفته شده از کتاب روش های پیشرفته آماری و کاربردهای آن- انتشارات جامعهنگر
در یک مطالعه و طرح تحقیقاتی بسیار اتفاق میافتد که فایل دادهها و تمام نتایج ثبتشده در اختیار ما نیست و در واقع به جای کار کردن با فایل دادهها، نتایجی از مشاهدات را به صورت یک جدول فراوانی و یا یک جدول توافقی در اختیار داریم. در اینحالت استفاده از نتایج مشاهدات به منظور انجام تحلیلهای توصیفی و یا استنباطی بیشتر، با استفاده از مفهومی به نام وزندهی مشاهدات یا Weight Cases انجام میشود.
بر اساس این مفهوم تلاش میشود به نرمافزار، تکرار حالتها فهمانده شود. به عنوان مثال در جدول زیر که مربوط به میزان تحصیلات مادران و نمره درس ریاضی دانشآموزان است، در پی آن هستیم که نمودارهای مناسبی جهت نمایش مشاهدات بیابیم. همچنین میخواهیم به این سوال پاسخ دهیم که آیا بین میزان سواد و تحصیلات مادران با نمره درس ریاضی فرزندان آنها، ارتباط و اثرگزاری وجود دارد یا خیر.
| جدول توافقی نمره و تحصیلات | جدول توافقی نمره دانشآموز و تحصیلات مادران | تحصیلات مادران | |||
| کمتر از دیپلم | دیپلم و فوق دیپلم | کارشناسی | کارشناسی ارشد و بالاتر | ||
| نمره دانشآموزان | 17-20 | 11 | 12 | 6 | 5 |
| 13-17 | 14 | 17 | 13 | 9 | |
| 10-13 | 8 | 10 | 6 | 3 | |
| 5-10 | 3 | 2 | 2 | 0 | |
| کمتر از 5 | 1 | 2 | 0 | 1 |
به این نکته توجه کنید که هدف در این گونه مسائل شناختن تکرارها به نرمافزار است. به عنوان مثال نرمافزار متوجه شود که 11 دانشآموز که نمره درس ریاضی آنها 17 تا 20 شده است دارای مادرانی با سطح تحصیلات کمتر از دیپلم بودهاند و یا اینکه 13 نفر که نمره ریاضی بین 13 تا 17 گرفتهاند، مادران آنها دارای تحصیلات کارشناسی بوده است و به همین ترتیب برای سایر گزینهها.
میخواهیم آزمونهای فرضیه زیر را مورد بررسی قرار دهیم.
فرض صفر. نمره دانشآموزان و سطح تحصیل مادران دانشآموز از یکدیگر مستقل هستند.
فرض مقابل. نمره دانشآموزان و سطح تحصیل مادران دانشآموز به یکدیگر وابسته هستند.
به منظور انجام این تحلیل و آزمون فرضیههای بالا، چند مرحله را طی میکنیم که به ترتیب در ادامه نوشته شده است.
![]()
دادههای جدول بالا را به شکل زیر وارد نرمافزار میکنیم. فایل دیتای این مثال را میتوانید از اینجا دریافت کنید.
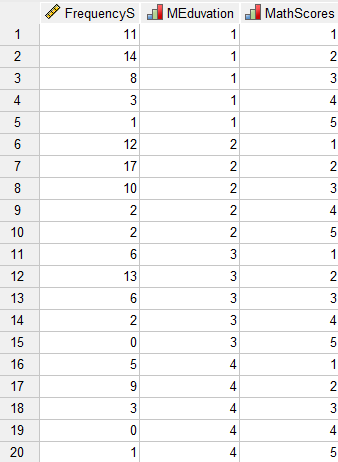
به این ترتیب ما فراوانی هر یک از گزینهها را در یک ستون (FrequencyS) وارد میکنیم. در ستون دیگر که نام آن را MEducation گذاشتهایم سطح تحصیلات مادر دانشآموز آمده است، بهطوری که کد 1 بیانگر تحصیلات کمتر از دیپلم، کد 2 دیپلم و فوق دیپلم، کد 3 کارشناسی و کد 4 کارشناسی ارشد و بالاتر را نشان میدهد.
به همین ترتیب ستونی تحت عنوان MathScores جهت معرفی نمرات دانشآموزان آمده است. کد یک نمره 20- 17، کد دو نمره 17- 13، کد سه نمره 13- 10، کد چهار نمره 10- 5 و کد پنج نمرات کمتر از 5 را نشان میدهد.
