رگرسیون مولفههای اصلی Principal Component Regression (PCR) در نرمافزار Prism
رگرسیون مولفه های اصلی، یک تکنیک پیشبینیکننده است که جایگزینی برای رگرسیون حداقل مربعات معمولی (OLS)، و رگرسیون حداقل مربعات جزئی (PLS) میباشد و زمانی مفید است که کمیتهای پیشبینیکننده (X) همبستگی بالایی با یکدیگر دارند یا زمانی که تعداد پیشبینیکنندهها از تعداد موارد (n) بیشتر باشد.
رگرسیون مولفه های اصلی PCR یک روش رگرسیون سریع، کارآمد و بهینه بر اساس کوواریانس است و معمولاً هنگامی استفاده میشود که Variableهای توضیحی زیادی که احتمالاً با یکدیگر همبسته هستند، در مطالعه وجود دارند. در زمینه همبسته بودن کمیتها میتوانید لینک (تشخیص هم خطی Collinearity Diagnostics در مدل های رگرسیونی) را مشاهده کنید.

تحلیل PCR روشی است که Variableهای مورد استفاده برای پیشبینی را به مجموعه کوچکتری از پیشبینی کنندهها کاهش میدهد. سپس از این مجموعه کوچک شده، برای انجام یک رگرسیون استفاده میکند. به این مجموعههای کوچک شده که از روی Independent Variableها ساخته میشود، اصطلاحاً مولفه Component گفته میشود.
PCR ویژگیهای تحلیل مولفههای اصلی Principal Component Analysis (PCA) و رگرسیون چندگانه Multiple Regression را ترکیب میکند. ابتدا مجموعهای از عوامل یا همان Component ها را به دست میآورد که تا حد امکان بیشترین کوواریانس بین کمیتهای مستقل را توضیح دهد. این بخش همان کاری است که PCA انجام میدهد. در مرحلهی بعد، مدل رگرسیون چندگانه را بین مقادیر کمیت وابسته و Component ها ایجاد میکند.
تفاوتها و شباهتها
تحلیلهایی مانند PLS، OLS، PCA و PCR را میتوان در یک رده قرار داد. آنها به صورت ترکیبی از تحلیلهای رگرسیونی و طراحی مولفهها Component کار میکنند. با اینحال با یکدیگر تفاوتهایی نیز دارند. در واقع هر کدام از آنها در یک ساختار متفاوت از مطالعه مورد استفاده قرار میگیرند.
در ادامه سعی کردهام به بیان تفاوتها و شباهتهای آنها با یکدیگر میپردازم. آموزش هر کدام از آنها را نیز میتوانید در سایت گراف پد مشاهده کنید.
- PCR با OLS
همانگونه که از نام آنها برمیآید، Principal Component Regression (PCR) و Ordinary Least Squares Regression (OLS) از نوع تحلیلهای رگرسیونی هستند. به این معنا که آنها دارای Dependent Variable (DV) و Independent Variable (IV) هستند و ما میخواهیم تاثیر IV ها را بر روی DV به دست بیاوریم. PCR رگرسیون مولفههای اصلی و OLS رگرسیون حداقل مربعات معمولی است. هم PCR و هم OLS به منظور براورد پارامترها از روش حداقل مربعات و مینیمم کردن مجموع مربع خطاها یعنی $ \displaystyle \sum\limits_{{i=1}}^{n}{{e_{i}^{2}}}$ استفاده میکنند.
با این حال تفاوت آنها در این است که PCR تحلیل رگرسیونی را بر روی مولفههای (Component) ساخته شده از روی Independent Variable ها انجام میدهند و OLS تحلیل رگرسیونی را بر روی خود Independent Variable ها انجام میدهد.
البته انجام تحلیل OLS نیاز به برقراری پیشفرضهایی دارد که در لینک (پیش فرض های تحلیل رگرسیون خطی Linear Regression) میتوانید مشاهده کنید. از PCR هنگامی که این پیشفرضها برقرار نباشد و به ویژه وجود هم خطی در بین کمیتهای مستقل دیده شود، استفاده میکنیم. آموزش رگرسیون OLS را هم میتوانید در لینک (رگرسیون حداقل مربعات معمولی Ordinary Least Squares regression (OLS)) ببینید.
- PCR با PCA
PCA با نام کامل Principal Component Analysis نامیده میشود. بنابراین به معنای این است که PCA فاقد آنالیز رگرسیونی است. دلیل مطلب نیز این است که ما در این تحلیل فاقد کمیت یا کمیتهایی با نام Dependent Variable هستیم و هر چه که داریم Independent Variable است. در واقع در PCA نمیخواهیم تاثیر IVها را بر روی DV به دست بیاوریم، بلکه میخواهیم از روی IVها به ساختن مولفههای اصلی یا همان Principal Component (PC) بپردازیم. در لینک (تحلیل مولفههای اصلی Principal Component Analysis (PCA)) میتوانید آموزش PCA را مشاهده کنید.
PCR نیز تا آنجا که به موضوع طراحی PC ها مربوط میشود با PCA همگام است و مشابه با آن کار میکند، اما به دلیل اینکه PCR دارای Dependent Variable است، یک گام از PCA جلوتر است و تحلیل رگرسیونی را بر روی PCهای ساخته شده از روی Independent Variable ها انجام میدهد.
- PCR با PLS
نام کامل PCR به صورت رگرسیون مولفههای اصلی Principal Component Regression بیان میشود. بنابراین PLS و PCR همانند OLS از نوع تحلیلهای رگرسیونی هستند. به این معنا که آنها دارای Dependent Variable (DV) و Independent Variable (IV) هستند و ما میخواهیم تاثیر IV ها را بر روی DV به دست بیاوریم.
هم PLS و هم PCR تحلیل رگرسیونی را بر روی مولفههای اصلی PC ها انجام میدهند. با این حال تفاوت آنها در نحوه طراحی و ساختن PC ها است. در PLS مولفهها (Component) از روی Independent Variable و Dependent Variable ها ساخته میشوند ولی در PCR مولفههای اصلی فقط از روی Independent Variable ها طراحی میشوند. علاقمند بودید از لینک (رگرسیون حداقل مربعات جزئی Partial Least Squares Regression (PLS)) میتوانید آموزش PLS را مشاهده کنید.
