پیش فرض های تحلیل رگرسیون خطی Linear Regression
مطالعه پیرامون ماهیت رابطه بین کمیتها را تحلیل رگرسیون Regression Analysis میگوییم. در واقع دو هدف عمده از بررسی روابط میان کمیتها عبارت است از
-
- چگونگی رابطه و میزان تاثیر کمیتها بر روی یکدیگر را مطالعه میکنیم.
- با در اختیار داشتن مقدار برخی از کمیتها، به پیشبینی بقیه کمیتها میپردازیم.
- پیش فرض 1
- پیش فرض 2
- پیش فرض 3
- پیش فرض 4
- پیش فرض 5
- پیش فرض 6
- پیش فرض 7
در این لینک (رگرسیون خطی Linear Regression در نرمافزار SPSS) میتوانید آموزش انجام تحلیل رگرسیونی خطی و براورد پارامترهای آن را ببینید.
آنچه من میخواهم در این مقاله صحبت کنم، پیشفرضهای انجام تحلیل رگرسیون خطی است. در واقع ارایه آنالیز رگرسیونی، نیاز به برقراری و تایید تعدادی پیشفرض در دادهها دارد. هنگامی که تصمیم میگیریم دادههای خود را با استفاده از Regression تحلیل کنیم، باید مطمئن شویم که دادهها واقعاً میتوانند با استفاده از آنالیز رگرسیونی تحلیل شوند و از 7 پیش فرضی که جهت ارایه یک نتیجه معتبر لازم است، تایید میگیرند.
بررسی این پیش فرضها کمی زمان بیشتری به آنالیز میافزایند و از شما میخواهند هنگام بررسی تنظیمات و تحلیل دادهها، روی چند دکمه دیگر در SPSS کلیک کنید و کمی بیشتر در مورد دادههای خود فکر کنید، نگران نباشید، کار سختی نیست.
پیشفرضهای تحلیل رگرسیونAssumptions
قبل از اینکه شما را با این 7 فرض آشنا کنیم، تعجب نکنید اگر هنگام تحلیل دادههای خود با استفاده از SPSS، یک یا چند مورد از این فرضیات نقض شد (برآورده نشود). در واقع هنگامی که با دادههای دنیای واقعی کار میکنیم، (به جای نمونههای کتاب درسی، که به شما نشان میدهند چگونه یک آنالیز رگرسیونی را زمانی که همه چیز خوب پیش میرود، انجام دهید.) این اتفاق عادی است و برای همه رخ میدهد. با این حال، نگران نباشید. حتی اگر دادههای شما برخی از پیش فرضها را تایید نکند، معمولاً راهی برای حل آن وجود دارد.
کمیت وابسته Dependent Variable که به آن پاسخ Response و Y نیز گفته میشود، باید در مقیاس پیوسته Scale اندازهگیری شوند. به عنوان مثال زمان (برحسب ساعت)، هوش (با استفاده از نمره IQ)، عملکرد امتحان (از 0 تا 100)، وزن (برحسب کیلوگرم) و غیره.
کمیتهای مستقل Independent Variables که به آنها پیشبینی کننده Predictor و یا X گفته میشود، نیز باید به صورت پیوسته Continuous اندازهگیری شده باشند.
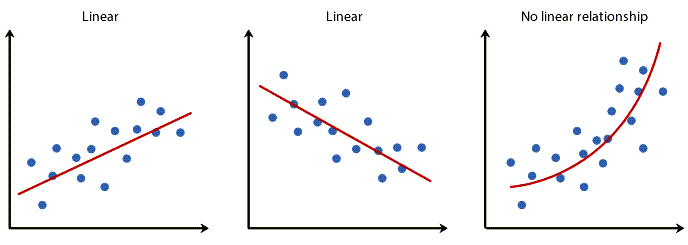
باید یک رابطه خطی linear relationship بین X و Y وجود داشته باشد. در حالی که روشهای مختلفی برای بررسی رابطه خطی وجود دارد، پیشنهاد میکنیم با استفاده از نمودارهای پراکنش Scatter Plots استفاده کنید. در این لینک (رسم نمودار پراکنش Scatter Plot با استفاده از نرمافزار SPSS) میتوانید آموزش رسم آنها را ببینید. با استفاده از این گرافها میتوانید به صورت بصری پراکندگی دادهها را به منظور خطی بودن بررسی کنید. نمودار پراکندگی شما ممکن است چیزی شبیه به یکی از موارد زیر باشد.
نمودارهای پراکنش اگر رابطه نمایش داده شده در نمودار پراکندگی شما خطی نیست، باید یک تحلیل رگرسیون غیرخطی انجام دهید، یک رگرسیون چند جملهای Polynomial Regression انجام دهید یا دادههای خود را تبدیل کنید، این کار را میتوانید با استفاده از SPSS انجام دهید.
نباید نقاط پرت Outliers قابل توجهی وجود داشته باشد. نقطه پرت یک نقطه داده مشاهده شده است که عدد پاسخ آن با مقدار پیشبینی شده توسط معادله رگرسیون بسیار متفاوت است. به این ترتیب، نقطه پرت نقطهای در یک نمودار پراکندش خواهد بود که (به صورت عمودی) از خط رگرسیون دور است و نشان میدهد که باقیمانده Residual و خطای زیادی دارد، گرافهای زیر را ببینید.
