مثال آموزشی Repeated Measures one-way ANOVA با گراف پد
همانگونه که میدانیم هنگامی که بخواهیم بیشتر از دو گروه را با یکدیگر مورد مقایسه قرار دهیم از تحلیلهای ANOVA استفاده میکنیم. نرمافزار گراف پد تحلیلهای ANOVA را در دو دسته Ordinary و Repeated Measure قرار میدهد. تحلیل Ordinary زمانی استفاده میشود که گروهها از یکدیگر مستقل باشند. در واقع این نوع آزمون تعمیم یافته آزمون T Test Unpaired است.
تحلیل Repeated Measure و یا همان اندازه گیری مکرر نیز به منظور مقایسه گروههای به هم وابسته و در زمانهای مختلف اندازهگیری شده، استفاده میشود. این نوع آزمون تعمیم یافته آزمون T Test Paired است.
ما در این آموزش قصد داریم درباره آزمونهای ANOVA از نوع Repeated Measure صحبت کنیم. تحلیل ANOVA از نوع Ordinary را میتوانید از اینجا مشاهده کنید. نرمافزار گراف پد، امکانات خوبی جهت انجام فرایند مقایسه بین گروهی چه به صورت ساده و یا پیشرفته، فراهم کرده است.
در مثال زیر با استفاده از نرمافزار گراف پد پریسم، به دنبال مقایسه بین چند گروه وابسته هستیم. در این مثال میخواهیم فرض برابری یا عدم برابری میانگین بین گروههای مختلف را آزمون کرده، مقدار احتمال آزمون را به دست آورده و از چند نمودار ساده جهت بیان تحلیل، استفاده کنیم.
این مثال با نام Repeated Measure one-way ANOVA در دسته تحلیلهای Column و در بخش One-way ANOVA صفحه ورودی نرمافزار گراف پد قرار دارد. فایل مثال را میتوانید از اینجا دانلود کنید.
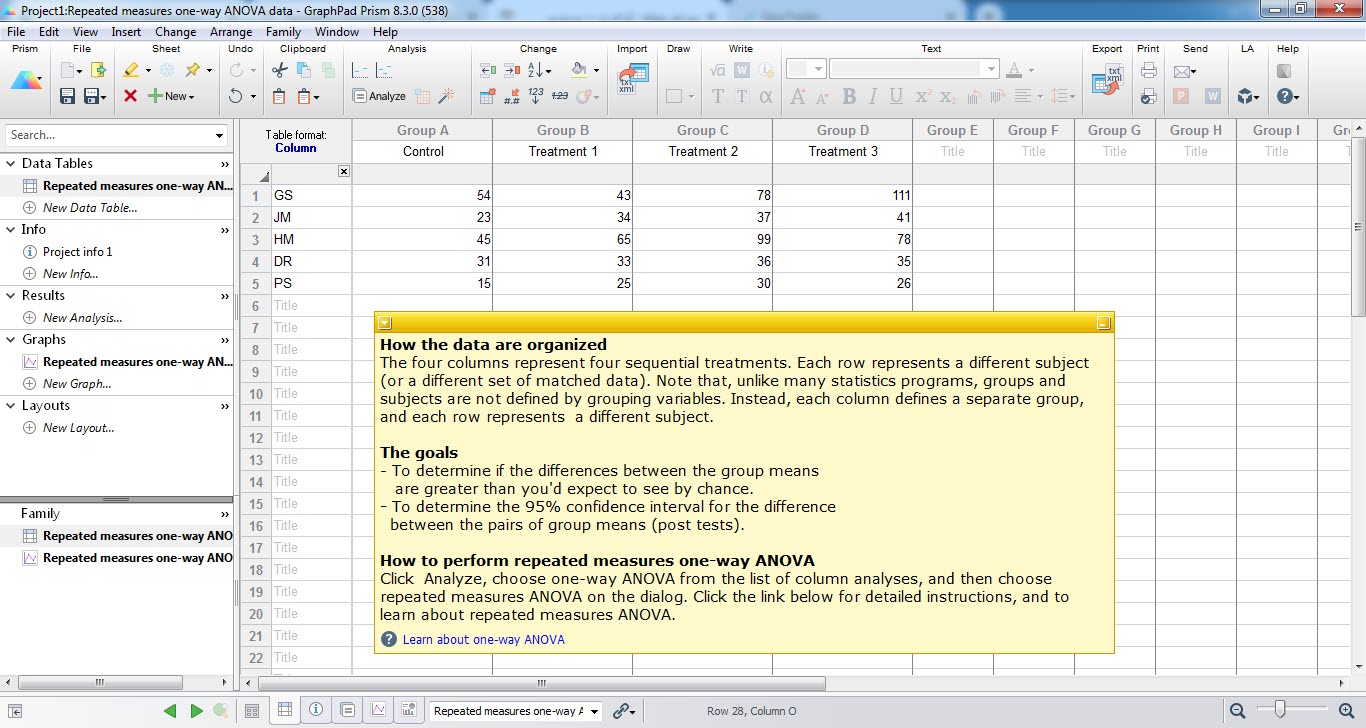