در این مقاله من به دنبال تعریف و کاربرد رگرسیون مولفه های اصلی PCR با استفاده از نرمافزار Prism هستم. در ادامه، مثال این مقاله را مشاهده میکنید. فایل دیتا را میتوانید از اینجا Principal Component Regression دریافت کنید.
مثال Principal Component Regression
Example
یک تولیدکننده نوشیدنی میخواهد بداند ترکیب شیمیایی نوشیدنی چگونه با ارزیابیهای حسی مرتبط است. او 37 نمونه دارد که هر کدام با 17 غلظت از عناصر (Cd, Mo, Mn, Ni, Cu, Al, Ba, Cr, Sr, Pb, B, Mg, Si, Na, Ca, P, K) به دست آمده است. او میخواهد امتیاز رایحه نوشیدنی را بر مبنای 17 عنصر پیشبینی کند.
بنابراین او در مطالعه خود هم دارای Dependent Variable (امتیاز رایحه) و هم تعداد زیادی Independent Variable (17 عنصر مختلف) است. تعداد مشاهدات در مقایسه با تعداد IV ها کم بوده (37 مشاهده) است. در واقع از آنجایی که نسبت نمونهها به پیشبینی کنندهها کم است، تولیدکننده تصمیم میگیرد از رگرسیون مولفه های اصلی PCR استفاده کند.
دادهها و این مثال را میتوانید از لینک (I.E. Frank and B.R. Kowalski (1984). “Prediction of Wine Quality and Geographic Origin from Chemical Measurements by Partial Least-Squares Regression Modeling,” Analytica Chimica Acta, 162, 241 − 251) دریافت کنید.
در تصویر زیر بخشی از دادههای این مثال آمده است.
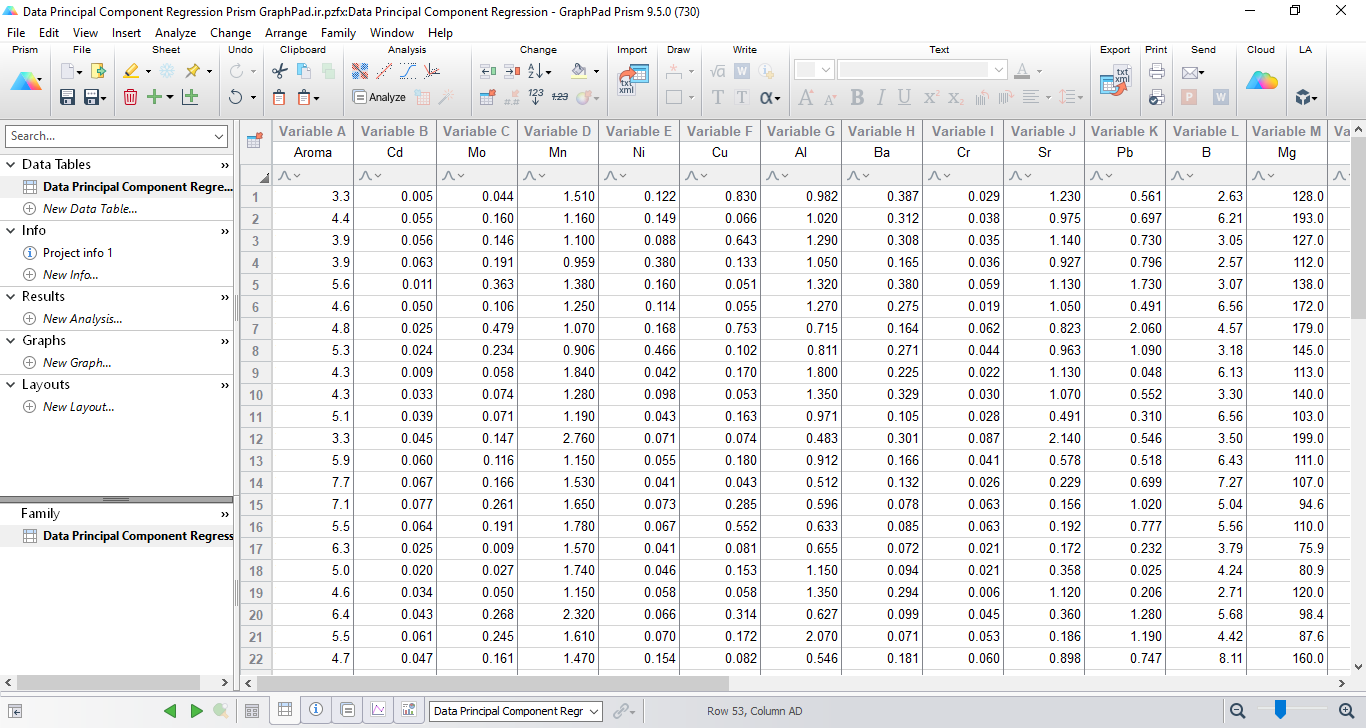
امتیاز رایحه که همان Dependent Variable است در ستون Aroma آمده است. در بقیه ستونها نیز غلظت عناصر مختلف که همان Independent Variable هستند، قرار گرفته است. هدف از این مطالعه این است که بتوانیم با استفاده از تحلیل (PCR) تعداد Variableها مورد نیاز برای توصیف مناسب دادهها را کاهش دهیم و سپس بر مبنای مجموعه کوچکی از اجزای اصلی ایجاد شده (مثلاً 3-2 مولفه)، به پیشبینی امتیاز رایحه نوشیدنی بپردازیم.
نکتهدر ادامه مراحل انجام Principal Component Regression در نرمافزار گراف پد را آوردهام. سعی میکنم هر یک را با جزئیات بیان کنم. در ابتدا به این نکته توجه کنید که در نرمافزار Prism تحلیل PCR در بخش تحلیلهای PCA قرار گرفته است. در واقع این نرمافزار، رگرسیون مولفههای اصلی را بخشی از تحلیلهای مولفه های اصلی میداند. بنابراین لازم است به هنگام کار با گراف پد، وارد بخش PCA شویم.
در شیت دیتا و در منوی Analysis بر روی گزینه Analyze میزنیم. البته میتوانیم به صورت مستقیم نیز ابزارک Principal Component Analysis انتخاب کنیم.
در این صورت وارد پنجره زیر با نام Analyze Data میشویم.
