آلفای کرونباخ Cronbach’s Alpha در تحلیل پایایی پرسشنامه
*** توضیحات تحلیل پایایی پرسشنامه (Reliability) برگرفته شده از کتاب روش های پیشرفته آماری و کاربردهای آن- انتشارات جامعهنگر***
پایایی Reliability یک پرسشنامه به معنای آن است که ابزار اندازهگیری تا چه اندازه نتایج یکسانی به دست میدهد. یعنی اگر پرسشنامه را در یک فاصله زمانی، چندین بار به گروه یکسانی بدهیم، نتایج حاصل تا چه اندازه میتواند مشابه باشد.
این موضوع پذیرفته شده است که نمیتوان انتظار داشت این نتایج به طور کامل یکسان باشد چرا که آزمودنی ما غالباً انسان است که در شرایط محیطی و ذهنی گوناگون میتواند به یک پرسش، پاسخهای نهچندان یکسانی دهد.

پایایی یک اندازه عددی قابل سنجش است. به منظور سنجش پایایی یک پرسشنامه معمولا از دو روش ثبات درونی و دو نیمهسازی استفاده میشود. (هر چند روشهای متنوع دیگری نیز وجود دارد.) ثبات درونی اندازهای است که بیان میکند سوالات موجود در یک پرسشنامه به چه میزان میتواند در یک شاخص خلاصه شده و با یکدیگر همبستگی و ارتباط داشته باشند.
روشهای اندازهگیری پایایی پرسشنامه
بهترین روش محاسبهی اندازه ثبات درونی، استفاده از ضریب آلفای کرونباخ در اندازهگیری پایایی یک پرسشنامه است.
این روش که بر مبنای هماهنگی و سازگاری سوالات پرسشنامه استوار است، از طریق یافتن واریانس هر سوال و واریانس مجموع سوالات به دست میآید. اندازههای پایایی یک پرسشنامه از منفی بینهایت تا یک مثبت میتواند باشد. با اینحال تنها اندازههای مثبت آن قابل تعریف است. اندازه پایایی صفر تا یک مثبت طیفی از عدم قابلیت اعتماد تا قابلیت اعتماد کامل را میپوشاند.
در جدول زیر تفسیر این اندازهها براساس ضریب آلفای کرونباخ آمده است.
|
اندازه عددی آلفای کرونباخ |
ثبات درونی پرسشنامه |
|
بزرگتر از 0.9 |
عالی |
|
بین 0.7 تا 0.9 |
خوب |
|
بین 0.6 تا 0.7 |
قابل قبول |
|
بین 0.5 تا 0.6 |
ضعیف |
|
کمتر از 0.5 |
غیرقابل قبول |
در این متن اموزشی به دنبال آن هستیم با استفاده از نرمافزار SPSS به بیان و توضیح نتایج تحلیل پایایی با استفاده از ضریب آلفا کرونباخ، بپردازیم.
مثال آموزشی تحلیل پایایی پرسشنامه (آلفا کرونباخ)
در یک بررسی به منظور سنجش سطح مدیریت دانش، پرسشنامهای طراحی و از کارکنان سازمان سوالات پرسیده شده است. این پرسشنامه شامل سوالات زیادی بوده است. با این حال من جهت اختصار بخشهایی از سوالات آن را آوردهام.
فایل دیتا این پرسشنامه و نتایج به دست آمده با استفاده از نرمافزار SPSS را میتوانید از اینجا دریافت کنید.
در ابتدای کار میخواهیم اندازهی پایایی این پرسشنامه با استفاده از ضریب آلفا کرونباخ را بسنجیم. به منظور به دست آوردن ضرایب مختلف قابلیت اعتماد و یا همان پایایی از مسیر زیر در نرمافزار SPSS استفاده میکنیم.
