رگرسیون لجستیک ساده Simple Logistic Regression با گراف پد
یکی از تحلیلهایی که در ورژنهای جدید گراف پد (8 به بعد) قرار گرفته است، مدلهای رگرسیون لجستیک Logistic Regression است.
همانگونه که میدانیم وقتی Variable پاسخ ما یعنی Y دو حالتی باشد (بله یا خیر، موفقیت یا شکست، رخداد یا عدم رخداد) و بخواهیم بین پاسخ با Variableهای مستقل یعنی Xها ارتباط و مدلبندی ایجاد کنیم، از مدلهای رگرسیون غیرخطی با نام لجستیک استفاده میکنیم.
در زمینه تئوریهای رگرسیون لجستیک، بحثهای زیادی وجود دارد. شما را به خواندن و مطالعه این لینک در سایت گراف پد توصیه میکنم.
در مثال زیر با استفاده از نرمافزار گراف پد پریسم، به ارایه و انجام تحلیل رگرسیون لجستیک، پرداختهایم. مطالعه ما در این بخش کاربردی و آموزش کار با نرمافزار و به دست آوردن براورد پارامترهای مدل است.
این مثال با نام Simple logistic regression در دسته تحلیلهای XY و در بخش Correlation & regression linear and nonlinear قرار دارد. فایل مثال را میتوانید از اینجا دانلود کنید.
وقتی مثال را Create میکنیم با دادههای زیر روبهرو میشویم. همانگونه که مشاهده میکنید دادهها در دو ستون یکی X که بیانگر تعداد ساعات مطالعه دانشآموز جهت آزمون و دیگری Y که نشاندهنده قبولی یا عدم قبولی در آزمون است، قرار گرفتهاند. در این مثال یافتههای مربوط به 125 دانشآموز آمده است.

همانگونه که بالاتر نیز اشاره کردیم، هنگامی که کمیت پاسخ ما به صورت دو حالتی باشد، از مدلهای رگرسیون لجستیک استفاده میکنیم. در این مثال نیز Y به حالتهای یک، یعنی قبولی در آزمون و صفر به معنای رد شدن در آزمون، کدبندی شده است.
نکتهای که در این زمینه نرم افزار گراف پد به آن اشاره میکند (در پنجره سبزرنگ Note نیز نوشته شده است.) این است که کدهای کمیت Y به صورت 0 و 1 نوشته شود. کد 1 به معنای مثبت و رخداد و کد 0 به معنای منفی و عدم رخداد، بیان شود.
بنابراین آنچه که در رگرسیون لجستیک به دنبال آن هستیم این است که احتمال 1 شدن و یا همان رخداد را پیشبینی کنیم. به اختصار احتمال رخداد را با p نشان میدهیم. البته این p با مقدار احتمال P value که سطح معناداری و پذیرش یا رد فرض صفر را نشان میدهد، کاملاً متفاوت است.
به نسبت p/1-p نسبت (شکست/پیروزی) یا (منفی/مثبت) نیز گفته میشود. یک توضیح تئوری کوچک اینکه در مدل رگرسیون لجستیک، لگاریتم این نسبت با Xها رابطه خطی دارد، یعنی
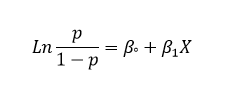
اگر طرفین معادله بالا را نمایی کنیم، به روابط زیر میرسیم.
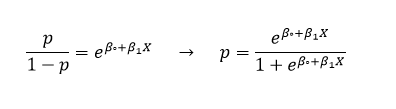
به این ترتیب میتوانیم مقدار p یا همان احتمال رخداد پیشامد مورد نظر را به دست بیاوریم.
خُب، حال به مثال خود بپردازیم. هدف ما در این مثال، به دست آوردن و پیشبینی احتمال قبولی دانشآموزان بر مبنای تعداد ساعات مطالعه است. این کار با استفاده از Logistic Regression قابل انجام است.
در واقع در این مثال ما یک Y و تنها یک X داریم. به همین دلیل به آن Simple Logistic Regression گفته میشود. اگر تعداد Xها و کمیتهای مستقل مطالعه بیشتر از یک بود، آنگاه مطالعه ما Multiple Logistic Regression نامیده میشد.
جهت انجام رگرسیون لجستیک، در شیت دادهها که با نام Study Data نامیده میشود، بر روی منوی Analyze کلیک کنید تا پنجره Analyze Data به صورت زیر برای ما باز شود.

در آنجا و از کادر XY analyses گزینه Simple logistic regression را انتخاب میکنیم. پنجره Parameters Simple Logistic Regression به صورت زیر برای ما باز میشود.