وقتی مثال را Create میکنیم با دادههای زیر روبهرو میشویم. همانگونه که مشاهده میکنید و در Note مثال نیز آمده است، میخواهیم چهار درمان Treatments متوالی را بر روی یک نمونه انجام دهیم، آنها را با هم مقایسه کرده و به این سوال پاسخ دهیم که آیا اختلافی بین درمانهای متوالی وجود دارد یا خیر. به این نکته مهم توجه کنید که هر درمان بر روی یک نمونه مستقل انجام نشده است، یعنی مطالعه از نوع Ordinary one-way ANOVA نیست، بلکه هر چهار درمان بر روی یک نمونه انجام گرفته است. به عنوان مثال در همان سطر با نام GS یکبار درمان Control انجام شده، بار دیگر بر روی همین سطر Treatment 1، یکبار treatment 2 و در انتها Treatment 3 انجام پذیرفته است. به این نوع از مطالعات Repeated measure و یا اندازه گیری مکرر، گفته میشود.
همچنین در این مثال به دنبال یافتن فاصله اطمینان 95 درصد برای اختلاف بین میانگینها نیز هستیم. همانگونه که بارها بیان کردیم یکی از خوبیهای کار با گراف پد، بیان مسیر گام به گام تحلیل توسط نرمافزار در مثالهای آموزشی آن است.
در این مثال و همانگونه که در بخش How to perform repeated measures one-way ANOVA از پنجره Note مشاهده میکنید، مراحل قدم به قدم انجام تحلیل آمده است.
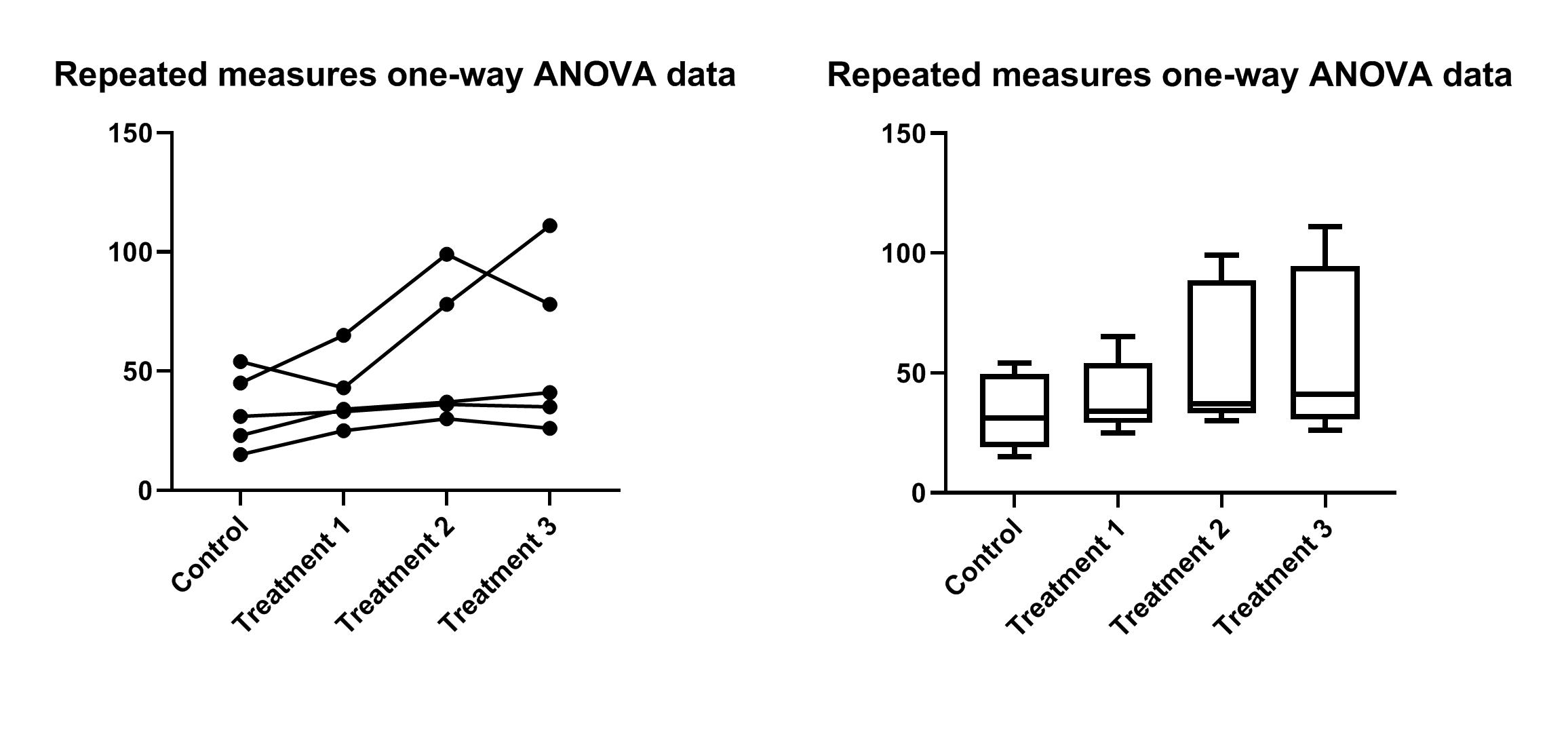
ابتدا در بخش Graphs از پنجره سمت راست (Navigator Panel) میتوان انواع نمودارهای قابل رسم توسط نرمافزار را با کلیک بر روی شیت با نام Repeated measure one-way ANOVA مشاهده کرد. همانگونه که میدانید به خوبی میتوان انواع ویرایشهای دلخواه بر روی گراف به دست آمده را اعمال کرد.

در اینجا در بخش Graph family و در کادر کشویی مقابل آن میتوان نوع نموداری را که میخواهیم رسم کنیم، انتخاب کنیم. از آنجا که در ابتدا این مثال در دسته تحلیلهای Column قرار داشت، بنابراین آن را به همان صورت Column قرار میدهیم.