Analyze → Scale → Reliability Analysis
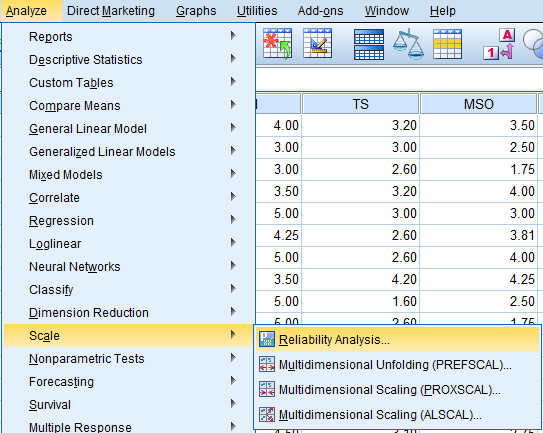
در پنجره Reliability Analysis باز شده، ابتدا کمیتهای پرسشنامه را انتخاب و در کادر Items قرار میدهیم. در بخش Model نیز که به صورت پیشفرض بر روی Alpha قرار دارد، همان را برمیگزینیم.
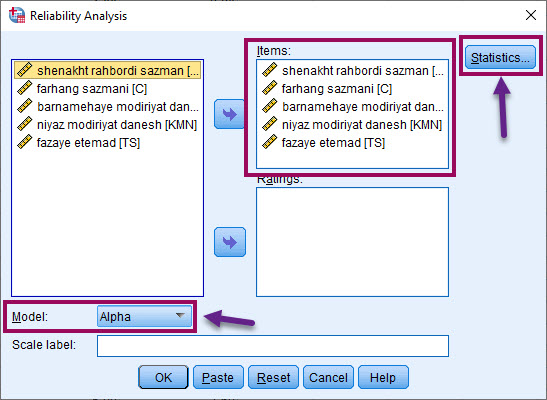
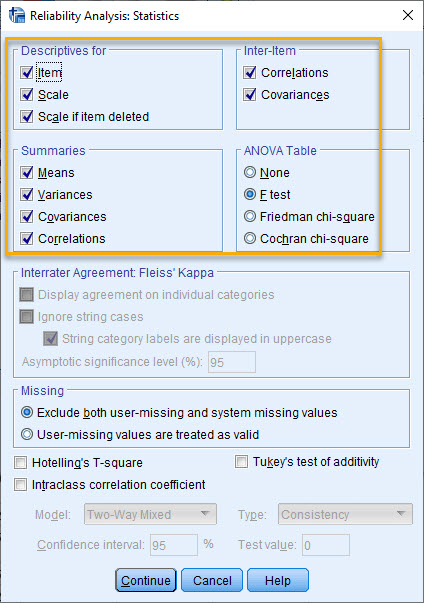
با این حال نکته مهم و تنظیمات بیشتر، در گزینه Statistics قرار دارد. من همه گزینهها در کادرهای Descriptives for جهت نمایش آمارههای توصیفی، Inter-Item جهت مشاهده ماتریس ضرایب همبستگی و کوواریانس، Summaries به منظور مشاهده جدول خلاصهای از میانگین، واریانس، کوواریانس و همبستگیها و همچنین کادر ANOVA Table جهت انجام آزمون آنالیز واریانس و در اینجا F test را انتخاب کردهام.
نتایج و توضیحات بیشتر را در پنجره Output نرمافزار و خروجیهای به دست آمده، بیان خواهیم کرد. حال OK کنید. در ادامه به تفکیک به بیان جداول به دست آمده میپردازیم.
نتایج تحلیل پایایی پرسشنامه
در ابتدا برنامه و Syntax های این تحلیل را مشاهده میکنید. استفاده از Syntax ها و محیط برنامه نویسی SPSS کاملاَ توصیه می شود.