همانگونه که میدانیم این تعاریف از طریق گزینهی Values در پنجره Variable View انجام میشود.
بنابراین گام اول در پاسخ به فرضیه بالا، وارد کردن اطلاعات و نتایج جدول به نرمافزار SPSS به نحوی که به آن اشاره کردیم، میباشد.
![]()
پس از اینکه دادههای جدول را وارد نرمافزار کرده و فایل دیتا را در نرمافزار SPSS ساختیم، در مرحله بعد هدف ما معرفی فراوانیها به عنوان مقادیر تکرار پذیر به نرمافزار است. این فرایند را تحت عنوان وزندهی فراوانیها یا همان Weight Cases معرفی میکنیم. جهت انجام این کار از مسیر زیر در نرمافزار SPSS استفاده میکنیم.
Data→ Weight Cases
با انتخاب این گزینه، پنجره زیر با نام Weight Cases برای ما باز میشود.
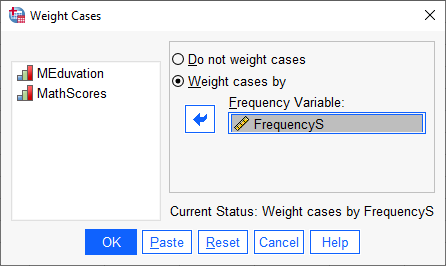
در این پنجره گزینه Weight cases by را انتخاب میکنیم. همچنین در کادر Frequency Variable ستون و کمیتی را قرار میدهیم که فراوانی افراد در آن نوشته شده است. از آنجا که ما فراوانیها را در ستون با نام FrequencyS نوشتهایم، این Variable را در کادر Frequency Variable قرار میدهیم.
سپس OK میکنیم. دقت کنید که پس از انجام این کار در فایل دادهها اتفاق خاصی نمیافتد، بلکه تنها در پنجره Output نرمافزار، پیامی با عنوان “WEIGHT BY FrequencyS” داده میشود.
با انجام این مرحله نرمافزار در مییابد که اعداد نوشته شده در ستون فراوانی به معنای مقادیر تکرارپذیر هستند. به عنوان مثال 12 نفر با کد 1 ستون MathScores (نمره 17-20) و با کد 2 ستون MEducation (تحصیلات دیپلم و فوق دیپلم) وجود دارند.
به همین ترتیب برای بقیه فراوانی نیز نرمافزار متوجه میشود که هر کدام از آنها بیانگر تکرار تعداد نفرات است.
![]()
پس از معرفی فراوانیها به نرمافزار با استفاده از روش Weight Cases، در مرحله بعد به انجام آزمون فرضیه وجود یا عدم وجود ارتباط بین تحصیلات مادران و نمره درس ریاضی دانشآموزان میپردازیم.
از آنجا که با فراوانیها روبهرو هستیم از آزمونهای احتمالی Contingency مانند کای اسکوئر یا کای دو Chi-Square استفاده میکنیم.
این کار با استفاده از مسیر زیر در نرمافزار SPSS انجام میشود.
Analyze → Descriptive Statistics → Crosstabs

پنجره زیر با نام Crosstabs برای ما باز خواهد شد.
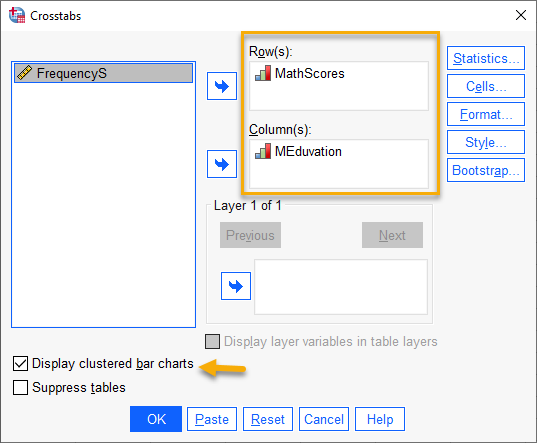
در این پنجره ما MathScores را که بیانگر نمرات ریاضی دانشآموزان بود در کادر Row و MEducation که نشاندهنده میزان تحصیلات مادران بود، در کادر Column قرار میدهیم. البته اگر آنها را جابهجا در سطر و ستون هم قرار دهیم، تفاوتی در نتایج آزمون کای دو نخواهد داشت.
همچنین به منظور مشاهده نمودار بین نمرات و تحصیلات، گزینه Display clustered bar charts را انتخاب میکنیم.
