آزمون ناپارامتری کوکران Cochran’s Q Test با نرم افزار SPSS
Cochran’s Q Test
آزمون ناپارامتری کوکران برای تعیین اینکه آیا در یک کمیت وابسته دوگانه بین سه یا چند گروه مرتبط تفاوتی وجود دارد یا خیر استفاده میشود. این آزمون را میتوان مشابه آنالیز واریانس اندازهگیری مکرر یک طرفه one-way repeated measures ANOVA در نظر گرفت، در حالی که کمیت وابسته آن به جای پیوسته، دوگانه Dichotomous است.

همچنین آزمون Cochran’s Q تعمیم یافته آزمون مک نمار McNemar’s Test در نظر گرفته میشود. آزمون کوکران معمولاً برای تحلیل مطالعات طولی longitudinal study و همچنین تحلیل شرکتکنندگانی که تحت آزمایشهای مختلف قرار گرفتهاند (معمولاً درمانها) استفاده میشود.
برای مثال، میتوانید از آزمون Cochran’s Q برای تعیین اینکه آیا تعداد و نسبت افرادی که عزت نفس پایین داشتند (در برابر افرادی که عزت نفس زیاد) پس از چند جلسه مشاوره کاهش یافته است یا خیر، استفاده کرد. در این مثال کمیت وابسته سطح عزت نفس است که دارای دو دسته «پایین» و «زیاد» میباشد و در چهار مقطع زمانی «قبل از جلسه اول مشاوره»، «بعد از جلسه دوم مشاوره»، «بعد از جلسه سوم مشاوره» و «بعد از جلسه مشاوره نهایی» اندازهگیری میشود.
هنگامی که آزمون Cochran’s Q را انجام میدهید، اگر نتیجه به دست آمده از نظر آماری معنادار نباشد، نشان میدهد که درصدها/نسبتها در مقاطع زمانی مختلف یا تحت درمانها/شرایط مختلف، یکسان است. در این شرایط، لزومی ندارد که نتایج خود را با یک تحلیل Post Hoc ادامه دهید. با این حال، اگر نتیجه آماری معنادار به دست بیاورید، احتمالاً میخواهید آزمون کوکران خود را با تحلیل تعقیبی دنبال کنید. من در این مقاله دربارهی این موضوع صحبت خواهم کرد.
انجام هر آزمون و تحلیل آماری نیاز به برقراری تعدادی پیش فرض و چارچوبهای آنالیز دارد. آزمون کوکران چهار پیش فرض دارد که باید رعایت شود. اگر این مفروضات برآورده نشدند، نمیتوانید از این آزمون استفاده کنید. بنابراین در ابتدا مناسب است دربارهی این موضوع صحبت کنیم.
پیش فرضهای Cochran’s Q Test
Assumptions
قبل از اینکه بخواهیم دربارهی نحوه انجام Cochran’s Q Test در نرمافزار SPSS صحبت کنیم، پیش فرضهای مختلفی را توضیح میدهیم که لازم است دادههای شما با آنها مطابقت داشته باشند تا نتیجه معتبری به شما بدهد. این پیش فرضها به صورت زیر هستند.
- پیش فرض (1)
کمیت وابسته باید دو گروهی باشد. مثالهایی از کمیتهای دوگانه Dichotomous شامل ایمنی درک شده (ایمن و ناایمن)، عملکرد امتحان (موفقیت و شکست)، انتخاب برند غلات (مارک A و برند B)، احساس دریازدگی (بله و نه)، میزان خستگی (کم و زیاد)، استفاده از تجهیزات ایمنی (از کلاه ایمنی استفاده میکند و از کلاه ایمنی استفاده نمی کند)، میباشد.
به این نکته دقت کنید که یک شرکت کننده نمیتواند همزمان در هر دو گروه باشد. به عنوان مثال، میخواهیم از آزمون کوکران برای تعیین اینکه آیا نسبت افرادی که قبل از یک دوره آموزشی دو هفتهای (مداخله)، در امتحان موفق شدهاند (در برابر رد شدن در امتحان) بعد از مداخله افزایش یافته است یا خیر، استفاده کنیم. در این مثال عملکرد در امتحان کمیت وابسته است که دارای دو گروه قبولی و مردودی میباشد.
