خوشه بندی دادهها (Clustering) در نرمافزار SPSS
هدف از خوشه بندی دادهها آن است که مشاهدات را در گروههای متجانس تقسیم کنیم، به گونهای که مشاهدات هر گروه، بیشترین شباهت و مشاهدات گروههای مختلف، کمترین شباهت را با هم داشته باشند.
در این آموزش به چگونگی انجام تحلیل خوشه بندی با استفاده از نرمافزار SPSS میپردازیم.

در یک بررسی به منظور سنجش میزان درآمد کارکنان یک شرکت، میخواهیم کمیت حقوق آنها را در چند گروه خوشه بندی کنیم. فایل داده این آموزش را میتوانید از اینجا Employee data دریافت کنید.
ابتدا از مسیر زیر در نرمافزار SPSS استفاده میکنیم.
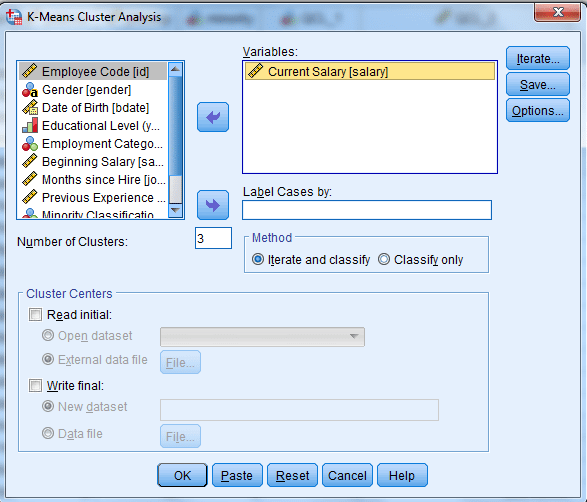
Analyze → Classify → K-Means Cluster
در پنجره باز شده کمیت salary را انتخاب و در کادر Variables قرار دهید.
چنانچه میخواهید کمیتهای دیگری را نیز خوشه بندی کنید، میتوانید بیش از یک کمیت را در این کادر قرار دهید.
در کادر Number of Cluster تعداد گروههای خوشهبندی خود را وارد کنید. مثلاً ما میخواهیم سه گروه از کمیت salary داشته باشیم. پس عدد 3 را وارد میکنیم.
در کادر Method نیز گزینه Iterate and classify را انتخاب کنید.
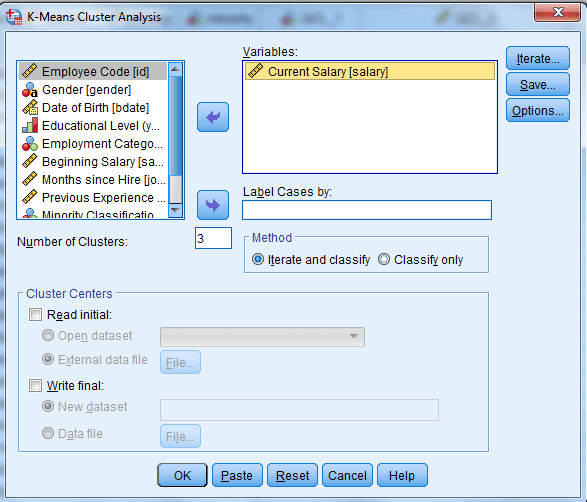
تنظیمات و گزینههای خوشه بندی دادهها
با کلیک بر دکمه Options پنجره زیر باز میشود.
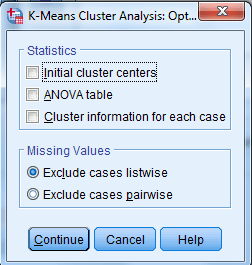
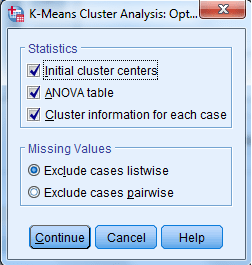
فعال کردن گزینه Initial cluster centers سبب میشود که جدول مقادیر اولیه مرکز هر خوشه تشکیل و نتایج در خروجی نرمافزار دیده شود.
انتخاب گزینه ANOVA table جدول تجزیه واریانس و آزمون آنالیز واریانس را به دست میدهد. در این آنالیز گروههای خوشه بندی با یکدیگر آزمون میشوند.
انتخاب گزینه Cluster information for each case سبب میشود که برای هر یک از سطرها، شماره خوشهای که به آن تعلق دارد و نیز فاصله آن تا مرکز خوشه به دست بیاید.
تنظیمات گزینه Save در آنالیز خوشهبندی
با کلیک بر دکمه Save کادر زیر باز خواهد شد.
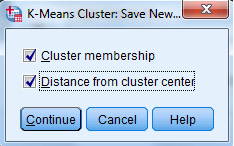
انتخاب گزینه Cluster membership کمیت جدیدی با نام qcl_1 به فایل داده اضافه میکند که در آن شماره خوشه متعلق به هر سطر نشان داده میشود. خوبی این کمیت این است که به سادگی و با یک sort کردن دادهها معلوم میشود چه تعداد و کدام موارد و سطرها در هر خوشه قرار گرفتهاند.
انتخاب گزینه Distance from cluster center کمیت جدیدی با نام qcl_2 به فایل داده اضافه میکند که در آن فاصله هر مورد با مرکز خوشهای که به آن تعلق دارد، مشخص میشود.
فرایند خوشه بندی دادهها با انجام عملیات تکرار انجام میشود. در دکمه Iterate تنظیمات میتوانید تعداد تکرارها تا رسیدن به خوشه مناسب را انتخاب کنید.
