بازاریابی، تحلیل RFM و دادههای تراکنش Transaction Data در نرمافزار SPSS
تحلیل RFM چیست؟
RFM Analysis
آنالیز RFM که نام صحیح و کامل آن Recency, Frequency, Monetary value است، ابزار تحلیل بازاریابی است که برای شناسایی بهترین مشتریان یک شرکت یا سازمان با استفاده از معیارهای خاص استفاده میشود. به عبارت دیگر، RFM روشی است که برای تحلیل ارزش مشتری استفاده میشود. این روش بیشتر در بازاریابی پایگاه داده Database Marketing و بازاریابی مستقیم Direct Marketing استفاده میشود.

این تکنیک مشتریان فعلی را که به احتمال زیاد به یک پیشنهاد جدید پاسخ میدهند، برای ما شناسایی میکند. در ابتدا بیایید تعاریف زیر را ببینیم.
تعریف. بازاریابی مستقیم Direct Marketing چیست؟
تجارت فروش محصولات یا خدمات به طور مستقیم به عموم مردم، به عنوان مثال. از طریق ایمیل، سایت، سفارش پستی یا فروش تلفنی.
تعریف. بازاریابی پایگاه داده Database Marketing چیست؟
بازاریابی پایگاه داده نوعی بازاریابی مستقیم است. این شامل جمعآوری دادههای مشتری مانند نام، آدرس، ایمیل، شماره تلفن و تاریخچه تراکنشها، است. سپس این اطلاعات تجزیه و تحلیل میشوند و برای ایجاد یک تجربه شخصی برای هر مشتری یا جذب مشتریان جدید استفاده میشود.
شاخصهای RFM
Quantitative Factors
مدل و آنالیز RFM مبتنی بر سه شاخص کمی و قابل اندازهگیری است. در واقع نام آنالیز RFM از این فاکتورها اقتباس شده است. آنها را در ادامه توضیح میدهیم.
-
تازگی Recency
چند وقت پیش یک مشتری خرید کرده است؟ How recently a customer has purchased?
مهمترین عامل در شناسایی مشتریانی که به یک پیشنهاد جدید پاسخ میدهند، تازگی است. مشتریانی که اخیراً خرید کردهاند، نسبت به مشتریانی که در گذشته خرید کردهاند، احتمال بیشتری برای خرید مجدد دارند.
در واقع عامل Recency به مفهوم زمان اشاره دارد.
-
فراوانی Frequency
چند وقت یکبار خرید میکند؟ How often he purchases?
عامل مهم دیگر فراوانی است. مشتریانی که در گذشته خریدهای بیشتری انجام دادهاند، نسبت به مشتریانی که خریدهای کمتری انجام دادهاند، با احتمال بیشتری پاسخ میدهند و تمایل به خرید مجدد دارند.
به عبارت دیگر Frequency به مفهوم تعداد و دفعات خرید میپردازد.
-
ارزش پولی Monetary Value
چقدر خرید و خرج میکند؟ How much does he spend?
سومین عامل مهم، مبلغ هزینه شده است که به آن ارزش پولی میگویند. مشتریانی که در گذشته بیشتر (در مجموع برای همه خریدها) خرج کردهاند، نسبت به کسانی که کمتر هزینه کردهاند، با احتمال بیشتری پاسخ میدهند.
به این ترتیب Monetary Value به مفهوم مالی و پولی اشاره دارد.
بنابراین ما در یک مطالعه RFM به بررسی سه ویژگی میپردازیم. تازگی، فراوانی و ارزش پولی شاخصها و معیارهای مورد بررسی در تحلیل RFM خواهند بود.
در این متن قصد داریم با استفاده از نرمافزار SPSS به بیان و نحوه اجرای آنالیز RFM بپردازیم.
تحلیل RFM در نرمافزار SPSS در دو بخش دادهها و اطلاعات تراکنش Transaction Data و دادهها و اطلاعات مشتری Customer Data انجام میشود.
در این متن درباره مبحث Transaction Data صحبت خواهیم کرد. موضوع Customer Data را میتوانید از این لینک ببینید.