هنگامی که یک شرکتکننده قبل از دوره دو هفتهای آموزشی در آزمون شرکت میکرد، فقط میتوانست آن را “گذرانده” یا “مردود” شده باشد. او نمیتوانست هم زمان هم قبول و هم مردود شود. به طور مشابه، پس از دو هفته دوره آموزشی نیز شرکتکننده همچنان میتوانست در امتحان قبول یا مردود شود.
- پیش فرض (2)
شما یک کمیت دارید که از سه یا چند گروه طبقهبندی شده و مرتبط Related Groups تشکیل شده است. به این معنا که کمیت شما ترتیبی Ordinal یا اسمی Nominal است.
مثالهایی از کمیت ترتیبی شامل موارد لیکرت (مثلاً مقیاس 7 رتبهای از کاملاً موافقم تا کاملاً مخالفم)، سطح فعالیت بدنی (مثلاً 4 گروه کم تحرک، کم، متوسط و زیاد)، مشتریانی که محصولی را دوست دارند. (از خیلی بد است تا خیلی خوب است). نمونههایی از کمیت اسمی شامل رشتههای تحصیلی (مثلاً، سه گروه علوم پایه، کشاورزی و “تربیت بدنی”)، مشاغل پرشکی (چهار گروه پزشک، پرستار، دندانپزشک و درمانگر).
مفهوم گروههای مرتبط Related Groups نشان میدهد که سه یا چند گروه مستقل نیستند. دلیل اصلی وجود گروههای مرتبط، داشتن افراد و مشاهدات یکسان در هر گروه است. زمانی که هر شرکت کننده دو یا چند مرتبه، در یک کمیت وابسته اندازهگیری شده باشد، میتوان در هر گروه افراد یکسانی داشت. به عنوان مثال، ممکن است شما عملکرد 10 نفر را در آزمون املا (Dependent Variable) در مراحل زمانی قبل، هنگام و بعد از اینکه تحت یک روش آموزش کامپیوتری برای بهبود املا قرار گرفتند، اندازهگیری کرده باشید. دوست دارید بدانید که آیا استفاده از روش آموزش کامپیوتر، عملکرد املایی آنها را بهبود میدهد یا اثرگزار نیست. گروه اول مرتبط شامل شرکت کنندگان در شروع (قبل از) آموزش املای کامپیوتری، گروه دوم مرتبط همان شرکت کنندگان در هنگام آموزش کامپیوتری و سومین گروه مرتبط از همان افراد در پایان مطالعه، تشکیل میشود.
- پیش فرض (3)
مشاهدات و افراد لازم است به عنوان یک نمونه تصادفی از جامعه مورد مطالعه، انتخاب شده باشند.
- پیش فرض (4)
اندازه نمونه شما به اندازه کافی بزرگ باشد که بتوانید مقدار احتمال مجانبی Asymptotic P-value به دست آمده توسط آزمون Cochran’s Q را تفسیر کنید. اگر اندازه نمونه شما ناکافی است، مقدار p مجانبی ممکن است دقیق نباشد، اما میتوانید یک نسخه Exact از آزمون کوکران را اجرا کنید که مقدار p دقیقتری را تولید کند.
مثال آزمون کوکران
Example
یک معلم مدرسه میخواهد بررسی کند که آیا داشتن زمان بیشتری برای مطالعه، باعث میشود که نرخ قبولی دانشآموزان افزایش یابد یا خیر. در این پژوهش، 60 دانشجو انتخاب شدند. از همه دانشآموزان ابتدا یک امتحان بدون اطلاع قبلی، گرفته شد. سپس دو هفته بعد از آنها یک امتحان آزمایشی و دو هفته بعدتر در امتحان نهایی شرکت کردند. عملکرد دانش آموزان در امتحانات بر حسب «موفق شدن» یا «مردودی» ارزیابی شد.
فایل دیتا این مقاله را میتوانید از اینجا Cochran’s Q Test دریافت کنید. در تصویر زیر بخشی از دادهها را مشاهده کنید.