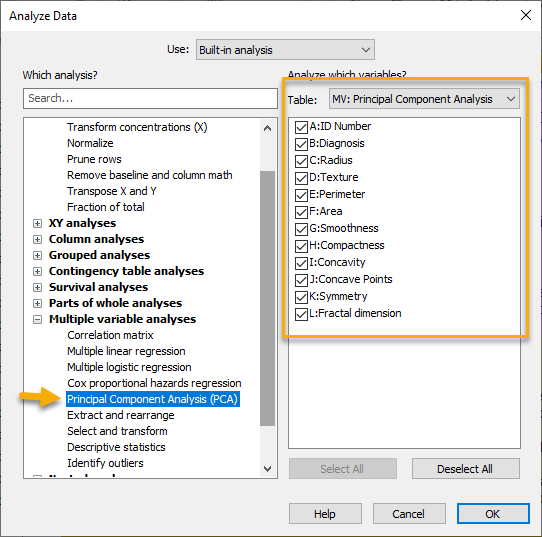
از آنجا که PCA یک تحلیل از نوع Multiple است، بنابراین در گزینههای Multiple variable analyses قرار دارد. آن را انتخاب میکنیم. در سمت راست پنجره بالا نیز اسامی Variable های موجود در مطالعه آمده است. چنانچه احیاناً خواستیم یک یا چند کمیت در مطالعه قرار نگیرد، تیک آنها را بر میداریم. با OK کردن وارد پنجره زیر میشویم.
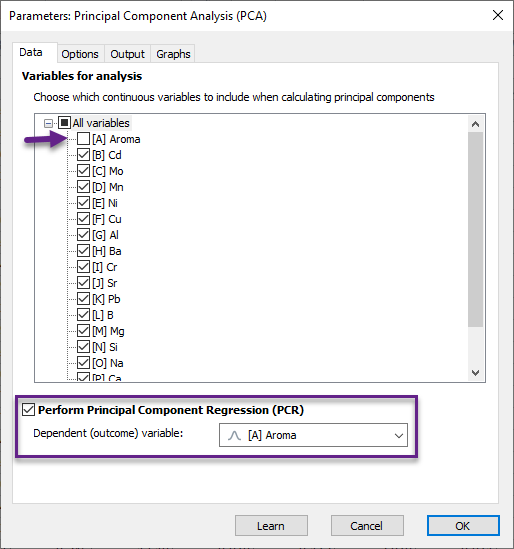
در پنجره Parameters Principal Component Analysis (PCA) به انتخاب تنظیمات نرمافزار جهت رگرسیون مولفههای اصلی، میپردازیم. به منظور فعال شدن PCR ابتدا لازم است در کادر بالا تیک کمیت Aroma را برداریم. این کار به دلیل این است که Aroma باید به عنوان کمیت وابسته Dependent Variable قرار گیرد و هنگامی که تحلیل از نوع PCR را انجام میدهیم، نباید کمیت وابسته در تشکیل Component ها مشارکت داشته باشد. (در متنهای قبلی به تفاوت بین PLS و PCR دقت کنید.)
من در لینک (تحلیل مولفههای اصلی Principal Component Analysis (PCA) در نرمافزار Prism) به صورت کامل به بیان گزینهها، تبها، تنظیمات و گرافهای موجود در این پنجره پرداختم. در این مقاله هدف من این است که صرفاً به بیان Principal Component Analysis (PCA) بپردازم. بنابراین از ذکر سایر گزینهها خودداری میکنم و خواننده علاقمند را به لینک بالا جهت مشاهده توضیحات بیشتر تحلیل مولفه های اصلی، ارجاع میدهم.
نرمافزار Prism، گرافها و نمودارهای مختلفی به هنگام اجرا کردن PCR به دست میدهد. در ادامه و به هنگام مشاهده نمودارهای به دست آمده، دربارهی آنها صحبت میکنیم. حال OK میکنیم. با انجام این کار در شیتهای Results و Graphs نتایج و نمودارهای PCR به دست میآید. در ادامه مقاله به توضیح و بیان آنها میپردازیم.
نتایج رگرسیون مولفههای اصلی
Results
پس از اجرای رگرسیون مولفههای اصلی، در شیت Results نرمافزار Prism، صفحه زیر را مشاهده میکنید.
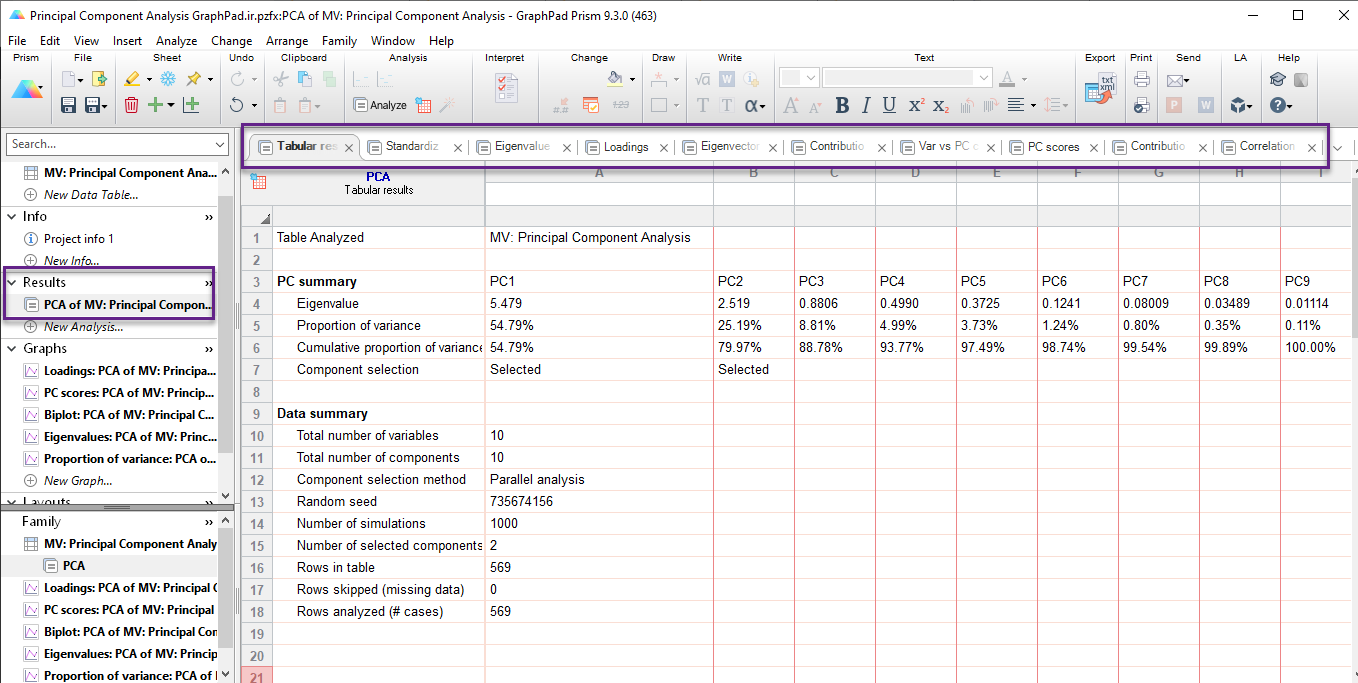
در صفحه نتایج، تبهای مختلفی مشاهده میکنید. من در تصویر بالا آنها را مشخص کردهام. هر کدام از این تبها به بیان جدول و نتایج مختلفی از تحلیل PCR اشاره میکند. در ادامه هر یک را توضیح میدهیم.