پس از آن سه تب مختلف با نامهای Box and violin ،Individual values و Mean/median & error دیده میشود. بر روی هر کدام از تبها که کلیک کنیم، میتوان نمودارهای ستونی مرتبط با همان تب را مشاهده کرد.
در تصاویر زیر، چندین گراف با استفاده از همین تبها بر روی دادههای مثال Ordinary one-way ANOVA رسم شده است. میتوانید خودتان نیز به سادگی امتحان کرده و این گرافها را به دست آورید. با استفاده از یک layout در گراف پد، این گرافها را در یک تصویر کنار هم قرار دادهایم. معمولاً نرمافزار گراف پد در تحلیلهای از نوع اندازه گیری مکرر Repeated measure رسم نمودارهای روند خطی را پیشنهاد میدهد. ما در ادامه علاوه بر نمودار خطی، یک باکس پلات نیز رسم کردهایم.
حال بیایید به تحلیل بین گروهها که بیانگر درمانهای متوالی میباشند و مقایسه آنها با یکدیگر بپردازیم. از آنجا که میخواهیم میانگینهای یک نمونه چند بار اندازهگیری شده (بیشتر از دو بار) را با هم مقایسه کنیم، پس تحلیل ما Repeated measure one-way ANOVA خواهد بود. جهت انجام این کار در شیت دادهها از منوی Analyze در بالای صفحه، گزینه One-way ANOVA and nonparametric or mixed را انتخاب میکنیم.
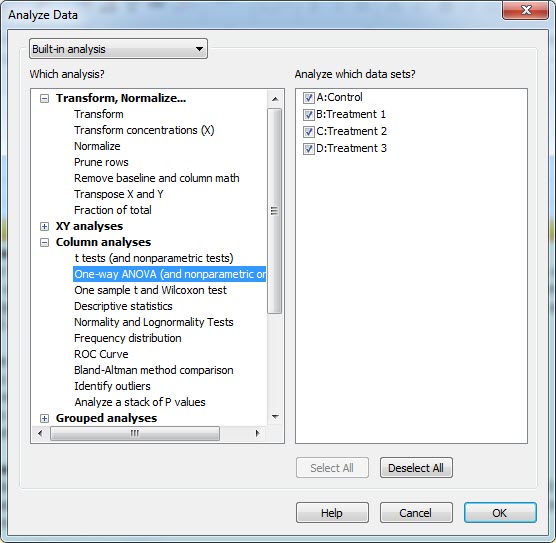
پنجره زیر با نام Parameters: One-way ANOVA and nonparametric or mixed برای ما باز میشود. در اینجا سه بخش انتخابی وجود دارد. در بخش Experimental design انتخاب میکنیم مطالعه ما Matching است یا خیر. اگر تحلیل ما از نوع Ordinary one-way ANOVA باشد یعنی گروهها از هم مستقل باشند ما گزینه No matching or pairing را انتخاب میکنیم. در این زمینه میتوانید این لینک را ببینید.
