نرمال کردن داده ها در نرم افزار SPSS
توزیع نرمال
Normal Distribution
مهمترین توزیع آماری با نام توزیع نرمال Normal Distribution نامیده میشود. اهمیت این توزیع تا بدان حد است که پیشفرض انجام بسیاری از تحلیلهای آماری نرمال بودن دادهها، دانسته میشود.

به عنوان مثال معمولاَ هنگامی میتوان از انواع تحلیلها و آزمونهای مقایسه پارامتری استفاده کرد که دادهها دارای توزیع نرمال باشند.
هدف ما در این نوشتار این است که روش و فرایندی جهت نرمال کردن دادهها و تبدیل دادههای غیرنرمال به دادههای نرمال به دست بیاوریم. ابزار کار ما در این متن، نرمافزار SPSS خواهد بود.
مثال
فایل مثال با نام Normal-Distribution.sav را میتوانید از اینجا دانلود کنید.
در این مثال از ۱۵۰ نفر، وزن آنها سوال شده است. یک بررسی ساده با استفاده از آزمون کلوموگروف-اسمیرنف نشان میدهد، دادهها فاقد توزیع نرمال هستند (P-value = 0.024) در گراف زیر نیز میتوانید هیستوگرام و منحنی نرمال یا همان Normal Curve دادهها را مشاهده کنید.
همانگونه که در گراف هم میتوانید مشاهده کنید میانگین و انحراف معیار وزن افراد به ترتیب برابر با ۷۳.۸۹ و ۱۰.۹۳۹ کیلوگرم به دست آمده است. این اعداد را به خاطر بسپارید.
نرمال کردن داده ها
Rank Cases
جهت انجام فرایند نرمال کردن دادهها، ابتدا دادهها را رتبهبندی میکنیم.
این کار با استفاده از مسیر زیر در نرمافزار SPSS انجام میشود.
Transform → Rank Cases
در این مسیر پنجره Rank Cases به صورت زیر برای ما باز خواهد شد. ما در این پنجره، کمیت و ستونی را که میخواهیم رتبه بندی کنیم، در کادر Variable(s) قرار میدهیم. بقیه تنظیمات را به صورت پیشفرض میپذیریم و بر روی دکمه Rank Types کلیک میکنیم.
با کلیک کردن بر روی دکمه Rank Types پنجره زیر برای ما باز میشود.
در این پنجره گزینههای Rank و Fractional rank را انتخاب میکنیم. با انجام این کار دو ستون جدید در فایل دادهها ساخته میشود. یک ستون رتبه هر سطر در بین سایر اعداد را برای ما نشان میدهد و ستون دیگر رتبه کسری هر دیتا را بیان میکند. در ادامه و به هنگام مشاهده خروجیها و نتایج به دست آمده، بیشتر درباره آنها صحبت خواهیم کرد.
حال Continue و سپس OK کنید. در فایل دیتا دو ستون جدید با نامهای Rweight و RFR001 ساخته میشود.
ستون Rweight به دلیل انتخاب گزینه Rank در پنجره Rank Cases Types ایجاد شده است. در این ستون، رتبه وزن هر فرد در مقایسه با سایر افراد آمده است. فردی که دارای کمترین وزن است، رتبه یک و به همین ترتیب با افزایش وزن، رتبه فرد نیز افزایش پیدا میکند. بالاترین رتبه یعنی ۱۵۰ نیز مربوط به فردی است که بیشترین وزن را دارد.
ستون RFR001 به دلیل انتخاب گزینه Fractional rank در پنجره Rank Cases Types ایجاد شده است. در این ستون، رتبه کسری هر فرد آمده است. به عنوان مثال فردی که دارای کمترین وزن است و رتبه آن در ستون Rweight برابر با یک است، رتبه کسری آن و عدد ستون RFR001 آن برابر با ۰.۰۰۶۷ شده است. این عدد حاصل تقسیم یک بر تعداد نمونه یعنی ۱۵۰ است. در واقع عدد ستون Rweight برای هر فرد از تقسیم رتبه هر فرد در ستون Rweight بر تعداد نمونه یعنی ۱۵۰ به دست میآید.
به این ترتیب برای هر فرد رتبه و رتبه کسری آن به دست میآید. این فرایند که نام آن را در SPSS با نام Rank Cases میشناسیم، مرحله ابتدایی تبدیل دادهها به دادههای نرمال شده است.
در ادامه کار بعدی که با استفاده از Compute Variable نرم افزار انجام میشود را پی میگیریم.
نرمال کردن داده ها
Compute Variable
در ادامه کار می بایست با استفاده از اعداد ستون RFR001، دادههای وزن که غیرنرمال بود را به دادههای نرمال تبدیل کنیم.