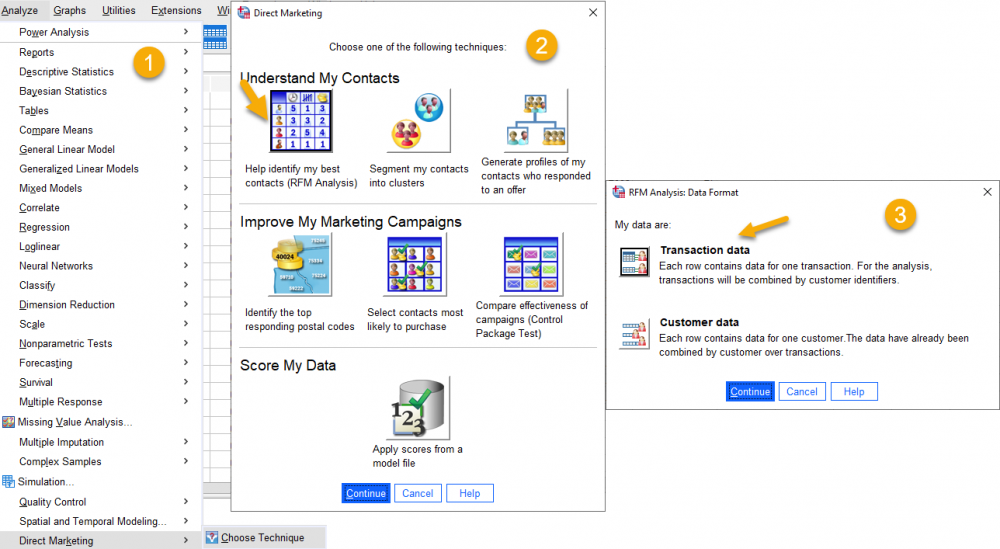
مسیر انجام تحلیل RFM
Transaction Data
مسیر انجام آنالیز RFM در نرمافزار SPSS به صورت زیر است.
Analyze→ Direct Marketing (Choose Technique) → RFM Analysis → Transaction Data
برای انجام یک تحلیل RFM از نوع Transaction Data باید یافتهها و Variableهای زیر در دسترس و در فایل دیتا ما موجود باشد.
- کمیت یا ترکیبی از کمیتها که هر مشتری را با یک کد یکتا و قابل تمایز، مشخص کند.
- کمیتی که تاریخ و زمان هر تراکنش را مشخص کند.
- کمیتی که ارزش پولی هر کمیت را بیان کرده باشد.
بنابراین ما در فایل دیتا خود به داشتن اطلاعاتی درباره زمان و ارزش هر تراکنش به همراه کدی برای هر مشتری نیازمند هستیم.
به یک نکته مهم دیگر نیز توجه کنید. در فایل دیتا مربوط به Transaction Data هر سطر به جای بیان یک مشتری و اطلاعات مربوط به او، به بیان یافتهها و اطلاعات درباره هر تراکنش میپردازد. به عبارت ساده در این نوع از تحلیل RFM، هر سطر بیانگر یک تراکنش است، نه یک فرد (مشتری).
با داشتن این اطلاعات (حداقل) میتوانیم تحلیل RFM را انجام دهیم.
حال بیایید در ادامه به بیان مثالی در زمینه تحلیل RFM بر مبنای دادههای تراکنش بپردازیم. فایل این مثال را میتوانید از اینجا دریافت کنیم.
مثال تحلیل RFM بر دادهها و اطلاعات تراکنش Transaction Data
این مثال، دادههای تراکنش خرید، تاریخ خرید، کالاهای خریداری شده و ارزش پولی هر تراکنش است. داده ها برای 4906 تراکنش به دست آمده است.
در تصویر زیر میتوانید بخشی از دادهها را مشاهده کنید. ستونی نیز با نام ID که کد شناساگر برای هر خریدار است، در فایل دیتا دیده میشود.
همانگونه که بالاتر گفتیم با استفاده از مسیر زیر، به انجام آنالیز RFM در نرمافزار SPSS میپردازیم.
Analyze→ Direct Marketing (Choose Technique) → RFM Analysis → Transaction Data
پس از رفتن به این مسیر، پنجره RFM Analysis from Transaction Data برای ما باز میشود.
تنظیمات نرمافزار
RFM Analysis from Transaction Data
در ادامه به تنظیمات پنجره RFM Analysis from Transaction Data جهت انجام تحلیل RFM و نحوه ورود اطلاعات به نرمافزار SPSS و انتخاب گزینهها صحبت میکنیم. در این پنجره با چهار تب روبهرو هستیم، به توضیح آنها میپردازیم.
