
خوشه بندی Cluster K-Means با نرمافزار Minitab
از Cluster K-Means برای گروهبندی مشاهدات در خوشههایی که ویژگیهای مشترک دارند استفاده میشود. این روش هنگامی مناسب است که شما اطلاعات کافی برای تعیین تعداد خوشه های مورد نیاز خود داشته باشید.
به این نکته نیز توجه کنید که Cluster K-means از یک روش غیر سلسله مراتبی برای گروهبندی مشاهدات استفاده میکند. بنابراین، در فرآیند خوشهبندی، دو مشاهده ممکن است پس از به هم پیوستن و Join شدن، به خوشههای جداگانه تقسیم شوند.

در زمینه تحلیل خوشهای با استفاده از نرمافزار Minitab میتوانید مقاله خوشه بندی مشاهدات Cluster Observations و خوشهبندی کمیتها Cluster Variables را ببینید.
لازم به ذکر است که اگر میخواهید مشاهدات (سطرها) را گروهبندی کنید اما هیچ اطلاعات اولیهای دربارهی نحوه تشکیل گروهها ندارید، از Cluster Observations استفاده کنید. اگر میخواهید Variableها (ستنونها) را گروهبندی کنید، از Cluster Variables استفاده کنید.
در این آموزش به چگونگی انجام تحلیل خوشه بندی Cluster K-Means با استفاده از نرمافزار Minitab میپردازیم.
مثال آموزشی Cluster Observations
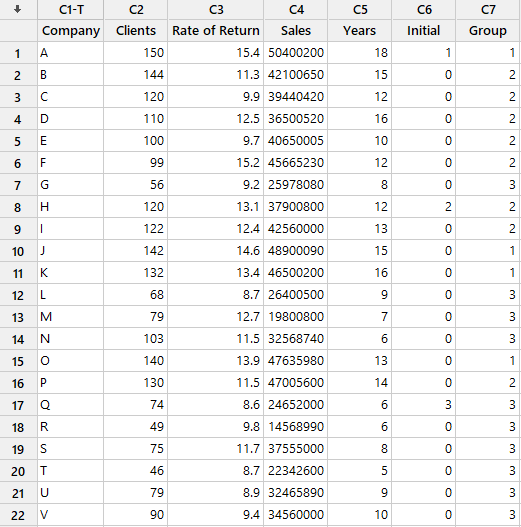
یک تحلیلگر تجاری میخواهد 22 شرکت تولیدی موفق کوچک تا متوسط را در گروههای مشابه، برای تحلیلهای آینده طبقهبندی کند. تحلیلگر دادههایی را در مورد تعداد مشتریان، نرخ بازده، فروش و سالهایی که شرکتها در تجارت بودهاند جمعآوری میکند. برای شروع فرآیند خوشه بندی، تحلیلگر قصد دارد شرکتها را به سه گروه اولیه تقسیم کند. تازه تأسیس شده، دارای رشد متوسط و شرکتهای جوان.
فایل داده و نتایج این آموزش را میتوانید از اینجا Cluster K-Means دریافت کنید. در تصویر زیر میتوانید دادهها را مشاهده کنید.
جهت خوشهبندی K-means، ابتدا از مسیر زیر در نرمافزار Minitab استفاده میکنیم.
Stat → Multivariate → Cluster K-Means
در این آموزش به تفکیک و با بیان جزئیات به شرح منوها و گزینههای نرمافزار Minitab جهت خوشهبندی K-Means میپردازیم.
تنظیمات نرمافزار Minitab
در پنجره باز شده با نام Cluster K-Means، کمیتهای Clients, Rate of Return, Sales, Years. را انتخاب و در کادر Variables قرار دهید.