جهت انجام این کار با استفاده از مسیر زیر وارد پنجره Compute Variable میشویم.
Transform → Compute Variable
در این پنجره مراحل زیر را پی میگیریم.
۱
در ابتدا و در کادر Target Variable برای ستونی که میخواهیم دادههای نرمال شده در آن قرار بگیرند، یک نام قرار میدهیم.
۲
حال به کادر Function group میرویم و در آنجا گزینه Inverse DF را پیدا و روی آن کلیک میکنیم.
۳
در کادر Functions and Special Variables گزینه Idf.Normal را پیدا و انتخاب میکنیم. با استفاده از نشانگر قرار داده شده، این گزینه را به کادر Numeric Expression انتقال میدهیم.
۴
در کادر Numeric Expression عبارت (?,?,?) IDF.NORMAL ظاهر میشود. در پنجره Compute Variable درباره این عبارت توضیح داده شده است.
آنچه که از توضیحات برمیآید این است که ما میبایست به جای علامت سوالها به ترتیب احتمال، میانگین و انحراف معیار دادهها را قرار دهیم. تشخیص میانگین و انحراف معیار که ساده است. آنها را در نمودار هیستوگرام بالا مشاهده کردیم که به ترتیب برابر با ۷۳.۸۹ و ۱۰.۹۳۹ کیلوگرم به دست آمده بود.
اما به جای علامت سوال اول و prob که مخفف probability است، چه چیزی قرار دهیم؟ پاسخ این است که همان ستون RFR001 که بیانگر رتبه کسری هر فرد و در واقع همان احتمال تجمعی است را قرار میدهیم. بنابراین به صورت زیر پنجره Compute Variable را خواهیم داشت.
با OK کردن در فایل دادهها، ستونی با نام NormalWeight ساخته میشود.
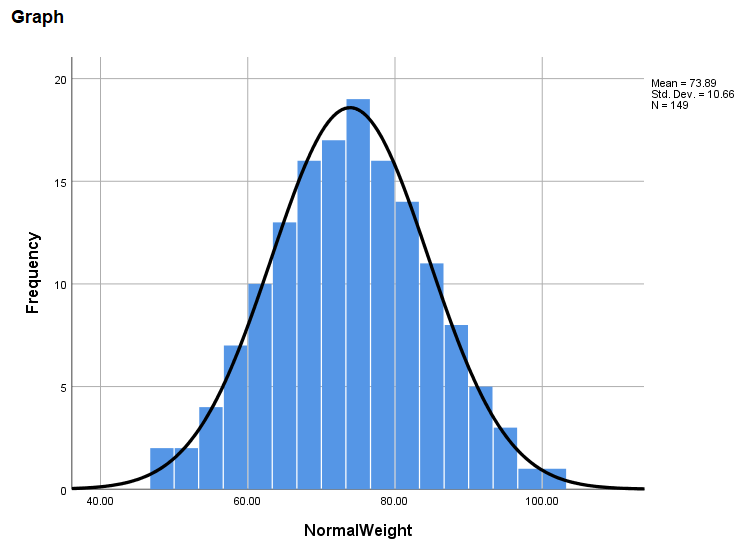
ابتدا بیایید آمارههای توصیفی ستون NormalWeight که دادههای نرمال شده وزن در آن قرار دارند را به دست بیاوریم. یک بررسی ساده نشان میدهد میانگین این دادهها کاملاَ همانند دادههای وزن در حالت غیرنرمال یعنی برابر با ۷۳.۸۹ است. انحراف معیار دادهها نیز تقریباَ مشابه و برابر با ۱۰.۶۶ به دست آمده است.
حال بیایید بر روی این دادهها یعنی همان ستون NormalWeight آزمون کلوموگروف-اسمیرنف را انجام دهیم. انتظار داریم این آزمون بیانکننده نرمال بودن دادههای به دست آمده باشد.
استفاده از آزمون کلوموگروف-اسمیرنف نشان میدهد دادههای ستون NormalWeight دارای توزیع نرمال هستند (P-value > 0.200) در گراف زیر نیز میتوانید هیستوگرام و منحنی نرمال دادههای این ستون را مشاهده کنید.
به وضوح همانگونه که میتوانید مشاهده کنید، هیستوگرام دادهها بیانگر نرمال بودن آنها است.
به این ترتیب ما توانستیم فرایندی را طراحی و اجرا کنیم که با استفاده از آن دادههای غیرنرمال به دادههای نرمال تبدیل شود و همچنین آمارههای توصیفی آن مانند میانگین و انحراف معیار ثابت بمانند.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2021). Normalize data in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/transform-data-to-normal-distribution/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2021). Normalize data in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/transform-data-to-normal-distribution/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.