-
Variables
در این تب لازم است، ستونها و Variableهای فایل دیتا، به درستی وارد تنظیمات نرمافزار شوند. در کادر Variables میتوانید نام و Label هر ستون را مشاهده کنید.
- در کادر Transaction Date همانگونه که از نام آن پیدا است، Variable مربوط به تاریخ هر تراکنش قرار میگیرد.
- در کادر Transaction Amount، ستون و Variable مربوط به مبلغ و ارزش پولی هر تراکنش قرار میگیرد.
- در بخش Summary Method انواع آمارهها شامل مجموع، ماکزیمم، میانگین و میانه، به منظور تحلیل RFM دیده میشود. نرمافزار SPSS به صورت پیشفرض بر روی Total قرار گرفته است.
به این نکته دقت کنید که در فایل دیتا و ستون ID کد مربوط به هر خریدار آمده بود. از آنجا که هر خریدار ممکن است چندین تراکنش داشته باشد، نرمافزار در اینجا از ما سوال میپرسد که کدام آماره را مبنای تحلیل قرار دهم. وقتی به عنوان مثال Total را انتخاب میکنیم به معنای این است که مجموع خرید هر مشتری در تحلیل RFM وارد مطالعه شود. اگر مثلاً Mean را انتخاب کنیم، یعنی میانگین تراکنشهای هر خریدار را در تحلیل قرار بده.
- در نهایت در کادر Customer Identifiers، ستون مربوط به اطلاعات و کدهای هر خریدار را قرار میدهیم.
در تصویر زیر میتوانید نحوه ورود Variable ها به نرمافزار را مشاهده کنید.
-
Binning
در این تب ما به گروهبندی و سطحبندی خریداران بر مبنای شاخصهای RFM یعنی تازگی، فراونی و ارزش پولی میپردازیم.
در حالت کلی، فرآیند گروهبندی تعداد زیادی از مقادیر عددی به تعداد کمی از دستهها، binning نامیده میشود. در تجزیه و تحلیل RFM، گروهها یا همان Binها، دستههای رتبهبندی شده هستند. ما میتوانیم با استفاده از تب Binning روشی را که برای تخصیص شاخصهای تازگی، فراونی و ارزش پولی به Binها استفاده میشود، انتخاب کنبم.
در ادامه بیایید بخشهای مختلف این تب را مرور کنیم. در تصویر زیر آنها را آوردهایم.
تب Binning دارای سه بخش مختلف است و همانگونه که گفتیم از تنظیمات آن جهت انتخاب روش و متد اختصاص سطوح مختلف شاخصهای RFM به هر کدام از خریداران، استفاده میکنیم. هر بخش را توضیح میدهیم.
-
Binning Method
این بخش شامل دو گزینه Nested به معنای تودرتو و Independent به معنای مستقل است.
گزینه Nested از شاخص تازگی و یا همان Recency شروع میکند و بر مبنای این شاخص به هر خریدار یک رتبه اختصاص میدهد. سپس به ازای هر رتبه Recency، رتبه فراوانی یا همان Frequency اختصاص میدهد. در مرحله آخر نیز به ازای هر رتبه Frequency، رتبه پولی یا همان Monetary اختصاص میدهد.
بنابراین نحوه رتبه دادن به هر خریدار، در طول یکدیگر و به صورت تودرتو، قرار دارد. یعنی ابتدا رتبههای تازگی داده میشود، در هر رتبه تازگی، رتبههای فراوانی را میدهیم و در هر رتبه فراوانی، رتبه پولی داده می شود. به صورت پیشفرض نرمافزار SPSS بر روی این گزینه قرار دارد.
در این روش رتبهدهی، ارزش و اهمیت بیشتر به شاخص Recency، در مرحله بعد Frequency و در انتها Monetary داده میشود. یکی از مزایای این روش این است که توزیع یکنواختتری از فراوانی رتبهها در بین خریداران ایجاد میکند.
گزینه Independent به هر شاخص به صورت مستقل از شاخص دیگر نگاه میکند. رتبه اختصاص داده شده به هر خریدار در هر شاخص نیز مستقل از شاخص دیگر داده میشود. معمولا در تعداد نمونههای کم، این روش رتبهدهی، توزیع یکنواخت کمتری بر روی فراوانی رتبهها ایجاد میکند.
