ضریب تطابق کندال Kendall’s coefficient of concordance (W)
ضریب تطابق کندال معیاری است که از رتبهها برای ارزیابی توافق بین افراد استفاده میکند (کندال و بابینگتون اسمیت 1939). هدف از کاربرد کندال W تعیین میزان توافق بین ارزیابان مختلف است. ضریب تطابق کندال (W) عددی بین 0 تا 1 است. عدد یک به معنای وجود توافق کامل بین ارزیابان و عدد صفر بیانگر عدم تطابق بین آنها میباشد.

به عنوان مثال فرض کنید از 5 نفر میخواهیم که 7 نوع نوشیدنی با طعمهای مختلف را رتبهبندی کنند. واضح است که ما میخواهیم بدانیم کدام طعم نوشیدنی بهترین است. با این حال آیا میتوانیم بررسی کنیم که افراد چقدر با یکدیگر موافق هستند؟ Kendall’s W دقیقاً این کار را انجام میدهد.
به عنوان یک مثال دیگر چنانچه به هشت نفر، شش فیلم سینمایی داده شود و سپس از این افراد بخواهیم نظر خود را دربارهی میزان مطلوب بودن فیلمهای سینمایی به صورت رتبههایی از 1 تا 6 ارایه دهند، میتوانیم با استفاده از ضریب تطابق کندال به بررسی میزان توافق افراد با یکدیگر بپردازیم.
مثال ضریب تطابق کندال
Example
همان مثال نوشیدنی با طعمهای مختلف را در نظر بگیرید. در تصویر زیر میتوانید دادهها را مشاهده کنید. فایل این مثال را از اینجا Kendall’s W دریافت کنید.

در دادههای بالا اسامی پنج ارزیاب آمده است. هر کدام از آنها با رتبههای 1 تا 7 نظر خود را دربارهی مطلوب بودن طعم نوشیدنی بیان کردهاند. عدد 1 به معنای کمترین مطلوبیت و عدد 7 بیشترین مطلوبیت است.
همانگونه که مشاهده میکنید هفت نوع نوشیدنی با طعمهای مختلف، هر یک در یک ستون جداگانه آمده است.
برای پاسخ به اینکه کدام نوشیدنی بهترین طعم و رتبه را دارد، آزمون فریدمن Friedman مناسب است زیرا اعداد ما کمیتهای ترتیبی است. اما سوال بعدی که در این مقاله میخواهیم به آن بپردازیم این است که
به چه میران داورها در مورد رتبهبندی طعمهای مختلف نوشیدنی توافق دارند؟
برای پاسخ به این سوال از تحلیل ناپارامتری ضریب تطابق کندال Kendall’s coefficient of concordance (W) میتوانیم استفاده کنیم.
جهت انجام این تحلیل، دو مسیر و رویه جداگانه در نرمافزار SPSS وجود دارد. من در ادامه هر یک را توضیح میدهم.

Analyze → Nonparametric Tests → Legacy Dialogs → K Related Samples
با استفاده از مسیر بالا، پنجره زیر با نام Test for Several Related Samples برای ما باز میشود.
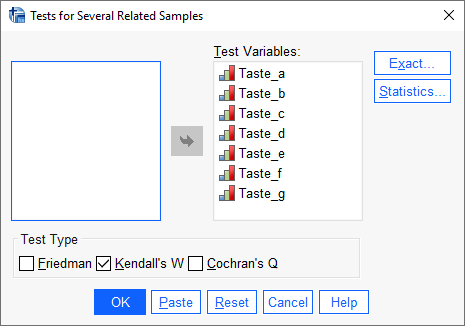
در این پنجره که مربوط به تنظیمات آزمونهای ناپارامتری چند نمونه وابسته در نرمافزار SPSS است، دادههای طعمهای مختلف نوشیدنی در کادر Test Variables قرار میگیرند. در کادر Test Type نیز گزینه Kendall’s W انتخاب شده است.