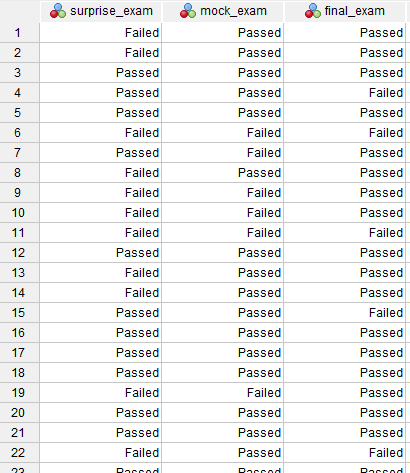
با توجه به اینکه دانشآموزان یکسانی در سه نوبت یعنی امتحان بدون اطلاع قبلی surprise_exam، آزمایشی mock_exam و نهایی final_exam، اندازهگیری شدهاند و وجود یک کمیت وابسته که دارای دو دسته متقابل منحصر به فرد است (مردودی و موفق)، آزمون کوکران انتخاب مناسبی برای تحلیل دادهها است.
جهت انجام تحلیل ناپارامتری Cochran’s Q Test دو مسیر و رویه جداگانه در نرمافزار SPSS وجود دارد. من در ادامه هر یک را توضیح میدهم.

Analyze → Nonparametric Tests → Legacy Dialogs → K Related Samples
با استفاده از مسیر بالا، پنجره زیر با نام Tests for Several Related Samples برای ما باز میشود.
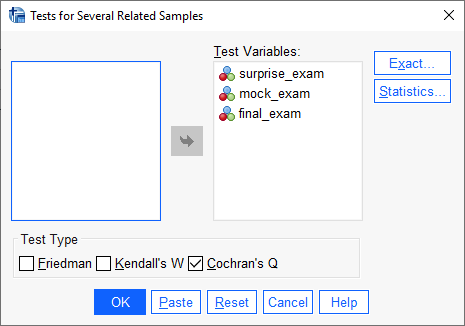
در این پنجره که مربوط به تنظیمات آزمونهای ناپارامتری k نمونه وابسته در نرمافزار SPSS است، آزمون Cochran’s Q را انتخاب میکنیم. همچنین ستونهای تایمهای مختلف امتحان در کادر Test Variables قرار میگیرند.
خب، حال OK کنید و در ادامه نتایج و خروجیهای نرمافزار SPSS را مشاهده کنید.
نتایج آزمون کوکران
Results
در پنجره Output میتوانید خروجیهای به دست آمده از آزمون ناپارامتری Cochran’s Q را ببینید. در ابتدای نتایج، جدول Frequencies آمده است.
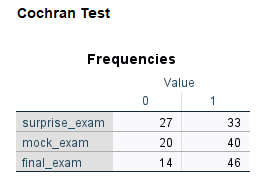
در این جدول تعداد افراد قبول و رد شده در هر کدام از امتحانهای بدون اطلاع، آزمایشی و نهایی، آمده است. به عنوان مثال نتایج این جدول به ما نشان میدهد که در آزمون ابتدایی 27 نفر رد شده و 33 نفر قبول شدهاند.
جدول بعدی در خروجیهای نرمافزار، با نام Test Statistics قرار دارد. در تصویر زیر آن را ببینید.
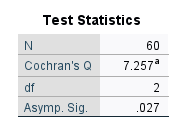
در این جدول میتوانیم به فرضیه برابر بودن درصد افراد قبول شده در مراحل مختلف امتحان، پاسخ دهیم.
نتیجه جدول بالا نشاندهنده وجود اختلاف معنادار نسبت افراد قبول شده است $ \displaystyle \left( {Cochran’s Q=7.257,\begin{array}{*{20}{c}} {} & {P-value=0.027} \end{array}} \right)$. به این ترتیب نتیجه میگیریم که داشتن زمان بیشتری برای مطالعه، باعث میشود که نرخ قبولی دانشآموزان افزایش یابد.
ایراد و نقصی که این مسیر نرمافزار دارد، عدم ارایه مقایسههای دوگانه بین زمانهای مختلف امتحان است. یعنی ما نمیدانیم کدام زمانها با یکدیگر اختلاف معنادار دارند و احیاناً کدامها ندارند. برای پاسخ به این سوال از مسیر دیگری در نرمافزار SPSS جهت اجرا آزمون Cochran’s Q استفاده میکنیم.
این مسیر در ورژنهای جدید نرمافزار SPSS قرار داده شده است و به نظرم دارای نتایج و خروجیهای بیشتری است.