حال در پنجره Crosstabs بر روی تب Statistics میزنیم. به پنجره زیر میرویم.
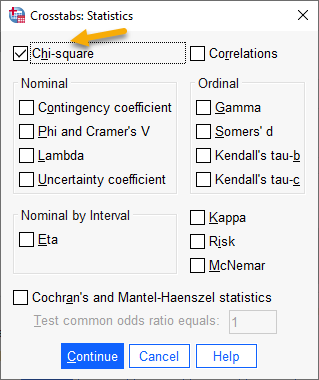
در پنجره Crosstabs Statistics آزمون Chi-square را انتخاب میکنیم. سپس دکمه Continue را میزنیم.
چنانچه بخواهیم درصدهای سطری و ستونی، نتایج را نیز مشاهده کنیم به تب Cells میرویم تا پنجره زیر با نام Crosstabs Cell Display برای ما باز شود.
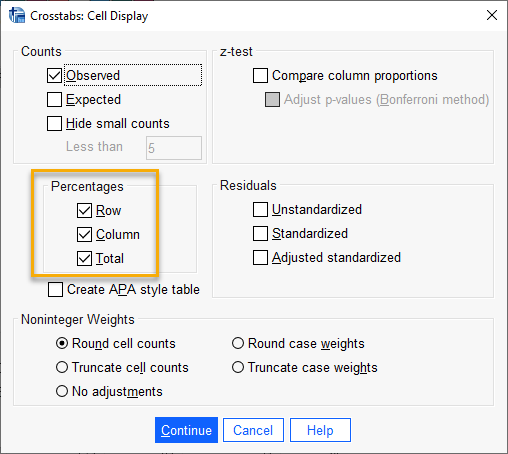
در پنجره Crosstabs Cell Display گزینههای Row، Column و Total را انتخاب میکنیم. در این صورت علاوه بر نمایش فراوانیها که خود جدول نیز آن را در اختیار ما قرار میداد، درصدهای سطری، ستونی و مجموع نیز برای ما در Output نرمافزار قابل مشاهده خواهد بود.
به منظور درک بهتر و بیشتر از آزمونهای کای دو، توصیه میکنیم متن و مقاله زیر را مشاهده کرده و به دقت مطالعه کنید.
درباره آزمونهای کای دو بیشتر بدانیم
در مرحلهی بعد Continue کرده تا دوباره وارد پنجره Crosstabs بشویم. دیگر در اینجا کاری نداریم. بنابراین OK میکنیم تا بتوان نتایج و خروجیهای نرمافزار را ببینیم.
نتایج و خروجیها
Output
هنگامی که در پنجره Crosstabs گزینه OK را میزنیم، در محیط Output نرمافزار SPSS، نتایج زیر برای ما به دست میآید. به توضیح آنها در ادامه میپردازیم.
در ابتدای خروجیها جدول توافقی بین تحصیلات و نمرات دیده میشود. در این جدول به تفکیک و به ازای هر کدام از ردههای تحصیلی مادران و نمره دانشآموزان، فراوانی به همراه درصدهای سطری، ستونی و مجموع نمایش داده شده است.
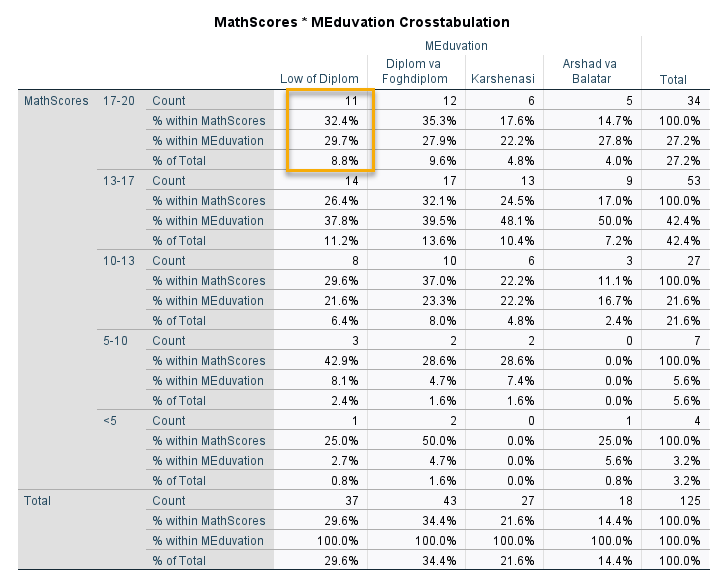
به عنوان مثال به کادر زردرنگ جدول بالا نگاه کنید. یافتههای این کادر نشان میدهد 11 دانشآموز که تحصیلات مادران آنها کمتر از دیپلم بوده است، نمره درس ریاضی آنها عددی بین 17 تا 20 شده است.
