بازاریابی، تحلیل خوشه ای Cluster Analysis در نرمافزار SPSS
Cluster Analysis
تحلیل خوشه ای یک ابزار اکتشافی است که به منظور گروهبندی یا خوشهبندی دادهها طراحی شده است. به عنوان مثال، با استفاده از این نوع آنالیز، میتوانید گروههای مختلفی از مشتریان را بر اساس ویژگیهای جمعیتشناختی و شاخصهای خرید، شناسایی کنید.

شرکتهای خردهفروشی و محصولات مصرفی مرتباً از تکنیکهای خوشهبندی و آنالیز خوشه ای برای دادههایی استفاده میکنند که عادات خرید، جنسیت، سن، سطح درآمد و …. مشتریانشان را توصیف میکند.
ملاحظات دادهها
Cluster Analysis data considerations
هنگامی که میخواهیم به آنالیز خوشهای در مطالعات مربوط به بازاریابی و Marketing بپردازیم، لازم است چند نکته کلیدی در شروع و ابتدای کار را بدانیم. در ادامه به اختصار درباره این نکات صحبت کردهایم.
-
Data
تحلیل خوشهای با دادههای پیوسته و دستهبندی شده، کار میکند. هر ردیف نشاندهنده یک مشتری است که باید خوشهبندی شود و ستونها Variableها ویژگیهایی را نشان میدهند که خوشهبندی بر اساس آنها انجام میشود.
-
Record Order
توجه داشته باشید که نتایج ممکن است به ترتیب رکوردها بستگی داشته باشند. برای به حداقل رساندن اثرات ترتیب، ممکن است بخواهید به صورت تصادفی رکوردها را مرتب کنید و تحلیل را چندین بار اجرا کنید، تا درستی و ثبات یک راهحل داده شده را تایید کنید.
-
Measurement Level
تعیین اینکه Variable ما در کدام نوع از سطوح اندازهگیری قرار میگیرد، اهمیت بسیار دارد و بر روی نتایج به دست آمده تاثیر میگذارد.
برای توضیح بیشتر بیان میکنیم که دادهها در سه سطح اندازهگیری به ترتیب زیر قرار میگیرند.
- اسمی Nominal.
زمانی میتوان یک Variable را اسمی تلقی کرد که مقادیر آن، دستههایی را بدون رتبهبندی نشان دهند (مثلاً بخش شرکتی که یک کارمند در آن کار میکند). نمونههایی از کمیت اسمی مانند منطقه، کدپستی و وابستگی مذهبی است.
- رتبهای Ordinal.
زمانی میتوان یک Variable را رتبهای در نظر گرفت که مقادیر آن، دستههایی را با رتبهبندی نشان دهند (به عنوان مثال، سطوح رضایت از خدمات از بسیار ناراضی تا بسیار راضی). نمونههایی از کمیتهای ترتیبی شامل نمرات نگرش است که نشاندهنده درجه رضایت یا اعتماد و امتیازات رتبهبندی ترجیح است.
- پیوسته Continuous.
یک Variable زمانی میتواند به عنوان پیوسته (مستمر) در نظر گرفته شود که مقادیر آن اندازههایی مرتب شده را با یک متریک معنیدار نشان دهند، به طوری که مقایسه فاصله بین اندازهها مناسب و واقعی باشد. نمونههایی از کمیتهای پیوسته شامل سن بر حسب سال و درآمد به هزار دلار است.
مسیر انجام تحلیل خوشهای
مسیر انجام آنالیز خوشهای در نرمافزار SPSS به صورت زیر است.
Analyze→ Direct Marketing (Choose Technique) → Segment my contacts into clusters
حال بیایید در ادامه به بیان مثالی در زمینه تحلیل خوشه ای بپردازیم. فایل این مثال را میتوانید از اینجا دریافت کنیم.
مثال تحلیل خوشهای در مطالعات بازاریابی
بخش بازاریابی یک شرکت میخواهد گروههای جمعیتی را در پایگاه داده مشتریان خود شناسایی کند تا بتواند به تعیین استراتژیهای کمپین بازاریابی و توسعه محصولات جدید کمک کند. این تحلیل بر روی 10000 مشتری انجام شده است.
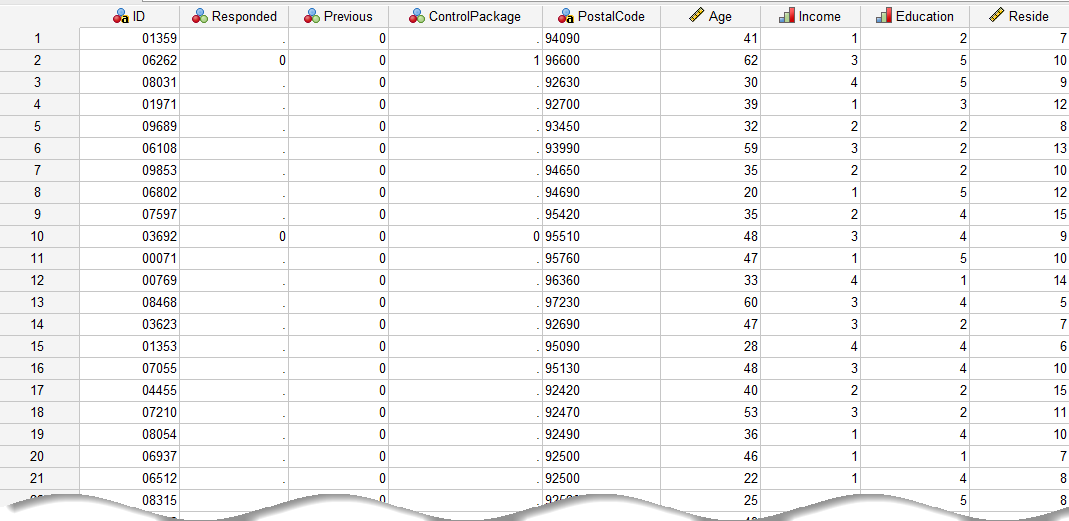
در تصویر زیر میتوانید بخشی از دادهها را مشاهده کنید. ستونی نیز با نام ID که کد شناساگر برای هر مشتری است، در فایل دیتا دیده میشود.
همانگونه که بالاتر گفتیم با استفاده از مسیر زیر، به انجام آنالیز خوشه ای در نرمافزار SPSS میپردازیم.
Analyze→ Direct Marketing (Choose Technique) → Segment my contacts into clusters
پس از رفتن به این مسیر، پنجره RFM Analysis from Customers Data برای ما باز میشود.