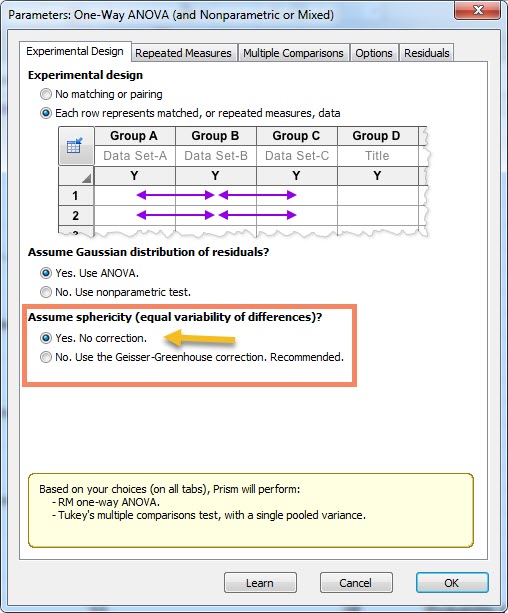
1- اگر مطالعه ما Repeated Measure one-way ANOVA باشد یعنی گروهها به هم وابسته باشند، گزینه Each row represents matched, or repeated measures, data را انتخاب میکنیم. در این مثال از آنجا که به دنبال مقایسه چهار گروه وابسته تحت عنوان یک گروه Control و سه درمان متوالی هستیم، بنابراین همین گزینه را انتخاب میکنیم. به فلشهایی که گراف پد نشان میدهد دقت کنید. فلشها نشان میدهند در هر سطر اختلاف بین درمانها با هم مقایسه میشوند.
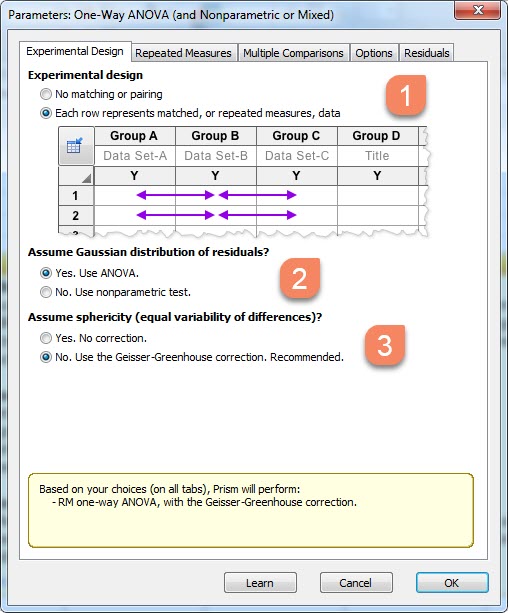
2- در بخش Assume Gaussian distribution of residuals، نرمافزار درباره نرمال بودن یا نبودن توزیع باقیماندهها سوال میپرسد. از آنجا که ANOVA خود یک مدل خطی است بنابراین دارای باقیمانده است. اگر باقیماندهها نرمال باشند از آزمون پارامتری یعنی همان ANOVA استفاده میشود و اگر باقیماندهها غیر نرمال باشند از آزمون ناپارامتری استفاده میکند. بنابراین لازم است به منظور انتخاب صحیح در این بخش، آزمون نرمالیتی را بر روی باقیماندههای این مثال نیز انجام دهیم. در این زمینه در ادامه توضیحات بیشتری میدهیم.
3- در بخش Assume sphericity equal variability of differences درباره فرضیت کرویت و برابری پراکندگی اختلافها از ما سوال میپرسد. فرضیه کرویت می گوید اختلاف بین هر جفت زمان اندازهگیری، باید واریانسهای یکسان و مشابهی داشته باشند. اگر واریانس اختلافها همگن باشند گزینه Yes. No correction که به معنای عدم اصلاح است را انتخاب میکنیم و اگر فرضیه کرویت رد شود و در واقع واریانس اختلافها همگن نباشند گزینه No. Use the Geisser-Greenhouse correction که در آن از اصلاح گیسر-گرینهاوس استفاده میکند، انتخاب میشود. البته گزینههای انتخابی این بخش به اینکه در بخش قبلی، آزمون پارامتری را انتخاب کنیم یا آزمون ناپارامتری، بستگی دارند.
اگر باقیماندهها نرمال باشند و در بخش Assume Gaussian distribution of residuals، گزینه آزمون پارامتری ANOVA انتخاب شود، همانند تصویر بالا Assume sphericity equal variability of differences میتواند شامل گزینههای بله فرضیه کرویت برقرار است، پس اصلاحی لازم نیست و گزینه خیر فرضیه کرویت برقرار نیست، پس از اصلاح گیسر-گرینهاوس استفاده کن، باشند.