چنانچه علاقمند باشیم برخی از آمارههای توصیفی نیز برای ما ارایه شود، میتوانیم از دکمه ![]() وارد پنجره زیر شویم و گزینههای Descriptive و Quartiles را انتخاب کنیم.
وارد پنجره زیر شویم و گزینههای Descriptive و Quartiles را انتخاب کنیم.
خب، حال OK کنید و در ادامه نتایج و خروجیهای نرمافزار SPSS که با استفاده از مسیر بالا به انجام تحلیل ضریب تطابق کندال پرداختیم را مشاهده کنید.
نتایج آزمون Kendall’s (W)
Results
در پنجره Output میتوانید خروجیهای آزمون ناپارامتری Kendall’s (W) را ببینید.
در ابتدای نتایج، جدول Descriptive Statistics آمده است. در تصویر زیر آن را میبینید.
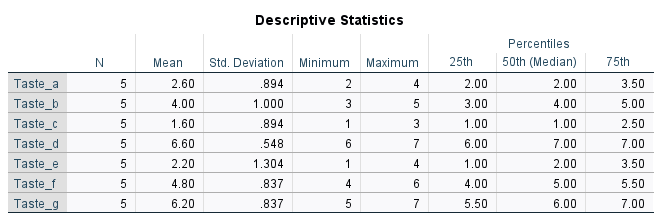
آمارههای توصیفی این جدول به تفکیک دادههای طعمهای مختلف نوشیدنی به دست آمده است. به عنوان مثال جدول بالا نشان میدهد میانگین و انحراف مطلوبیت برای طعم a برابر با 2.60 و 0.89 است.
جدول بعدی در خروجیهای نرمافزار، با نام Ranks Table قرار دارد. در تصویر زیر آن را ببینید.
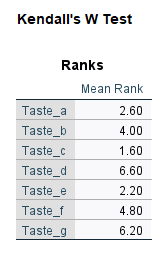
جدول بالا که از آن با نام جدول رتبهها Ranks Table یاد میشود، میانگین رتبه Mean Rank را برای هر کدام از طعمهای نوشیدنی نشان میدهد.
شاید برای شما این سوال پیش بیاید که منظور از رتبهها و میانگین آنها چیست؟
من پاسخ به این سوال را به صورت کامل در کتاب روشهای پیشرفته آماری و کاربردهای آن دادهام. علاقمند بودید به فصل دهم این کتاب مراجعه کنید.
با استفاده از نتایج این جدول میتوانیم بگوییم کدام طعم دارای بیشترین مطلوبیت (طعم d با میانگین رتبه 6.6) و کدام طعم نوشیدنی دارای کمترین مطلوبیت (طعم c با میانگین رتبه 1.6) است.
در نهایت در خروجیهای نرمافزار جدول دیگری با نام Test Statistics دیده میشود.

در این جدول میتوانیم به فرضیه وجود توافق و تطابق در بین داوران پاسخ دهیم.
نتیجه جدول بالا (در سطح معناداری پنج درصد) بیانگر اندازه توافق بالا بین ارزیابان در نمره دادن به مطلوبیت طعمهای مختلف نوشیدنیها است (Kendall’s W = 0.829, P-value < 0.001) این نتیجه معنادار به دست آمده است.
خب، حال بیایید از مسیر دیگری به بیان تحلیل ناپارامتری ضریب تطابق کندال (W) بپردازیم. این مسیر در ورژنهای جدید نرمافزار SPSS قرار داده شده است و به نظر دارای نتایج و خروجیهای بیشتری است.

Analyze → Nonparametric Tests → Related Samples
هنگامی که از مسیر بالا جهت انجام آزمونهای ناپارامتری در نمونههای وابسته استفاده میکنیم، پنجره زیر با نام Nonparametric Tests Two or More Related Samples برای ما باز میشود. در تصویر زیر آن را ببینید.
ما با استفاده از این مسیر و پنجره تنظیمات بالا، نه فقط میتوانیم آزمون تطابق کندال را انجام دهیم، بلکه قادر هستیم که آزمونهای ناپارامتری دارای بیشتر از دو گروه وابسته را نیز انجام دهیم. در ادامه به توضیح هر کدام از بخشها و تبهای این پنجره میپردازیم.