تنظیمات نرمافزار
Cluster Analysis
در ادامه به تنظیمات پنجره Cluster Analysis جهت انجام تحلیل خوشه ای و نحوه ورود اطلاعات به نرمافزار SPSS و انتخاب گزینهها صحبت میکنیم. در این پنجره با دو تب روبهرو هستیم، به توضیح هر یک از آنها میپردازیم.
-
Fields
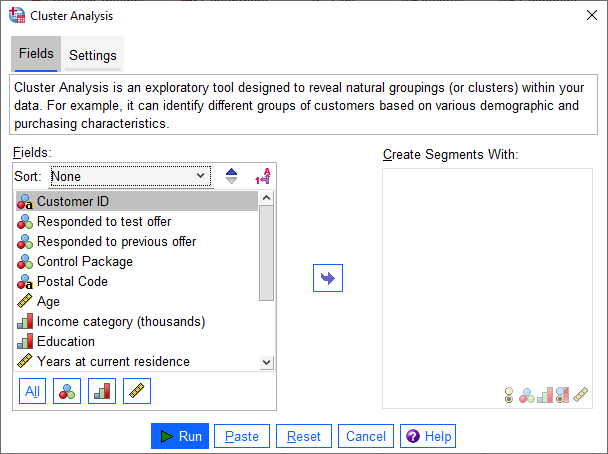
این تب به دو بخش و کادر Fields و Create Segments With تقسیم میشود.
- در کادر Fields اسامی همه ستونها و Variableهای مطالعه آمده است. در این کادر میتوانید Measurement هر کدام از کمیتها را مشاهده کنید. در بالاتر توضیح دادیم که سطح اندازهگیری یا همان Measure کمیت باید به درستی انتخاب شده باشد.
- در کادر دیگر با نام Create Segments With، میتوانیم انتخاب کنیم که گروه، خوشه و یا به قول نرمافزار Segment تشکیل شده بر مبنای کدامیک از Variableهای کادر Fields باشد. در این کادر میتوانیم یک یا چند کمیت را قرار دهیم.
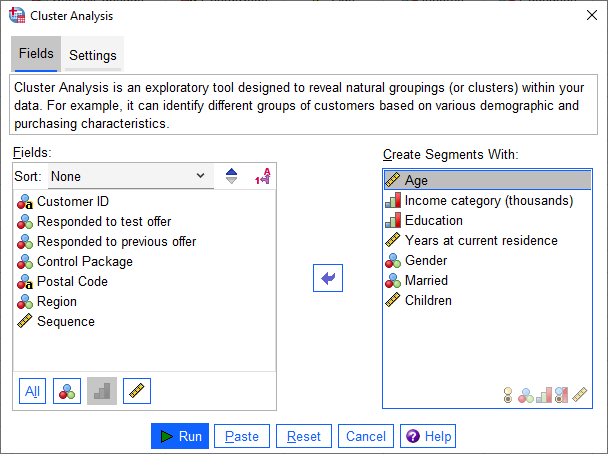
به عنوان مثال ما میخواهیم خوشههای تشکیل شده بر مبنای کمیتهای زیر باشد.
Age, Income category, Education, Years at current residence, Gender, Married, and Children
بنابراین آنها را از کادر Fields به کادر Create Segments With منتقل میکنیم.
در تصویر زیر میتوانید نحوه ورود Variable ها به نرمافزار SPSS را مشاهده کنید.
-
Settings
در پنجره Cluster Analysis تب دیگری با نام Settings دیده میشود. در ادامه دربارهی آن صحبت میکنیم.
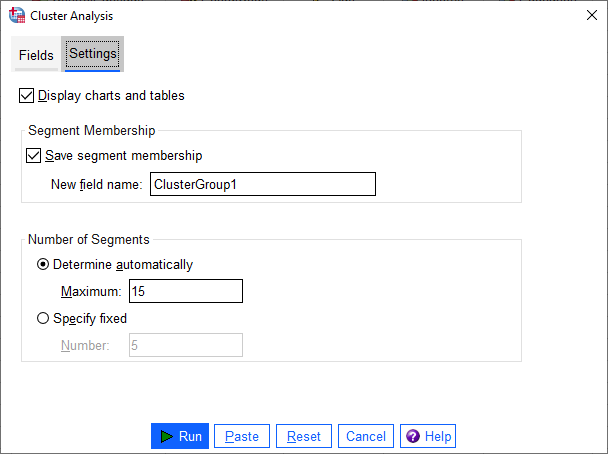
برگه تنظیمات به شما این امکان را میدهد تا بتوانیم نمودارها و جداولی به دست آمده را مشاهده کنیم، یک فیلد جدید در دادهها ذخیره کنید که Segment (خوشه) را برای هر مشتری در مجموعه دادهها مشخص میکند و همچنین مشخص کنید که چه تعداد Segment تشکیل شود.
در ادامه بیایید بخشهای متختلف این تب را توضیح دهیم.
-
Display charts and tables
جداول و نمودارهایی را نمایش میدهد که خوشهها را توصیف میکنند.
-
Segment Membership
یک Variable (فیلد) جدید در فایل دادهها ایجاد میکند و نشان میدهد هر سطر (مشتری) به چه خوشهای Segment تعلق دارد. به سادگی میتوانیم یک نام دلخواه برای این Field جدید انتخاب کنیم.
-
Number of Segments
نحوه تعیین تعداد خوشهها یا همان Segmentها را مشخص میکند.
گزینه Determine automatically به طور خودکار “بهترین” تعداد Segment ها را تا حداکثر تعیین شده، به دست میآورد. نرمافزار SPSS به صورت پیشفرض بر روی این گزینه و بیشترین تعداد خوشه برابر با 15 قرار گرفته است.
گزینه Specify fixed به شما این امکان را میدهد که تعداد مشخص و از قبل تعیین شدهای برای تعداد خوشهها تعیین نمایید.
حال در ادامه با Run کردن تنظیمات و انتخاب Variableها میتوانیم نتایج به دست آمده توسط نرمافزار SPSS را مشاهده کنیم.
نتایج تحلیل خوشهای
Output Cluster Analysis
هنگامی که Run میکنیم، نتایج و خروجیهای نرمافزار در پنجره Output به دست میآید. علاوه بر آن در فایل دیتا، یک ستون و Variable جدید با نام ClusterGroup1 ساخته میشود. همانگونه که در بخشهای بالاتر بیان کردیم، این ستون جدید مشخص میکند هر سطر (مشتری) به کدام خوشه تعلق دارد.
در تصویر زیر میتوانید بخشی از این فایل دیتا را مشاهده کنید.