-
Number of Bins
در این بخش به سادگی مشخص می کنیم که به ازای هر کدام از شاخصهای RFM یعنی Recency و Frequency و همچنین Monetary، چه تعداد گروه و دسته ایجاد کنیم. به صورت پیشفرض نرمافزار بر روی 5 گروه قرار دارد. در این صورت تعداد کل Binهای ما 75 خواهد بود.
به ازای هر کدام از شاخصها، میتوان بین 2 تا 9 گروه تشکیل داد. یعنی تعداد Binها حداقل میتواند 8 و یا حداکثر 729 باشد.
-
Ties
در این بخش دربارهی رفتار با مقادیر یکسان شاخصهای RFM تصمیم میگیریم. مثلا به تراکنشهایی که همگی در یک روز بوده و یا ارزش پولی آنها همانند بوده است Tie گفته می شود. در این بخش گزینههایی جهت نحوه تحلیل بر روی Tieها داریم. در ادامه آنها را ببینیم.
گزینه Assign ties to the same bin همانگونه که از نام آن برمیآید، Tieها را در Bin یکسان قرار میأهد. به عبارت ساده یعنی در مواردی که اندازه شاخصهای RFM یکسان باشد، به آنها گروههای RFM یکسان و همانند تعلق میگیرد. مثلا اگر تراکنشها در یک روز خاص باشد، برای همه این تراکنشها اندازه Recency Score یکسان خواهیم داشت.
گزینه Randomly assign ties به معنای آن است که در مواردی که ما با Tieها روبهرو هستیم، Binها را صورت تصادفی به آنها اختصاص میدهد. معمولاً از این روش زمانی استفاده میکنیم که تعداد Tieها زیاد باشد. به معنای آنکه ما با تعداد زیادی از تراکنشها با تاریخ، مقدار و فراوانی و ارزش پولی یکسانی روبهرو هستیم.
-
Save
خب حال بیایید درباره تب دیگر یعنی Save صحبت کنیم. در تصویر زیر میتوانید آن را ببینید.
هنگامی که تحلیل RFM از نوع Transaction Data انجام میدهیم، یک فایل دیتا جدید برای ما ایجاد میشود. در این فایل به ازای هر خریدار، اعداد و اندازههای شاخصهای RFM به دست میآید.
ما در تب Save مشخص میکنیم که این فایل جدید، شامل چه اطلاعات و ستونهایی باشد. همچنین تعیین میکنیم که نام و مجل ذخیره این فایل جدید چه و کجا باشد.
حال بیایید ببینیم این فایل جدید شامل چه چیزهایی میتواند باشد.
در گام اول بیان میکنیم که ستون ID که اطلاعات منحصربه فرد و یکتا به ازای هر خریدار دارد، به صورت اتوماتیک در فایل جدید ذخیره میشود. یعنی انتخابی برای آن وجود ندارد و حتماً در فایل جدید تحلیل RFM قرار دارد.
اما میتوانیم سایر گزینهها و ستونها را جهت نمایش در فایل جدید انتخاب کنیم یا انتخاب نکنیم. این اطلاعات شامل موارد زیر است.
-
Date of most recent transaction for each customer
خیلی ساده، ستونی با نام Date_most_recent در فایل جدید ساخته میشود. در این ستون، اطلاعات مربوط به آخرین تراکنش هر خریدار قرار میگیرد.
به این نکته توجه کنید که به سادگی میتوانیم در همین تب Save اسامی Variableهای ساخته شده را به دلخواه خود ویرایش کنیم. برای این کار کافی است بر روی نام Variable دبل کلیک کنید.
-
Number of transactions
ستونی با نام Transaction_count در فایل جدید ساخته میشود. در این ستون مجموع تعداد تراکنشهای هر خریدار قرار میگیرد.
-
Amount
ستونی با نام Amount در فایل جدید ساخته میشود. از آنجا که در تب Variables و در کادر Summary Method، آماره Total را انتخاب کردیم، بنابراین در این ستون، مجموع تراکنشهای هر مشتری به دست میآید.
-
Recency score
ستونی با نام Recency_score در فایل جدید ساخته میشود. امتیازی که بر اساس آخرین تاریخ تراکنش به هر مشتری اختصاص مییابد، در این ستون قرار میگیرد.