اولین تبی که در شیت Results دیده می شود با نام Tabular results است. من در تصویر بالا نمای کلی از آن آوردهام.
در این تب اطلاعاتی دربارهی مولفههای اصلی یا همان PCهای تشکیل شده، مقادیر ویژه، نسبت واریانس توضیح داده شده (همراه با نسبت تجمعی آن)، و تعداد PCهای انتخاب شده، آمده است.
به این نکته مهم توجه کنید که PCR قبل از اینکه یک تحلیل رگرسیونی باشد یک PCA است. بنابراین ابتدا به تشکیل و طراحی مولفههای اصلی میپردازد و سپس با استفاده از Principal Component های به دست آمده به ارایه و انجام رگرسیون PC میپردازد. من در تصویر زیر این نتایج را نشان دادهام.

در یک تحلیل PCR، به تعداد Variableها، مولفه اصلی یا همان PC خواهیم داشت. بنابراین ما در اینجا با 17 مولفه اصلی روبهرو هستیم. با این حال همه آنها به عنوان انتخاب شده Selected، در تحلیل ما قرار نمیگیرند. در این مثال چهار مولفه (از PC1 تا PC4) به اندازه 65.11 درصد پراکندگی و واریانس دادهها را بیان میکنند. این نتیجه از یافتههای سطر Cumulative proportion of variance به دست میآید. PC1 به تنهایی 24.42% و PC2 به تنهایی 15.72% واریانس دادهها را بیان میکنند.
بنابراین نتیجه میشود که 17 کمیت به 4 مولفه اصلی یا PC تبدیل می شوند. این هدف ابتدایی تحلیل PCR است. یعنی تبدیل تعداد زیاد Variableها به تعداد کمتر PCها، در عین حفظ حداکثری اطلاعات (حدود 65 درصد در این مثال). اما همچنان کار ما تمام نشده است و ما به دنبال ایجاد یک مدل رگرسیونی هستیم.
در بخش دیگر تب Tabular results، اطلاعاتی درباره تعداد کمیتها، مشاهدات، روش انتخاب مولفهها و موارد دیگر آمده است. در تصویر زیر آنها را ببینید.
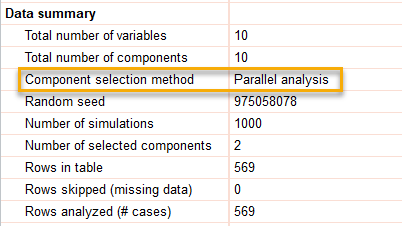
نتایج این بخش نشان میدهد ما تعداد 17 کمیت و مولفه داشتهایم. نرمافزار از روش تحلیل موازی Parallel analysis جهت انتخاب مولفهها استفاده کرده است. در روش تحلیل موازی، 1000 مجموعه دیتا شبیهسازی شده و از بین 17 مولفه، 4 مولفه انتخاب شده است. به توضیحات بیشتر دربارهی تحلیل موازی علاقمند بودید لینک (تحلیل مولفههای اصلی Principal Component Analysis (PCA) در نرمافزار Prism) را ببینید.
تعداد مشاهدات جهت آنالیز نیز 37 مورد بوده است. داده گمشده و Missing data هم نداشتهایم. این خلاصه موضوعاتی است که در تحلیل PCR مثال ما و در بخش با نام Data summary آمده است.
آنچه ما به دنبال آن بودیم یعنی انجام رگرسیون بر روی Componentها در تب PCR results آمده است. در تصویر زیر میتوانید نتایج آن را مشاهده کنید.
در این تب، نتایج یک رگرسیون واقعی آمده است و همان چیزی است که ما به دنبال آن بودیم. روش رگرسیون انجام شده نیز حداقل مربعات Least Squares میباشد. مانند همه رگرسیونها، در شیت PCR results ابتدا نتایج آنالیز واریانس آمده است. در تصویر زیر آن را ببینید.

نتیجه به دست آمده در جدول آنالیز واریانس بالا، نشاندهنده وجود رابطه معنادار بین Dependent Variable امتیاز رایحه نوشیدنی با Independent Variable ها میباشد (P value<0.001).
یک چیزی در این نتایج میتواند توجه ما را به خود جلب کند. عدد DF درجه آزادی مدل رگرسیونی برابر با 4 به دست آمده است. در حالی که اگر قرار بود ما با یک مدل رگرسیونی خطی Multiple Regression روبه رو باشیم باید عدد DF برابر با تعداد کمیتهای مستقل موجود در مدل و برابر با 17 بود. پس چرا درجه آزادی در اینجا 4 است؟
پاسخ این است که ما در اینجا با یک مدل رگرسیون خطی چندگانه Multiple Linear Regression (MLR) روبهرو نیستیم، بلکه ما یک مدل رگرسیون مولفههای اصلی PCR انجام میدهیم. در بالاتر نیز گفتیم این مدل رگرسیونی بر روی Independent Variable ها انجام نمیشود، بلکه بر روی Component های تشکیل شده از روی کمیتهای مستقل انجام میشود. از آنجا که ما 4 مولفه اصلی در این مثال شناسایی کردیم، بنابراین تعداد درجات آزادی مدل رگرسیونی ما نیز به تعداد مولفههای اصلی یعنی چهار خواهد بود و نه به تعداد کمیتهای مستقل یعنی 17.