همچنین اگر در بخش Assume Gaussian distribution of residuals آزمون ناپارامتری انتخاب شود، دیگر بخش Assume sphericity equal variability of differences را نخواهیم داشت. همانگونه که میدانید آزمون ناپارامتری در این حالت فریدمن Friedman خواهد بود.

بنابراین انتخاب صحیح بین آزمون پارامتری و ناپارامتری جهت انجام فرایندهای بعدی تحلیل مهم است. از آنجا که هنوز نمیدانیم باقیماندهها نرمال هستند یا خیر، که براساس آن پارامتری یا ناپارامتری بودن آزمون مقایسه را انتخاب کنیم، پس قبل از هر تحلیلی، به تب Residuals میرویم. پنجره زیر برای ما باز خواهد شد.
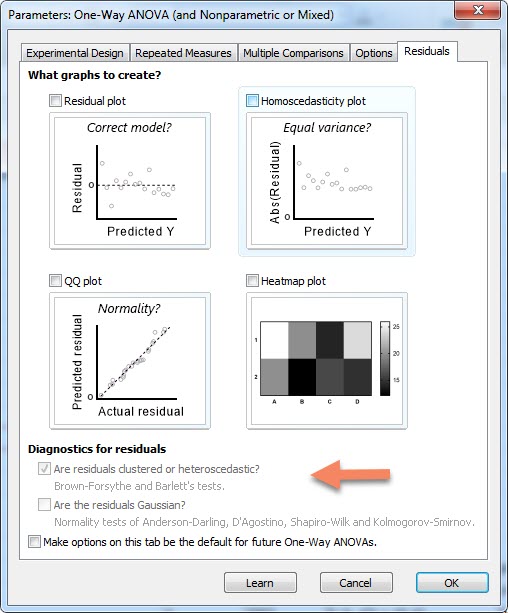
در این تب و در بخش Diagnostics for residuals دو گزینه Are residuals clustered or heteroscedastic به منظور بررسی فرضیه برابر بودن واریانس گروهها و گزینه Are the residuals Gaussian جهت بررسی فرضیه نرمال بودن توزیع باقیماندهها، وجود دارد. اما نکته جالب توجه این است که هر دو گزینه فعلاً غیرفعال هستند.
از دیدگاه نرمافزار گراف پد زمانی گزینه Are the residuals Gaussian فعال میشود که ما در تب Experimental design گزینه No matching or pairing را انتخاب کنیم. به این نکته دقت کنید که مطالعه ما از نوع تکرار مکرر است و میبایست در تب Experimental design گزینه Each row represents matched, or repeated measures, data جهت مقایسه بین ستونها انجام شود، اما در اینجا به منظور بررسی نرمال بودن یا نبودن باقیماندهها و پس از آن انتخاب آزمون پارامتری یا ناپارامتری، مجبور به انتخاب گزینه No matching or pairing هستیم تا فعلاً تکلیف توزیع باقیماندهها روشن شود و سپس به ادامه تحلیل بپردازیم.
بنابراین فعلا در تب Experimental design گزینه No matching or pairing را انتخاب کنیم. پس از آن به تب Residuals میرویم و گزینه Are the residuals Gaussian را که هم اکنون فعال است، انتخاب میکنیم.
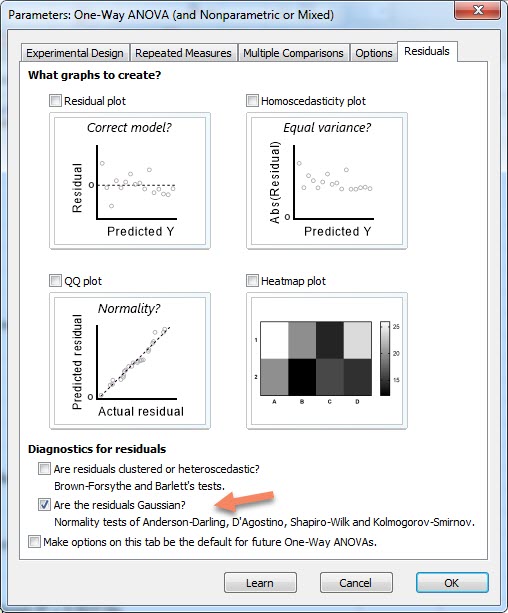
به بقیه تنظیمات کاری نداریم و OK میکنیم. هدف ما در این مرحله فقط این است که ببینیم باقیماندهها نرمال هستند یا خیر. یک شیت جدید در فولدر Results نرمافزار ایجاد میشود. در این مرحله کاری به بقیه نتایج نداریم، تنها بخش Normality of Residuals را نگاه میکنیم.