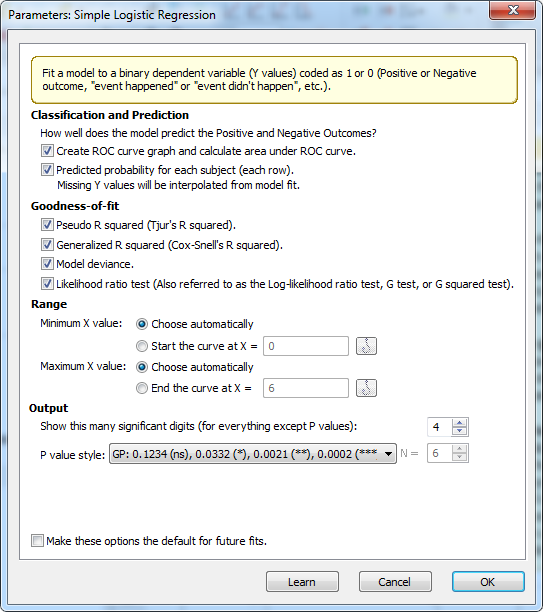
البته میتوانستیم در همان شیت دادهها به صورت مستقیم وارد پنجره Parameters Simple Logistic Regression نیز شویم. برای اینکار در بالای منوی Analyze بر روی ابزارک Fit a simple logistic regression model کلیک میکنیم.
- Classification and prediction
با انتخاب گزینههای این بخش منحنی راک ROC Curve و سطح زیر این منحنی برای ما محاسبه شده و به دست میآید. در زمینه منحنی راک میتوانید این لینک را در سایت گراف پد ببینید.
همچنین پیشبینی احتمال رخداد، به ازای هر سطر با استفاده از مدل رگرسیون لجستیک به دست آمده، بیان خواهد شد. به این مفهوم که انتظار داریم هر فرد مطالعه با چه احتمالی در آزمون موفق باشد.
- Goodness-of-fit
به هر حال هر مدل رگرسیونی چه خطی و چه غیرخطی نیاز به ارزیابی و بررسی مناسبت مدل دارد. در این بخش با استفاده از آمارههای موجود در نرم افزار گراف پد، به بررسی مدل لجستیک به دست آمده، میپردازیم.
- Range
چنانچه علاقمند باشیم که Xها از اندازه خاصی تا مقدار خاصی در مطالعه قرار گیرند، تنظیمات این بخش را انتخاب میکنیم. به صورت پیشفرض نرم افزار گراف پد، انتخاب خاصی از کمترین و بیشترین X ندارد و همه آنها را در مطالعه قرار میدهد.
- Output
تعداد رقمهای اعشار مقدار احتمال P value و نحوه و قالب نمایش آن، در این بخش قابل انجام است.
با OK کردن، شیت جدید با نام Simple logistic regression of Study Data در فولدر Results پنجره راهبری سمت چپ نرمافزار، ساخته میشود. این شیت دارای دو زبانه با نامهای Tabular results و Row prediction است.
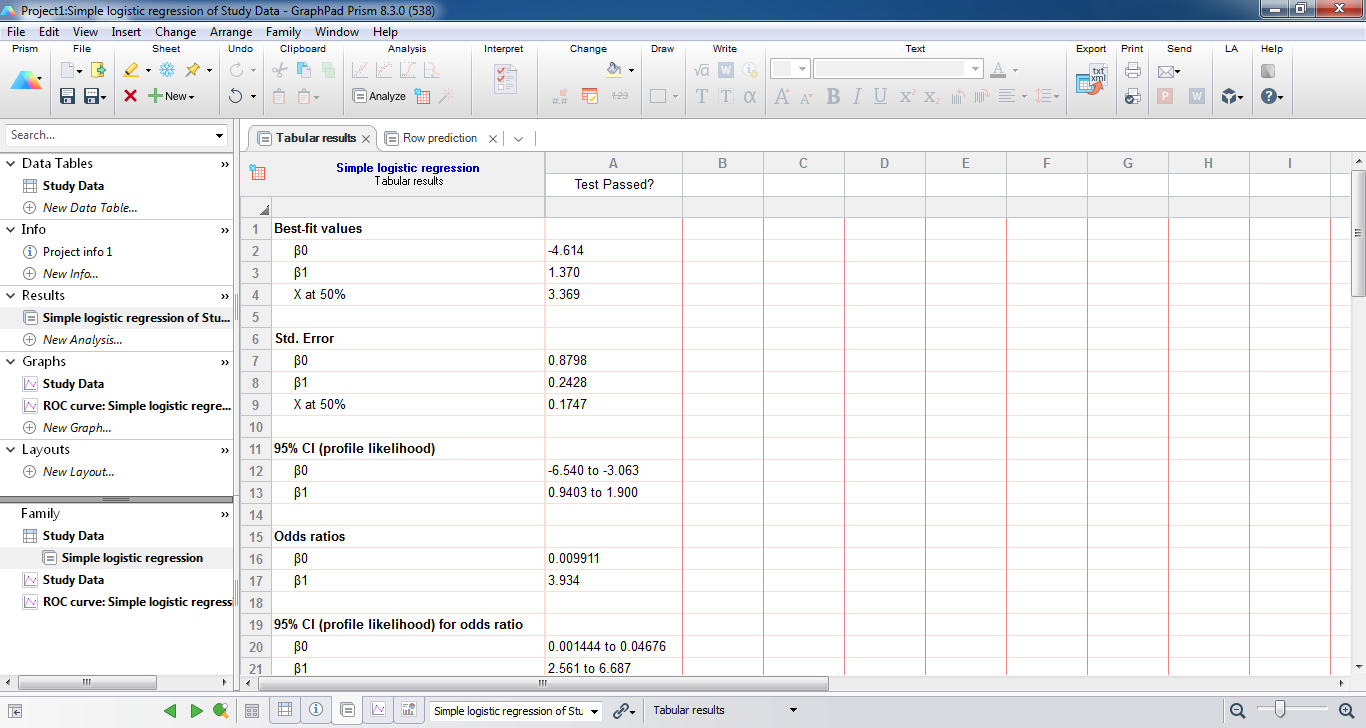
در ادامه به توضیح بخشهای مختلف شیت Tabular results میپردازیم.