در این تب دو گزینه وجود دارد. انتخاب هر کدام به شما اجازه میدهد که هدف از آزمون ناپارامتری خود را مشخص کنید.
- Automatically compare observed data to hypothesized
با انتخاب این گزینه به نرمافزار اجازه میدهیم، بر مبنای نوع دادهها و تعداد گروههای وابسته، آزمون مناسب را انتخاب کند. بر این مبنا نرمافزار، آزمونهای McNemar’s, Cochran’s Q, Wilcoxon matched-pair Signed-Rank و Friedman’s 2-way ANOVA را انجام میدهد. معمولاً به صورت پیشفرض همین گزینه را میپذیریم.
- Customize analysis
هنگامی که میخواهید تنظیمات آزمون را به صورت دستی در تب Settings اصلاح کنید، این گزینه را انتخاب کنید. انتخاب این گزینه به شما امکان میدهد تا کنترل دقیقی بر آزمونهای انجام شده و گزینههای آنها داشته باشید. سایر آزمونهای ناپارامتری موجود در برگه تنظیمات عبارتند از Sign test، Marginal Homogeneity، و یک فاصله اطمینان (براورد Hodges-Lehmann) نیز برای نمونههای با دو گروه موجود است. همه این موارد را میتوانید در تب Settings مشاهده کنید.
Fieldsبا استفاده از گزینههای این تب، کمیتهای وابسته را وارد نرمافزار میکنیم.
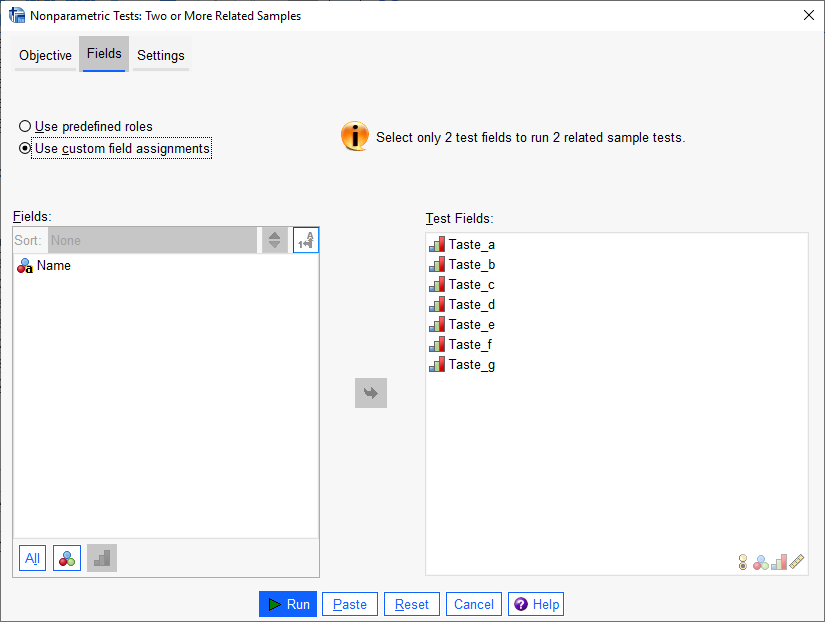
در کادر Test Fields ستونها و دادههای رتبهدهی به هر طعم نوشیدنی ، قرار میگیرد.
Settingsدر این تب میتوانیم انواع آزمونهای ناپارامتری قابل انجام برای نمونههای وابسته را مشاهده کنیم. هنگامی که در تب Objective گزینه Automatically compare observed data to hypothesized را انتخاب میکنیم، در تب Settings نیز به صورت پیشفرض گزینه Automatically choose the tests based on the data فعال است.
همانگونه که قبلاً نیز گفتیم، انتخاب این گزینه سبب میشود که نرمافزار به صورت خودکار و بر مبنای نوع و تعداد گروههای وابسته، آزمون آماری ناپارامتری مناسب دادهها را برای ما انجام دهد.