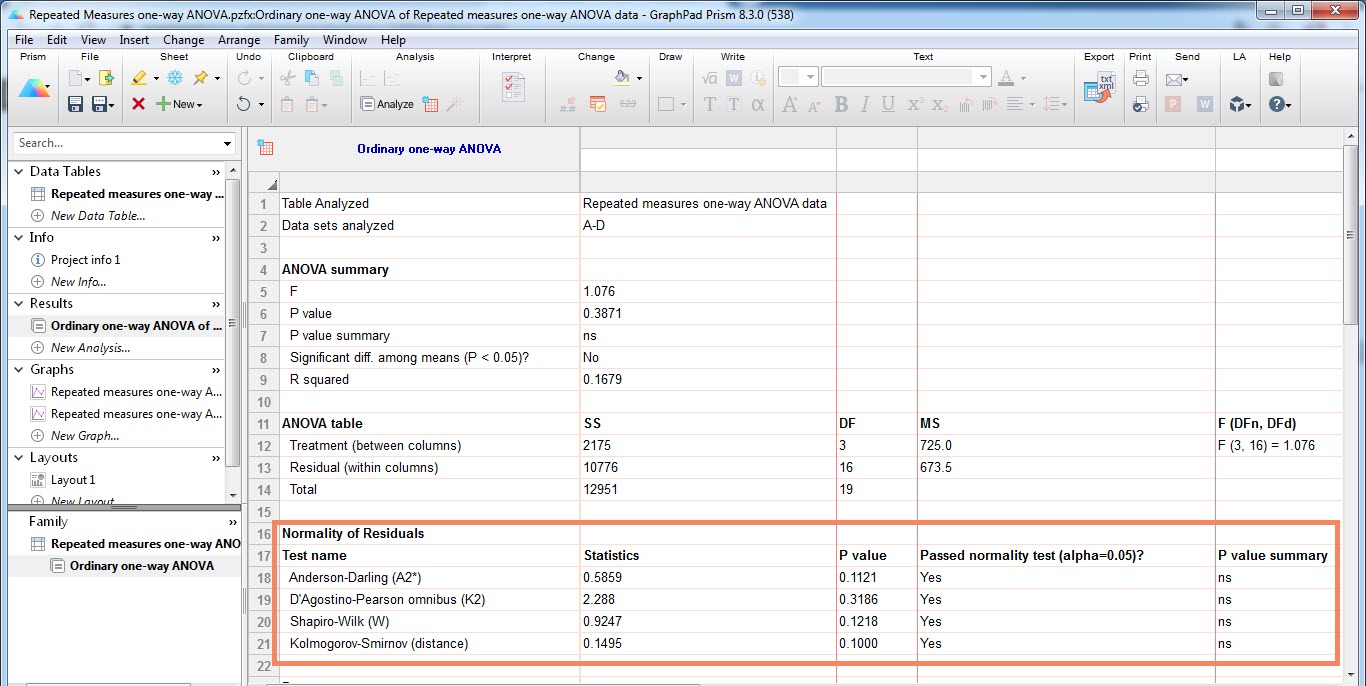
نرمافزار گراف پد بر مبنای چهار روش آزمون نرمالیتی را انجام میدهد، با این حال توصیه نرمافزار استفاده از روش D’Agostino-Pearson است. در این زمینه میتوانید لینک https://www.graphpad.com/guides/prism/8/statistics/stat_choosing_a_normality_test.htm را ببینید. روش متداول Kolmogorov-Smirnov نیز آمده است. همانگونه که مشاهده میکنید بر مبنای روش توصیهشدهی D’Agostino-Pearson توزیع باقیماندهها نرمال است. مقدار احتمال P-value نشان میدهد، در سطح معنیداری پنج درصد باقیماندهها نرمال هستند. بنابراین استفاده از روش پارامتری در این مثال صحیح است.
خُب، پس تا اینجا ما متوجه شدیم مطالعه ما پارامتری خواهد بود. به منظور ادامه تحلیل به شیت دادهها میرویم و از آنجا در منوی Analyze بالای صفحه، گزینه One-way ANOVA and nonparametric or mixed را انتخاب میکنیم. بار دیگر به پنجره Parameters: One-way ANOVA and nonparametric or mixed برمیگردیم.
از آنجا که مطالعه ما اندازهگیری مکرر است اینبار به درستی در تب Experimental design گزینه Each row represents matched, or repeated measures, data را انتخاب میکنیم.