- Best-fit values
این بخش مهمترین نتایج تحلیل رگرسیون لجستیک را شامل میشود. پارامترهای β0 و β1 مدل در این بخش قرار گرفته است. مثبت شدن β1 بیانگر وجود ارتباط مستقیم بین تعداد ساعات مطالعه و قبولی در آزمون، میباشد.

با استفاده از اعداد به دست آمده برای همین پارامترها، میتوان احتمال موفقیت در آزمون برای هر فرد را محاسبه کرد. به این ترتیب مدل رگرسیون لجستیک مثال ما به صورت زیر خواهد بود.
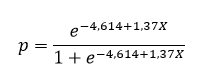
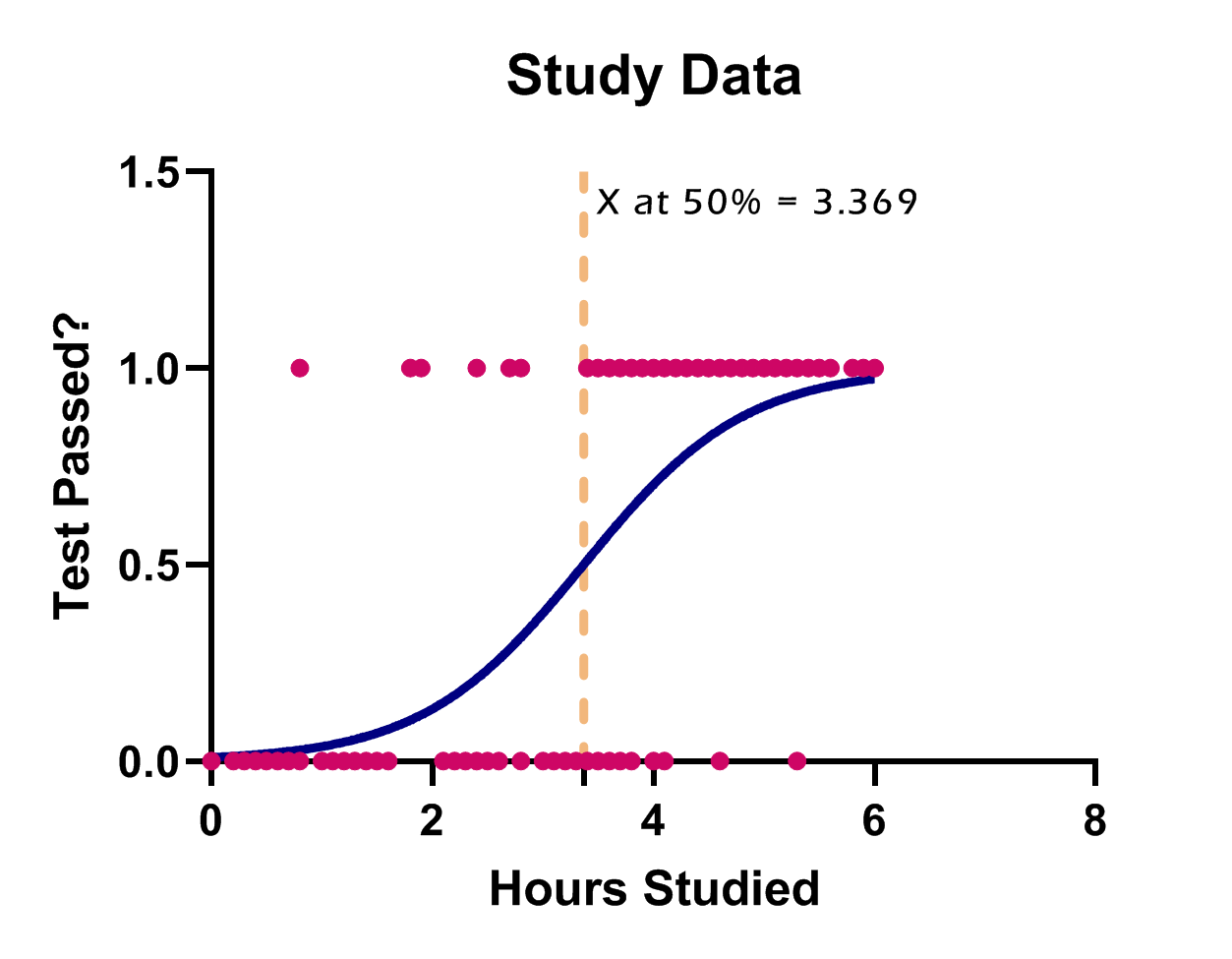
در این بخش نتیجه دیگری با نام X at 50% آمده است. این آماره بیانگر مقدار Xای است که برای آن احتمال رخداد 50 درصد، به دست میآید. به عبارت دیگر در این مثال یعنی چند ساعت مطالعه کنیم تا احتمال قبولی ما در آزمون برابر با 50 درصد باشد؟ پاسخ برابر با 3.369 ساعت خواهد بود.