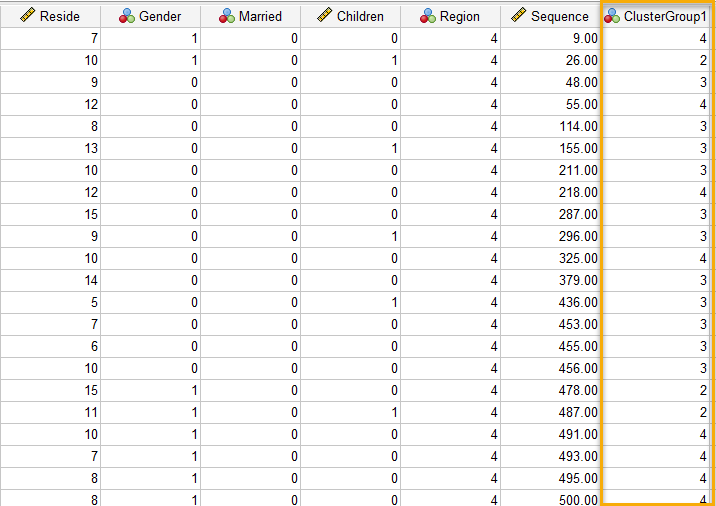
همانگونه که مشاهده میکنید یک ستون با نام ClusterGroup1 به انتهای فایل دیتا اضافه شده است. هر عدد در این ستون نشان میدهد آن سطر یا مشتری به کدام Segment تعلق دارد.
حال به فایل Output و خروجیهای نرمافزار نگاه کنید. نتیجه زیر را میبینیم.
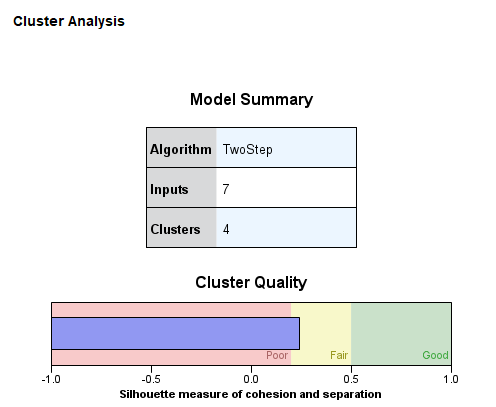
آنچه در نتیجه بالا به دست میآید خلاصهای از تحلیل خوشهای انجام شده است. این نتیجه نشان میدهد براساس 7 ورودی (خاطرتان باشد ما در تب Fields و کادر Create Segments With به تعداد هفت Field و Variable را قرار دادیم.) چهار خوشه یا همان Segment شناسایی شده است.
همچنین نمودار کیفیت خوشه Cluster Quality Chart نشان میدهد کیفیت کلی مدل در محدوده Fair قرار دارد.
حال بر روی نتیجه بالا در پنجره Output دبل کلیک کنید. با انجام این کار پنجره Model Viewer برای ما به صورت زیر باز میشود.

در اینجا و با استفاده از تنظیمات پنجره Model Viewer میتوانید یافتهها و خروجیهای بیشتر و متنوعتری به دست بیاورید و ببینید.
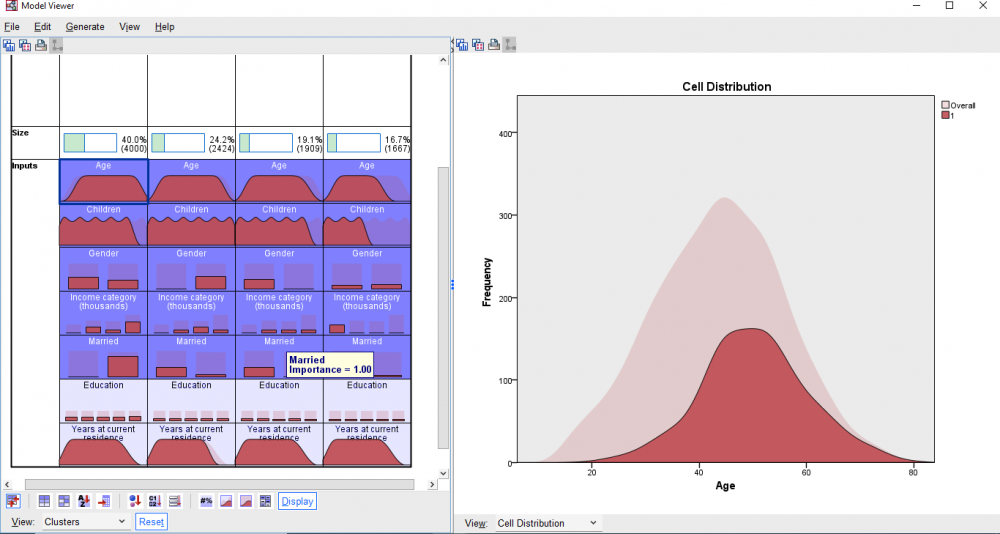
بخش راست پنجره Model Viewer با استفاده از یک نمودار دایرهای، درصد و فراوانی تعداد مشتریان در هر خوشه را نشان میدهد. در جدول پایین نیز اندازه کوچکترین و بزرگترین خوشه به همراه نسبت اندازه بزرگترین به کوچکترین خوشه، آمده است.
به عنوان مثال نتیجه بالا نشان میدهد بزرگترین خوشه (خوشه شماره 1) دارای 4000 مشتری و کوچکترین آنها (خوشه شماره 4) دارای 1667 مشتری است.
حال بیایید سعی کنیم سایر نتایج و تحلیلهایی که در پنجره Model Viewer قابل مشاهده است را ببینیم.
