بازاریابی و تمایل به خرید Propensity to Purchase در SPSS
Propensity to Purchase
روش تمایل به خرید Propensity to Purchase از نتایج یک پست آزمایشی یا کمپین قبلی برای ایجاد نمره یا اصطلاحاً Score استفاده میکند. نمرات نشان میدهند که کدام فرد بیشترین احتمال پاسخ مثبت و خرید را دارد. فیلد Response نشان میدهد که چه کسی به ایمیل آزمایشی یا کمپین قبلی پاسخ داده است.

فیلدهای Propensity ویژگیهایی هستند که میخواهید از آنها برای پیشبینی احتمال پاسخ مثبت در افراد دیگر استفاده کنید. خوب است در همین جا بدانیم که ما در تحلیل Propensity to Purchase با یک مدل رگرسیون لجستیک باینری روبهرو هستیم.
این تکنیک از رگرسیون لجستیک باینری برای ساخت یک مدل پیش بینی استفاده میکند. فرآیند طراحی و به کارگیری یک مدل پیش بینی دارای مراحل زیر است.
![]()
مدل را بسازید و فایل مدل را ذخیره کنید. شما مدل را با استفاده از مجموعه دادهای می سازید که نتیجه مورد علاقه (اغلب به عنوان هدف Target شناخته میشود) برای آن مشخص است. این نتیجه میتواند پاسخ مثبت و خرید باشد. برای مثال، اگر میخواهید مدلی بسازید که پیشبینی کند چه کسی احتمالاً به یک کمپین ایمیل پاسخ میدهد، باید با مجموعه دادهای شروع کنید که از قبل شامل اطلاعاتی در مورد اینکه چه کسی پاسخ داده و چه کسی پاسخ نداده، باشد. به بیان ساده ما در این گام باید تحلیل را بر روی افرادی انجام دهیم که پاسخ آنها (خرید یا عدم خرید) را میدانیم. به این ترتیب ما مدل را بر روی گروه کوچکی از مشتریان، طراحی میکنیم و میسازیم.
![]()
برای به دست آوردن نتایج پیشبینیشده، آن مدل را در مجموعه دادهای متفاوت که نتیجه مورد علاقه آن یعنی همان پاسخ مثبت یا منفی با کمپین، برای ما مشخص نیست اعمال کنید.
ملاحظات دادهها
Data Considerations
هنگامی که میخواهیم به آنالیز Propensity to Purchase در مطالعات مربوط به بازاریابی و Marketing بپردازیم، توجه به سطوح اندازهگیری و یا همان Measurement Level دادهها مهم است. در ادامه به اختصار درباره آن صحبت میکنیم.
در واقع تعیین اینکه Variable ما در کدام نوع از سطوح اندازهگیری قرار میگیرد، اهمیت بسیار دارد و بر روی نتایج به دست آمده تاثیر میگذارد.
برای توضیح بیشتر بیان میکنیم که دادهها در سه سطح اندازهگیری به ترتیب زیر قرار میگیرند.
- اسمی Nominal.
زمانی میتوان یک Variable را اسمی تلقی کرد که مقادیر آن، دستههایی را بدون رتبهبندی نشان دهند (مثلاً بخش شرکتی که یک کارمند در آن کار میکند). نمونههایی از کمیت اسمی مانند منطقه، کدپستی و وابستگی مذهبی است.
- رتبهای Ordinal.
زمانی میتوان یک Variable را رتبهای در نظر گرفت که مقادیر آن، دستههایی را با رتبهبندی نشان دهند (به عنوان مثال، سطوح رضایت از خدمات از بسیار ناراضی تا بسیار راضی). نمونههایی از کمیتهای ترتیبی شامل نمرات نگرش است که نشاندهنده درجه رضایت یا اعتماد و امتیازات رتبهبندی ترجیح است.
- پیوسته Continuous.
یک Variable زمانی میتواند به عنوان پیوسته (مستمر) در نظر گرفته شود که مقادیر آن اندازههایی مرتب شده را با یک متریک معنیدار نشان دهند، به طوری که مقایسه فاصله بین اندازهها مناسب و واقعی باشد. نمونههایی از کمیتهای پیوسته شامل سن بر حسب سال و درآمد به هزار دلار است.
حال بیایید در ادامه به بیان مثالی در زمینه تحلیل Propensity to Purchase بپردازیم. توضیحات بیشتر را میتوانید در این مثال مشاهده کنید و در ادامه دربارهی آنها حرف بزنیم. همچنین فایل این مثال را میتوانید از اینجا دریافت کنید.
مثال کار با نرمافزار SPSS Propensity to Purchase
Example
فرض کنید، بخش بازاریابی یک شرکت میخواهد از نتایج یک پست الکترونیکی آزمایشی برای تخصیص امتیاز تمایل به خرید به بقیه پایگاه داده کاربران خود، با استفاده از ویژگیهای فردی و دموگرافیک آنها، جهت شناسایی افرادی که به احتمال زیاد پاسخ مثبت میدهند و خریدار هستند، استفاده کند.
در تصویر زیر میتوانید بخشی از دادههای این مثال را مشاهده کنید.