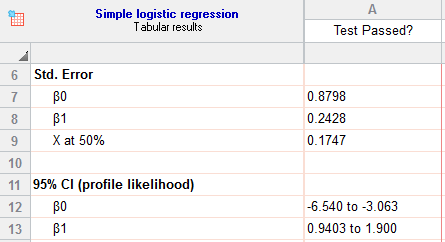
- Std. Error & 95% CI
انحراف معیار خطا به ازای هر کدام از پارامترهای مدل رگرسیون لجستیک در این بخش از تحلیل قابل مشاهده است. همچنین میتوانید فواصل اطمینان 95 درصد برای پارامترهای β0 و β1 مدل را ببینید.
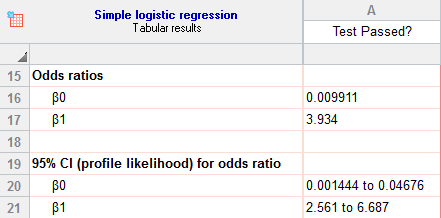
- Odds ratios & 95% CI
نسبت بخت و یا همان Odds Ratio که به اختصار به آن OR نیز گفته میشود، از مهمترین نتایج تحلیل رگرسیون لجستیک به حساب میآید. در جدول زیر نسبت بختها به همراه فواصل اطمینان 95 درصد آنها بیان شده است.
آنچه که اهمیت فراوان دارد نسبت بخت برای پارامتر β1 است. این نسبت به صورت زیر به دست میآید.
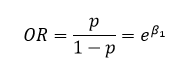
به معنای دیگر، نسبت بخت به صورت نسبت موفقیت به شکست، تعبیر میشود. عدد آن نیز به صورت نمایی شده پارامتر β1 به دست میآید.
خُب، حال بیایید در این مثال به توضیح آن بپردازیم. عدد 3.934 به دست آمده برای OR نشان میدهد که اگر تعداد ساعات مطالعه یک ساعت افزایش یابد احتمال موفقیت در آزمون 3.9 برابر افزایش مییابد. فاصله اطمینان به دست آمده نیز در هر دو کران پایین و بالای خود از عدد یک بیشتر شده است. این مطلب تا همین جا به معنای معنادار بودن تاثیر مثبت ساعات مطالعه بر روی قبولی در آزمون است.
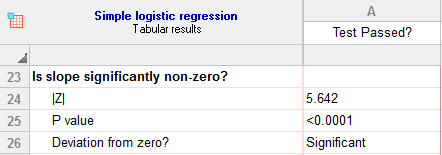
- Is slope significantly non-zero
پاسخ به این سوال که آیا شیب مدل و یا همان β1 به دست آمده، معنادار است یا خیر، در این بخش قرار دارد. مقدار احتمال به دست آمده بیانگر رد فرضیه عدم معناداری و صفر بودن شیب رگرسیونی است. بنابراین آنچه که پذیرفته میشود غیرصفر بودن و معنادار بودن β1 است. به عبارت دیگر میپذیریم که تعداد ساعات مطالعه بر روی قبولی یا رد در آزمون، موثر است.
- Likelihood ratio test
در هر مدل رگرسیونی چه خطی و چه غیرخطی، نیاز به ابزار و آزمونی برای بررسی معنادار بودن مدل هستیم. در مدل رگرسیون غیرخطی لجستیک از آزمونی با نام نسبت درستنمایی و یا همان Likelihood ratio جهت ارزیابی مدل استفاده میکنیم. P value <0.001 به دست آمده فرض صفر یعنی عدم معناداری مدل را رد کرده و نشان میدهد، مدل به دست آمده مناسب و معنادار است.