RELIABILITY /VARIABLES=G C KMP KMN TS /SCALE(‘ALL VARIABLES’) ALL /MODEL=ALPHA /STATISTICS=DESCRIPTIVE SCALE CORR ANOVA /SUMMARY=TOTAL MEANS VARIANCE COV CORR
با استفاده از همین چند خط فرمان در محیط Syntax نرم افزار SPSS میتوانیم به سادگی، تحلیل پایایی و ضریب آلفا کرونباخ به همراه سایر جداول و آمارههای مربوطه را به دست بیاوریم.
-
جدول Case Processing Summary
در خروجیهای نرمافزار، ابتدا جدول زیر با نام Case Processing Summary مشاهده می شود.

در این جدول تعداد سطرها و یا همان افراد مورد بررسی، آمده است. مشاهدات بر مبنای تعداد افراد واقعی و تعداد افراد نادیده گرفته شده Excluded تقسیم شده است. در این مثال ۱۷۷ نفر پاسخدهنده وجود داشته است که هیچکدام Missing نبودهاند و همگی در تحلیل قرار گرفتهاند.
-
جدول Reliability Statistics
جدول Reliability Statistics را میتوان مهمترین یافته تحلیل پایایی دانست. نتایج این جدول در ادامه آمده است.
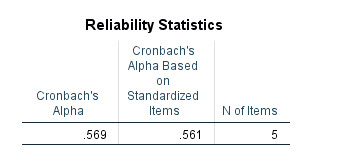
این جدول دارای سه بخش است. Cronbach’s Alpha که عدد آن برابر با ۰.۵۶۹ شده است، همان عدد پایایی مطالعه را نشان میدهد. این اندازه بیانگر پایایی ضعیف دادهها در این مطالعه میباشد.
ستون دیگر با نام Cronbach’s Alpha Based on Standardized Items به میزان پایایی مطالعه پس از استاندارد شدن دادهها اشاره دارد. در اینجا منظور از استاندارد شدن، همان تفاضل هر عدد از میانگین ستون و تقسیم نتیجه به دست آمده بر انحراف معیار ستون، است.
آلفای کرونباخ استاندارد شده در مواردی استفاده میشود که واحدهای اندازهگیری هر آیتم یا ستون، متفاوت از دیگری باشد. در این موارد نتیجه به دست آمده برای Cronbach’s Alpha Based on Standardized Items از نتیجه به دست آمده برای Cronbach’s Alpha معتبرتر و صحیحتر است.
با این حال در مواردی که واحدهای اندازهگیری یکسان هستند، مثلاَ با سوالات یک پرسشنامه با طیف لیکرت روبهرو هستیم، بهتر است از عدد Cronbach’s Alpha استفاده کنیم.
ستون دیگر با نام N of items به سادگی به تعداد سوالات و کمیتهای قرار گرفته در تحلیل پایایی اشاره دارد. در این مثال چون پایایی را بر روی پنج سوال پرسشنامه به دست آوردهایم، بنابراین N of items برابر با ۵ شده است.
-
جدول Item Statistics
فهم جدول Item Statistics بسیار ساده است.

همانگونه که میبینید به ازای هر کدام از سوالات (پنج سوال)، آمارههای توصیفی شامل میانگین، انحراف معیار و تعداد افراد پاسخدهنده به هر سوال، آمده است. به عنوان مثال برای سوالی با نام شناخت راهبردی سازمان، میانگین پاسخ ۱۷۷ نفر، برابر با ۲.۷۲ و انحراف معیار آنها ۰.۸۷۷ شده است.
-
جدول Inter-Item Correlation Matrix
با استفاده از جدول Inter-Item Correlation Matrix به سادگی، ماتریس همبستگی بین سوالات و آیتمهای پرسشنامه را به دست میآوریم.