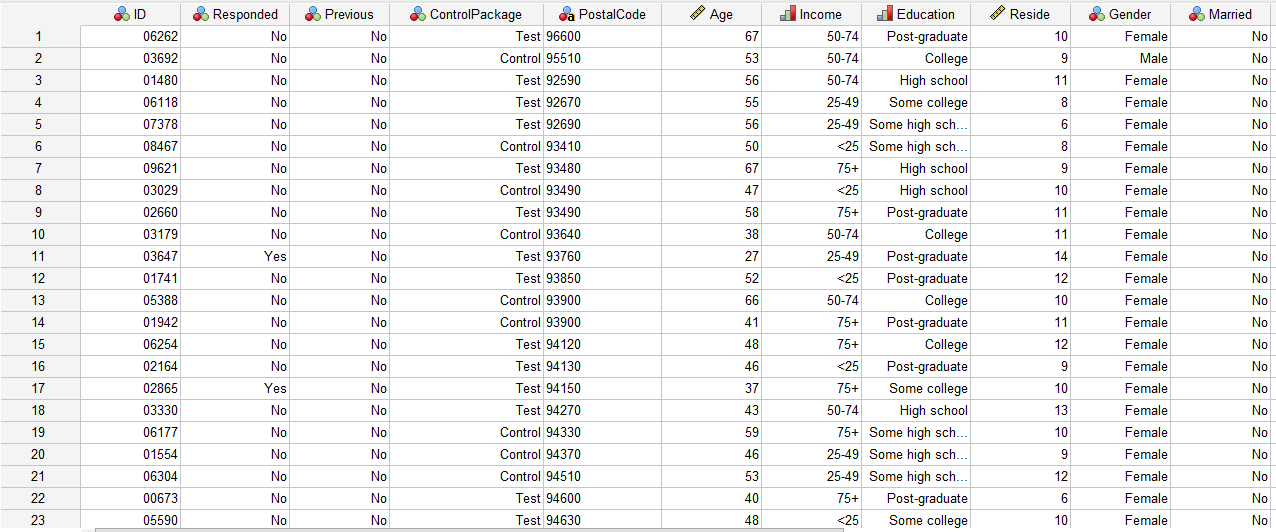
این بررسی بر روی 1917 فرد انجام شده است. همچنین در این فایل ستونی با نام Responded مشاهده میشود. در این ستون افرادی که کد 1 دارند به معنای این است که به ایمیل پاسخ داده و خرید کردهاند. افراد دارای کد صفر به ایمیل پاسخ ندادهاند. یک تحلیل فراوانی ساده نشان میدهد تعداد 1817 نفر پاسخ منفی و 100 نفر پاسخ مثبت دادهاند.
ما در این مثال به دنبال آن هستیم که با استفاده از نتایج ستون Responded یک مدل رگرسیون لجستیک بین این ستون به عنوان Dependent Variable و ویژگیهای فردی و دموگرافیک افراد به عنوان Independent Variable برقرار کنیم.
در مرحله بعد میخواهیم مدل لجستیک به دست آمده خود را بر روی دادههای دیگری که فقط ویژگیهای دموگرافیک و فردی دارند (یعنی فقط Independent Variable دارند) و فاقد ستون Responded هستند (یعنی Dependent Variable برای آنها وجود ندارد)، برازش دهیم.
با استفاده از مسیر زیر، به انجام آنالیز Propensity to Purchase در نرمافزار SPSS میپردازیم.
Analyze→ Direct Marketing (Choose Technique) → Select contacts most likely to purchase
پس از رفتن به این مسیر، پنجره Propensity to Purchase برای ما باز میشود.
تنظیمات نرمافزار
Fields & Settings
در ادامه به تنظیمات پنجره Propensity to Purchase جهت انجام تحلیل در SPSS و انتخاب گزینهها صحبت میکنیم. در این پنجره با دو تب به نامهای Fields و Settings روبهرو هستیم، به توضیح آنها میپردازیم.
-
Fields
این تب به چند بخش و کادرهای مختلفی تقسیم میشود. آنها را توضیح میدهیم.
- کادر Fields
در کادر Fields اسامی همه ستونها و Variableهای مطالعه آمده است. در این کادر میتوانید Measurement هر کدام از کمیتها را مشاهده کنید. در بالاتر توضیح دادیم که سطح اندازهگیری یا همان Measure کمیت باید به درستی انتخاب شده باشد.
- کادر Response Field
فیلد پاسخ باید اسمی Nominal و یا رتبهای Ordinal باشد. در این فیلد مشخص میشود چه افرادی پاسخ مثبت داده و خرید کردهاند. معمولاً Response Field با کدهای صفر و یک به ازای هر فرد مشخص میشود. افراد دارای پاسخ مثبت کد یک هستند و افراد بدون پاسخ کد صفر در نظر گرفته میشوند.
اگر این فیلد دارای چندین کد باشد فقط یکی از آنها به عنوان پاسخ مثبت بیان شده و بقیه پاسخ منفی در نظر گرفته میشوند.
همچنین اگر این فیلد شامل عددی است که تعداد یا مقدار خریدها را نشان میدهد، باید یک فیلد جدید دیگر ایجاد کنید که در آن با کدهای صفر و یک پاسخهای مثبت یا عدم پاسخها را مشخص کرده باشید.
- کادر Positive response value
این کادر کاملاً به کادر قبلی یعنی Response Field وابسته است و کد مثبت (افرادی که به ایمیل پاسخ دادهاند و خرید کردهاند) را تعریف میکند. همچنین در کادر بازشو میتوانید لیستی از تمام مقادیر تعریف شده در Response Field را مشاهده کنید. یکی از آنها را به عنوان پاسخ مثبت در نظر بگیرید.
- کادر Predict Propensity with
در این کادر، فیلدها و Variableهایی که میخواهیم مدل رگرسیون لجستیک ما بر مبنای آنها ساخته شود، قرار میگیرد. این فیلدها میتواند اسمی، رتبهای و یا پیوسته باشد.
حال بیایید به مثال خودمان برگردیم.
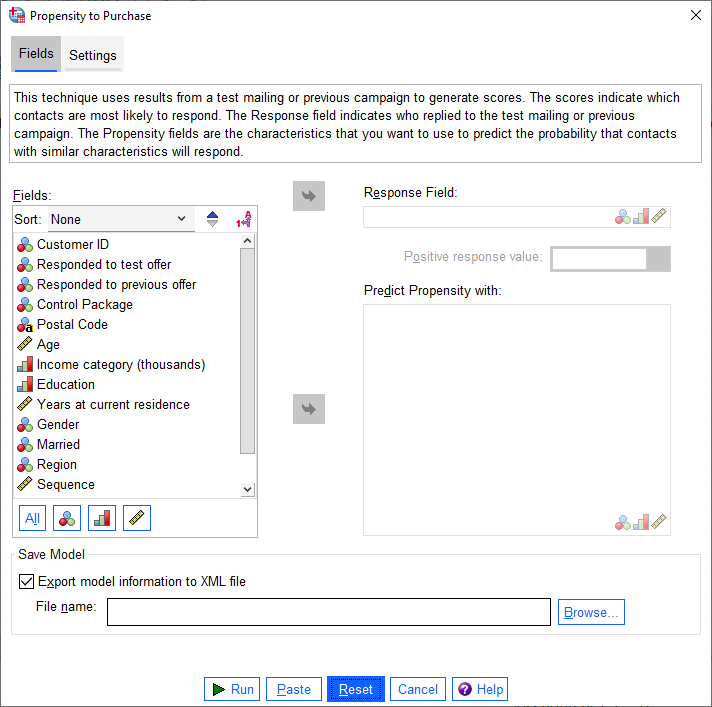
در کادر Fields تمام Variableهای موجود در مثال آمده است. در کادر Response Field نیز کمیت Responded to test offer قرار داده میشود.
