خوشه بندی افراد و مشاهدات (Observations) با نرمافزار Minitab
هدف از خوشه بندی در این آموزش آن است که افراد و مشاهدات را در گروههای همانند دستهبندی کنیم، به گونهای که مشاهدات و سطرهای قرار گرفته در هر گروه، بیشترین شباهت و افراد گروههای مختلف، کمترین شباهت را با هم داشته باشند.
در این آموزش به چگونگی انجام تحلیل خوشه بندی مشاهدات Cluster Observations با استفاده از نرمافزار Minitab میپردازیم.

یک طراح برای یک شرکت لوازم ورزشی میخواهد یک دستکش دروازه بان فوتبال جدید را آزمایش کند. طراح دارای 20 ورزشکار است که دستکش جدید را پوشیده و اطلاعات جنسیت، قد، وزن و دست غالب (چپ دست یا راست دست) ورزشکاران را جمع آوری میکند.
طراح میخواهد ورزشکاران را بر اساس شباهت هایشان گروهبندی کند. به این نکته توجه کنید که ما میخواهیم بر روی افراد و سطرها خوشهبندی انجام دهیم، بنابراین از تحلیل Cluster Observation استفاده میکنیم.
فایل داده و نتایج این آموزش را میتوانید از اینجا Cluster Observations دریافت کنید. در تصویر زیر میتوانید دادهها را مشاهده کنید.
جهت خوشهبندی Observations، ابتدا از مسیر زیر در نرمافزار Minitab استفاده میکنیم.
Stat → Multivariate → Cluster Observations
در این آموزش به تفکیک و با بیان جزئیات به شرح منوها و گزینههای نرمافزار Minitab جهت خوشهبندی Observationها میپردازیم.
تنظیمات نرمافزار Minitab
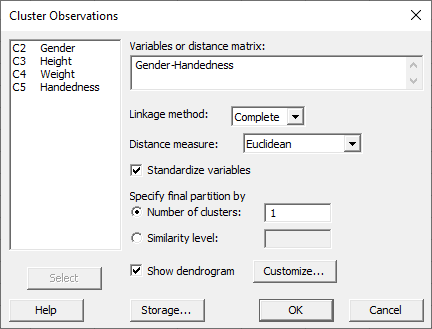
در پنجره باز شده، تمام کمیتها یعنی Gender، Height، Weight و Handedness را انتخاب و در کادر Variables or distance matrix قرار دهید.
Linkage method روش خوشهبندی افراد و نحوه قرار گرفتن در هر خوشه را مشخص میکند.
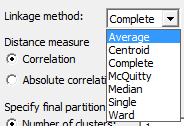
در جدول زیر به شرح گزینههای مختلف آن میپردازیم. گزینهها به نحوه تعریف فاصله بین دو خوشه اشاره میکنند.
| Average | Centroid | Complete | McQuitty | Median | Single | Ward |
| فاصله بین دو خوشه، میانگین فاصله بین یک سوال از یک خوشه، با سوال خوشه دیگر است. | فاصله بین دو خوشه، فاصله بین مرکز یا میانگین خوشهها است. | فاصله بین دو خوشه، ماکزیمم فاصله بین سوال در هر خوشه و سوال در خوشه دیگر. (روش دورترین همسایگی) | فاصله بین دو خوشه، نصف مجموع فاصله هر کدام از دو خوشه با خوشه سوم دیگر. | فاصله بین دو خوشه، میانه فاصله بین یک سوال از یک خوشه، با سوال خوشه دیگر است. | فاصله بین دو خوشه، مینیمم فاصله بین سوال در هر خوشه و سوال در خوشه دیگر. (روش نزدیکترین همسایگی) | فاصله بین دو خوشه، مجموع انحراف مربعات از نقاط مرکزی است. |
علاقمند بودید، جهت به دست آوردن فرمول هر کدام از روابط میتوانید به لینک https://support.minitab.com/en-us/minitab/18/help-and-how-to/modeling-statistics/multivariate/how-to/cluster-variables/methods-and-formulas/linkage-methods/ مراجعه کنید.
تنظیمات بخش Distance measure در Cluster Observations
در بخش Distance measure نحوه انتخاب اندازه فاصله بین افراد قرار دارد.
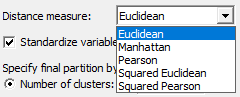
در اینجا معمولاً گزینه اقلیدسی Euclidean انتخاب میشود.