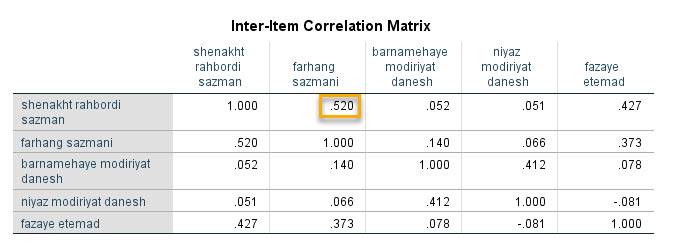
به عنوان مثال، جدول بالا نشان میدهد ضریب همبستگی بین شناخت راهبردی سازمان و فرهنگ سازمانی دارای یک ارتباط مثیت و تقریباَ قوی با یکدیگر هستند. بقیه ضرایب همبستگی بین هر کدام از کمیتها با یکدیگر را نیز میتوانید مشاهده کنید.
-
جدول Inter-Item Covariance Matrix
به همین ترتیب در جدول زیر Inter-Item Covariance Matrix آمده است.
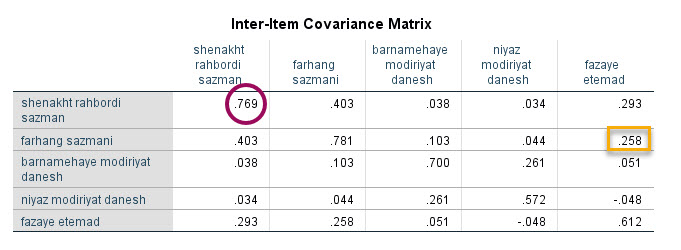
در این جدول اندازه کوواریانس بین آیتمها با یکدیگر آمده است. به عنوان مثال کوواریانس بین فرهنگ سازمانی و فضای اعتماد برابر با ۰.۲۵۸ شده است.
نکتهای که در این میان مهم است، اعداد روی قطر می باشد. این اعداد (به عنوان مثال ۰.۷۶۹ برای شناخت راهبردی سازمان) همان واریانس هر آیتم میباشد. اگر دقت کنید در جدول Item Statistics عدد انحراف معیار برای این آیتم برابر با ۰.۸۷۷ شده است. به سادگی وقتی این عدد را به توان دو میرسانیم (انحراف معیار بتوان دو همان واریانس است.) به عدد ۰.۷۶۹ که بر روی قطر ماتریس کوواریانس قرار دارد، میرسیم. بنابراین به سادگی اعداد روی قطر ماتریس کوواریانس بالا، همان توان دو اعداد انحراف معیار جدول Item Statistics است.
-
جدول Summary Item Statistics
جدول Summary Item Statistics خلاصهای از جداول Item Statistics و Inter-Item Correlation Matrix به همراه Inter-Item Covariance Matrix است.
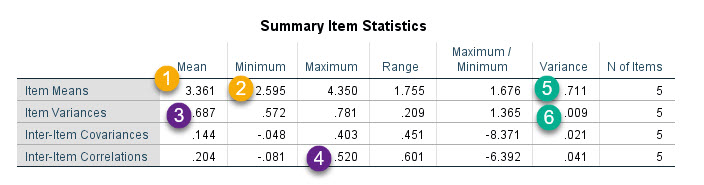
در ادامه به ترتیب شمارهگزاریهای بالا سعی میکنم، درباره جدول Summary Item Statistics صحبت کنم.
- در جدول Item Statistics و در ستون Mean، میانگین هر کدام از آیتمها آمده است. عدد ۳.۳۶۱ به دست آمده در جدول Summary Item Statistics بالا، همان میانگین این میانگینها را نشان میدهد. یعنی اگر از اعداد ستون Mean در جدول Item Statistics میانگین بگیریم، همان عدد ۳.۳۶۱ به دست میآید.