- Area under the ROC Curve
چنانچه خاطرتان باشد در پنجره Parameters Simple Logistic Regression و به هنگام تنظیمات مدل، گزینه Classification and prediction را جهت رسم منحنی راک فعال کردیم. در جدول زیر اندازه AUC و مساحت زیر منحنی ROC امده است. در زمینه منحنی راک میتوانید این لینک را در سایت گراف پد ببینید.
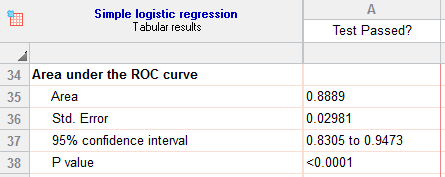
عدد حدود 0.89 برای Area نشان میدهد مدل لجستیک به دست آمده میتواند تا 89 درصد موارد را به درستی پیشبینی کند. مقدار احتمال P value <0.001 به دست آمده، نشاندهنده این است که مدل لجستیک توانایی مناسبی جهت تشخیص قبولی و یا رد در بین افراد مورد بررسی را دارا است.
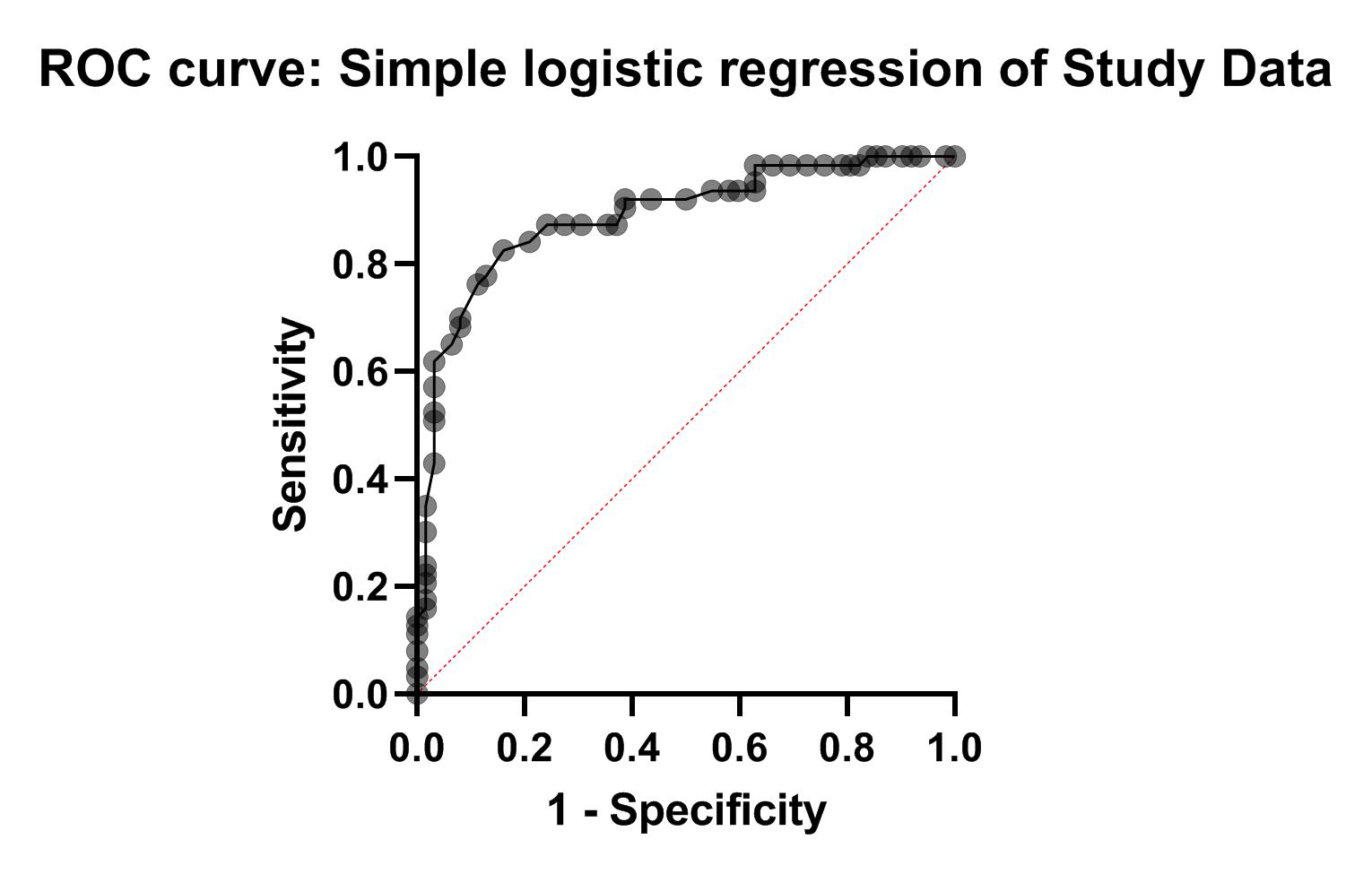
در شکل زیر منحنی راک ROC Curve این مثال که در شیت با نام ROC curve: Simple logistic regression of Study Data در فولدر Graphs پنجره راهبری نرمافزار قرار دارد، آمده است.