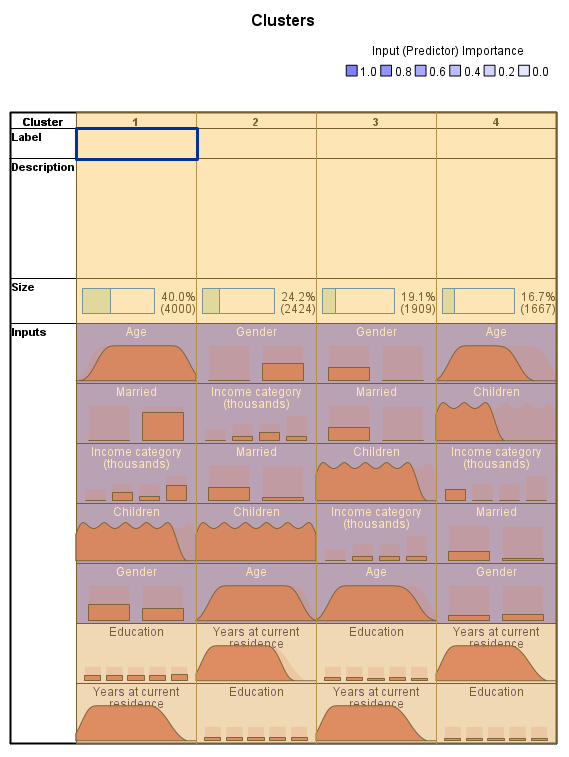
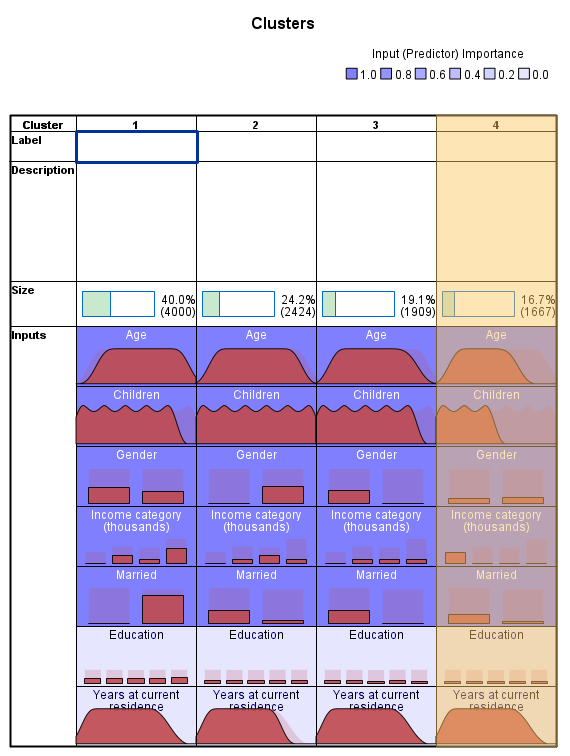
در کادر سمت چپ پنجره Model Viewer و گوشه پایین گزینه View دیده میشود. این گزینه در حال حاضر بر روی Model Summary قرار گرفته است. آن را بر روی Clusters قرار دهید. خروجی و نتیجه زیر به دست میآید.
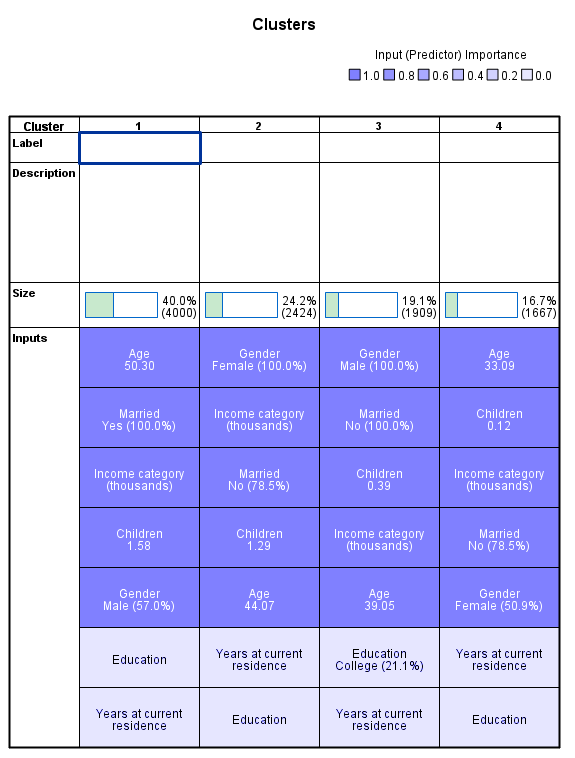
در این جدول آمارههای توصیفی شامل میانگین (برای Variableهای پیوسته) و نما Mode یعنی فراوانی بیشترین رده (برای کمیتهای Ordinal و Nominal) نمایش داده میشود.
در هر خوشه ترتیب قرار گرفتن Fieldها براساس مفهومی به اسم اهمیت Importance میباشد. ترتیب رنگها از پررنگ به کم رنگ نیز همین مفهوم Importance را نشان میدهد.
به عنوان مثال در خوشه شماره 1 که اندازه آن 40 درصد کل مشتریان (4000 نفر) است، بیشترین اهمیت مربوط به فیلد Age با میانگین 50.30 میباشد. پس از آن فیلد Married قرار دارد که در آن همه افراد ازدواج کردهاند.
نما فیلد با نام Income category (thousands) در این خوشه، رده 75+ است که 56.1% مشتریان این خوشه را شامل میشود.
متوسط تعداد فرزندان افراد قرار گرفته در این خوشه 1.58 است و جنسیت 57 درصد افراد این خوشه مرد میباشد.
فیلدهای Education و Years at current residence دارای کمترین اهمیت در تشکیل خوشه شماره 1 هستند. نما فیلد Education در این خوشه، رده تحصیلی Post-graduate با درصد فراوانی 20.5% میباشد. به همین ترتیب میانگین فیلد Years at current residence در خوشه 1 برابر با 9.47 به دست آمده است.
به این ترتیب برای سایر خوشهها میتوانید آمارههای توصیفی شامل میانگین و نما فیلدهای تشکیل دهنده هر خوشه را مشخص کنید.
در انتهای جدول Cluster View گزینهها و آیکونهایی جهت تعیین نحوه نمایش فیلدها قرار داده شده است. به عنوان مثال میتوانید فیلدها را براساس اهمیت درون خوشهای within-cluster importance و یا ترتیب حروف الفبا، مرتب کنید.
همچنین میتوانید در هر فیلد مربوط به هر خوشه، توزیع مطلق Absolute Distribution و یا توزیع نسبی Relative Distribution را مشاهده کنید. گراف زیر را ببینید.