در بخش Assume Gaussian distribution of residuals، نیز از آنجا که متوجه نرمال بودن توزیع باقیماندهها شدیم، گزینه Yes. Use ANOVA را انتخاب میکنیم.
اما هنوز دربارهی Assume sphericity equal variability of differences اطلاعی نداریم. در واقع هنوز نمیدانیم فرضیه کرویت پراکندگی اختلافها را بپذیریم یا خیر. یعنی هنوز نمیدانیم واریانس اختلاف بین هر جفت زمان اندازهگیری با یکدیگر برابر هستند یا خیر. برای این منظور باید ابتدا اختلافها و دادههای آن را به دست آوریم. به منظور مشاهده اختلاف بین هر جفت زمان اندازهگیری، به تب Options میرویم.
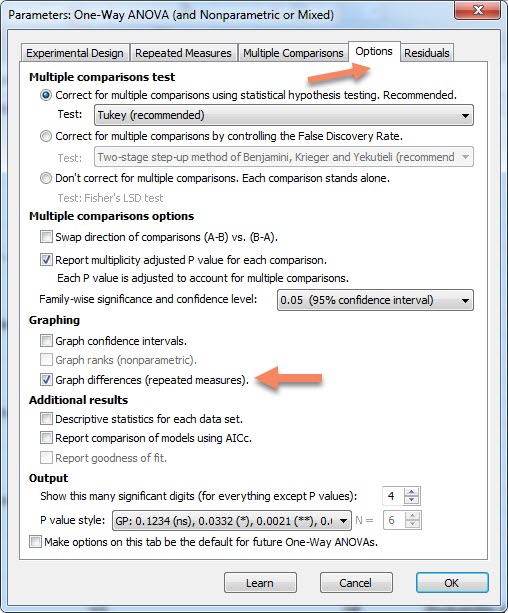
در آنجا و از کادر Graphing گزینه Graph differences repeated measures را انتخاب میکنیم. اگر این گزینه غیرفعال بود ابتدا به تب Multiple Comparisons بروید و از آنجا گزینه Compare the mean of each column with the mean of every other column را فعال کنید. در رابطه با این تب بعداً صحبت خواهیم کرد.
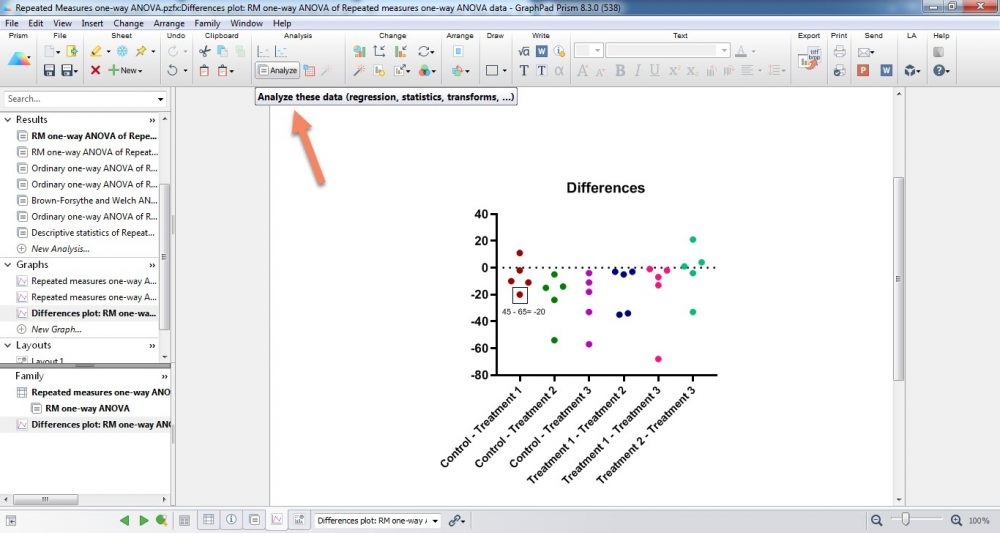
با OK کردن میتوانیم در فولدر Graphs از پنجره Navigator panel نمودار با نام Differences plot: RM one-way ANOVA of Repeated measures one-way ANOVA data را به صورت زیر مشاهده کنیم. البته ما به منظور وضوح بیشتر کمی رنگهای نمودار را ویرایش کردهایم.