شاید مهمترین هدفی که ما از تحلیل Principal Component Regression (PCR) داشتیم، رسیدن به نتایج جدول ضرایب و براورد پارامترهای رگرسونی، یعنی یافتن میزان و اندازه تاثیر هر کمیت مستقل بر روی کمیت وابسته بوده است. درست است که مدل PCR بر روی Component ها اجرا میشود، اما هدف نهایی ما از اجرای مدل، درک اثرگزاری هر Independent بر روی Dependent (البته به واسطهی اجرا کردن یک مدل رگرسیون مولفههای اصلی) بوده است. این نتیجهای است که در جدول زیر به دست آمده است. آن را ببینید.
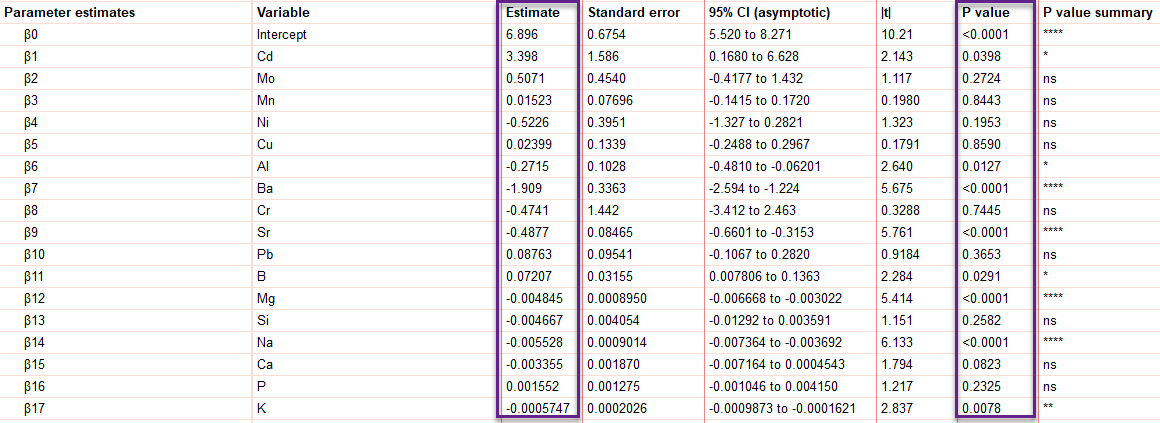
در واقع یکی از خوبیهای نرمافزار Prism این است که پس از اجرای مدل رگرسیون مولفه های اصلی PCR بین کمیت وابسته و Principal Component ها، ضرایب رگرسیونی را به خود کمیتهای مستقل تبدیل میکند. این کار و فهم ما را سادهتر میکند. در واقع Prism یک گام جلوتر حرکت میکند و به جای ارایه گزارش و بیان نتایج ضرایب رگرسیونی بر روی Component ها، که خب شاید فهم آنها برای ما سخت باشد، کار را سادهتر میکند و نتایج PCR به دست آمده را روی Independent Variable های مطالعه، تبدیل میکند.
ضرایب مثبت در این جدول، نشاندهنده تاثیر مثبت افزایش غلظت آن عنصر بر امتیاز رایحه و ضرایب منفی بیانگر تاثیر منفی افزایش غلظت آن عنصر بر روی امتیاز رایحه است. در مواردی هم که نزدیک به صفر هستند، نشاندهنده تاثیر ضعیف و اندک عنصر بر امتیاز رایحه نوشیدنی است. از نتایج ستون P value میتوانیم معنادار بودن یا نبودن تاثیر عنصر بر امتیاز رایحه نوشیدنی را به دست بیاوریم.
به عنوان مثال این جدول نشان میدهد عنصر کادمیوم Cd تاثیر مثبت (Estimate = 3.398) بر رایحه نوشیدنی دارد. با این حال عنصر Ba تاثیر منفی (Estimate = -1.909) بر رایحه نوشیدنی دارد. بقیه موارد را نیز میتوانید در جدول بالا مشاهده کنید.
در این تب مقادیر ویژه Eigenvalue مربوط به هر PC آمده است. هم مقادیر ویژه مربوط به دادههای مورد تحلیل قرار گرفته (استاندارد شده) و هم مقادیر ویژه به دست آمده از روش شبیهسازی و تحلیل موازی. در تصویر زیر آنها را ببینید.
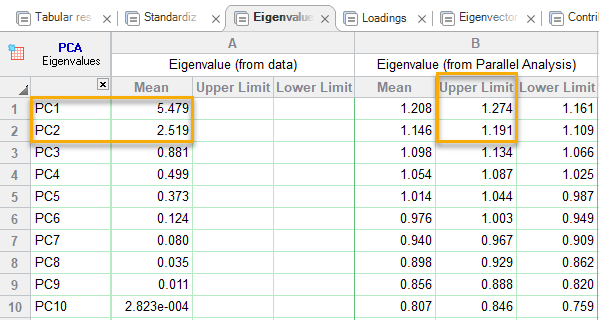
در تب بالا و در بخش مربوط به Eigenvalue (from data)، مقادیر ویژه هر PC آمده است. این نتایج از تحلیل عاملی بر روی دادههای استاندارد شده حاصل میشود. در بخش Eigenvalue (from Parallel Analysis)، مقادیر ویژه به دست آمده از تحلیلهای عاملی بر روی دادههای شبیهسازی شده (1000 مجموعه دیتا توسط نرمافزار ساخته شده است.) مشاهده می شود.
به ازای هر PC، میانگین، Upper Limit که همان صدک 95 ام، 1000 مقدار ویژه به دست آمده از شبیهسازی است، همراه با Lower Limit که صدک 5 ام، مقادیر ویژه است، دیده میشود. به یاد داشته باشید در لینک (تحلیل مولفههای اصلی Principal Component Analysis (PCA)) برای روش تحلیل موازی بیان کردیم که مولفههایی انتخاب میشوند که مقادیر ویژه آنها از صدک 95ام بزرگتر باشد.
همانگونه که در نتایج جدول بالا مشاهده میکنید، فقط برای PC1 تا PC4 است که مقادیر ویژه به دست آمده از روی دادههای استاندارد شده آنها بزرگتر از مقادیر ویژه صدک 95 ام است، به همین دلیل آنها جهت اجرای مدل PCR انتخاب شدهاند و بقیه PC ها در مدل قرار نگرفتهاند.
تب بعدی در شیت نتایج نرمافزار Prism، با نام Loadings معرفی میشود. فهم نتایج این شیت ساده است. ابتدا در تصویر زیر آن را ببینید.