انتخاب دکمه Euclidean سبب میشود، فاصله بین دو فرد i و k از رابطه زیر به دست آید.
که در آن dik فاصله بین دو فرد و xij ما xkj اندازه عددی به دست آمده برای هر فرد میباشد.
چنانچه علاقمند هستید به منظور به دست آوردن بقیه فرمولها و روابط به لینک زیر مراجعه نمایید.
گزینه Standardize variables را نیز انتخاب میکنیم. این کار سبب میشود نرمافزار همه Variable ها و ستونها را هم مقیاس و هم وزن میکند. استانداردسازی در بیشتر موارد عمل خوبی است، به ویژه زمانی که کمیتها از مقیاسهای متفاوتی استفاده میکنند. فرض کنید کمیت A در مقیاس تومان از 0 تا 10،000،000 تومان است، و کمیت B نسبتی در مقیاس 0.0 تا 1.0 است. اگر Variable ها استاندارد نباشند، تحلیل خوشه بندی مشاهدات به دلیل مقادیر بزرگتر مقیاس کمیت A در مقایسه با B، وزن بسیار بیشتری بر A نسبت به B قرار میدهد. بنابراین بهتر است Variable ها استاندارد شوند.
تنظیمات بخش Specify final partition by
در بخش Specify final partition by معیارهای مورد نظر برای تعیین گروهبندی نهایی را مشخص کنید.

گزینه Number of clusters به ما این امکان را میدهد تا تعداد خوشههای نهایی Variableها را خودمان انتخاب کنیم. به عنوان مثال اگر پیشفرض عدد یک نرمافزار را بپذیریم، در این مثال همه افراد (20 نفر) در یک خوشه اصلی قرار میگیرند.
گزینه Similarity level به ما امکان انتخاب تعداد خوشهها را بر مبنای مشابهت و اصطلاحاً سطح همانندی بین Observationها میدهد. توجه کنید که Similarity level میتواند همانند یک Cut off در خوشه بندی مشاهدات عمل کند. در این زمینه در ادامه بیشتر توضیح خواهیم داد.
گزینه Show dendrogram در Cluster Variables
در انتهای تنظیمات خوشهبندی با نرمافزار Minitab گزینه Show dendrogram وجود دارد.
![]()
انتخاب این گزینه سبب طراحی یک گراف درختی مفید از نحوه و فرایند گام به گام خوشه بندی مشاهدات خواهد شد.
به منظور اعمال برخی اصلاحات دلخواه میتوانید با دکمه Customize کار کنید.
حل مثال آموزشی خوشه بندی مشاهدات (Observations)
حال بیایید به مثال مطرح شده در این نوشتار بپردازیم. همانگونه که در ابتدا بیان کردیم 24 Variable مربوط به خصوصیات و ویژگیهای فنی و ظاهری ماشین، از 750 فرد پرسیده شده است. میخواهیم این سوالات را در چند گروه خوشه بندی کنیم. مراحل زیر را گام به گام طی میکنیم.
1- فایل آموزشی Cluster Observations را در نرمافزار Minitab باز کنید.
2- از مسیر زیر در نرمافزار Minitab استفاده میکنیم.
Stat → Multivariate → Cluster Observations
3- تمام کمیتها را انتخاب و در کادر Variables or distance matrix قرار دهید.
4- از کادر Linkage method گزینه Complete را انتخاب کنید.
5- در بخش Distance measure گزینه Euclidean را برگزینید.
6- گزینه Standardize variables را انتخاب میکنیم.
7- فعلاً در این مرحله، تعداد 1 خوشه اصلی پیشفرض نرمافزار در بخش Number of clusters را بپذیرید.
8- گزینه Show dendrogram را به منظور نمایش گراف خوشه بندی سوالات انتخاب کنید.
حال OK کنید. نتایج زیر به دست میآید که در ادامه دربارهی آنها صحبت میکنیم.
تحلیل نتایج مثال آموزشی خوشه بندی مشاهدات
هنگامی که تنظیمات نرمافزار را OK میکنید، نتایج زیر به دست میآید. ما به بررسی آنها میپردازیم.