این 11 نفر، 32.4 درصد کل افرادی هستند که نمره آنها 17-20 به دست آمده است. همچنین آنها 29.7 درصد افرادی هستند که سطح تحصیلات مادران آنها کمتر از دیپلم بوده است. از آنجا که تعداد کل افراد مورد بررسی 125 نفر بوده است، نتیجه شده است که این 11 نفر برابر با 8.8 درصد از کل شرکتکنندگان در این مثال هستند.
بقیه جزئیات را نیز که به صورت کامل در جدول توافقی بالا بیان شده است، میتوانید ببینید.
خب، حال بیایید نتایج آزمون کای دو که با استفاده از آن میتوانیم فرضیه ارتباط و یا دم ارتباط بین تحصیلات مادران و نمره دانشآموزان را به دست بیاوریم، مشاهده کنیم. در جدول زیر نتیجه آزمون Chi-Square آمده است.
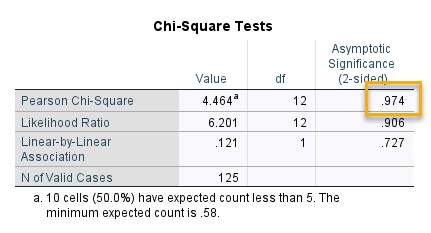
نتیجه به دست آمده در این جدول نشان میدهد در سطح معنیداری α = 0.05 درصد، رابطه بین تحصیلات مادران و نمره درس ریاضی دانشآموزان، معنادار نیست (P-value = 0.974). این مطلب به معنای آن است که فرض صفر (عدم ارتباط) تایید شده و فرض مقابل (وجود ارتباط) رد میشود.
بنابراین بر مبنای این دادهها و مثال مطرح شده، نمیتوانیم به وجود ارتباط معنادار بین نمره درس ریاضی دانشآموز و سطح سواد مادران، دست پیدا کنیم. بنابراین میپذیریم این دو Variable با یکدیگر ارتباط نداشته و از هم مستقل هستند.
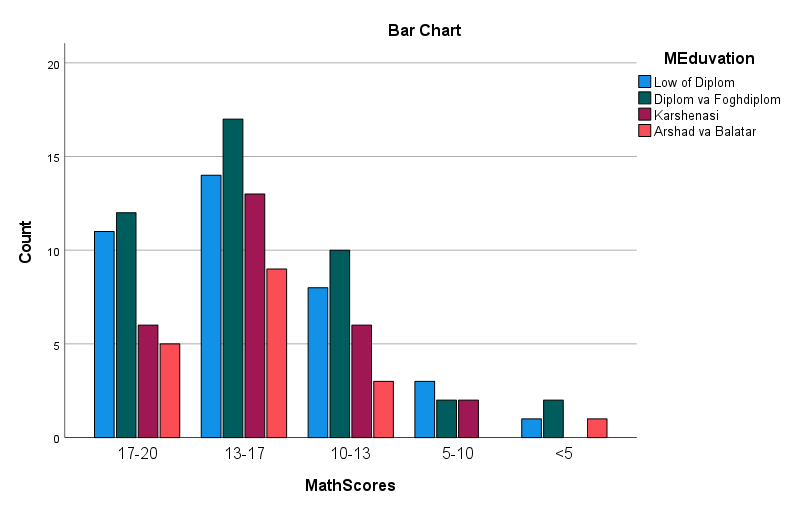
به یاد داشته باشید، در تنظیمات نرمافزار و در پنجره Crosstabs از SPSS خواستیم که نمودار میلهای خوشهای Clustered Bar بین Variable ها را نیز برای ما رسم کند. در انتهای Output ها، این گراف برای ما به دست آمده است.
همانگونه که در این گراف میتوانید مشاهده کنید، بیشترین فراوانی مربوط به دانشآموزان با نمرات درس ریاضی بین 13 تا 17 می باشد. در این رده مادران با تحصیلات دیپلم و فوق دیپلم، بیشتر از سایر تحصیلات به چشم میخورند.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Weight Cases in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/weight-cases-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Weight Cases in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/weight-cases-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.