این امتیاز عددی از 1 تا تعداد Bin ای است که در تب Binning و در بخش Number of Bins انتخاب کردیم. به عنوان مثال در این متن ما تعداد Bin را عدد 5 قرار دادیم. پس در این ستون امتیازها بین 1 تا 5 به هر مشتری، تعلق میگیرد. نمرات بالاتر نشاندهنده تاریخ تراکنشهای جدیدتر است.
-
Frequency score
ستونی با نام Frequency_score در فایل جدید ساخته میشود. امتیازی که بر اساس تعداد کل تراکنشها به هر مشتری اختصاص مییابد، در این ستون میآید. نمرات بالاتر نشاندهنده تعداد تراکنشهای بیشتر است. در اینجا نیز امتیازات از عدد 1 تا Bin است.
-
Monetary score
ستونی با نام Monetary_score در فایل جدید ساخته میشود. امتیازی که بر اساس آماره انتخاب شده در تب Variables و در کادر Summary Method به ارزش پولی هر مشتری اختصاص مییابد، در این ستون قرار میگیرد. نمرات بالاتر نشان دهنده ارزش پولی بیشتر است. در اینجا نیز امتیازات از عدد 1 تا Bin است.
-
RFM score
ستونی با نام RFM_score در فایل جدید ساخته میشود. اعداد این ستون، اندازهای سه تایی هستند که از به ترتیب کنار هم قرار گرفتن نمرات Recency و Frequency و Monetary به دست میآیند.
نکتهای که وجود دارد این است که به طور پیشفرض همهی گزینههای بالا در فایل داده جدید قرار میگیرند. بنابراین مواردی را که نمیخواهید، لغو انتخاب کنید.
-
Output
در پنجره RFM Analysis from Transaction Data تب دیگری با نام Output دیده میشود. در ادامه دربارهی آن صحبت میکنیم.
همانگونه که در تصویر بالا دیده میشود، تب Output به دو بخش Binned Data و Unbinned Data تفکیک میشود.
-
Binned Data
بخش Binned Data چنانچه از نام آن برمیآید مربوط به دادهها و یافتههای Bin یا همان سطوح و گروههای تشکیلدهنده نمرات شاخصهای RFM است.
در این بخش گزینههایی مانند رسم گراف Heat Map و چارت فراوانی Bin ها قرار دارد. همچنین میتوانیم یک جدول توافقی از Bin ها به دست بیاوریم.
در واقع نتایج این بخش بر روی ستونهای فایل جدید دیتا که پس از تحلیل RFM ایجاد میشود، انجام میگیرد. نام این ستونها را در تب Save به ترتیب Recency_score و Frequency_score و Monetary_score قرار دادیم.
-
UnBinned Data
در بخش Unbinned Data هیستوگرام و نمودار پراکنش برای هر کدام از جفت Variable ها به دست میآید. دقت کنید این نتایج بر روی دادههای Unbinned یعنی تاریخ آخرین تراکنش هر مشتری، مجموع تعداد خریدها و مجموع ارزش پولی خریدها به دست میآید.
در واقع نتایج این بخش بر روی ستونهای فایل جدید دیتا که پس از تحلیل RFM ایجاد میشود، انجام میگیرد. نام این ستونها را در تب Save به ترتیب Date_most_recent و Transaction_count و Amount قرار دادیم.
ما همه این گزینهها را انتخاب کردهایم. در خروجی و نتایج نرمافزار SPSS میتوانیم آنها را مشاهده کرده و درباره آنها بیشتر توضیح دهیم.
خروجیها و نتایج تحلیل RFM
Output RFM Analysis
هنگامی که OK میکنیم، نتایج و خروجیهای نرمافزار در پنجره Output به دست میآید. علاوه بر آن یک فایل دیتا جدید نیز ساخته میشود. همانگونه که در بخشهای بالاتر نیز بیان کردیم، این فایل دیتا به ازای هر مشتری، یافته و اطلاعات تراکنش او را به دست میدهد.
در تصویر زیر میتوانید بخشی از این فایل دیتا را مشاهده کنید.
همانگونه که قبلاً نیز اشاره کردیم، این فایل و ستونهای آن، پس از اجرای آنالیز RFM به دست میآید. اولین نکتهای که در این فایل اهمیت دارد، تعداد سطرها و موارد این فایل است.
به فایل اولیه و دادههایی که بر روی آن آنالیز انجام دادید، نگاه کنید. این فایل شامل 4906 تراکنش بوده است. حال بیایید به فایل جدید ساخته شده بعد از آنالیز RFM نگاه کنید. تعداد سطرهای آن برابر با 995 مورد است.