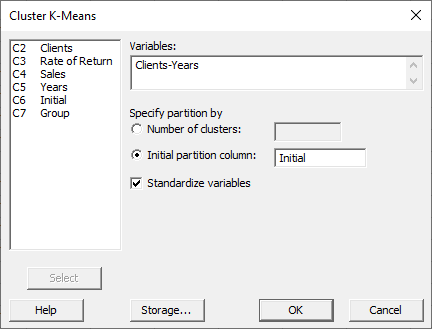
در بخش Specify partition by گزینهی Initial partition column را انتخاب کرده و Initial را در آن قرار میدهیم. این ستون بیانگر دیدگاه اولیه تحلیلگر در تقسیم شرکتها به گروههای تازه تأسیس شده، دارای رشد متوسط و شرکتهای جوان، است.
گزینه Standardize variables را نیز انتخاب میکنیم. این کار سبب میشود نرمافزار همه Variable ها و ستونها را هم مقیاس و هم وزن میکند. استانداردسازی در بیشتر موارد عمل خوبی است، به ویژه زمانی که کمیتها از مقیاسهای متفاوتی استفاده میکنند. فرض کنید کمیت A در مقیاس تومان از 0 تا 10،000،000 تومان است، و کمیت B نسبتی در مقیاس 0.0 تا 1.0 است. اگر Variable ها استاندارد نباشند، تحلیل خوشه بندی مشاهدات به دلیل مقادیر بزرگتر مقیاس کمیت A در مقایسه با B، وزن بسیار بیشتری بر A نسبت به B قرار میدهد. بنابراین بهتر است Variable ها استاندارد شوند.
چنانچه علاقمند باشیم که بدانیم هر شرکت در کدام خوشه قرار میگیرد، بر روی دکمه Storage بزنید تا وارد پنجره زیر با نام Cluster K-Means Storage شوید.
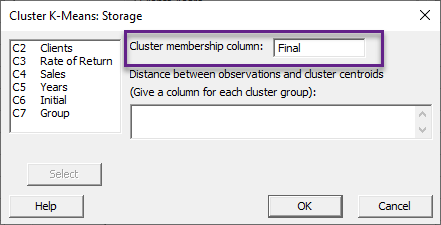
در آنجا و در کادر Cluster membership column نرمافزار از شما میخواهد، به دلخواه یک نام وارد کنید. به عنوان مثال من Final نوشتهام. این کار باعث میشود، یک ستون جدید در فایل دیتا با نام Final ساخته شود و در آن شمارههای 1، 2 و 3 که نشاندهنده تعلق هر فرد به خوشههای سه گانه است، قرار گیرد. این کار را انجام میدهیم و سپس OK میکنیم.
تحلیل نتایج مثال آموزشی خوشه بندی مشاهدات
هنگامی که تنظیمات نرمافزار را OK میکنید، نتایج زیر به دست میآید. ما در ادامه به بررسی آنها میپردازیم.
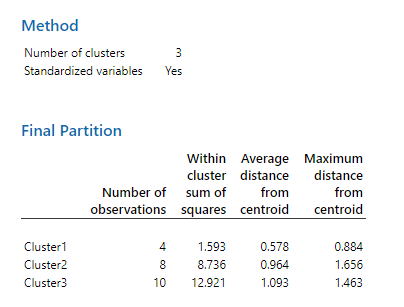
در ابتدا نرمافزار درباره تعداد خوشههای تشکیل شده و فعال بودن گزینه Standardize variables گزارش میدهد.
در جدول بالا با نام Final Partition اطلاعاتی درباره تعداد مشاهدات قرار گرفته در هر خوشه، مجموع مربعات، میانگین فاصله افراد از مرکز خوشه و بیشترین فاصله از مرکز خوشه، بیان شده است.
خوشه یک (شرکتهای تاسیس شده) دارای کمترین فاصله با یکدیگر در بین سه خوشه هستند. مقدار برای میانگین فاصله از مرکز (0.578) به دست آمده است. خوشه یک کمترین تعداد شرکتها نیز را دارد.