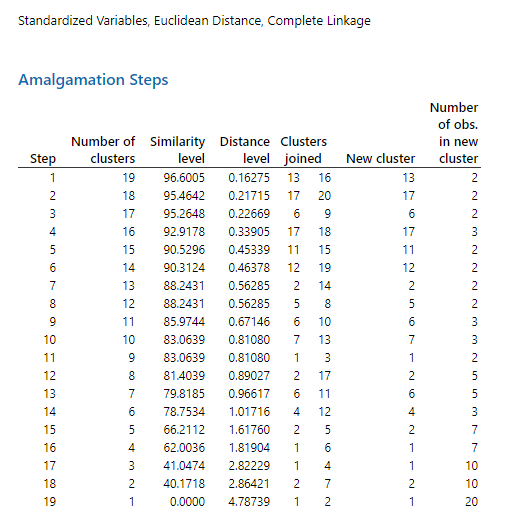
خط بعدی درباره گزینههای انتخاب شده Linkage method و Distance measure گزارش میدهد.
نتایج تحت عنوان جدولی به نام Amalgamation Steps بیان شده است. تفسیر آنها ساده و البته دقیق خواهد بود. در جدول زیر تفسیر نام ستونها را بیان کردهایم.
| Number of obs. in new cluster | New cluster | Clusters joined | Distance level | Similarity level | Number of clusters | Step |
| تعداد Variableهای موجود در خوشه ایجاد شده در هر گام. | خوشه جدید تشکیلشده در هر گام. این خوشه نماینده یکی از سوالات ترکیب شده با یکدیگر میباشد. | شماره Variableهایی که در هر گام با یکدیگر ترکیب شدهاند. | میزان سطح اختلاف خوشهها با یکدیگر در هرگام. با بیشتر شدن گامها این سطح افزایش مییابد. | میزان سطح تشابه خوشهها به یکدیگر در هر گام. با بیشتر شدن گامها این سطح کاهش مییابد. | تعداد خوشههای تشکیلشده در هر Step | شماره گام اجرای فرایند خوشه بندی سوالات. همواره برابر با تعداد Variableها منهای یک است. |
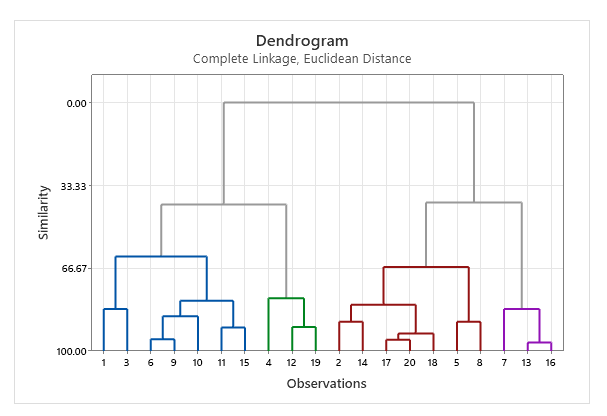
به عنوان مثال نتایج به دست آمده نشان میدهد در گام 1، مشاهدات شماره 16 و 13 با یکدیگر ترکیب شده و یک خوشه جدید به نمایندگی فرد شماره 13 را ساختهاند. در این صورت 19 خوشه وجود دارد (18 مشاهده به همراه یک خوشه شامل افراد شماره 16 و 13). Similarity level در این خوشهها برابر با 96.6 درصد و Distance level برابر با 0.1627 است.
فرایند خوشه بندی مشاهدات ادامه پیدا کرده است تا در نهایت، یک خوشه کلی از تمام افراد ساخته شده است.
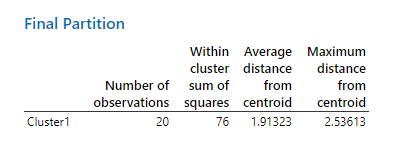
در جدول زیر با نام Final Partition اطلاعاتی درباره تعداد مشاهدات قرار گرفته در خوشه (20 فرد)، مجموع مربعات، میانگین فاصله افراد از مرکز خوشه و بیشترین فاصله از مرکز خوشه، بیان شده است. جدول Final Partition نشان میدهد، یک خوشه تشکیل شده است.
به همین ترتیب گراف Show dendrogram که نشاندهنده نحوه خوشه بندی مشاهدات Cluster Observations است، دیده میشود.