- همان اعداد ستون Mean در جدول Item Statistics را نگاه کنید. کمترین مقدار آنها چقدر است؟ به وضوح ۲.۵۹۵ است. در جدول بالا نیز این عدد به عنوان مینیمم میانگینها آمده است. پس سطر Item Means در جدول Summary Item Statistics بالا، همان آمارههای توصیفی ستون Mean در جدول Item Statistics است. مثلاَ نگاه کنید، بزرگترین عدد میانگین چقدر است؟ ۴.۳۵۰. همین عدد نیز به عنوان ماکزیمم در سطر Item Means آمده است.
- حال سطر Item Variances را ببینید. نتایج این سطر از ستون Std. Deviation جدول Item Statistics میآید. به عنوان مثال عدد 0.687 میانگینِ واریانسهای سوالات پرسشنامه است. یعنی اگر بیاییم ستون Std. Deviation جدول Item Statistics را به توان دو برسانیم تا واریانس آیتمها به دست بیاید، اعدادی که در سطر Item Variances جدول بالا مشاهده میکنید، همان آمارههای توصیفی واریانس آیتمها می باشد. مثلاَ کمترین مقدار این واریانسها عدد ۰.۵۷۲ است که در جدول بالا با نام Minimum آمده است.
- در سطر Inter-Item Correlations آمارههای توصیفی مربوط به ضرایب همبستگی در جدول Inter-Item Correlation Matrix آمده است. به عنوان مثال بزرگترین عدد این جدول ۰.۵۲۰ است که در جدول بالا هم به عنوان Maximum بیان شده است. به عنوان مثالی دیگر، میانگین این ضرایب همبستگی برابر با ۰.۲۰۴ است.
- عدد 0.711 در ستون Variance جدول بالا، بیانگر واریانس همان میانگینهای جدول Item Statistics است. یعنی اگر بیاییم از سوالات میانگین بگیریم و برای هر آیتم، میانگین به دست بیاوریم، سپس از این اعداد میانگینها، واریانس به دست آوریم، این واریانس برابر با ۰.۷۱۱ خواهد بود.
- به همین ترتیب اگر بیاییم انحراف معیارهای هر آیتم (ستون Std. Deviation جدول Item Statistics) را به توان دو برسانیم و آنها را به واریانس هر آیتم تبدیل کنیم، و از این اعداد واریانسها دوباره واریانس بگیریم، عدد واریانسِ واریانسها برابر با ۰.۰۰۹ خواهد بود.
-
جدول Item-Total Statistics
یکی از مهمترین نتایج و جدولهای مرتبط با تحلیل پایایی همین جدول Item-Total Statistics است. این جدول سعی میکند به پرسشنامه به عنوان یک کل نگاه کند و به جای بررسی هر آیتم یا سوال، کلیت پرسشنامه را مورد بررسی قرار دهد. در ادامه این جدول را مشاهده میکنید.

به دلیل اهمیت این جدول، سعی میکنیم همه ستونهای آن را به صورت جداگانه بیان کنم.
Scale Mean if Item Deleted
به منظور فهم این ستون، فرض کنید در دادهها ستون جدیدی میسازیم با نام Sum. این ستون در واقع مجموع اعداد سوالات دیگر است. به تصویر زیر نگاه کنید.