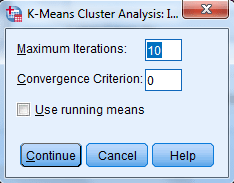
در پنجره Iterate گزینه Maximum Iteration ماکزیمم تعداد دفعات الگوریتم تکرار برای محاسبه مرکز خوشهها را تعیین میکند. به طور پیشفرض بر روی عدد 10 است به معنای آنکه الگوریتم تکرار حداکثر ده بار اجرا میشود.
گزینه Convergence Criterion نیز معیار همگرایی تکرارها برای رسیدن به خوشه مناسب را تعیین میکند. به عنوان مثال اگر عدد 0.01 را در این کادر وارد کنیم، آنگاه الگوریتم محاسبه مرکز خوشهها تا زمانی که اندازه فاصله مرکز بیش از 0.01 باشد، تکرار خواهد شد.
حالا OK کنید. خروجی نتایج به صورت زیر دیده میشود.
تحلیل نتایج خوشهبندی دادهها (Clustering)
با انجام تنظیمات بالا، نتایج زیر به دست میآید.
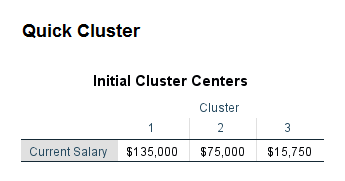
همانگونه که مشاهده میشود برای کمیت salary سه خوشه تشکیل شده است. در جدول Initial Cluster Centers مرکز اولیه هر سه خوشه قابل مشاهده است.
جدول بعدی با نام Iteration History اندازه Change در مرکز خوشهها را در 8 مرحله از الگوریتم تکرار تا رسیدن به معیار همگرایی انتخاب شده در دکمه Iterate تنظیمات، یعنی 0 نشان میدهد.
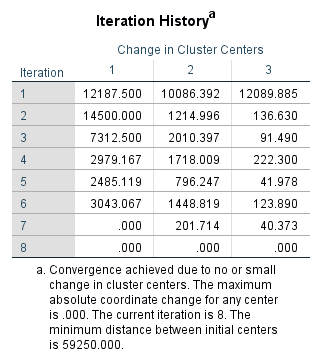
همانگونه که در نتایج این جدول دیده میشود، نرمافزار با 8 بار تکرار الگوریتم توانسته است به خوشههایی دست یابد که معیار همگرایی صفر را پذیرفتهاند. اعداد جدول نشان میدهد به ازای هر بار تکرار اندازه مرکز هر سه خوشه چقدر Change شده است.
در جدول بعدی شماره خوشه هر سطر و فاصله آن با مرکز خوشه به دست آمده است.
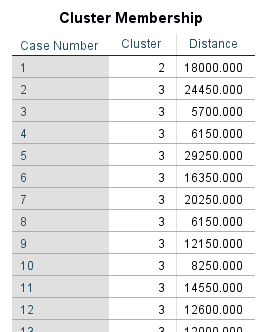
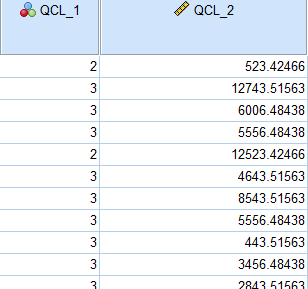
البته همانگونه که در دکمه Save تنظیمات خوشه بندی عنوان کردیم، در فایل داده دو ستون جدید که شماره خوشه و فاصله تا مرکز را نشان میدهند، با نامهای qcl_1 و qcl_2 ایجاد شده است.
نتایج پس از الگوریتم تکرار خوشهبندی
در جدول Final Cluster Centers مرکز خوشهها در آخرین تکرار نمایش داده شده است.
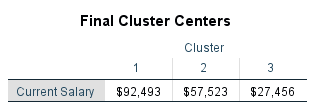
میتوانید این جدول را با جدول Initial Cluster Centers مقایسه کنید. میبینید که پس از طی شدن الگوریتم تکرار، مرکز خوشهها به یکدیگر نزدیکتر شده است.
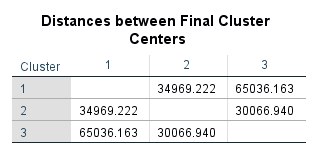
جدول بعدی با نام Distances between Final Cluster Centers فاصله مرکز هر خوشه پس از آخرین مرحله الگوریتم تکرار، با خوشه دیگر را نشان میدهد.
از آنجا که میتوان اعضای هر خوشه را نمونهای از یک جمعیت در نظر گرفت، بنابراین با استفاده از آزمون انالیز واریانس به سادگی میتوان وجود اختلاف معنادار بین خوشهها را بررسی کرد.
نتایج در جدول ANOVA آمده است.

مقدار Sig سطح معناداری آزمون را نشان میدهد. از آنجایی که این مقدار بسیار کوچک است (P-value<0.001) بنابراین فرض همانند بودن خوشهها را رد میکنیم. به معنای دیگر اینکه ما با سه خوشه متفاوت از یکدیگر روبهرو هستیم.
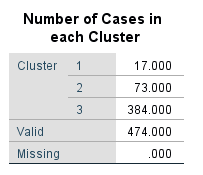
جدول بعدی با نام Number of Cases in each Cluster تعداد موردهای هر خوشه را پس از آخرین مرحله الگوریتم تکرار نشان میدهد.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). Clustering data in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/clustering-analysis-with-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). Clustering data in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/clustering-analysis-with-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.