Analyze → Nonparametric Tests → Related Samples
هنگامی که از مسیر بالا جهت انجام آزمونهای ناپارامتری در نمونههای وابسته استفاده میکنیم، پنجره زیر با نام Nonparametric Tests Two or More Related Samples برای ما باز میشود. در تصویر زیر آن را ببینید.
ما با استفاده از این مسیر و پنجره تنظیمات بالا، میتوانیم انواع آزمونهای ناپارامتری را که به بررسی دو یا چند گروه وابسته میپردازد، انجام دهیم. در ادامه به توضیح هر کدام از بخشها و تبهای این پنجره میپردازیم.
در این تب دو گزینه وجود دارد. انتخاب هر کدام به شما اجازه میدهد که هدف از آزمون ناپارامتری خود را مشخص کنید.
- Automatically compare observed data to hypothesized
با انتخاب این گزینه به نرمافزار اجازه میدهیم، بر مبنای نوع دادهها و تعداد گروههای وابسته، آزمون مناسب را انتخاب کند. بر این مبنا نرمافزار، آزمونهای McNemar’s, Cochran’s Q, Wilcoxon matched-pair Signed-Rank و Friedman’s 2-way ANOVA را انجام میدهد. معمولاً به صورت پیشفرض همین گزینه را میپذیریم.
- Custom analysis
هنگامی که میخواهید تنظیمات آزمون را به صورت دستی در تب Settings اصلاح کنید، این گزینه را انتخاب کنید. انتخاب این گزینه به شما امکان میدهد تا کنترل دقیقی بر آزمونهای انجام شده و گزینههای آنها داشته باشید. سایر آزمونهای ناپارامتری موجود در برگه تنظیمات عبارتند از Sign test، Marginal Homogeneity، و یک فاصله اطمینان (براورد Hodges-Lehmann) نیز برای نمونههای با دو گروه موجود است. همه این موارد را میتوانید در تب Settings مشاهده کنید.
Fieldsبا استفاده از گزینههای این تب، ستونهای تایمهای مختلف امتحان را وارد نرمافزار میکنیم.
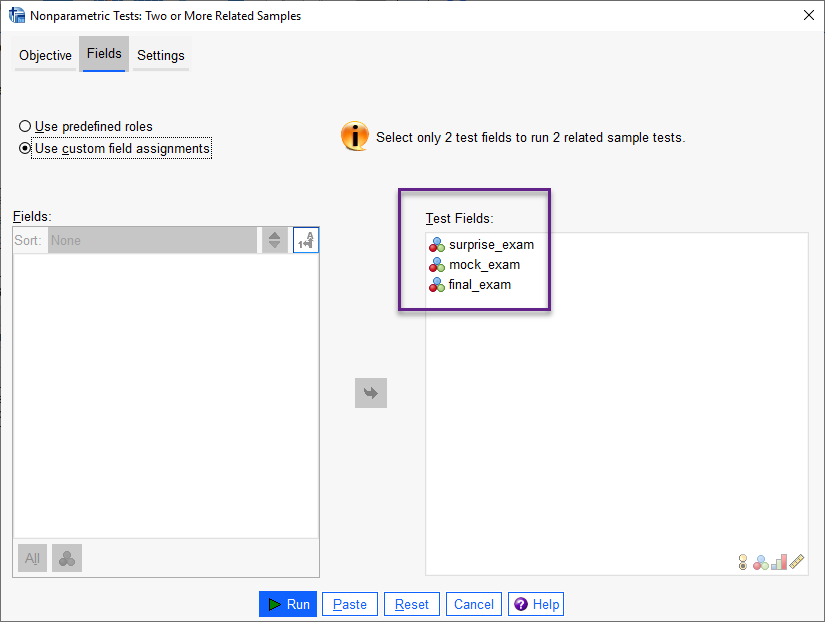
در کادر Test Fields ستونهای مربوط به امتحانهای بدون اطلاع، آزمایشی و نهایی، قرار میگیرد.
Settingsدر این تب میتوانیم انواع آزمونهای ناپارامتری قابل انجام برای نمونههای وابسته را مشاهده کنیم. هنگامی که در تب Objective گزینه Automatically compare observed data to hypothesized را انتخاب میکنیم، در تب Settings نیز به صورت پیشفرض گزینه Automatically choose the tests based on the data فعال است.