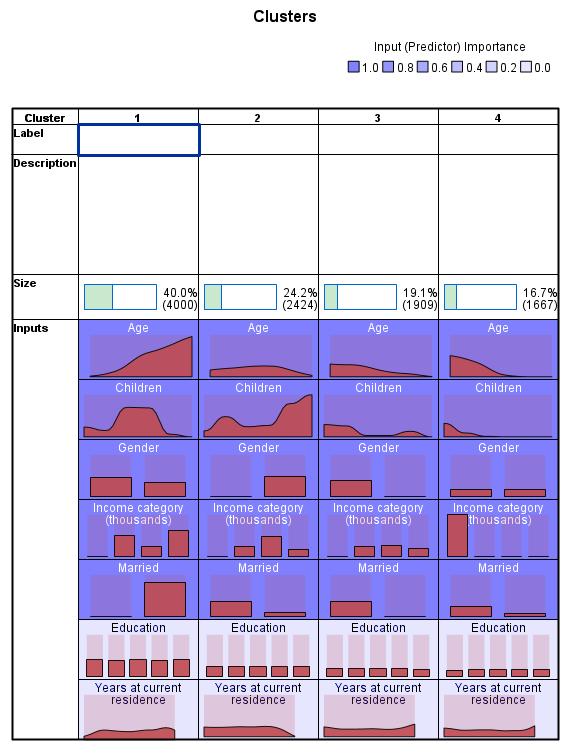
به عنوان مثال و به منظور درک بهتر، جدول Cluster View به صورت Relative Distribution نمایش داده شده است. این نحوه نمایش به خوبی به ما کمک میکند که هم در فیلدهای پیوسته و هم در فیلدهای اسمی و رتبهای، نحوه پراکنش دادهها را مشاهده کنیم.
به منظور نمایش بهتر و خواناتر، اگر بر روی هر سلول (Field) مربوط به یک خوشه خاص کلیک کنید، میتوانید نموداری را ببینید که مقادیر آن فیلد را برای آن خوشه، خلاصه میکند. گراف زیر را ببینید.
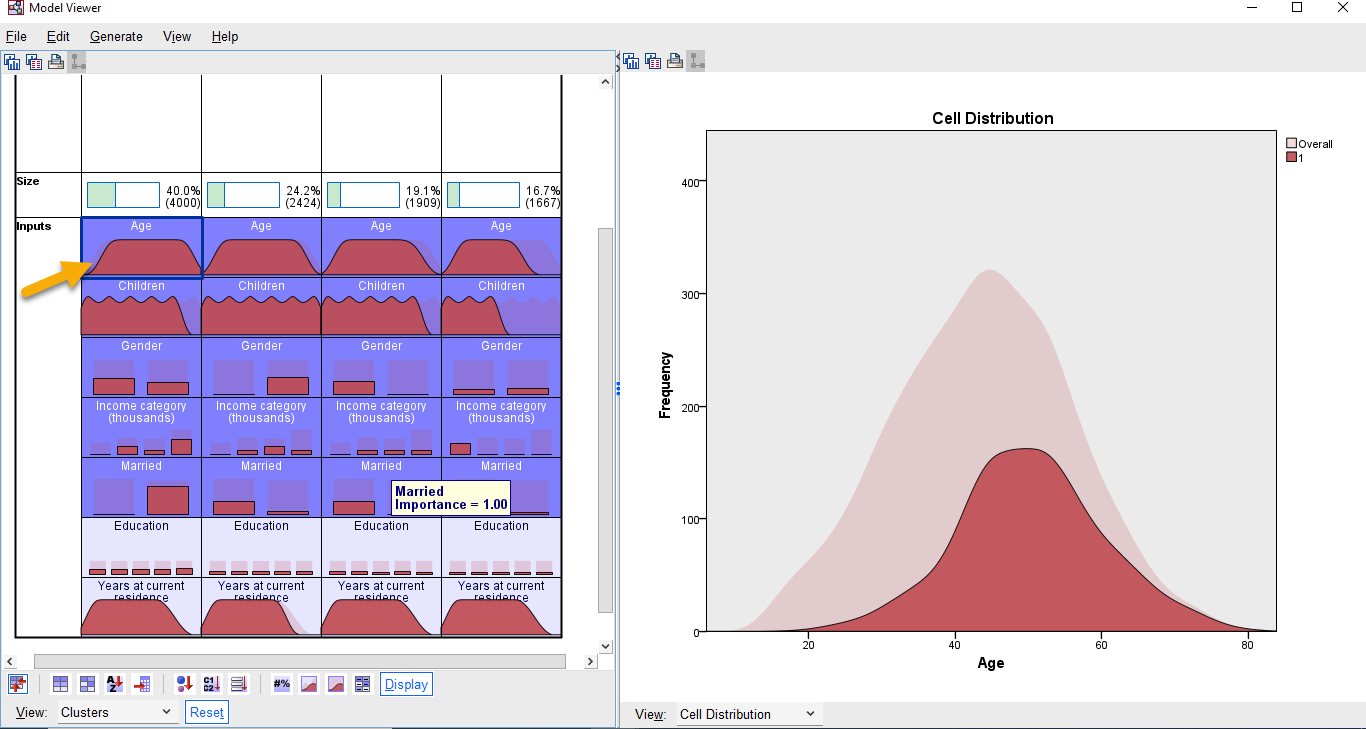
به عنوان مثال در گراف بالا، جدول Cluster View به صورت Absolute Distribution نشان داده شده است. وقتی بر روی هر خانه این جدول کلیک میکنیم، در سمت راست میتوانیم توزیع فراوانی همان خانه را مشاهده کنیم.
گراف توزیع فراوانی در حالت پررنگ، مربوط به همان خانه و در حالت کمرنگ مربوط به کل دادهها میباشد.
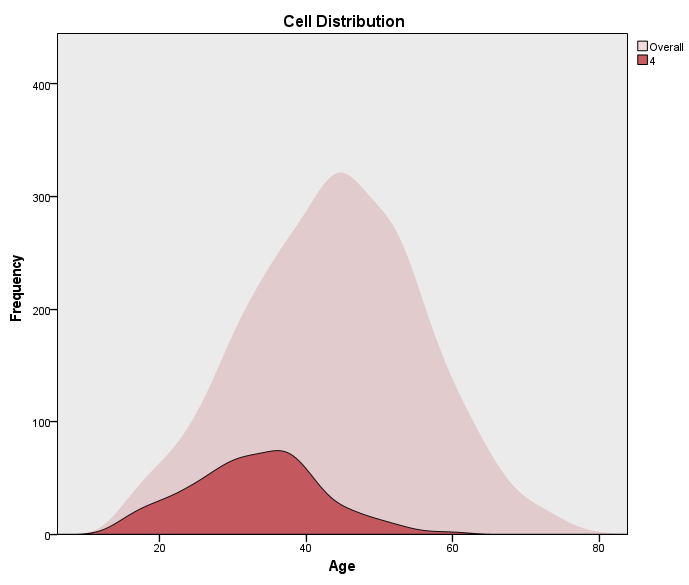
به عنوان مثال گراف توزیع فراوانی بالا، نحوه پراکنش سن افراد در خوشه شماره 1 به همراه توزیع فراوانی سن همه افراد مطالعه را نشان میدهد. اگر همین گراف را برای خوشههای دیگر به دست بیاورید، متوجه این نکته میشوید که مشتریان خوشه 1 در مقایسه با مشتریان سایر خوشهها، مسنتر هستند. افراد خوشه 4 نیز جوانتر به دست میآیند.