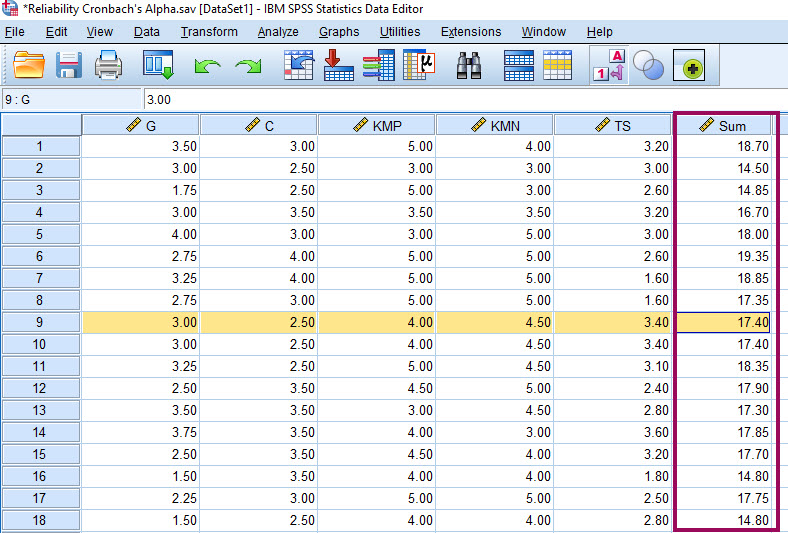
به عنوان مثال در سطر نهم، مجموع سوالات از ۱ تا ۵، برابر با ۱۷.۴۰ شده است. به همین ترتیب برای هر فرد، عددی به دست آمده است که مجموع سایر سوالات است. جدول Item-Total Statistics بر روی این ستون (Sum) تحلیل و نتایج خود را ارایه میدهد.
حال بهتر میتوان درباره ستون Scale Mean if Item Deleted حرف زد. همانگونه که از نام این ستون برمیآید، این ستون به معنای میانگین ستون Sum در دادههاست، وقتی که یک آیتم خاص حذف شده است.
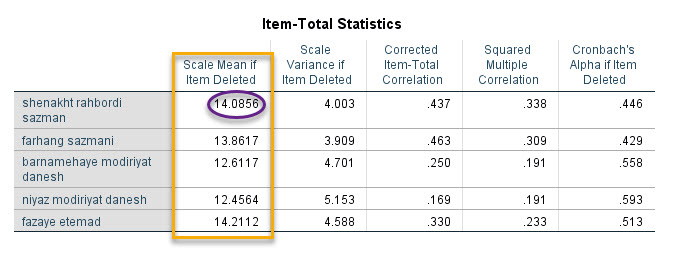
به عنوان مثال عدد 14.08 در ستون Scale Mean if Item Deleted و برای آیتم شناخت راهبردی سازمان را ببینید. این عدد نشان میدهد اگر آیتم شناخت راهبردی سازمان از ستون Sum در دادهها حذف شود، میانگین ستون Sum برابر با ۱۴.۰۸ خواهد بود. به همین ترتیب اگر آیتم فرهنگ سازمانی از دادههای Sum حذف شود، میانگین این ستون برابر با ۱۳.۸۶ خواهد بود.
به این ترتیب هر عدد Scale Mean if Item Deleted در جلوی هر آیتم، به معنای میانگین ستون Sum است وقتی آن آیتم حذف شود.
Scale Variance if Item Deleted
با فهم ستون Scale Mean if Item Deleted، درک ستون Scale Variance if Item Deleted ساده خواهد بود. در واقع هر عدد مقابل یک آیتم خاص در این ستون بیانگر واریانس ستون Sum میباشد وقتی که آن آیتم خاص حذف می شود.

به عنوان مثال عدد ۳.۹۰۹ نشان میدهد اگر سوال فرهنگ سازمانی حدف شود، آنگاه واریانس دادههای باقیمانده در ستون Sum (مجموع چهار سوال دیگر) برابر با ۳.۹۰۹ خواهد بود. به عنوان مثال دیگر عدد ۵.۱۵۳ بیان میکند که اگر آیتم نیاز مدیریت دانش حذف شود، دادههای باقیمانده Sum دارای واریانس برابر با ۵.۱۵۳ هستند.
Corrected Item-Total Correlation
ستون Corrected Item-Total Correlation به اندازه ارتباط و همبستگی بین هر آینم با مجموع آیتمهای دیگر میپردازد.