همانگونه که قبلاً نیز گفتیم، انتخاب این گزینه سبب میشود که نرمافزار به صورت خودکار و بر مبنای نوع و تعداد گروههای وابسته، آزمون آماری ناپارامتری مناسب دادهها را برای ما انجام دهد.
با این حال انتخاب گزینه Customize tests باعث میشود، به دلخواه بتوانیم آزمون ناپارامتری مورد علاقه را انجام دهیم. در تصویر زیر این آزمونها را ببینید.
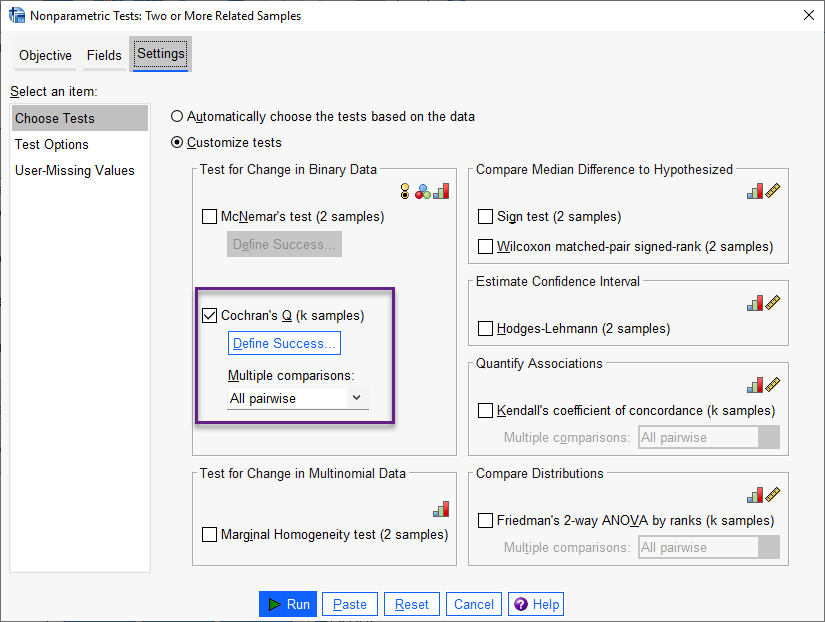
در پنجره بالا، آزمون Cochran’s Q مشخص و انتخاب شده است. در اینجا لازم است ابتدا با استفاده از دکمه ![]() به تعریف موفقیت (رویداد مورد علاقه) بپردازیم. پنجره زیر برای ما باز میشود.
به تعریف موفقیت (رویداد مورد علاقه) بپردازیم. پنجره زیر برای ما باز میشود.
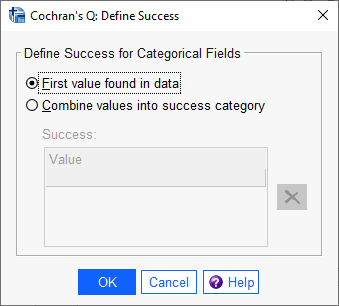
انتخاب گزینه First value found in data سبب میشود که نرمافزار اولین عدد نوشته شده در فایل دیتا را به عنوان کد موفقیت تعریف کند. چنانچه به فایل دیتا نگاه کنید، اولین عدد در اولین ستون، کد صفر است. به همین دلیل نرمافزار، Success را به عنوان کد صفر میخواند.

چنانچه بخواهیم کد دیگری را به عنوان Success به نرمافزار معرفی کنیم از گزینه Combine values into success category استفاده میکنیم. به عنوان مثال من میخواهم کد 1 را به عنوان موفقیت تعریف کنم، بنابراین از این گزینه مطابق با تصویر زیر استفاده میکنم.
البته خوب است این نکته را بدانیم که نحوه تعریف موفقیت، تاثیری بر روی نتایج آزمون کوکران ندارد.
در نهایت با استفاده از کادر Multiple comparisons و انتخاب گزینه All pairwise میتوانیم همه مقایسههای ممکن دو به دو بین تایمهای امتحان را به دست بیاوریم. در نهایت خروجیها و نتایج زیر به دست میآید.