مثلاً من در گراف زیر توزیع فراوانی مطلق سن افراد خوشه شماره 4 را آوردهام.
حالتها و خانههای دیگر را نیز خودتان میتوانید مشاهده کنید. مثلاً در گراف زیر توزیع فراوانی فیلد با نام Income category در خوشه شماره 3 آمده است.
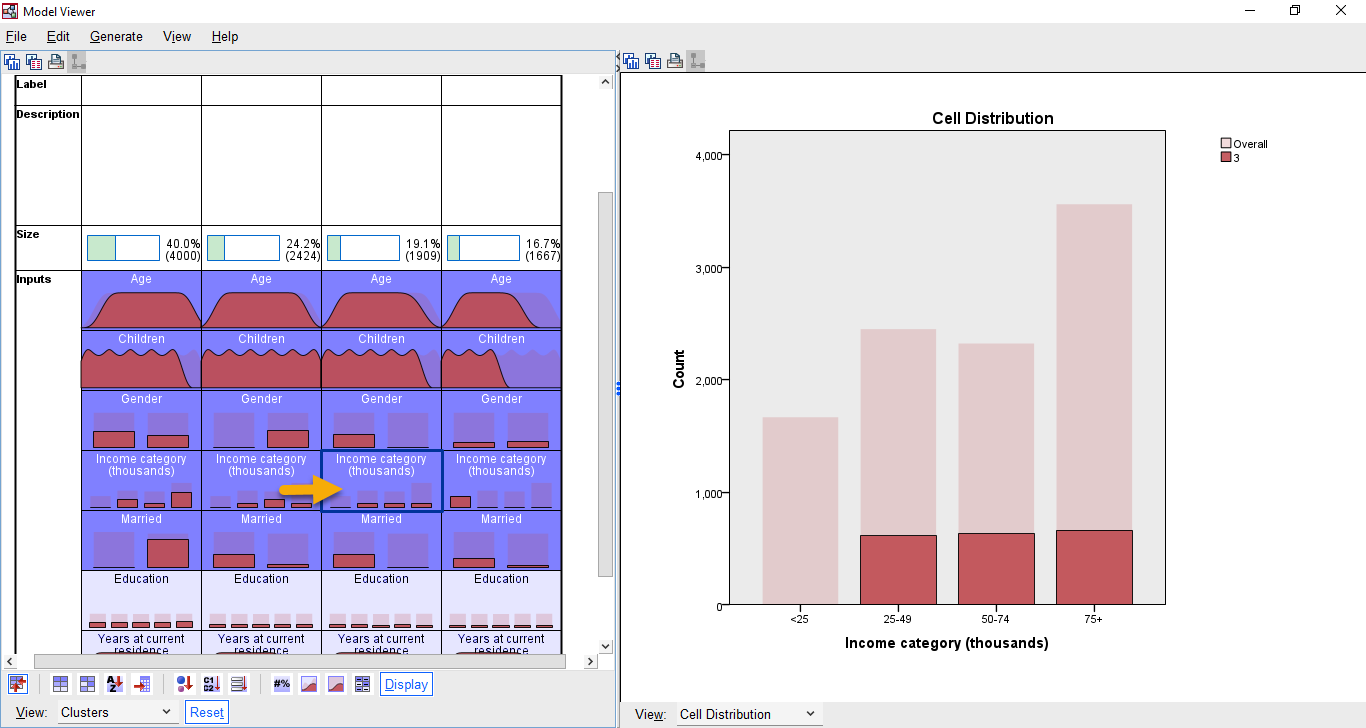
این گراف نشان میدهد فیلد Income category مربوط به خوشه شماره 3 فاقد مشتری در رده <25 است. فراوانی مشتریان در ردههای دیگر نیز تقریباً همانند یکدیگر است، با این حال فراوانی در رده 75+ بیشتر از سایر ردهها مشاهده میشود.
در نمودار میلهای زیر، توزیع فراوانی فیلد Income category خوشه شماره 4 را ببینید.
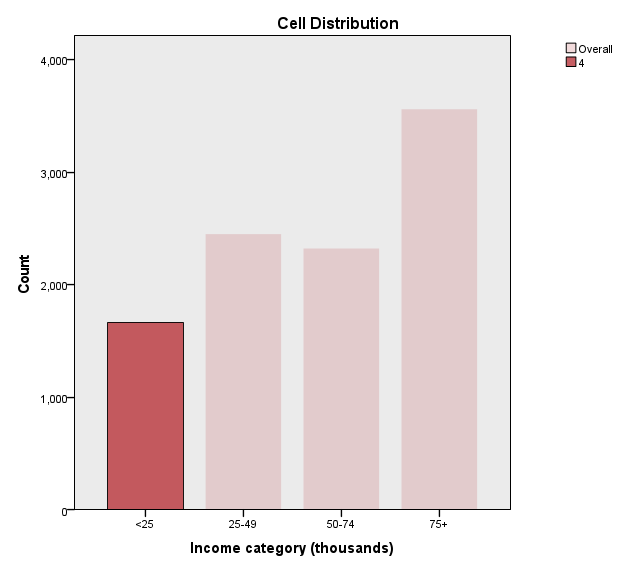
همانگونه که میتوانید مشاهده کنید، همه مشتریان این خوشه که تعداد آنها برابر با 1667 نفر بوده است، در رده <25 قرار گرفتهاند.
به این نکته توجه کنید که برای فیلدهای پیوسته، هیستوگرام Histogram و برای فیلدهای اسمی و یا رتبهای نمودار میلهای Bar Chart رسم میشود.
بر مبنای آنالیز خوشهای انجام شده و همچنین گرافهای Absolute Distribution و Relative Distribution، نتایج زیر برای هر خوشه به دست میآید.
یک نکته دیگر هم اینکه خانههای Description در گرافهای بالا، فیلدهای متنی هستند که میتوانید آنها را ویرایش کنید و توضیحات هر خوشه را در آن بنویسید.
مشاهده ویژگیهای هر خوشه
در متن بالا به بیان ویژگیهای جمعیتی هر خوشه پرداختیم. حال در ادامه میخواهیم این یافتهها را به صورت کلی و همزمان ببینیم. هدف ما این است که دریابیم هر خوشه چه ویژگیهایی دارد و مشتریان هر خوشه چه افرادی هستند.