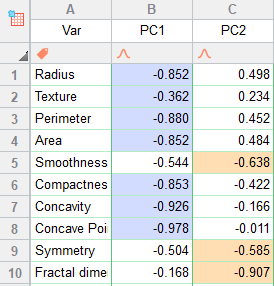
خوب است ابتدا بدانید اعداد نوشته شده، همبستگی Correlation هستند. بنابراین در بازه 1+ تا 1- قرار دارند. هر عدد نشاندهنده ارتباط بین Variable با PC انتخاب شده است. به عنوان مثال عدد 0.854- بیانگر وجود ارتباط قوی و وارون بین Mo و PC2 است.
کاربرد نتایج تب Loadings در این جهت است که ما میتوانیم تشخیص دهیم، هر Variable در کدام PC بهتر است قرار گیرد. به عنوان مثال برای Ni عدد جدول Loadings برای PC4 بزرگتر از بقیه و برابر با 0.433 به دست آمده است. این عدد نشان میدهند Ni بیشتر تمایل دارد به PC4 تعلق گیرد، زیرا دارای همبستگی قویتری با آن به نسبت سایر PC ها است.
به همین ترتیب برای سایر Variableها، در هر PC که عدد آن بزرگتر بود (به صورت قدرمطلق و صرفنظر از مثبت یا منفی بودن آن)، به همان PC تعلق میگیرد. من در جدول بالا با استفاده از رنگ، مشخص کردم که هر Variable متعلق به کدام PC است.
تب بعدی نتایج با نام PC scores شناخته میشود. به منظور درک آنها به نظرم بهتر است ابتدا درباره نتایجی با نام بردارهای ویژه Eigenvectors صحبت کنیم. البته ما فعلاً این تب را در نتایج PCR خود نمیبینیم. در ادامه دربارهی آنها صحبت میکنیم.
بردارهای ویژه Eigenvectors که به آنها بردارهای مولفه اصلی Principal Component Vectors نیز میگویند، بیانگر ضرایب مدل خطی بین PCها با Variableها هستند. جهت به دست آوردن آنها لازم است بار دیگر به تنظیمات پنجره Parameters Principal Component Analysis (PCA) بازگردیم. در آنجا از تب Output گزینه Eigenvectors را انتخاب میکنیم. تصویر زیر را ببینید.
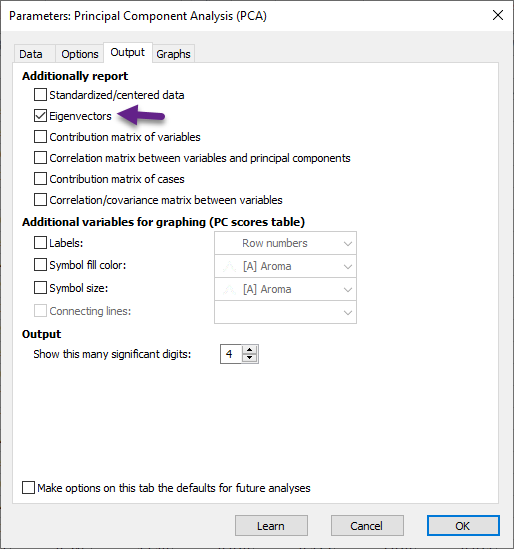
با OK کردن همان نتایج PCR تکرار میباشد، منتهی اینبار یک شیت جدید به نام Eigenvectors به نتایج نرمافزار اضافه شده است. در تصویر زیر من جدول بردارهای ویژه برای مولفههای اصلی انتخاب شده را آوردهام.
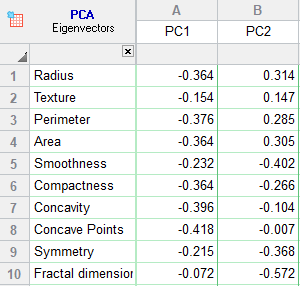
بیان کردیم که بردارهای ویژه Eigenvectors بیانگر ضرایب مدل خطی بین PCها با Variableها هستند. به عنوان مثال مدلهای زیر را ببینید.
$\displaystyle \begin{array}{l}PC1\begin{array}{*{20}{c}} {} \end{array}is\begin{array}{*{20}{c}} {} \end{array}defined\begin{array}{*{20}{c}} {} \end{array}as=\left( {0.044\times Cd} \right)-\left( {0.163\times Mo} \right)+\left( {0.032\times Mn} \right)\begin{array}{*{20}{c}} {} \end{array}and\begin{array}{*{20}{c}} {} \end{array}so\begin{array}{*{20}{c}} {} \end{array}on\\PC2\begin{array}{*{20}{c}} {} \end{array}is\begin{array}{*{20}{c}} {} \end{array}defined\begin{array}{*{20}{c}} {} \end{array}as=-\left( {0.360\times Cd} \right)-\left( {0.522\times Mo} \right)-\left( {0.124\times Mn} \right)\begin{array}{*{20}{c}} {} \end{array}and\begin{array}{*{20}{c}} {} \end{array}so\begin{array}{*{20}{c}} {} \end{array}on\end{array}$
در این مدلها رابطه خطی بین عناصر به عنوان Independent Variables با هر کدام از PC ها نوشته شده است. از آنجا که میتوان بردارهای ویژه را به عنوان ضرایب رگرسیونی در نظر گرفت، بنابراین عدد بزرگتر مقدار ویژه به معنای تاثیر بیشتر آن Variable بر PC است. به این نکته دقت کنید که نتیجهای که تب Loadings در تعلق Variable به PC به دست میدهد همانند نتایج تب Eigenvectors است.
به منظور درک نتایج این تب، بهتر است یکبار دیگر نتایج تب Eigenvector را ببینید. من در آنجا از یک مدل خطی رگرسیونی صحبت کردیم که در آن PCها، کمیت وابسته Dependent Variable (DV) و Eigenvectorها ضرایب مدل رگرسیونی بودند.
آنچه در این تب و در تصویر زیر مشاهده میکنید، در واقع همان DVهای برازش شده برای هر فرد، در مدل رگرسیونی است که ما به آن PC Score میگوییم. آنها را ببینید.