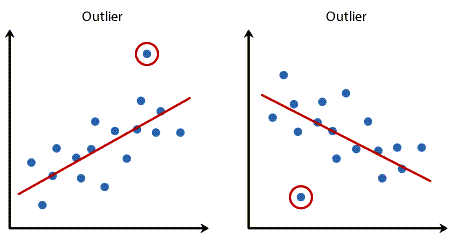
نقاط پرت در مدل رگرسیون خطی مشکل دادههای پرت این است که میتوانند تاثیر منفی بر تحلیل رگرسیون داشته باشند (به عنوان مثال، تناسب معادله رگرسیون را کاهش دهند) که برای پیشبینی مقدار کمیت وابسته (پاسخ) بر اساس کمیت مستقل (پیشبینی کننده) استفاده میشود. وجود دادههای پرت دقت پیشبینی نتایج شما را کاهش میدهند. خوشبختانه، هنگام استفاده از SPSS برای اجرای رگرسیون خطی، میتوانید به راحتی معیارهایی را برای کمک به تشخیص موارد پرت در نظر بگیرید. با استفاده از تشخیص موردی casewise diagnostics که یک فرآیند ساده هنگام استفاده از SPSS است، میتوانید نقاط پرت را تشخیص دهید. علاقمند بودید در این لینک (آزمون دوربین واتسن Durbin-Watson و تشخیص موردی Casewise diagnostics) میتوانید آموزش آن را ببینید.
همچنین با استفاده از رسم نمودارهای جعبهای که آموزش آن را میتوانید در این لینک ببینید (رسم Box Plot با استفاده از نرمافزار SPSS) میتوانیم به شناسایی و یافتن دادههای پرت، اقدام کنیم. در این زمینه میتوانید این آموزش را هم ببینید. (تشخیص داده پرت با استفاده از Grubbs’ Test در Minitab)
مشاهدات باید از یکدیگر مستقل باشند. این کار را به سادگی میتوانید با استفاده از آزمون دوربین-واتسن Durbin-Watson بررسی کنید. در این زمینه لینک (آزمون دوربین واتسن Durbin-Watson و تشخیص موردی Casewise diagnostics) را ببینید.
یکی دیگر از پیشفرضهای انجام تحلیل رگرسیون خطی برقرار بودن مفهومی به اسم هم واریانسی و یا Homoscedasticity است. در این زمینه توصیه میکنم حتماً مقاله آزمونهای ناهم واریانسی Heteroscedasticity Tests در نرم افزار SPSS را مطالعه کنید.
هم واریانسی به این معنا است که باید خطای مدل که به آن Residual و باقیمانده هم گفته میشود، دارای ثبات در واریانس باشد. مفهوم ثبات در واریانس هم به معنای این است که خطاهای مدل نباید با مقادیر عددی برازش شده برای Dependent Variable یا همان کمیت پاسخ، مرتبط و وابسته باشند.
به نمودارهای پراکندگی زیر که سه مثال ساده ارایه میدهند نگاه کنید. دو مورد از دادههایی که این فرض را نقض میکنند (به نام ناهم واریانسی Heteroscedasticity) و یک مورد از دادههایی که این فرض را برآورده میکند (به نام هم واریانسی Homoscedasticity).
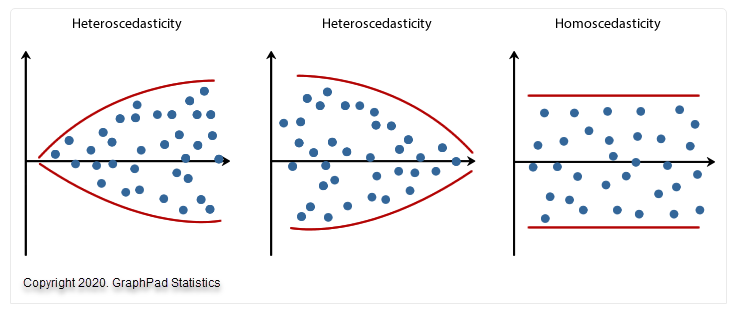
هم واریانسی Homoscedasticity و ناهم واریانسی Heteroscedasticity باقیماندهها یا همان Residuals باید به طور تقریبی نرمال باشند (Approximately Normally). در اینجا یک نکته بسیار مهم وجود دارد. آنالیز رگرسیون خطی نسبت به نقض فرض نرمال بودن باقیماندهها اصطلاحا استوار Robust است. به این معنی که این فرض میتواند تا حدی نقض شود و همچنان نتایج معتبری ارایه دهد. ما با استفاده از نمودار احتمال نرمال میتوانیم به بررسی این فرض بپردازیم. علاقمند بودید لینک (نمودار احتمال نرمال Normal Probability Plot در مدل های رگرسیونی) را ببینید. همچنین در این زمینه لینک بررسی نرمال بودن دادهها را مشاهده کنید (آزمون نرمال بودن دادهها Normality Test در نرمافزار SPSS).
در این مقاله به بیان پیشفرضهای آنالیز رگرسیون خطی پرداختیم. در واقع انجام تحلیل رگرسیون، نیاز به برقراری و تایید تعدادی پیشفرض در دادهها دارد، که باید مطمئن شویم دادهها واقعاً میتوانند با استفاده از آنالیز رگرسیونی تحلیل شوند و از 7 پیش فرضی که جهت ارایه یک نتیجه معتبر لازم است، تایید میگیرند.چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Assumptions of Linear Regression Analysis. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/assumptions-linear-regression/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Assumptions of Linear Regression Analysis. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/assumptions-linear-regression/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.