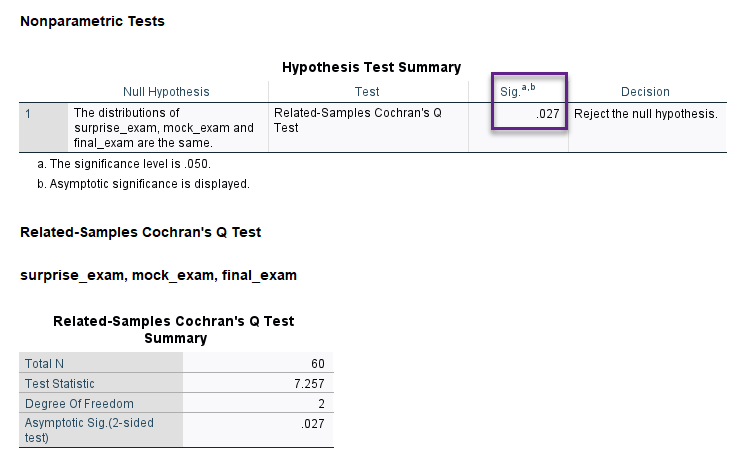
نتیجه به دست آمده بیانگر وجود اختلاف در نسبت افراد قبول شده در تایمهای مختلف امتحان است. این نتیجهای بود که در بخش قبل نیز به دست آوردیم.
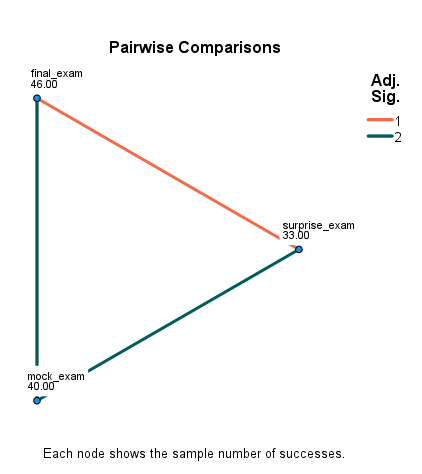
در گراف زیر درصد افراد قبول و رد شده در هر تایم امتحان، آمده است.
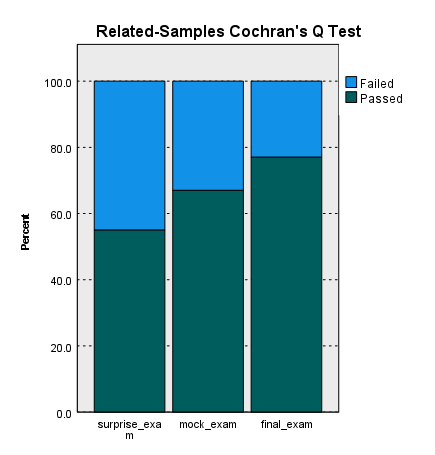
گراف بالا نشان میدهد، درصد افراد قبول شده در امتحان، با افزایش مدت زمان فرصت برای امتحان، بیشتر میشود. به این معنا که هر چقدر افراد فرصت بیشتری برای درس خواندن داشتهاند، نسبت قبولی آنها نیز افزایش داشته است. البته این نتیجهای است که قبلا نیز به دست آوردیم.

نتیجهای که ما به دنبال آن بودیم در جدول Pairwise Comparisons بالا آمده است. این جدول نشان میدهد اختلاف معنادار بین درصد موفقیت در آزمون و تایمهای امتحان در بین زمانهای امتحان ابتدایی و امتحان نهایی دیده میشود (P-value = 0.021).
در گراف زیر به خوبی معنادار بودن و یا نبودن مقایسههای دوبهدو بین تایمها آمده است.
نتیجه به دست آمده در نمودار بالا نشان میدهد بین زمانهای امتحان ابتدایی و نهایی اختلاف معنادار وجود دارد. اعداد نوشته شده تعداد افراد موفق شده در امتحان را نشان میدهد.
در همان تب Settings و از بخش Test Options میتوانیم به دلخواه خود سطح معناداری و فواصل اطمینان را قرار دهیم. نرمافزار SPSS به صورت پیشفرض این اعداد را به ترتیب 0.05 و 95.0 درصد قرار داده است.

چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2023). Cochran’s Q Non-parametric test with SPSS software. Statistical tutorial and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/cochrans-q-spss/.php
For example, if you viewed this guide on 12th January 2023, you would use the following reference
GraphPad Statistics (2023). Cochran’s Q Non-parametric test with SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2023, from https://graphpad.ir/cochrans-q-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.