برای انجام این کار به جدول Cluster View بروید. بر روی شماره خوشهای که میخواهید ویژگیهای آن را ببینید، کلیک کنید. به عنوان مثال ما میخواهیم ویژگیهای افراد موجود در خوشه شماره یک را ببینیم. پس بر روی نام این خوشه کلیک میکنیم.
با انجام این کار در سمت راست پنجره Model Viewer نتایج زیر در قالب گرافهای با نام Cluster Comparison قابل مشاهده خواهد بود.
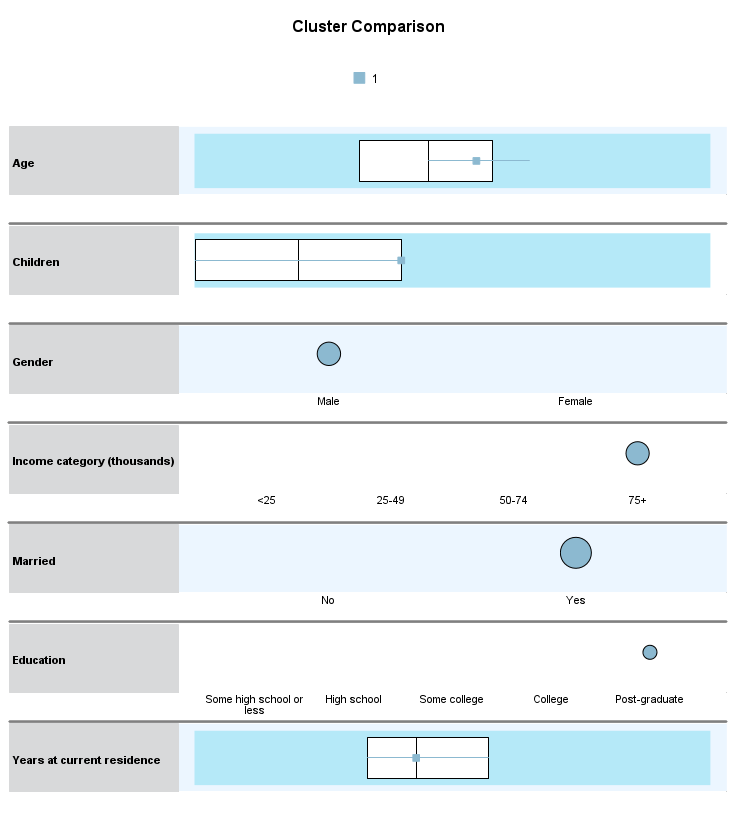
در این گراف، برای کمیتهای پیوسته یعنی Age, Years at current residence, Children نمودار جعبهای شامل میانه، چارک اول و چارک سوم رسم شده است.
برای کمیتهای رتبهای و اسمی یعنی Income category, Education, Gender, Married نیز به ازای بزرگترین فراوانی رده، نمودار دایرهای رسم شده است. هر چه دایره بزرگتر باشد نشان میدهد فراوانی و درصد بیشتری را آن رده در مقایسه با سایر ردهها به خود اختصاص داده است.
چنانچه نشانگر موس را بر روی هر کدام از گرافهای جعبهای یا دایرهای ببرید، میتوانید آمارههای توصیفی آن ویژگی را برای شاخص شماره یک مشاهده کنید.
به عنوان مثال این گراف نشان میدهد همه افراد خوشه شماره یک متاهل هستند، معمولا از قشر پردرآمد افراد هستند و سطح تحصیلات آنها نسبت به سایرین نیز بالاتر است. تعداد فرزندان و سن آنها نیز بالا به دست میآید.
برای سایر خوشهها نیز به سادگی میتوانید این نتایج و گرافها را به دست بیاورید و ببینید.
مقایسه خوشهها
حال بیایید به مقایسه ویژگیهای هر خوشه با یکدیگر بپردازیم. این کار جالب توجه خواهد بود و به ما در درک بهتر نحوه خوشهبندی مشتریان و افراد کمک خواهد کرد.
برای انجام این کار در همان جدول Cluster View با استفاده از دکمه Ctrl بر روی شماره خوشههایی که میخواهید ویژگیهای آنها را با هم مقایسه کنید، کلیک کنید. به عنوان مثال من میخواهم هر چهار خوشه را با هم مورد مقایسه قرار دهم. تصویر زیر را ببینید.
همانگونه که در تصویر بالا مشاهده میکنید، من با استفاده از دکمه Ctrl هر چهار خوشه جدول Cluster View را انتخاب کردهام.
حال در سمت راست پنجره Model Viewer، منوی View را در حالت Cluster Comparison قرار دهید. با انجام این کار گراف زیر که به خوبی به مقایسه ویژگیهای هر خوشه با خوشه دیگر میپردازد، به دست میآید.
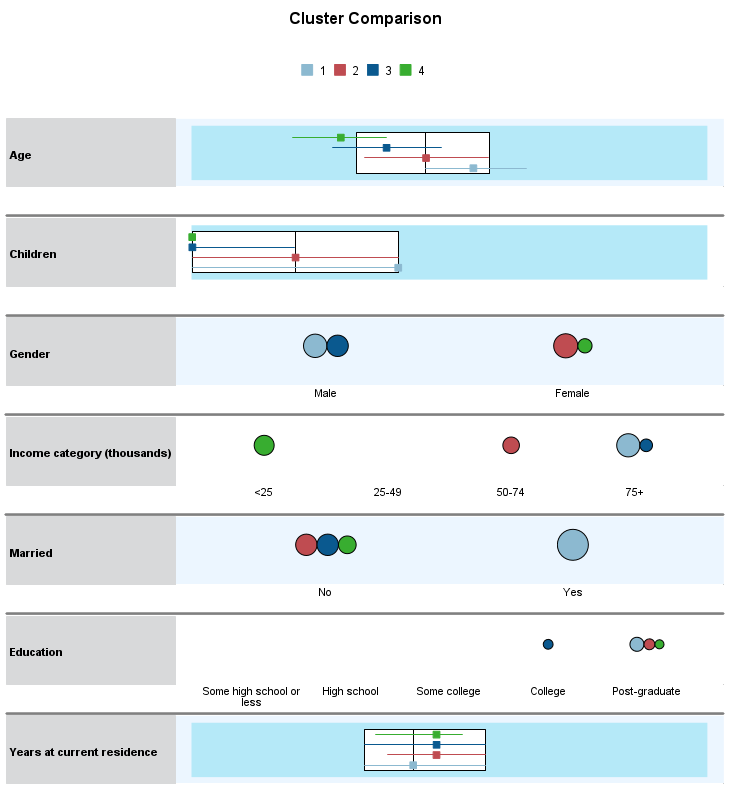
گراف به دست آمده کاملاً گویا است و به خوبی به مقایسه آمارههای توصیفی ویژگیهای هر خوشه با خوشه دیگر میپردازد. به عنوان مثال مشخص میشود سن افراد خوشه یک در مقایسه با سایر خوشهها بیشتر است و مشتریان خوشه چهارم جوانترین افراد هستند.