- Goodness of Fit & Equation
آمارههای سنجش خوب بودن مدل و یا اصطلاحاً نیکویی برازش Goodness of Fit در این بخش آمده است.

همچنین میتواند مدل رگرسیون لجستیک را که به صورت زیر است، مشاهده کنید. (البته ما فرمول این مدل را در همان ابتدای نتایج و در بخش Best-fit values بیان کردیم.
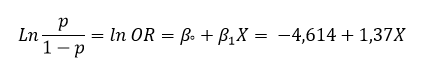
همانگونه که قبلاً نیز بیان کردیم این معادله نشان میدهد افزایش یا کاهش X و یا همان تعداد ساعات مطالعه به چه میزان بر روی موفقیت در آزمون اثرگذار است. (یک ساعت مطالعه بیشتر، احتمال موفقیت در آزمون را 3.9 برابر افزایش میدهد.
- Data summary
در این بخش خلاصهای از دادههای مثال رگرسیون لجستیک را مشاهده میکنید. جدول زیر بیان میکند که 125 سطر (فرد) مورد بررسی قرار گرفته است. داده گمشده Missing data که شامل افراد دارای عدم پاسخ است، در این مثال دیده نمیشود. 63 فرد کد 1 یعنی قبولی در آزمون و 62 نفر در آزمون رد شدهاند.
تعداد دو پارامتر یعنی همان β0 و β1 نیز براورد شده است. نسبت تعداد افراد به پارامترها یعنی 125/2 برابر با 62.5 و نسبت تعداد افراد قبول و تعداد افراد رد شده در آزمون به تعداد پارامترهای براورد شده به ترتیب برابر با 31.5 و 31 است.

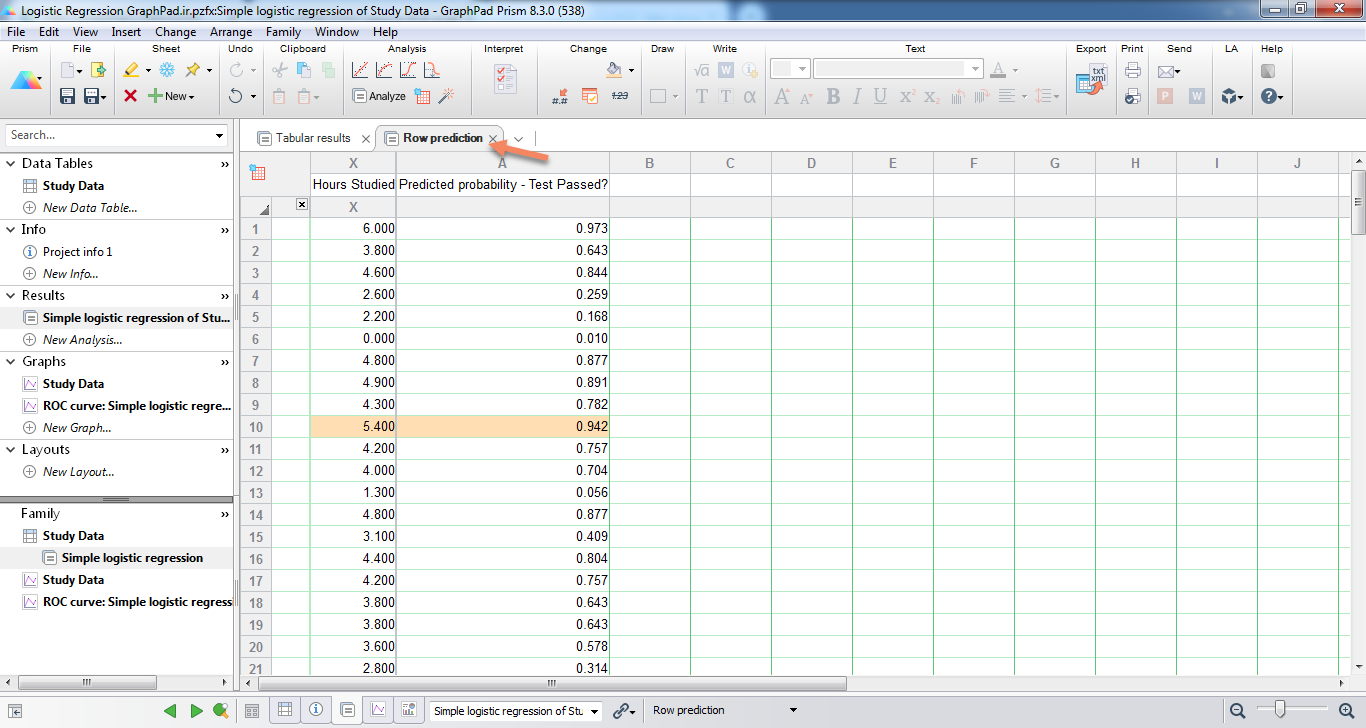
شیت نتایج، یک زبانه دیگر با نام Row prediction دارد. در این زبانه به ازای هر فرد (125 نفر) و تعداد ساعت مطالعه آنها، احتمال قبولی در آزمون براساس مدل رگرسیون لجستیک به دست آمده، محاسبه شده است. به عنوان مثال برای فردی که تعداد ساعت مطالعه او 5.4 بوده است، احتمال موفقیت در آزمون برابر با 94.2 درصد به دست آمده است. به همین ترتیب برای بقیه افراد نیز میتوان بر مبنای مدل لجستیک، احتمال موفقیت را به دست آورد.