در کادر کشویی Positive response value کدهای No و Yes دیده میشود. همانگونه که قبلاً نیز گفتیم در این کادر باید کد پاسخ مثبت قرار گیرد. بنابراین کد 1 یا همان Yes را انتخاب میکنیم.
ما میخواهیم پروفایلهای تشکیل شده بر مبنای کمیتهای زیر باشد.
Age, Income category, Education, Years at current residence, Gender, Married and Region
بنابراین آنها را از کادر Fields به کادر Predict Propensity with منتقل میکنیم.
در پایین پنجره Propensity to Purchase بخش دیگری با نام Save Model دیده میشود. با استفاده از این بخش میتوانیم مدل رگرسیون لجستیک خود را ذخیره کرده و آن را برای مرحله دیگر تحلیل Propensity to Purchase که در بالا به آن اشاره کردیم، فراخوان کنیم. در کادر File name یک نام دلخواه برای آن قرار میدهیم و با استفاده از دکمه Browse محل ذخیره این فایل را مشخص میکنیم. این فایل در قالب XML خواهد بود. به عنوان مثال من نام آن را Propensity to Purchase میگذارم.
در تصویر زیر میتوانید نحوه ورود Variable ها به نرمافزار SPSS در تب Fields را مشاهده کنید.

-
Settings
در پنجره Propensity to Purchase تب دیگری با نام Settings دیده میشود. در ادامه دربارهی آن صحبت میکنیم.
برگه تنظیمات به شما این امکان را میدهد تا بتوانیم حداقل تعداد نمونهها در هر پروفایل را کنترل کنیم. همچنین کمترین آستانه نرخ پاسخ را در خروجیها قرار دهیم.
در ادامه بیایید بخشهای متختلف این تب را توضیح دهیم.
-
Model Validation
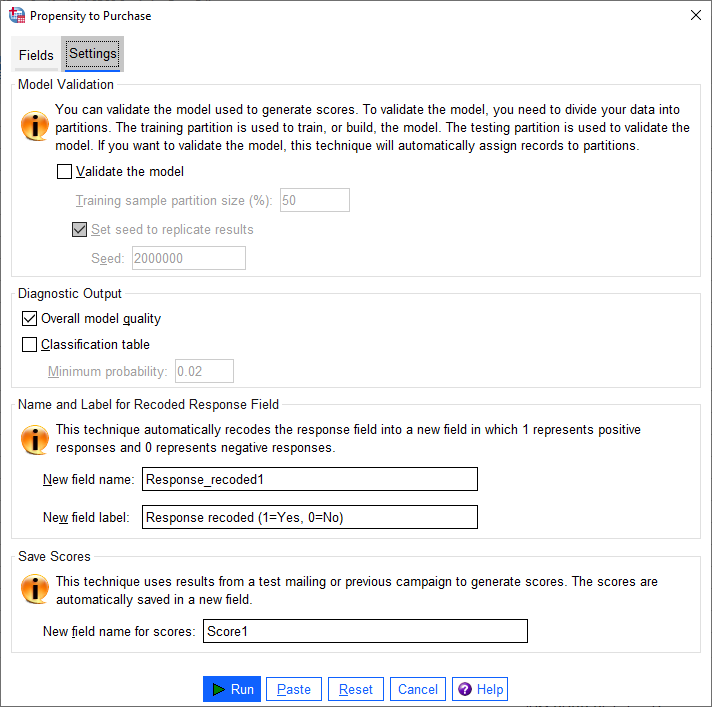
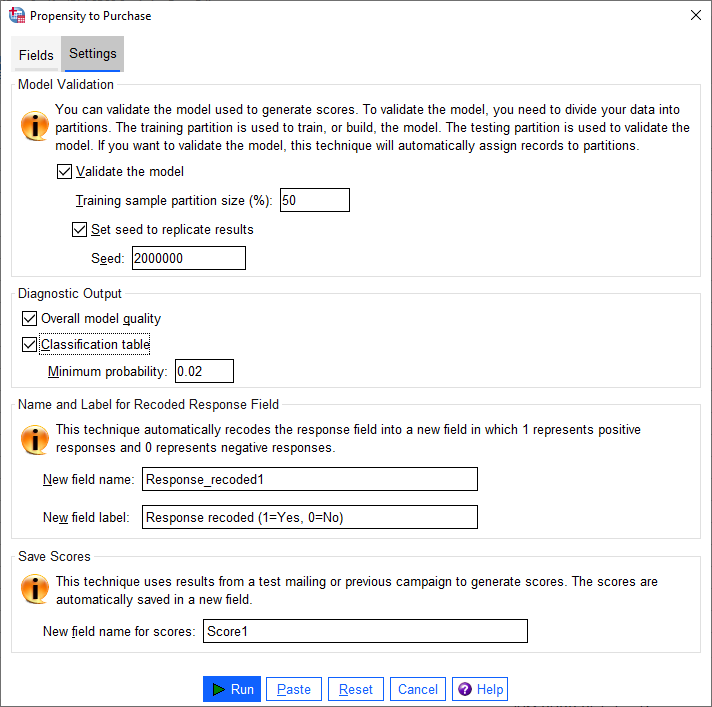
این بخش که به آن اعتبارسنجی مدل گفته میشود، گروههای با نامهای آموزشی Training و آزمایشی Testing را برای اهداف تشخیصی ایجاد میکند. اگر جدول طبقهبندی یعنی Classification table را در بخش Diagnostic Output انتخاب کنید، این جدول به منظور مقایسه، به بخشهای آموزشی (انتخاب شده) و تست (انتخاب نشده) تقسیم میشود. نمرات که در واقع همان احتمال پاسخ مثبت در مدل رگرسیون لجستیک است، بر مبنای مدل به دست آمده از نمونه Training (که همیشه دارای رکوردهای کمتری نسبت به تعداد کل رکوردهای موجود است)، میباشد. ما در این بخش گزینه Validate the model را انتخاب میکنیم.