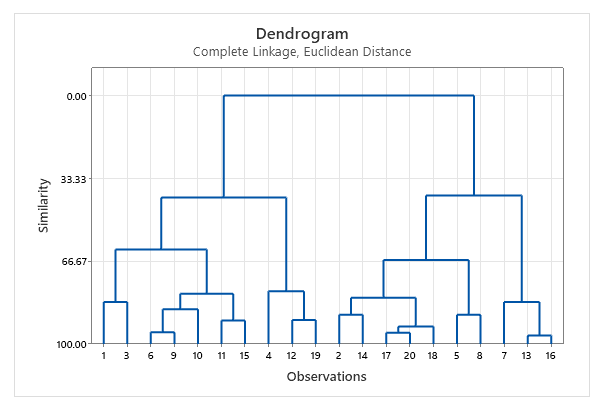
تشکیل تعداد خوشههای بیشتر در Cluster Variables
حال فرض کنید بخواهیم به جای ترکیب تمام افراد و Observationها در یک خوشه، آنها را در تعداد خوشههای بیشتری دستهبندی کنیم. برای انجام این کار در تنظیمات نرمافزار در بخش Number of clusters تعداد خوشهها را به عنوان مثال 3 انتخاب میکنیم.
در این صورت نتایج جدول Amalgamation Steps به دست آمده همانند قبل خواهد بود. اینبار جدول Final partition بیانگر نتایج برای سه خوشه خواهد بود. آن را ببینید.
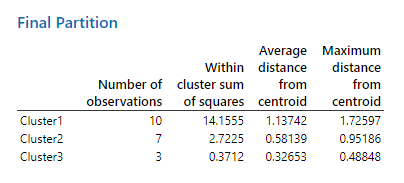
تعداد افراد در هر خوشه در جدول Final partition مشخص شده است. این جدول نشان میدهد 10 نفر در خوشه 1، 7 نفر در خوشه 2 و سه نفر در خوشه 3 قرار گرفتهاند.
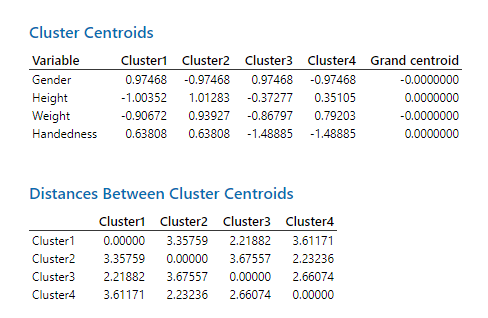
نرمافزار Minitab نتایج بیشتری نیز برای ما ارایه کرده است. این نتایج در قالب جدولهای با نام Cluster Centroid و Distances Between Cluster Centroids میباشد. در ادامه آنها را ببینید.
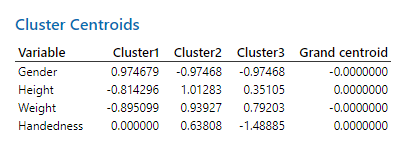
در جدول Cluster Centroid فاصله بین هر Variable با مرکز خوشه به دست آمده است. از آنجا که در تنظیمات نرمافزار، گزینه Standardize variables را انتخاب کردهایم اعداد بالا امکان منفی شدن نیز دارند. کمتر بودن فاصله (کوچک بودن عدد) به معنای تاثیر بیشتر Variable بر آن خوشه و بیشتر بودن فاصله (بزرگ بودن عدد) به معنای تاثیر کمتر Variable بر آن خوشه است.
به عنوان مثال برای Height، فاصله بین این کمیت با مرکز خوشه 1 برابر با 0.81- است. فاصله آن با مرکز خوشه 2 برابر با 1.01 و با خوشه سه برابر با 0.35 میباشد. بنابراین نتیجه می شود که Height بیشترین تاثیر را بر روی خوشه 3 و کمترین تاثیر را بر خوشه 2 دارد.
در ادامه نتایج جدول Distances Between Cluster Centroids را ببینید.
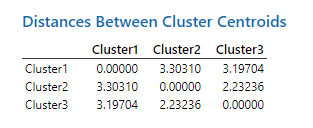
این جدول به بیان فاصله بین مرکز هر خوشه با خوشه دیگر میپردازد. واضح است که اعداد روی قطر صفر هستند. فاصله بیشتر به معنای تفاوت بیشتر بین خوشهها با یکدیگر میباشد.