خُب، آنچه در این مثال همچنان باقی مانده است، مشاهده و رسم گرافهای متناظر با تحلیل رگرسیون لجستیک میباشد. در فولدر Graphs پنجره سمت چپ میتوان عناوین دو شیت با نامهای Study Data و ROC curve: Simple logistic regression of Study Data را مشاهده کرد.
در بالا و به هنگام بیان نتایج سطح زیر منحنی راک از گراف ROC curve: Simple logistic regression of Study Data صحبت کردیم. در ادامه با کلیک بر روی شیت Study Data پنجره زیر برای ما باز میشود.

از آنجا که مثال رگرسیون لجستیک در دسته تحلیلهای XY قرار دارد، بنابراین کادر Graph family را بر روی همان XY قرار میدهیم. با OK کردن گراف زیر برای ما ساخته میشود.
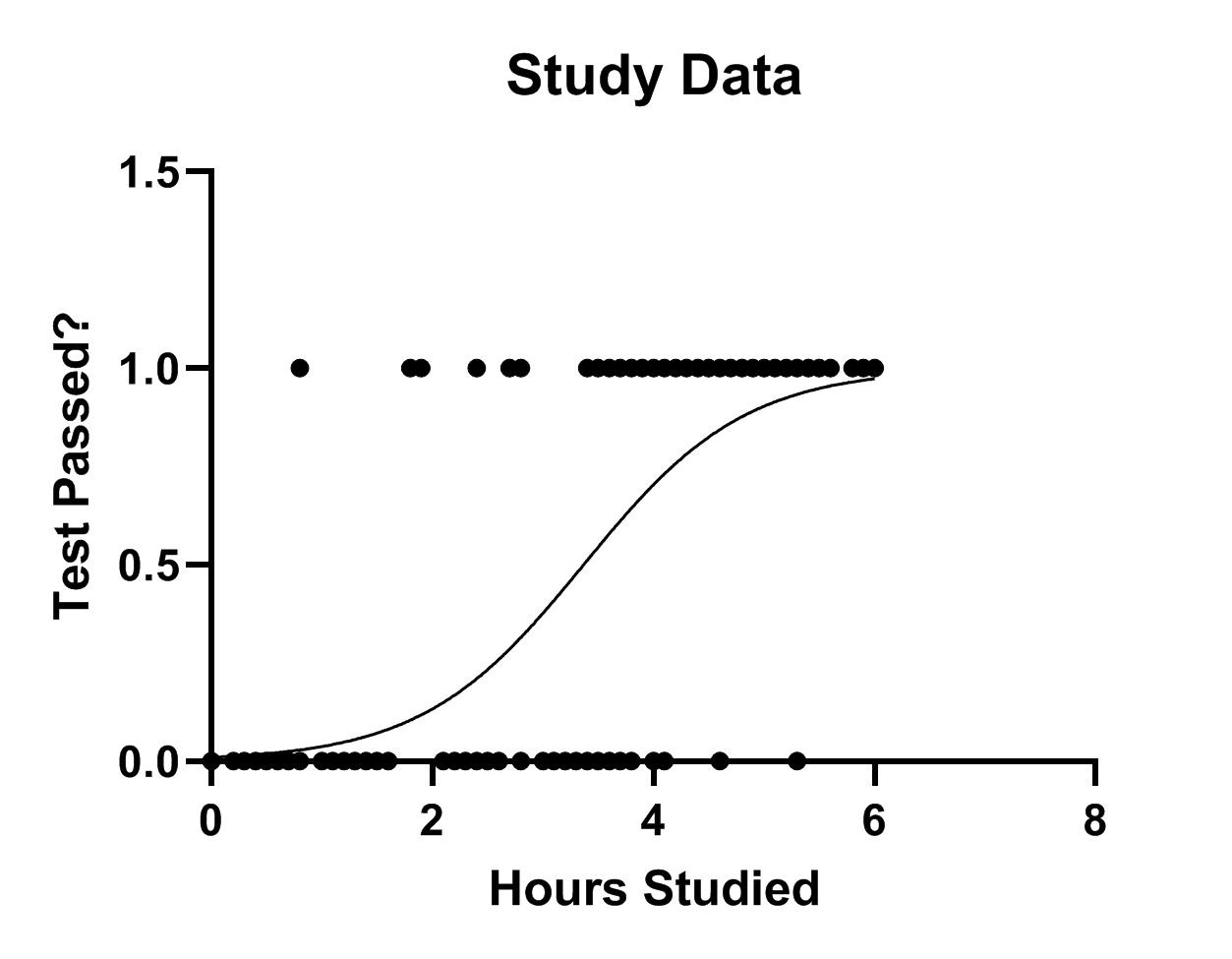
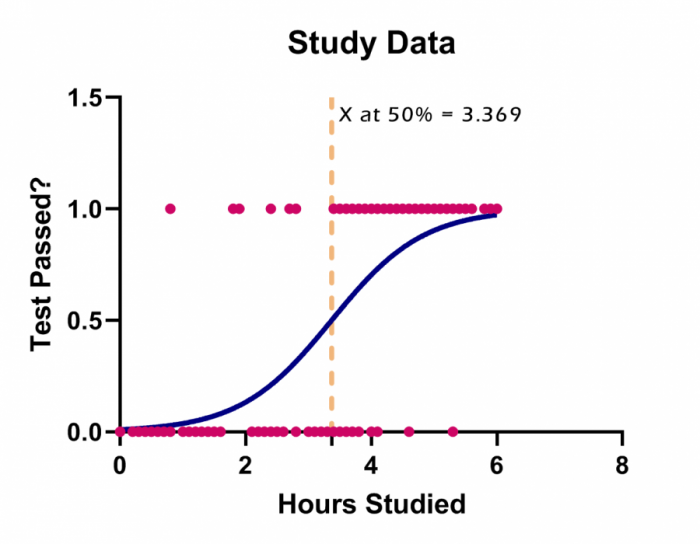
گراف بالا ترکیبی از نقاط و یک منحنی میباشد. نقاط در دو سطح صفر به معنای رد شدن در آزمون و یک به معنای قبولی در آزمون قرار گرفتهاند. محور X نیز تعداد ساعات مطالعه برای آزمون به ازای هر فرد را نشان میدهد. به وضوح افراد قبول شده، تعداد ساعات مطالعه بیشتری داشتهاند.