با این حال انتخاب گزینه Customize tests باعث میشود، به دلخواه بتوانیم آزمون ناپارامتری مورد علاقه خود را انجام دهیم. در تصویر زیر این آزمونها را ببینید.
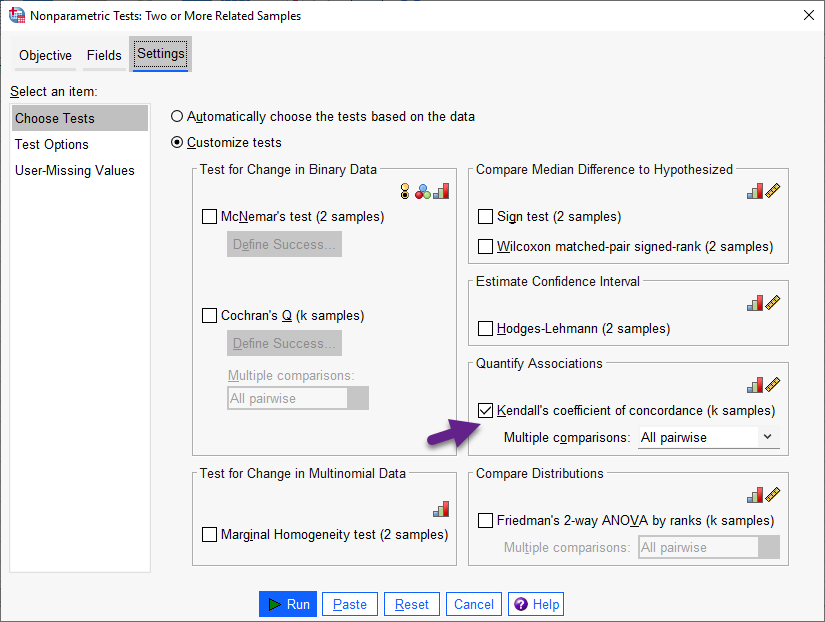
در تصویر بالا، من Kendall’s coefficient of concordance (k samples) را مشخص و انتخاب کردهام. در این مسیر میتوانیم با استفاده از گزینه Multiple comparisons به مقایسههای متعدد گروههای وابسته با یکدیگر بپردازیم. هنگامی که Run میکنیم نتایج زیر به دست میآید.
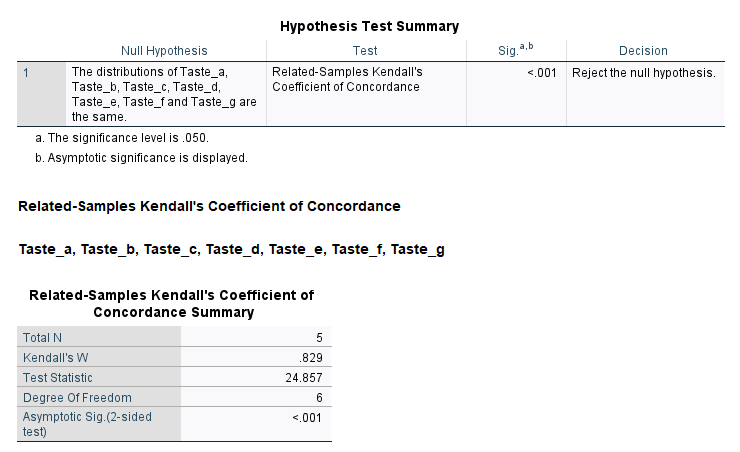
فرض صفر در این آزمون همانند بودن توزیع رتبهها در هر کدام از طعمهای نوشیدنی است. نتیجه به دست آمده بیانگر تطابق زیاد و معنادار بین ارزیابان است (Kendall’s W = 0.829, P-value < 0.001).