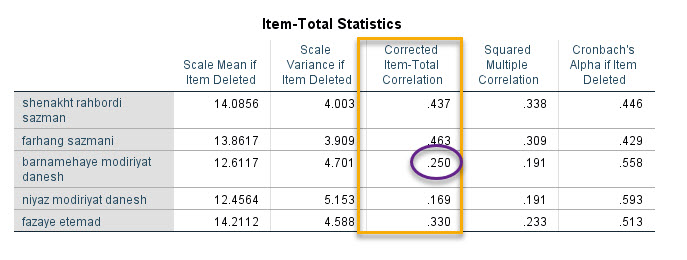
به عنوان مثال اگر در همان ستون Sum که گفتیم مجموع تمام سوالات و آیتمهای پرسشنامه است، سوال برنامههای مدیریت دانش را حذف کنیم و سپس بین دادههای باقیمانده و همین آینم برنامههای مدیریت دانش، ضریب همبستگی (پیرسن) به دست بیاوریم، عدد حاصل برابر با ۰.۲۵۰ خواهد بود.
پس در واقع Corrected Item-Total Correlation در هر آیتم به معنای ضریب همبستگی بین آن آینم با مجموع سایر سوالات میباشد.
Squared Multiple Correlation
ستون Squared Multiple Correlation شامل اطلاعات جالبی است. مثلاَ فرض کنید میخواهیم بدانیم عدد ۰.۳۳۸ به چه معنا است.
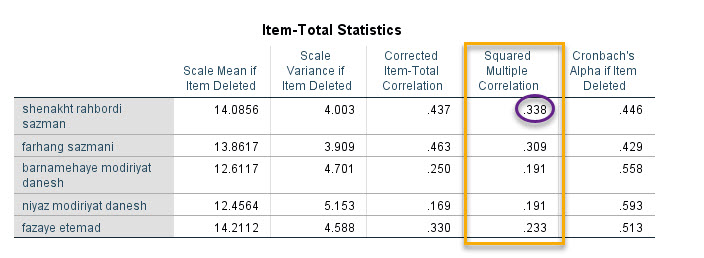
برای فهمیدن این عدد و سایر اعداد ستون Squared Multiple Correlation بیایید یک مدل رگرسیون خطی بین شناخت راهبردی سازمان به عنوان Dependent Variable و سایر کمیتها (یعنی چهار سطر دیگر) به عنوان Independent Variable ایجاد کنیم.
نتیجه به دست آمده از این مدل رگرسیونی در ادامه آمده است.
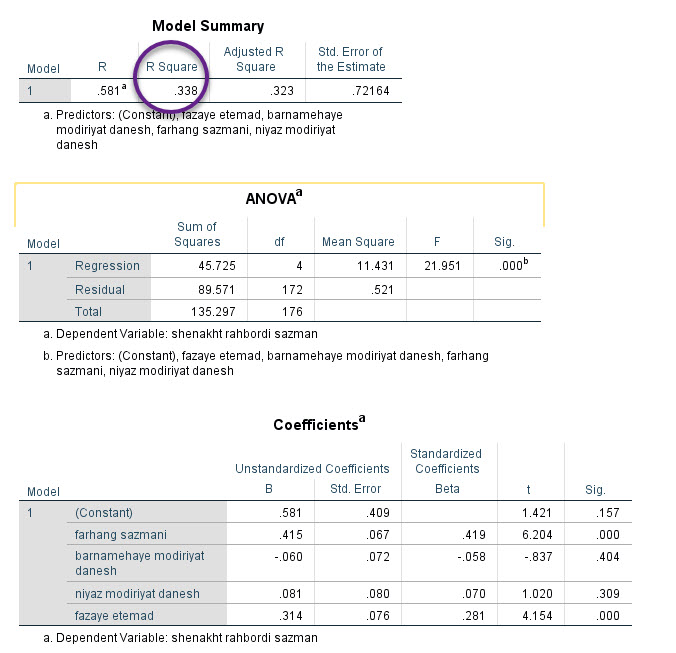
چنانچه به تصویر بالا دقت کنید، مقدار ضریب تعیین و یا همان R Square مشخص شده است. ببینید عدد آن چقدر است؟ ۰.۳۳۸. یعنی دقیقاَ همان مقداری که در ستون Squared Multiple Correlation مشاهده کردیم.