Training sample partition size (%). با استفاده از این گزینه، درصد رکوردهایی که باید به نمونه Training اختصاص داده شود را مشخص کنید. بقیه رکوردها به نمونه Testing اختصاص داده میشوند. مقدار باید بین صفر و 100 باشد. معمولاً به صورت پیشفرض این عدد بر روی 50 قرار گرفته است.
Set seed to replicate results. از آنجایی که رکوردها به طور تصادفی به نمونههای Training و Testing اختصاص داده میشوند، هر بار که این روش را اجرا میکنید ممکن است نتایج متفاوتی دریافت کنید، مگر اینکه همیشه از نقطه شروع یکسان که به آن Seed گفته می شود، تولید اعداد تصادفی را انجام دهیم. به صورت پیشفرض نرمافزار SPSS عدد Seed را برابر با 200000 در نظر میگیرد.
-
Diagnostic Output
در این بخش درباره نتایج و خروجیهایی که در پنجره Output نرمافزار به دست میآید، صحبت میکند.
Overall model quality. یک نمودار میله ای از کیفیت کلی مدل نشان میدهد که به صورت مقداری بین 0 و 1 بیان میشود. یک مدل خوب باید مقداری بیشتر از 0.5 داشته باشد.
Classification table. جدولی را نشان میدهد که پاسخهای مثبت و منفی پیشبینی شده را با پاسخهای مثبت و منفی واقعی مقایسه میکند. میزان دقت کلی میتواند نشان دهد که مدل چقدر خوب کار میکند، با این حال ممکن است به درصد پاسخهای مثبت پیشبینی شده صحیح علاقه بیشتری داشته باشید. درباره این جدول و نتایج آن در ادامه بیشتر صحبت خواهیم کرد.
Minimum probability. رکوردهایی با مقدار Score بیشتر (یادتان باشد گفتیم این Scoreها در واقع همان احتمال پاسخ مثبت در مدل رگرسیون لجستیک است) از مقدار مشخص شده را به دسته پاسخ مثبت پیشبینی شده در جدول طبقهبندی، اختصاص میدهد. به عنوان یک قاعده کلی، شما باید مقداری نزدیک به حداقل نرخ پاسخ هدف خود را که به صورت نسبت بیان می شود، مشخص کنید. به عنوان مثال، اگر به نرخ پاسخ حداقل 5 درصد علاقه دارید، 0.05 را مشخص کنید. مقدار باید بزرگتر از 0 و کمتر از 1 باشد.
-
Name and Label for Recoded Response Field
این روش به طور خودکار فیلد پاسخ را در یک فیلد جدید که در آن 1 نشاندهنده پاسخهای مثبت و 0 نشاندهنده پاسخهای منفی است، بار دیگر کدگزاری میکند. تحلیل در فیلد دوباره کدگذاری شده انجام میشود. شما میتوانید نام و برچسب پیشفرض را اصلاح کرده و نام دلخواه خود را قرار دهید. به این نکته توجه کنید که نامها باید با قوانین نامگزاری IBM® SPSS® Statistics مطابقت داشته باشند.
-
Save Scores
یک فیلد جدید شامل نمرات تمایل به خرید، به طور خودکار در مجموعه داده اصلی ایجاد میشود. این نمرات نشاندهنده احتمال پاسخ مثبت است که به صورت نسبت بیان می شود. به این نکته توجه کنید که نام فیلدها باید با قوانین نامگزاری SPSS مطابقت داشته باشد. همچنین نام فیلد نمیتواند نام فیلدی را که از قبل در مجموعه داده وجود دارد کپی کند. اگر این رویه را بیش از یک بار روی مجموعه داده اجرا کنید، باید هر بار نام متفاوتی را قرار دهید.
در تصویر زیر میتواند تنظیمات دلخواه تب Setting را مشاهده کنید.
حال در ادامه با Run کردن تنظیمات و انتخاب Variableها میتوانیم نتایج به دست آمده توسط نرمافزار SPSS را مشاهده کنیم.
نتایج خروجیهای SPSS تحلیل تمایل به خرید
Output
هنگامی که Run میکنیم، نتایج و خروجیهای نرمافزار در پنجره Output به دست میآید. همچنین در فایل دیتا، دو ستون جدید ایجاد میشود. تصویر زیر را ببینید.
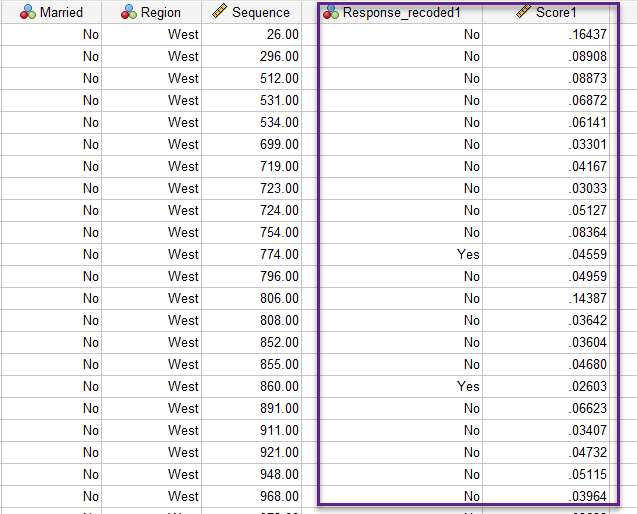
اسامی این ستونهای جدید یعنی Response_recoded1 و Score1 در همان تنظیمات پنجره Propensity to Purchase قرار داده شده بود. ستون Response_recoded1 در واقع همان یافتههای فیلد Responded to test offer است که بار دیگر جهت انجام تحلیل کدگزاری شده است. یادتان باشد این ستون به پاسخ مثبت و یا منفی کاربران میپرداخت.