این اختلاف به دلیل این است که فایل اولیه در هر سطر به یک تراکنش اشاره دارد و فایل ساخته شده در هر سطر به یک خریدار و مشتری می پردازد. از آن جا که هر مشتری چندین تراکنش داشته است، همه تراکنش های او در یک سطر قرار گرفته است.
در تب Save از پنجره تنظیمات RFM Analysis from Transaction Data مشخص کردیم که چه ستونها و اطلاعاتی در این فایل جدید قرار گیرد. حتی نام آنها را نیز تعیین کردیم. نتیجه آن تنظیمات را میتوانید در این فایل مشاهده کنید.
فایل دارای اطلاعات و ستونهایی با نام ID که شماره هر خریدار را مشخص کرده است، تاریخ آخرین خرید، تعداد تراکنشها، ارزش مالی تراکنشها، نمره شاخصهای Recency و Frequency به همراه Monetary و در نهایت RFM Score به ازای هر خریدار است.
همانگونه که قبلاً نیز بیان کردیم نمرات بالاتر در شاخصهای RFM نشاندهندهی خریدهای جدیدتر، تعداد بیشتر خریدها و ارزش پولی بالاتر خریدها میباشد.
به عنوان مثال فردی که RFM Score او برابر با 555 است، بیانگر این است که او در مقایسه با سایر افراد دارای جدیدترین و تازهترین خریدها، بیشترین خرید و بیشترین ارزش مالی است.
فرد دیگری که RFM Score او 551 است، تازگی و فراوانی خرید مشابهی با فرد قبلی دارد اما ارزش مالی خرید او به شدت کمتر از فرد قبلی است.
قابل توجه است که بهترین افراد برای یک شرکت که البته هدف از آنالیز RFM شناسایی همین افراد بود، کسانی هستند که RFM Score آنها برابر با 555 باشد.
به این نکته بسیار مهم توجه کنید که تاکید ما بر روی عدد 5 به دلیل این است که در تب Binning تعداد Bin ها را برابر با 5 در نظر گرفتیم.
حال به فایل Output و خروجیهای نرمافزار نگاه کنید. در تب Output پنجره تنظیمات RFM Analysis from Transaction Data انتخاب کردهایم که چه جداول و گرافهایی را در این فایل میتوانیم مشاهده کنیم.
در ابتدای خروجیها، نموداری با نام RFM Bin Counts دیده میشود.
در این نمودار به ازای هر کدام از شاخصهای Frequency، Recency و Monetary تعداد Binها که همان تعداد گروهها و سطوح هر شاخص بودند، آمده است. بهترین مشتریان افرادی هستند که هر سه شاخص برای آنها عدد 5 و در نتیجه RFM_Score برابر با 555 باشد. این افراد در نمودار بالا با فلش سبز مشخص شدهاند.
بدترین مشتریان نیز که RFM_Score برابر با 111 است، با فلش قرمز رنگ مشخص شدهاند.
گراف بالا در واقع به بیان تعداد و شمارش هر کدام از شاخصها میپردازد. به عنوان مثال کمترین تعداد Bin ها مربوط به Recency با کد 5 (تازهترین خریدارها) و Frequency با کد 4 است. یعنی افرادی که نمره RFM آنها به صورت .54 است.
بیشترین تعداد Bin ها نیز مربوط به Recency با کد 5 (تازهترین خریدارها) و Frequency با کد 3 است. یعنی افرادی که نمره RFM آنها به صورت .53 است.
پس از نمودار RFM Bin Counts جدول با نام Case Processing Summary آمده است.
در این جدول به سادگی توضیح داده شده است که تحلیل بر روی 995 مشتری (مجموع تعداد تراکنش آنها برابر با 4906 بود) انجام شده است. داده Miss وجود نداشته است و همه دادهها موجود بودهاند.
جدول بعدی نیز با نام Frequency score * Monetary score * Recency score Crosstabulation به بیان تعداد در هر Bin میپردازد. این جدول در واقع همان دادههای گراف بالا با نام RFM Bin Counts است. بخشهایی از این جدول را در شکل زیر میتوانید ببینید.