جدول Final Partition نشان میدهد، در خوشه 1، چهار شرکت تازه تاسیس شده، در خوشه 2، هشت شرکت با رشد متوسط و در خوشه 3، ده شرکت جوان قرار گرفتهاند.
در فایل دیتا، ستون Final که قبلاً از آن حرف زدیم، ایجاد شده است. در تصویر زیر آن را ببینید.
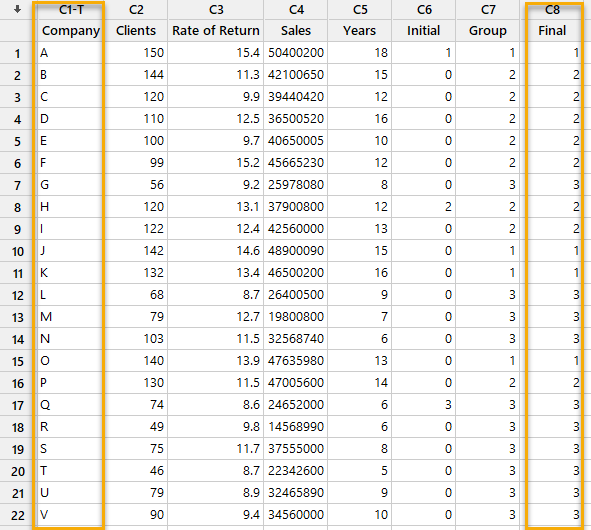
همانگونه که مشاهده میکنید، ستون Final با کدهای 1 تا 3، مشخص کرده است که هر شرکت در کدام خوشه قرار گرفته است.
نرمافزار Minitab نتایج بیشتری نیز برای ما ارایه کرده است. این نتایج در قالب جدولهای با نام Cluster Centroid و Distances Between Cluster Centroids میباشد. در ادامه آنها را ببینید.
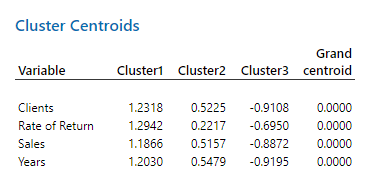
در جدول Cluster Centroid فاصله بین هر Variable با مرکز خوشه به دست آمده است. از آنجا که در تنظیمات نرمافزار، گزینه Standardize variables را انتخاب کردهایم اعداد بالا امکان منفی شدن نیز دارند. کمتر بودن فاصله (کوچک بودن عدد) به معنای تاثیر بیشتر Variable بر آن خوشه و بیشتر بودن فاصله (بزرگ بودن عدد) به معنای تاثیر کمتر Variable بر آن خوشه است.
به عنوان مثال برای Clients، فاصله بین این کمیت با مرکز خوشه 1 برابر با 1.23 است. فاصله آن با مرکز خوشه 2 برابر با 0.52 و با خوشه سه برابر با 0.91- میباشد. بنابراین نتیجه می شود که Clients بیشترین تاثیر را بر روی خوشه 2 و کمترین تاثیر را بر خوشه 1 دارد.
در ادامه نتایج جدول Distances Between Cluster Centroids را ببینید.
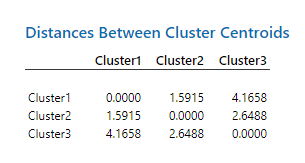
این جدول به بیان فاصله بین مرکز هر خوشه با خوشه دیگر میپردازد. واضح است که اعداد روی قطر صفر هستند. فاصله بیشتر به معنای تفاوت بیشتر بین خوشهها با یکدیگر میباشد. فاصله کمتر نیز بیانگر مشابهت و همانندی بیشتر خوشه با همدیگر است. به عنوان مثال خوشههای یک و دو مشابهت بیشتری نسبت به خوشههای یک و سه دارند.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Cluster K-Means using Minitab. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/k-means-minitab/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Cluster K-Means using Minitab. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/k-means-minitab/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.