ستون Score1 نیز به هر فرد یک نمره داده است. این نمره در واقع همان احتمال پاسخ مثبت توسط فرد است که با استفاده از مدل رگرسیون لجستیک باینری به دست میآید. یادتان باشد ما در بخش Minimum probability از تنظیمات نرمافزار عدد 0.02 را قرار دادیم. بنابراین در مواردی که Score بالاتر از این عدد است، پاسخ مثبت و در مواردی که کمتر از این عدد است پاسخ منفی در نظر گرفته میشود.
اگر خوب دقت کنید مشاهده میکنید که در خیلی از موارد بین این یافته و ستون Response_recoded1 تناقض وجود دارد. یعنی عدد Score مثلاً بالاتر از 0.02 به دست آمده است و بنابراین از دیدگاه مدل پاسخ مثبت است، اما در ستون Response_recoded1 پاسخ منفی است. وجود این تناقض ما را به استفاده از جدول زیر که در Output نرمافزار به دست میآید، راهنمایی میکند. در واقع این تناقض چیز عجیبی نیست.
در ابتدای فایل Output جدول زیر با نام Classification Table دیده میشود.
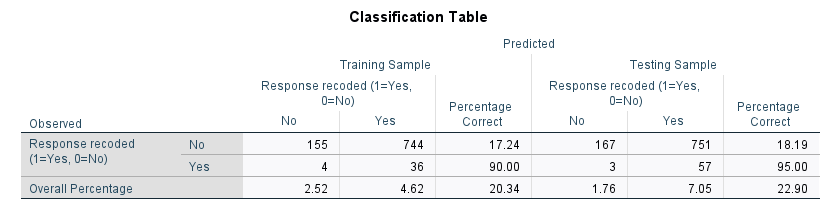
جدول طبقهبندی مقادیر پیشبینی شده فیلد Responded to test offer را با مقادیر واقعی آن مقایسه میکند. میزان دقت کلی یا همان Overall Percentage میتواند نشانههایی از عملکرد خوب مدل ارائه دهد، اما اگر هدف مطالعه ایجاد مدلی باشد که گروهی از افرادی را که احتمالاً پاسخ مثبتی میدهند شناسایی کند، ممکن است بیشتر به درصد پاسخهای مثبت پیشبینیشده صحیح علاقه داشته باشید.
جدول طبقهبندی به بخشهای Training Sample و Testing Sample تقسیم میشود. از Training Sample برای ساخت مدل لجستیک استفاده میشود. سپس این مدل ساخته شده به Testing Sample اعمال میشود تا ببیند مدل چقدر خوب کار میکند.
حداقل نرخ پاسخ مشخص شده 0.02 یا 2% بود. جدول طبقهبندی بالا نشان میدهد که میزان طبقهبندی صحیح برای پاسخهای مثبت در نمونه آموزشی 4.62 درصد و در نمونه آزمایشی 7.05 درصد است. از آنجایی که نرخ پاسخ نمونه آزمایشی بیشتر از 2% است، این مدل باید قادر باشد افرادی را شناسایی کند که احتمالاً نرخ پاسخگویی بیشتر از 2% را ارائه میدهند.
در ادامه بیایید بخشهای مختلف این جدول و اعداد آن را بیشتر بررسی کنیم. تصویر زیر را ببینید. به ترتیب شمارهگزاری آنها را توضیح میدهیم.

1 عدد 155 به دست آمده در نمونه Training نشان میدهد 155 نفر در واقع (Observed) پاسخ منفی داده بودند، نرمافزار نیز به درستی آنها را در گروه No پیشبینی شده بر مبنای مدل (Predicted) قرار داده است.
2 عدد Percentage Correct برابر با 17.24 به دست آمده است. تعداد کل افرادی که در نمونه Training پاسخ منفی داده بودند (Observed) برابر با 899 = 744 + 155 نفر بوده است. از بین آنها فقط 155 نفر به درستی منفی تشخیص داده شده و پیشبینی شدهاند. بنابراین درصد درستی در اینجا برابر با 155/899 نفر است که همان 17.24 درصد به دست میآید.
3 به عدد 36 به دست آمده در نمونه Training نگاه کنید. این عدد نشان میدهد 36 نفر که پاسخ مثبت داده بودند (Observed)، مدل نیز به درستی آنها را در گروه Yes پیشبینی شده بر مبنای مدل (Predicted) قرار داده است. از آنجا که در نمونه Training رویهم 40 نفر پاسخ مثبت داده بودند (Observed)، بنابراین درصد درستی پیشبینی مدل در اینجا 90 درصد است.
4 Overall Percentage در اینجا برابر با 4.62 درصد به دست آمده است. تعداد کل افرادی که در نمونه Training بر مبنای مدل لجستیک، پاسخ مثبت پیشبینی شدهاند (Predicted) برابر با 780 = 36 + 744 نفر بوده است. از بین آنها فقط 36 نفر به درستی مثبت پیشبینی شدهاند. بنابراین درصد درستی در اینجا برابر با 36/780 نفر است که همان 4.62 درصد به دست میآید.
5 به اعداد روی قطر یعنی 155 و 36 نگاه کنید. آنها مواردی هستند که مدل به درستی پیشبینی کرده است. 155 نفر پاسخ منفی و 36 نفر پاسخ مثبت. بنابراین تعداد موارد پیشبینی درست 191 = 36 + 155 است. تعداد کل نمونه آموزشی نیز برابر با 939 = 36 + 4 + 744 + 155 نفر است. بنابراین درصد درستی پیشبینی کلی در این نمونه برابر با 191/939 یعنی همان 20.34 درصد است.
6 همه مواردی که برای بخش Training گفتیم برای بخش Testing نیز برقرار است. Overall Percentage در اینجا برابر با 7.05 درصد به دست آمده است. تعداد کل افرادی که در نمونه Testing بر مبنای مدل لجستیک، پاسخ مثبت پیشبینی شدهاند (Predicted) برابر با 808 = 57 + 751 نفر بوده است. از بین آنها فقط 57 نفر به درستی مثبت پیشبینی شدهاند. بنابراین درصد درستی در اینجا برابر با 57/808 نفر است که همان 7.05 درصد به دست میآید. به این ترتیب از آنجایی که نرخ پاسخ نمونه آزمایشی بیشتر از 2% است، این مدل باید قادر باشد افرادی را شناسایی کند که احتمالاً نرخ پاسخگویی بیشتر از 2% را ارائه میدهند.