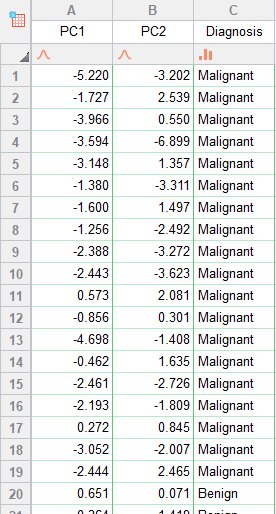
اعداد نوشته شده در ستونهای PC1 تا PC4، مقدار برازش شده به ازای هر مشاهده (37 مورد داشتیم) برای مدل رگرسیون خطی است که در آن Variableها همان Independent Variable (IV) هستند.
چنانچه علاقمند باشیم از نتایج این شیت میتوانیم در یک تحلیل رگرسیون چندگانه که در آن Aroma به عنوان کمیت وابسته و PCها به عنوان کمیتهای مستقل Independent Variable مطرح هستند، استفاده کرد.
به این ترتیب ما تا اینجا توانستیم به بیان و توضیح جداول و نتایج به دست آمده از رگرسیون مولفههای اصلی در شیت Results بپردازیم. همچنان به شما توصیه میکنم که جهت مشاهده توضیحات و جداول بیشتر به لینک (تحلیل مولفههای اصلی Principal Component Analysis (PCA)) مراجعه کنید. در آنجا میتوانید چیزهای بیشتری درباره تحلیل مولفههای اصلی ببینید و به دست بیاورید.
در ادامه کار به توضیح و مشاهده نمودارها و گرافهای نتیجه شده از PCR خواهیم پرداخت.
گرافهای رگرسیون مولفههای اصلی
Graphs
در یک تحلیل رگرسیون مولفه های اصلی Principal Component Regression با استفاده از نرمافزار Prism، گرافها و نمودارهای متنوعی به دست میآید. نرمافزار Prism در رگرسیون مولفه های اصلی PCR، چهار نمودار و گراف به نامهای زیر برای ما رسم میکند.
- Loadings
- PC scores
- Biplot
- Proportion of variance
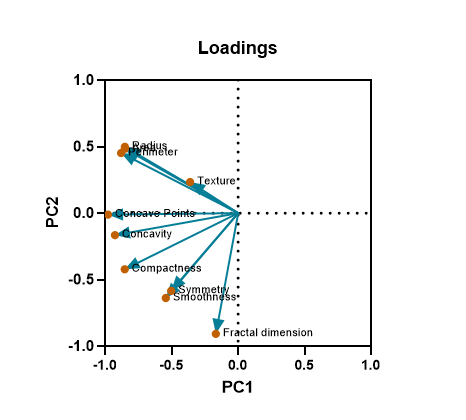
در ادامه دربارهی هر یک توضیح میدهیم. از گراف Loadings شروع میکنیم. به عنوان مثال در گراف زیر PC1 و PC2 آمده است. در تصویر زیر آن را ببینید.
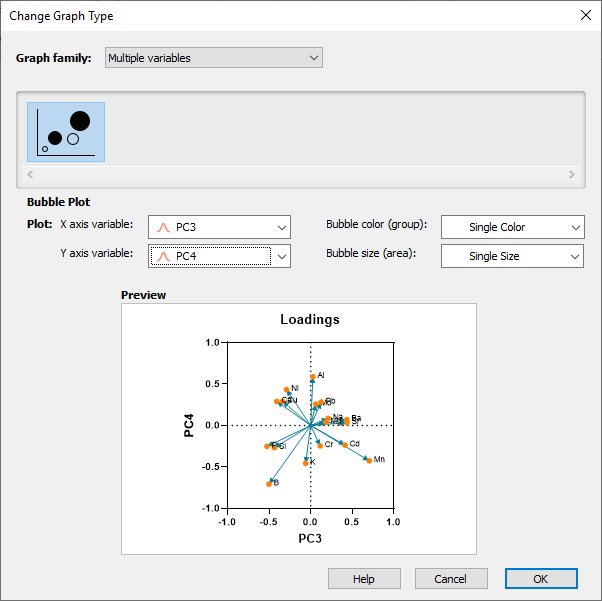
چنانچه علاقمند باشیم که گراف Loadings را بر روی PC های دیگری نیز به دست بیاوریم، کافی است از منوی Change در بالای گراف، گزینهی Choose a different type of graph را انتخاب کنیم. با این کار وارد پنجره Change Graph Type میشویم. در آنجا میتوانیم به دلخواه PC های خود را جهت رسم در نمودار Loadings قرار دهیم. تصویر زیر را ببینید.
برای فهم گرافهای Loadings بهتر است به شیت Results و تب Loadings بروید. در آنجا بیان کردیم که همبستگی بین هر کدام از Variableها با PCها به دست آمده است. در نمودارهای Loadings همبستگی هر Variable به صورت آرایه (x,y) که در آن x همبستگی کمیت با PC قرار گرفته در محور افقی و y همبستگی با PC قرار گرفته در محور عمودی است، گزارش میشود.
به عنوان مثال در گراف بالا برای عنصر Al آرایه (0.424 ,0.050) به دست آمده است. این آرایه نشان میدهد، Al با PC1، همبستگی به اندازه 0.050 و با PC2 همبستگی 0.424 واحد دارد.
در گراف Loadings میتوانید آرایههای همبستگی به ازای هر Variable را ببینید. دایرهها همان نقاط عددی همبستگی برای PC1 و PC2 هستند. خطوط نیز از مبدا مختصات و از نقطه (0 ,0) رسم شدهاند. قبلاً نیز بیان کردیم همبستگی کمیت با هر کدام از PCها که بیشتر باشد، به آن PC اختصاص داده میشود.
کاربرد دیگر گراف Loadings در این است که میتوانیم به رابطه بین Variableها با یکدیگر نیز پی ببریم. همانطور که در نمودار بالا نشان داده شده است، عناصر Ba، Sr و K به صورت خوشهای نزدیک به هم هستند که نشان میدهد آنها دارای همبستگی مثبت با یکدیگر هستند. در مقایسه، بردارهای Al و Si یا یکدیگر زاویه تقریباً قائم را تشکیل میدهند که نشان میدهد با یکدیگر همبستگی ندارند. با انتخاب گزینه Correlation matrix در تب Output تنظیمات نرمافزار و به دست آوردن ماتریس همبستگس بین عناصر، میتوانیم تایید کنیم که این فرضیات تا حد زیادی درست هستند.