به همین ترتیب در نهایت، Show dendrogram به دست آمده است. این گراف جایگاه سه خوشه و شماره افراد تشکیلدهنده آنها را نشان میدهد.
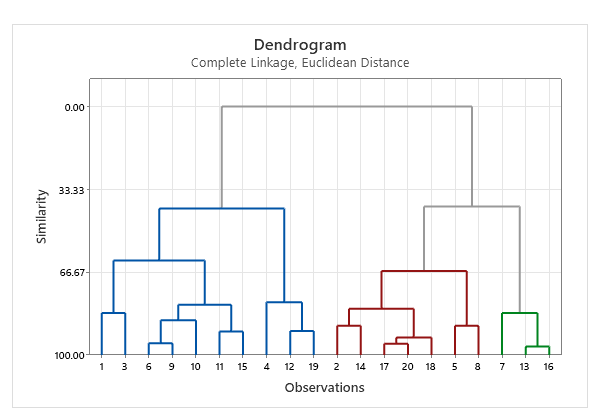
به عنوان مثال در dendrogram میتوان مشاهده کرد که افراد شماره 7، 13 و 16 در خوشه شماره 3 قرار گرفتهاند.
چنانچه علاقمند باشیم که بدانیم هر فرد و Observation در کدام خوشه قرار میگیرد، بار دیگر به تنظیمات نرمافزار و پنجره Cluster Observation باز گردید. در آنجا دکمه Storage وجود دارد.
بر روی این دکمه کلیک کنید تا وارد پنجره زیر با نام Cluster Observations Storage شوید.
در آنجا و در کادر Cluster membership column نرمافزار از شما میخواهد، به دلخواه نام یک ستون را وارد کنید تا شمارههای 1، 2 و 3 که نشاندهنده تعلق هر فرد به خوشههای سه گانه است، قرار گیرد. این کار را انجام میدهیم و سپس OK میکنیم.
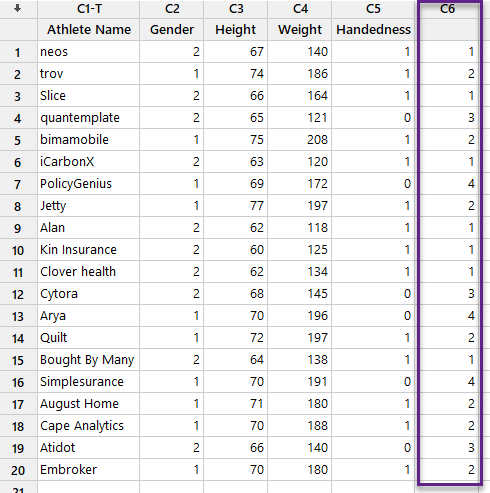
با انجام این کار یک ستون جدید با نام C6 در شیت دیتا ایجاد میشود. تصویر آن را در زیر ببینید.
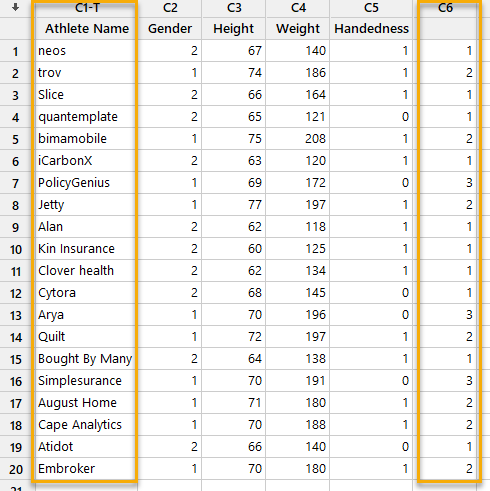
همانگونه که مشاهده میکنید، در یک ستون جدید و در مقابل نام هر فرد، شماره خوشهای که فرد در آن قرار گرفته است، نوشته شده است.
استفاده از گزینه Similarity level به عنوان Cut off
سطح تشابه و یا همان Similarity level در تحلیلهای خوشه بندی، میتواند به عنوان Cut off کمک کند که دریابیم چه تعداد خوشه در تحلیل خود داشته باشیم.
برای این منظور لازم است، یکبار نتایج را همانند مرحله اول همین مثال با یک خوشه به دست آوریم.