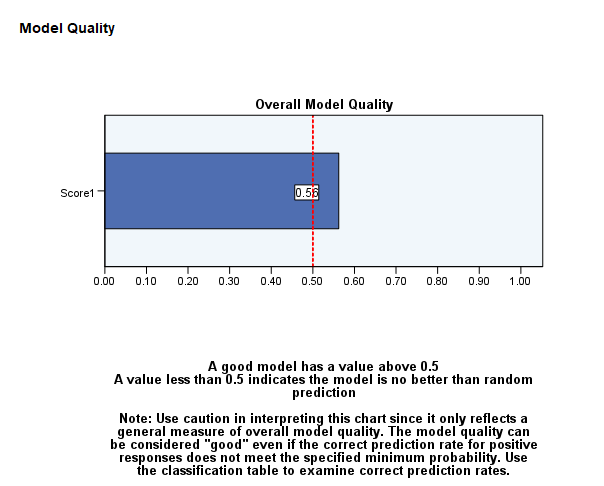
به فایل Output و خروجیهای نرمافزار نگاه کنید. در این خروجیها گراف زیر با نام Overall Model Quality دیده میشود.
نمودار کیفیت کلی مدل یک نشانه و گراف بصری از کیفیت مدل ارائه میدهد. معمولاً بیان میشود که کیفیت کلی مدل باید بالای 0.5 باشد. در اینجا ما با یک اندازه عددی 0.56 روبهرو هستیم. بنابراین مدل ما مناسب است.
در ابتدای متن بیان کردیم که فرآیند طراحی و به کارگیری یک مدل پیشبینی در مطالعات Propensity to Purchase دارای مراحل زیر است. بار دیگر آنها را بیان میکنیم.
![]()
مدل را بسازید و فایل مدل را ذخیره کنید. شما مدل را با استفاده از مجموعه دادهای می سازید که نتیجه مورد علاقه (اغلب به عنوان هدف Target شناخته میشود) برای آن مشخص است. این نتیجه میتواند پاسخ مثبت و خرید باشد. برای مثال، اگر میخواهید مدلی بسازید که پیشبینی کند چه کسی احتمالاً به یک کمپین ایمیل پاسخ میدهد، باید با مجموعه دادهای شروع کنید که از قبل شامل اطلاعاتی در مورد اینکه چه کسی پاسخ داده و چه کسی پاسخ نداده، باشد. به بیان ساده ما در این گام باید تحلیل را بر روی افرادی انجام دهیم که پاسخ آنها (خرید یا عدم خرید) را میدانیم. به این ترتیب ما مدل را بر روی گروه کوچکی از مشتریان، طراحی میکنیم و میسازیم.
![]()
برای به دست آوردن نتایج پیشبینیشده، آن مدل را در مجموعه دادهای متفاوت که نتیجه مورد علاقه آن یعنی همان پاسخ مثبت یا منفی با کمپین، برای ما مشخص نیست اعمال کنید.
تا به حال هر آنچه صحبت کردیم مربوط به مرحله 1 یعنی ساختن و ذخیره کردن مدل بود. حال در مرحلهی بعد باید این مدل طراحی شده را بر روی دیتای دیگری که Dependent Variable آن مشخص نیست (به دلیل اینکه ما بر روی این دادهها ایمیل تبلیغاتی یا کمپینی هنوز ارسال نکردهایم که بدانیم چه افرادی پاسخ مثبت میدهند و چه افرادی پاسخ منفی) به کار ببریم و امتحان کنیم. در جدول Classification Table نشان دادیم که Overall Percentage برای نمونه آزمایشی برابر با 7.05 درصد است که از حداقل نرخ پاسخ 2 درصد که در تنظیمات نرمافزار آن را در نظر گرفتیم، بالاتر است. بنابراین میتوانیم انتظار داشته باشیم که مدل قادر است افرادی را شناسایی کند که نرخ پاسخگویی بیشتر از 2% را ارائه میدهند.
در ادامه متن به بیان نحوه انجام مرحله بعدی میپردازیم.
بکارگیری مدل
Applying the model
فرض کنید ما مدل رگرسیون لجستیک خود را بر روی افرادی که هم Dependent Variable آنها را میدانستیم (یعنی پاسخ مثبت یا منفی) و هم Independent Variable های آنها را میدانیم، برازش دادهایم و به دست آوردهایم. یادتان باشد ما این مدل را در تنظیمات نرمافزار و در یک فایل با فرمت XLM با نام Propensity to Purchase ذخیره کردیم. در این مرحله میخواهیم از یافتههای این مدل جهت به کار بردن بر روی دیتایی که پاسخ مثبت و منفی آنها را نمیدانیم (به دلیل اینکه ایمیل یا کمپینی ارسال نکردهایم) و فقط Independent Variable های آنها برایمان مشخص است، استفاده کنیم.
به تصویر زیر نگاه کنید. این تصویر دادههایی را نشان میدهد که پاسخ مثبت یا منفی افراد را نمیدانیم و صرفاً همانند مرحله قبل ویژگیهای فردی و دموگرافیک افراد برایمان مشخص است. فایل دیتا را میتوانید از اینجا دریافت کنید.