گراف بعدی نرمافزار Prism، با نام PC Scores دیده میشود. در تصویر زیر آن را آوردهام. در اینجا نیز گراف به عنوان نمونه بر روی PC1 و PC2 رسم شده است.
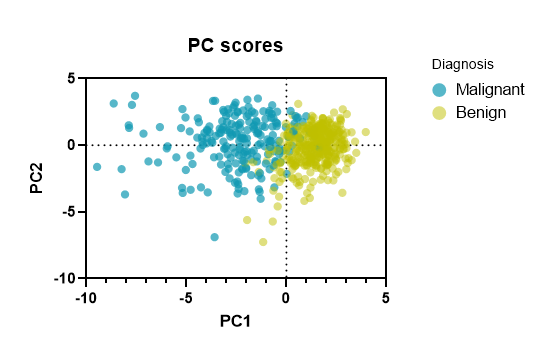
معمولاً گرافها در نرمافزار Prism، بیانگر نتایج به دست آمده و درکی شهودی از آنها هستند. گراف PC Scores نیز نتایج تب PC Scores در شیت نتایج را نشان میدهد. به منظور اختصار، میتوانید به توضیحات بیان شده در تب PC Scores مراجعه کنید.
در این گراف هر دایره یک فرد و ردیف در شیت دیتا را نشان میدهد. از گراف PC Score میتوانیم جهت شناسایی دادههای پرت یا غیرمعمول Outliers or Unusual، مطالعه نیز استفاده کنیم. در واقع دادههایی که دورتر از سایر افراد در گراف PC Score قرار میگیرند، به عنوان افرادی که حجم و درصد زیادی از واریانس را در بر میگیرند، گزارش میشوند. در تصویر بالا یکی از آنها را مشخص کردهام. چنانچه موس را بر روی دایرههای مشخص شده در بالا ببرید، میتوانید شماره ردیف آنها را در شیت دیتا مشاهده کنید.
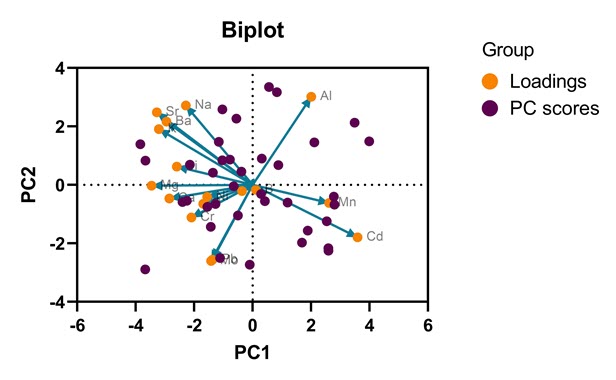
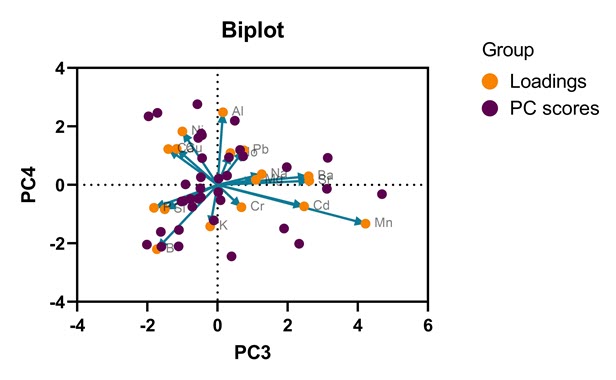
گراف بعدی رگرسیون مولفههای اصلی با نام Biplot شناخته میشود. در تصویر زیر آن را ببینید.

شاید بتوان گفت Biplot چیز جدیدی نیست و از ترکیب گرافهای بالا یعنی Loadings و PC scores به دست میآید. به هر حال اگر علاقمند بودید، آنها را در یک نمودار و کنار هم ببینید، میتوانید از Biplotها استفاده کنید.
باز هم به این نکته دقت کنید که با استفاده از منوی Change در بالای گراف و انتخاب گزینهی Choose a different type of graph میتوانیم به دلخواه PC های خود را جهت رسم در نمودار Biplot قرار دهیم. به عنوان مثال من در ادامه Biplot برای PC های 3 و 4 را رسم کردهام. تصویر زیر را ببینید.
در نهایت هنگام انجام تحلیل رگرسیون مولفه های اصلی PCR با نرمافزار Prism، گراف دیگری با نام Proportion of variance آمده است. این نمودار به واریانس توضیح داده شده توسط هر PC اشاره میکند. در تصویر زیر آن را میبینید.
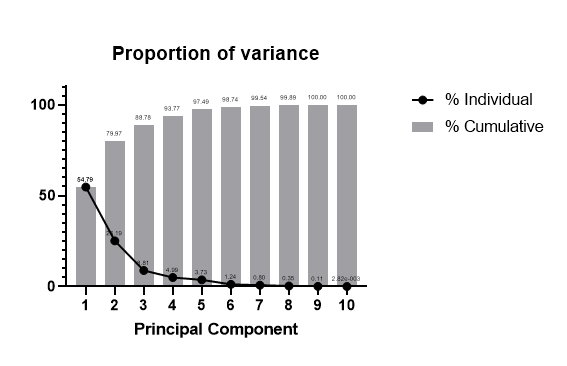
نتایج این گراف را میتوانید در تب Tabular results ببینید. در نمودار Proportion of variance، خط به معنای واریانس بیان شده توسط هر PC است. همواره این خط نزولی است و میتوان آن را شِمای دیگری از گراف Eigenvalues دانست. با افزایش تعداد PCها، واریانس بیان شده توسط هر کدام، کاهش مییابد. به همین دلیل ما معمولاً فقط سه یا چهار PC ابتدایی را انتخاب میکنیم.
همچنین در نمودار بالا، ستونها به معنای واریانس تجمعی توضیح داده شده توسط مولفههای اصلی هستند. به سادگی میدانیم روند آنها صعودی است و در انتها به عدد 100 میرسند. این گراف نشان میدهد PC1 تا PC4 روی هم، حدود 65 درصد پراکندگی و واریانس دادهها را توضیح میدهند که عدد مناسبی است.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2023). Principal Component Regression (PCR) in Prism software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/principal-component-regression-prism/.php
For example, if you viewed this guide on 12th January 2023, you would use the following reference
GraphPad Statistics (2023). Principal Component Regression (PCR) in Prism software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/principal-component-regression-prism/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.