منحنی گراف نیز احتمال موفقیت به ازای ساعات مطالعه را نشان میدهد. این Curve اصطلاحاً یک منحنی سیگموئیدی نامیده میشود.
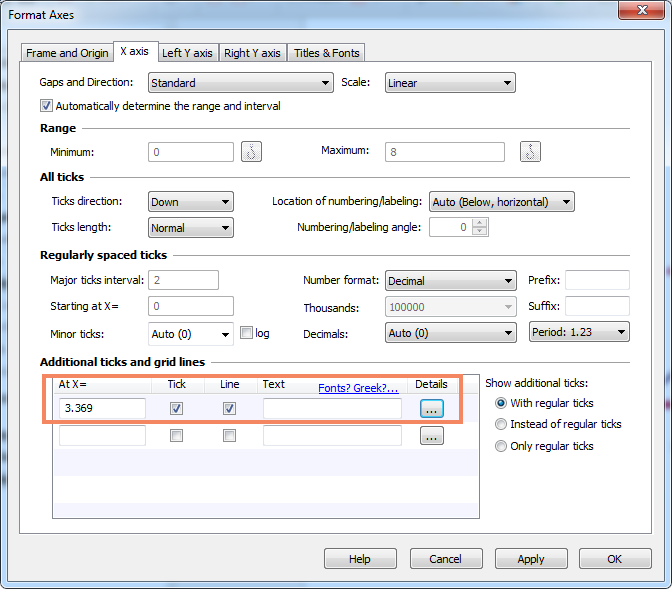
چنانچه علاقمند باشیم عبارت با نام X at 50% که بیانگر Xای بود که احتمال موفقیت برای آن 50 درصد است را در گراف بالا مشاهده کنیم، بر روی محور X دبل کلیک کرده و تنظیمات زیر را در کادر Additional ticks and grid lines قرار میدهیم. عدد 3.369 نوشته شده همان مقدار X at 50% است که در بخش Best-fit values نتایج نرمافزار برای ما به دست آمده است.
با Apply و OK کردن خط نشانگر X at 50% نیز در گراف دیده میشود. با کمی ویرایش، میتوانیم به گراف زیر برسیم.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). Simple Logistic Regression GraphPad Prism software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/simple-logistic-regression/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). Simple Logistic Regression GraphPad Prism software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/simple-logistic-regression/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.