توجه به مقدار Similarity level که در کدام مرحله به یکباره و نسبت به گامهای دیگر، کاهش مییابد، کمک خواهد کرد آن مقدار سطح تشابه را به عنوان Cut off در تنظیمات و در مقابل کادر Similarity level وارد کنیم.
در نتایج خوشه بندی به دست آمده در مرحله اول این مثال مشاهده میشود که در گام شماره 17 مقدار Similarity level، نسبت به گامهای دیگر کاهش بیشتری دارد. سطح تشابه در این Step برابر با 41.05 درصد به دست آمده است.
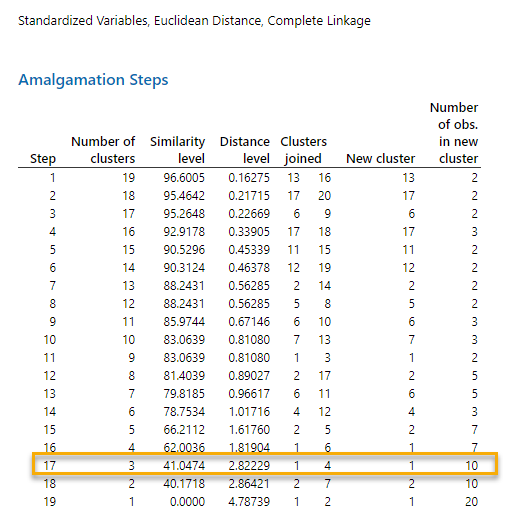
در واقع هنگامی که تعداد خوشهها از 4 به 3 میشود، سطح تشابه بیش از 20 درصد کاهش مییابد (از 62.0036 به 41.0474). بنابراین نتیجه میشود تعداد خوشههای مورد نیاز و معقول در این مطالعه، چهار خوشه است.
برای این منظور در تنظیمات نرمافزار مقدار 42 را در برابر کادر Similarity level وارد میکنیم. این مطلب به معنای آن است که ما از نرمافزار میخواهیم سطح تشابه را حداقل برابر با 42 درصد در نظر بگیرید. بنابراین Similarity level به عنوان یک نقطه برش Cut off عمل میکند و همانگونه که در بالا دیدید، تعداد چهار خوشه برای ما به دست میدهد.
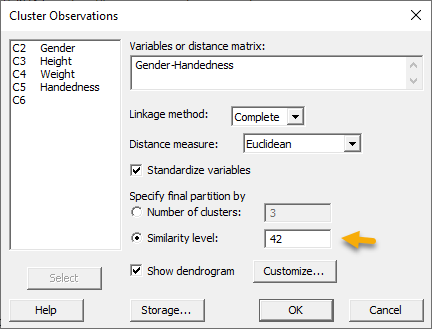
با OK کردن نتایج جدید در Final partition مشاهده میشود.
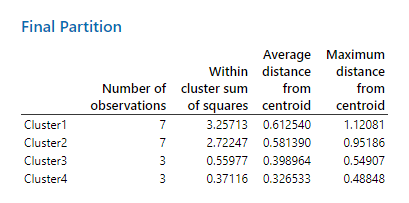
همانگونه که دیده میشود چنانچه مقدار 42 درصد را به عنوان Cut off در نظر بگیریم، تعداد چهار خوشه برای این مثال به دست میآید. بر این مبنا در خوشه 1 و 2 تعداد هفت نفر و در خوشههای سه و چهار تعداد 3 نفر قرار میگیرند.
پاسخ به این سوال که هر فرد در کدام خوشه قرار میگیرد، با استفاده از گزینه Storage و کادر Cluster membership column که در متنهای بالاتر به آن اشاره کردیم، امکان پذیر است. در تصویر زیر میتوانید مشاهده کنید. هر فرد مشخص شده است که در کدام خوشه قرار میگیرد.
به همین ترتیب میتوانید جدولهای Cluster Centroid و Distances Between Cluster Centroids که این بار بر مبنای چهار خوشه ایجاد شده است را ببینید.
گراف Show dendrogram در این نحوه تحلیل جدید نیز خوشههای تشکیل شده را نشان میدهد.
بنابراین با استفاده از نرمافزار Minitab به سادگی میتوانیم به خوشه بندی مشاهدات Cluster Observations بپردازیم.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Cluster Observations using Minitab. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/cluster-observations-minitab/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Cluster Observations using Minitab. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/cluster-observations-minitab/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.