خوشههای شماره 1 و 3 عمدتاً مرد هستند و افراد خوشه شماره 2 و 4 معمولاً از بین زنان تشکیل شدهاند. افراد خوشه شماره 4 کم درآمدترین افراد هستند و افراد خوشههای شماره 1 و 3 دارای درآمدهای بیشتر.
بقیه یافتهها و نتایج مقایسهای را نیز میتوانید در گراف بالا مشاهده کنید.
انتخاب مشتریان بر مبنای خوشهها
Selecting Records
یکی از کارهای مفیدی که بعد از تحلیل خوشهای میتوان انجام داد، انتخاب مشتریان و یا اصطلاحاً Select Records بر مبنای خوشههای به دست آمده است. منظور این است که ما میخواهیم مثلاً افراد خوشه یک را انتخاب و فقط بر روی آنها تحلیل انجام دهیم. این کار با استفاده از همان جدول Cluster View در خروجیهای نرمافزار قابل انجام است.
مثلاً فرض کنید من میخواهم افراد و مشتریان خوشه چهارم را در فایل دیتا خود انتخاب کنم و بر روی آنها تحلیل انجام دهم.
برای انجام این کار به جدول Cluster View بروید. بر روی شماره خوشهای که میخواهید افراد آن را در فایل دیتا انتخاب کنید، کلیک کنید. اگر میخواهید به صورت همزمان مشتریان دو خوشه را انتخاب کنید، از دکمه Ctrl استفاده کنید.
در مرحله بعد در منوهای همان پنجره Model Viewer، گزینه Generate و از آنجا گزینه Filter records را انتخاب کنید.

با انجام این کار، پنجره زیر برای ما باز میشود.
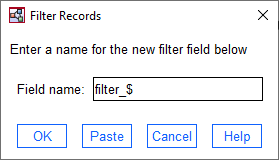
در پنجره Filter Records به سادگی میتوانیم یک نام دلخواه برای ستونی که رکوردها را فیلتر و انتخاب میکند، قرار دهیم. به صورت پیشفرض، نرمافزار نام $_filter را گذاشته است.
در این پنجره OK کنید. حال به فایل دیتا بروید. فایل دیتا به صورت زیر درآمده است.
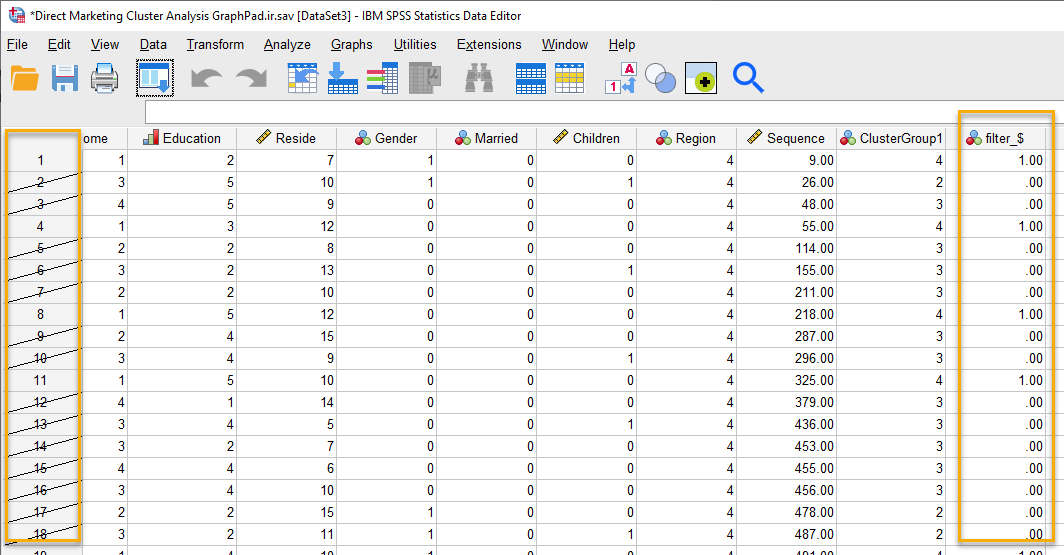
همانگونه که در تصویر بالا میتوانید ببینید، یک ستون جدید با نام $_filter به انتهای فایل دیتا اضافه شده است. این ستون دارای کدهای یک و صفر است. کد یک به معنای این است که آن سطر و رکورد، انتخاب شده است و کد صفر به معنای عدم انتخاب آن سطر است.
از آنجا که ما افراد موجود در خوشه شماره 4 را انتخاب کردیم، افرادی کد یک را دریافت کردهاند که شماره آنها در ستون ClusterGroup برابر با 4 بوده است.
در تصویر بالا بر روی شماره سطرهایی که انتخاب نشدهاند، خط خورده است. سطرهایی نیز که انتخاب شدهاند، فاقد علامت خط خوردگی هستند.
حال از این به بعد اگر بر روی فایل دیتا هر نوع تحلیلی انجام دهیم، آنالیز و تحلیل ما فقط بر روی افراد Select و انتخاب شده (یعنی افراد موجود در خوشه شماره چهار) انجام میشود.
بیان این نکته نیز لازم است که افراد و رکوردهایی که در این نمونه ما انتخاب نشدهاند، از فایل دیتا حذف نشدهاند و همچنان در فایل دیتا وجود دارند. آنها فقط و در حال حاضر از ادامه تحلیل کنار گذاشته شدهاند.
در پایان مطلب اینکه، تحلیل خوشه ای یک ابزار اکتشافی مفید است که میتواند گروهبندیهای کاربردی و موثر را در دادههای شما، آشکار کرده و به دست به دست بیاورد. میتوانید از اطلاعات این خوشهها برای تعیین استراتژیهای کمپین بازاریابی و توسعه محصولات جدید خود استفاده کنید. شما میتوانید مشتریان را بر اساس قرار گرفتن در هر خوشه، به منظور تحلیل بیشتر یا کمپینهای بازاریابی هدفمند، انتخاب کنید.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2021). Direct Marketing, Cluster Analysis in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/direct-marketing-cluster-analysis/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Direct Marketing, Cluster Analysis in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/direct-marketing-cluster-analysis/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.