به عنوان مثال به فلش روی تصویر نگاه کنید. عدد 8 بر روی آن نشان میدهد، تعداد افراد با کد یک در شاخص Recency (یعنی قدیمیترین خریدارها) و دارای کد 2 در شاخص Frequency و همچنین کد 2 در شاخص Monetary برابر با هشت نفر بوده است. تعداد Total و مجموع هر کدام از Binها نیز در جدول بالا آمده است.
یک نتیجه و خروجی مفید دیگر در Output نرمافزار SPSS، نمودار و گرافی با نام Heat Map است. این نمودار با شدت و ضعف رنگها به ما در شناسایی بهترین مشتریان و تعداد آنها کمک میکند.
در این نمودار Frequency در محور X و Recency در محور Y قرار دارد. شاخص دیگر RFM یعنی Monetary به عنوان Legend قرار میگیرد.
توجه در نمودار بالا نشان میدهد افرادی که بیشترین فراوانی خرید را داشتهاند، یعنی Frequency Score آنها برابر با 5 بوده و همچنین افرادی که تازهترین خریدها را انجام دادهاند به معنای اینکه Recency Score آنها نیز برابر با 5 بوده است، پُر رنگترین خانهها یعنی بیشترین ارزش پولی (میانگین) را هزینه کردهاند.
در این میان بیشترین رنگ مربوط به خریدارانی است که بیشترین خریدها را هم انجام دادهاند. به این نکته مهم توجه کنید که رنگها بر مبنای آماره میانگین ارزش پولی هزینه شده است و نه مجموع ارزش پولی. گراف Heat Map بالا نشان میدهد افرادی که زیاد خرید میکنند معمولاً خریدهای با قیمت بالا هم انجام میدهند.
نرمافزار SPSS بر مبنای دادههای خام و نه Bin شده، هیستوگرام زیر را نیز به دست میدهد. آن را ببینید.
این گراف با دادههای خام و اصطلاحاً Unbinned Data کار می کند. در این هیستوگرام میتوانید آمارههای میانگین، انحراف معیار و تعداد به ازای هر کدام از شاخصهای RFM را مشاهده کنید.
به عنوان مثال میانگین تاریخ خرید مشتریان، 19 مارس 2006 و انحراف معیار تاریخ خریدها 194.5 روز بوده است. بخش Recency هیستوگرام بالا بیان میکند که تازهترین خریدها دارای تعداد بیشتری نسبت به خریدهای قدیمیتر است.
متوسط تعداد تراکنشها توسط مشتریان 4.93 خرید و انحراف معیار آنها 2.2 بوده است. بخش Frequency هیستوگرام بالا نشان میدهد که خریدهای با فراوانی کمتر، تعداد بیشتری نسبت به خریدهای با فراوانی بیشتر هستند. به زبان ساده یعنی اینکه افراد این مطالعه معمولا تعداد تراکنشهای زیادی نداشتهاند.
میانگین ارزش پولی هزینه شده در این خریدها توسط هر مشتری برابر با 466.5 واحد و انحراف معیار آن 240.6 واحد بوده است. بخش Monetary هیستوگرام نیز نشان میدهد که تعداد تراکنشهای با مبالغ پایین، بیشتر از تعداد تراکنشهای با مبلغ بالا بوده است.
در ادامه نمودارهای پراکنش بین هر کدام از شاخصهای RFM با یکدیگر را مشاهده میکنید.
به عنوان مثال نمودار پراکنش بین Recency و Monetary نشان میدهد افرادی که تازهتر خرید کردهاند، پول بیشتری نیز پرداخت کردهاند.
به همین ترتیب نمودار پراکنش بین Frequency و Monetary نشان میدهد افرادی که تتعداد تراکنشهای بیشتری داشتهاند، پول بیشتری نیز پرداخت کردهاند.
همچنین نمودار پراکنش بین Recency و Frequency نشان میدهد افرادی که تازهتر خرید کردهاند، تعداد خریدها و تراکنشهای بیشتری نیز داشتهاند.
آنچه در این متن بیان شد، آشنایی با تحلیل RFM و شاخصهای آن به همراه نحوه به دست آوردن آنها در نرمافزار SPSS بر روی دادههای تراکنش و یا اصطلاحاً Transaction Data بود.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2021). Direct Marketing, RFM analysis of Transaction Data in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/direct-marketing-rfm-analysis-transaction-data/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2021). Direct Marketing, RFM analysis of Transaction Data in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/direct-marketing-rfm-analysis-transaction-data/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.