بنابراین به سادگی مشخص میشود اعداد ستون Squared Multiple Correlation که در جلوی هر کمیت یا نام سوال نوشته شده، در واقع همان R Square یک مدل رگرسیونی هستند. هنگامی که آن کمیت به عنوان Dependent Variable و سایر کمیتها (یعنی چهار سطر دیگر) به عنوان Independent Variable در نظر گرفته میشوند.
Cronbach’s Alpha if Item Deleted
ستون Cronbach’s Alpha if Item Deleted به سادگی به معنای آن است که با حذف هر کدام از سوالات یا آیتمها، اندازه عددی آلفای کرونباخ چقدر خواهد بود.
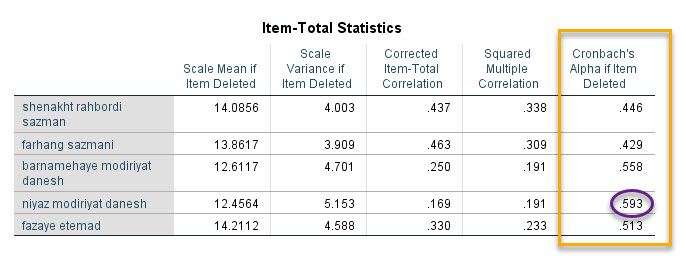
به عنوان مثال به عدد ۰.۵۹۳ در تصویر بالا نگاه کنید. این عدد نشان میدهد اگر آیتم نیاز مدیریت دانش را از مطالعه حذف کنیم، در آن صورت ضریب آلفای کرونباخ سایر آیتمها برابر با ۰.۵۹۳ خواهد بود. به این نکته دقت کنید که آلفا کرونباخ تمام سوالات برابر با ۰.۵۶۹ شده بود. بنابراین حذف این آیتم میتواند پایایی را بهبود ببخشد.
-
جدول Scale Statistics
این جدول به وضوح اطلاعاتی درباره همان ستون Sum که در بالاتر به آن اشاره کردم، به ما میدهد. ستون Sum در واقع مجموع سایر آیتمها بود.
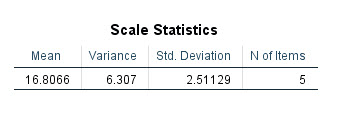
به عنوان مثال میانگین ستون Sum، برابر با ۱۶.۸۰۶ و واریانس آن ۶.۳۰۷ شده است.
-
جدول ANOVA
نتایج این جدول در واقع همان آنالیز واریانس معروف است، وقتی که میخواهیم میانگین آیتمها را با هم مقایسه کنیم. همچنین آماره دیگری با نام Grand Mean در این جدول دیده می شود.
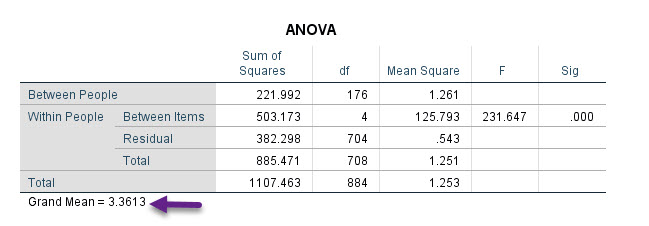
نتایج آنالیز واریانس نشان میدهد، میانگین آیتمها با یکدیگر اختلاف معنادار دارد (P-value < 0.001). منظور از Grand Mean نیز میانگین کل سوالات پرسشنامه میباشد..
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2021). Cronbach’s Alpha in the reliability analysis of the questionnaire using SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/cronbach-alpha-reliability/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2021). Cronbach’s Alpha in the reliability analysis of the questionnaire using SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/cronbach-alpha-reliability/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.