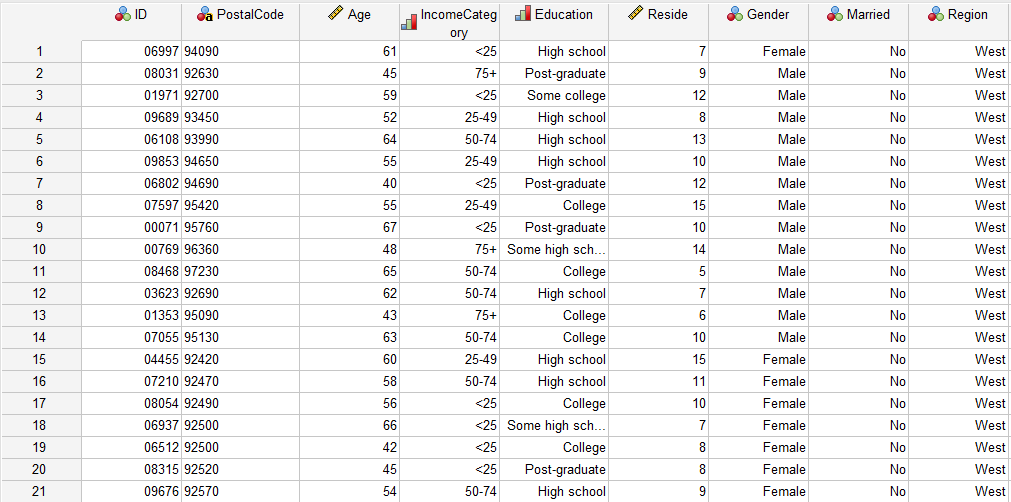
همانگونه که در تصویر بالا مشاهده میکنید، دادهها دارای اطلاعات فردی برای هر کاربر هستند اما ستونی دربارهی اینکه پاسخ مثبت با منفی به پیشنهاد خرید دادهاند، وجود ندارد. همانگونه که قبلتر گفتیم ما میخواهیم مدل رگرسیون لجستیک به دست آمده از مرحلهی قبل را بر این دادهها برازش دهیم.
برای انجام این کار لازم است در ابتدا همان فایل XLM را فراخوان کنیم. این کار با استفاده از مسیر زیر در نرمافزار SPSS انجام میشود.
Utilities → Scoring Wizard → Select contacts most likely to purchase
در این مسیر پنجره زیر با نام Scoring Wizard برای ما باز میشود. در ابتدا و با استفاده از دکمه Browse فایل XLM ذخیره شده از انجام مرحله قبلی را فراخوان میکنیم. با انجام این کار در کادر Model Details اطلاعات مربوط به این فایل و مدل اجرا شده بر روی آن، مشخص میشود.
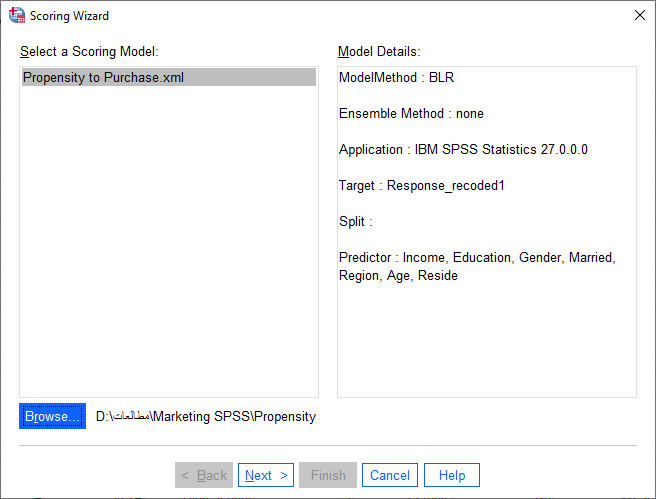
سپس Next میکنیم تا وارد پنجره بعدی شویم. تصویر زیر را ببینید.
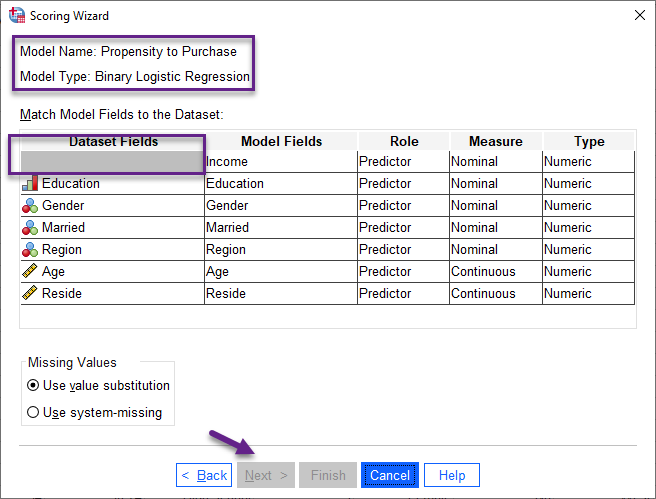
در ابتدای این پنجره نام مدل که همان Propensity to Purchase است، بیان میشود. نوع مدل نیز رگرسیون لجستیک باینری Binary Logistic Regression نوشته شده است. هدف ما در این پنجره این است که بین اجزای مدل در فایل XLM و ستونهای فایل دیتا فعلی که میخواهیم تحلیل لجستیک را بر روی آن انجام دهیم (به این فایل دیتا Active Dataset میگوییم) تطابق برقرار کنیم.
چنانچه دقت کنید دکمه Next در این پنجره فعال نیست. این مطلب نشان میدهد در حال حاضر بین فایل XLM فراخوان شده و فایل Active Dataset تطابق برقرار نیست. در واقع فیلد و ستونهایی وجود دارد که همچنان انتخاب شده نیستند. اگر دقت کنید میبینید که ستون IncomeCategory در اینجا وجود ندارد و جای آن در بخش Dataset Fields خالی است. پس لازم است آن را نیز انتخاب کنیم. تصویر زیر را ببینید.
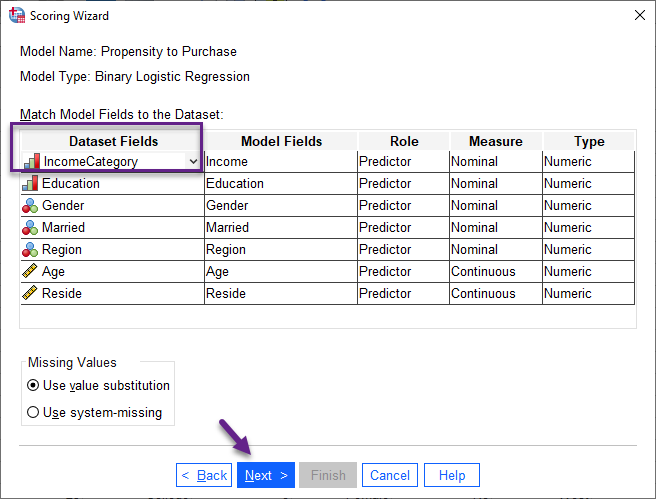
با انجام این کار همانگونه که مشاهده میکنید گزینه Next نیز فعال میشود. بر روی آن میزنیم تا وارد پنجره بعدی شویم. تصویر آن را در ادامه ببینید.