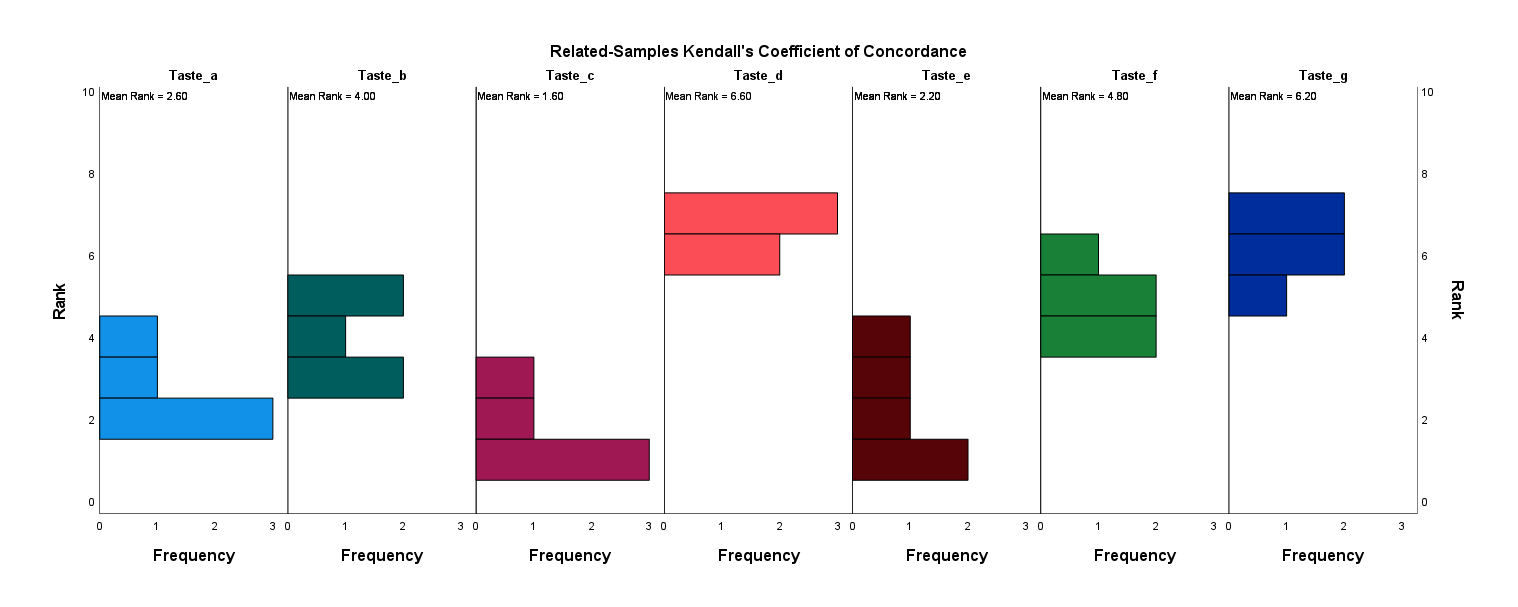
در گراف زیر نمودار فراوانی رتبهها به ازای هر کدام از طعمهای نوشیدنی، به دست آمده است.
همانگونه که در گراف بالا دیده میشود بیشترین رتبه مربوط به طعم d و کمترین رتبه به طعم c اختصاص دارد.
در ادامه با استفاده از جدول Pairwise Comparisons به مقایسه دو به دو رتبه طعمهای مختلف نوشیدنی با یکدیگر میپردازیم.
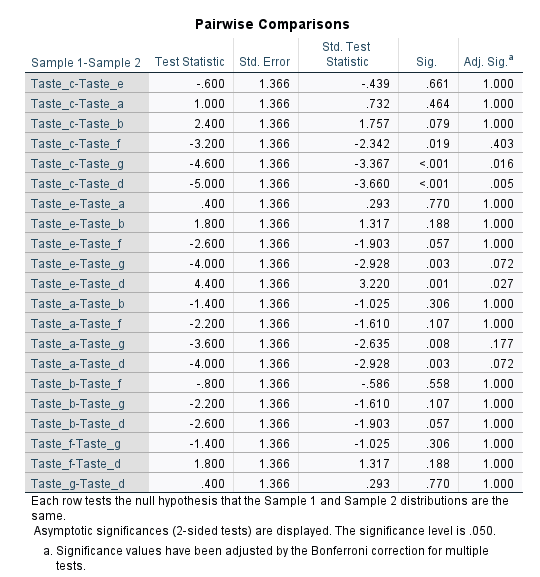
این جدول همانند Post Hoc در آنالیز واریانس یک طرفه رفتار میکند و به مقایسه دو به دو هر کدام از طعمها با یکدیگر میپردازد. همانگونه که در زیر جدول نوشته شده است، فرض صفر در هر آزمون همانند بودن توزیع دادهها در بین دو طعم نوشیدنی است.