در این پنجره ستون یا ستونهایی که میتواند در فایل دیتا فعلی ایجاد شود، آمده است. هر کدام را که انتخاب کنید، در انتهای فایل دیتا، ستون مربوط به آن ساخته میشود. به این نکته دقت کنید که در این پنجره گزینه Probability of Selected Category را انتخاب کرده و کد 1 که به معنای پاسخ مثبت است، در کادر خالی قرار گرفته باشد. حال بار دیگر بر روی دکمه Next بزنید. وارد پنجره زیر خواهید شد.
در این مرحله که پنجره انتهایی است، نمرات Score که همان احتمال مشاهده پاسخ مثبت بر مبنای مدل رگرسیون لجستیک است، در فایل Active Dataset قرار میگیرند.
حال بر روی دکمه Finish بزنید. با انجام این کار، در فایل دیتا چهار ستون جدید (هر یک مربوط به یکی از گزینه های پنجره Scoring Wizard) ساخته میشود. در تصویر زیر میتوانید آنها را ببینید.
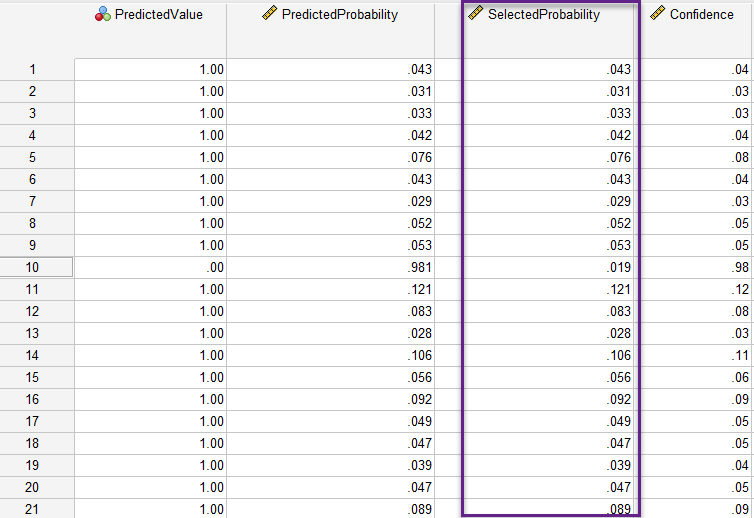
از آنجا که ما در این مثال علاقهمند به یافتن احتمال پاسخ مثبت هستیم. بنابراین به دادههای ستون SelectedProbability توجه میکنیم. در این ستون هر عدد بیانگر احتمال پاسخ مثبت و خرید توسط فرد مورد بررسی (سطر) میباشد.
خاطرتان باشد ما حداقل احتمال پاسخ مثبت را برابر با 0.02 و یا 2% در نظر گرفتیم. در اینجا هر کدام از اعداد ستون SelectedProbability بزرگتر از 0.02 باشد، از دیدگاه نرمافزار و مدل برازش شده، احتمال پاسخ مثبت است و برای همین در ستون PredictedValue کد 1 را دریافت کرده است. در مواردی هم که اعداد ستون SelectedProbability کوچکتر از 0.02 باشد، از دیدگاه نرمافزار و مدل برازش شده، احتمال پاسخ منفی است و برای همین در ستون PredictedValue کد 0 ثبت شده است.
ستون SelectedProbability به شما در شناسایی افرادی که پتانسیل پاسخ مثبت را دارند، کمک خواهد کرد. به عنوان مثال چنانچه شما دارای محدویت ارسال بستههای تبلیغاتی خود هستید و فقط میخواهید آنها را برای افرادی بفرستید که احتمال پاسخ مثبت آنها از سطح مشخص بالاتر است (مثلاً بالاتر از پانزده درصد)، این کار را میتوانید به سادگی با Sort کردن در ستون SelectedProbability انجام دهید. به عنوان مثال به تصویر زیر نگاه کنید.
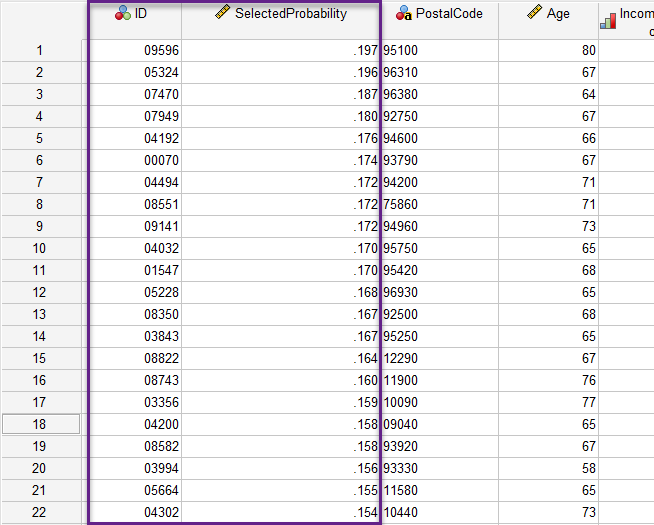
همه این ID ها افرادی هستند که احتمال پاسخ مثبت در آنها بیشتر از 15 درصد است. بنابراین با تمرکز بر روی آنها میتوان صرفاً بستههای تبلیغاتی را برای این افراد (کدپستی آنها را نیز در همین فایل داریم) ارسال کرد.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Direct Marketing and Propensity to Purchase in SPSS. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/direct-marketing-spss-propensity-to-purchase/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Direct Marketing and Propensity to Purchase in SPSS. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/direct-marketing-spss-propensity-to-purchase/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.