نتیجه آزمون در دو ستون Sig که همان مقدار احتمال معناداری مجانبی دوطرفه با سطح 0.05 درصد و دیگری ستون Adj Sig است، گزارش شده است. در ستون Adj Sig مقادیر معناداری توسط تصحیح بونفرونی برای آزمونهای چندگانه Bonferroni correction for multiple tests تنظیم شده است.
تصحیح بونفرونی برای کاهش شانس به دست آوردن نتایج مثبت کاذب (خطای نوع I) یعنی رد فرض صفر در صورتی که فرض صفر درست است، استفاده میشود. این کار به ویژه هنگامی که تعداد مقایسههای دوگانه زیاد است، توصیه میشود.
نحوه به دست آوردن عدد مقدار احتمال P value برای ستون Adj Sig نیز ساده است و از حاصلضرب عدد ستون Sig در تعداد آزمونهای دوگانه (در این مثال 21 آزمون) به دست میآید. در مواردی نیز که عدد حاصلضرب بیشتر از 1 میشود، همان عدد یک گزارش می شود (احتمال بزرگتر از یک که نداریم!) در این زمینه به توضیحات بیشتری علاقمند بودید این لینک را ببینید.
نرمافزار SPSS بر مبنای نتایج جدول Pairwise Comparisons و ستون Adj Sig گراف زیر را برای ما رسم میکند.
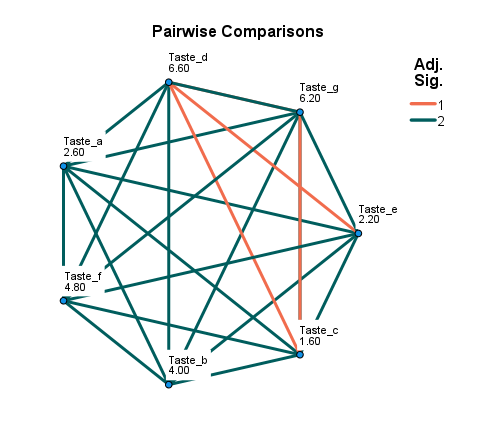
گراف به دست آمده به خوبی، مقایسههای معنادار و غیرمعنادار را به ما نشان میدهد. به عنوان مثال این گراف نشان میدهد رتبه مطلوبیت نوشیدنی با طعم d با طعمهای c و e اختلاف معنادار دارد. همچنین نوشیدنی طعم g نیز دارای اختلاف معنادار با طعم c است. به این نکته هم دقت کنید که اعداد نوشته شده در زیر عنوان هر طعم نوشیدنی، همان میانگین رتبه Mean Rank برای سیکل میباشد.
در همان تب Settings و از بخش Test Options میتوانیم به دلخواه خود سطح معناداری و فواصل اطمینان را قرار دهیم. نرمافزار SPSS به صورت پیشفرض این اعداد را به ترتیب 0.05 و 95.0 درصد قرار داده است.

چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2023). Kendall’s coefficient of concordance (W) in SPSS Software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/spss-kendalls-concordance-coefficient-w/.php
For example, if you viewed this guide on 12th January 2023, you would use the following reference
GraphPad Statistics (2023). Kendall’s coefficient of concordance (W) in SPSS Software. Statistical tutorials and software guides. Retrieved January, 12, 2023, from https://graphpad.ir/spss-kendalls-concordance-coefficient-w/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.