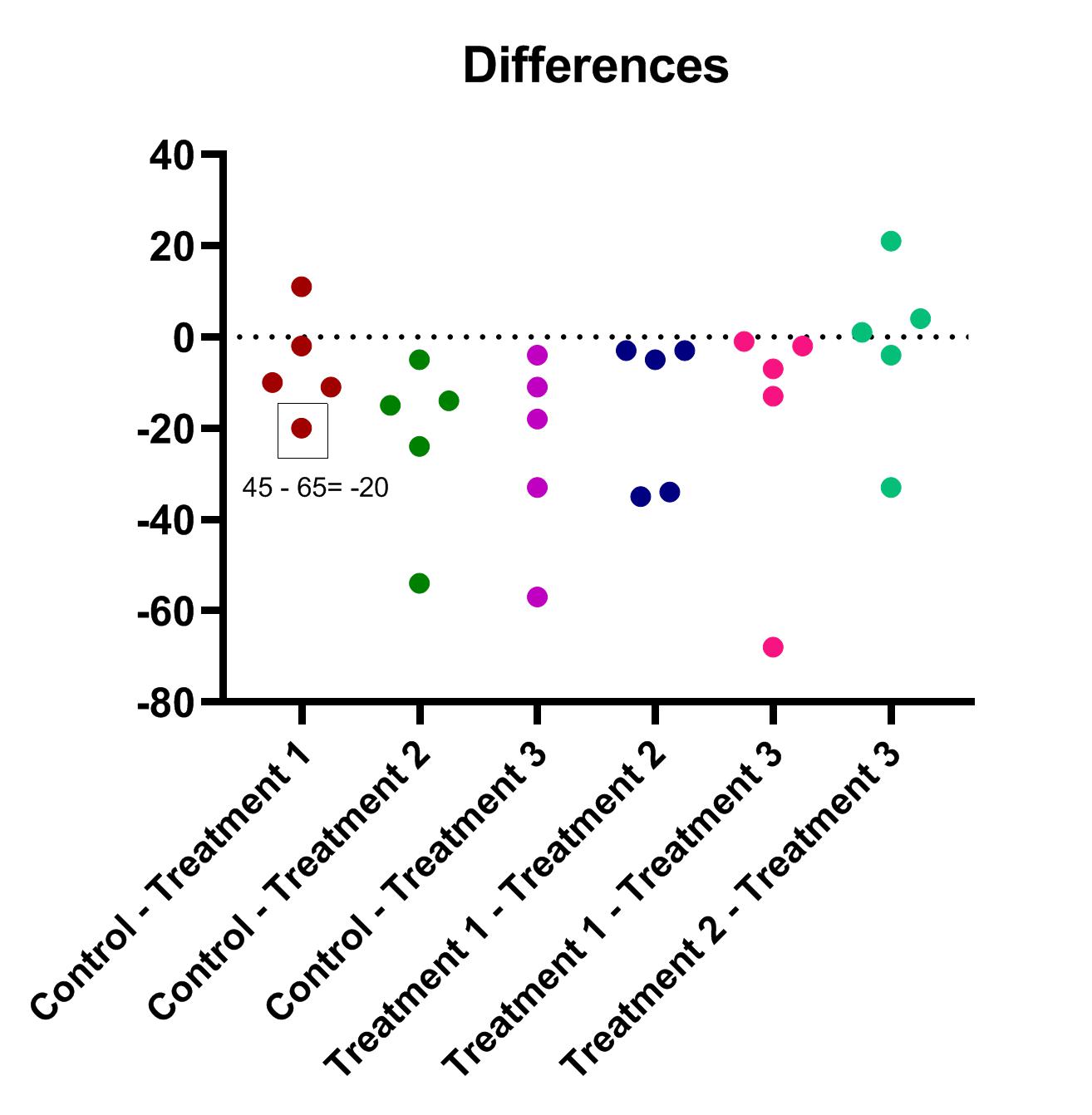
در این گراف اختلاف بین هر گروه با گروه دیگر آمده است. به عنوان مثال سطر سوم در گروه کنترل دارای عدد 45 و در گروه Treatment 1 دارای عدد 65 بوده است، اختلاف این دو یعنی 20- در نمودار بالا مشخص شده است. به همین ترتیب هر کدام از نقاط نمودار بالا همان اختلاف بین دو گروه به ازای هر سطر (پنج نمونه یا سطر داریم)، میباشد.
خُب، حال سوال این است که با این گراف چه کنیم؟ در واقع فرضیه کرویت که در بالا به آن اشاره کردیم و به معنای برابر بودن واریانسهای اختلافها است به دادههای همین نمودار اشاره دارد. ما باید بررسی کنیم آیا واریانس این شش گروه ساخته شده که هر یک بیانگر اعداد اختلاف بین دو گروه میباشد، با یکدیگر برابر هستند یا خیر.
برای این منظور خیلی ساده در همین شیت گراف که هستیم بر روی دکمه Analyze در بالای صفحه کلیک میکنیم.
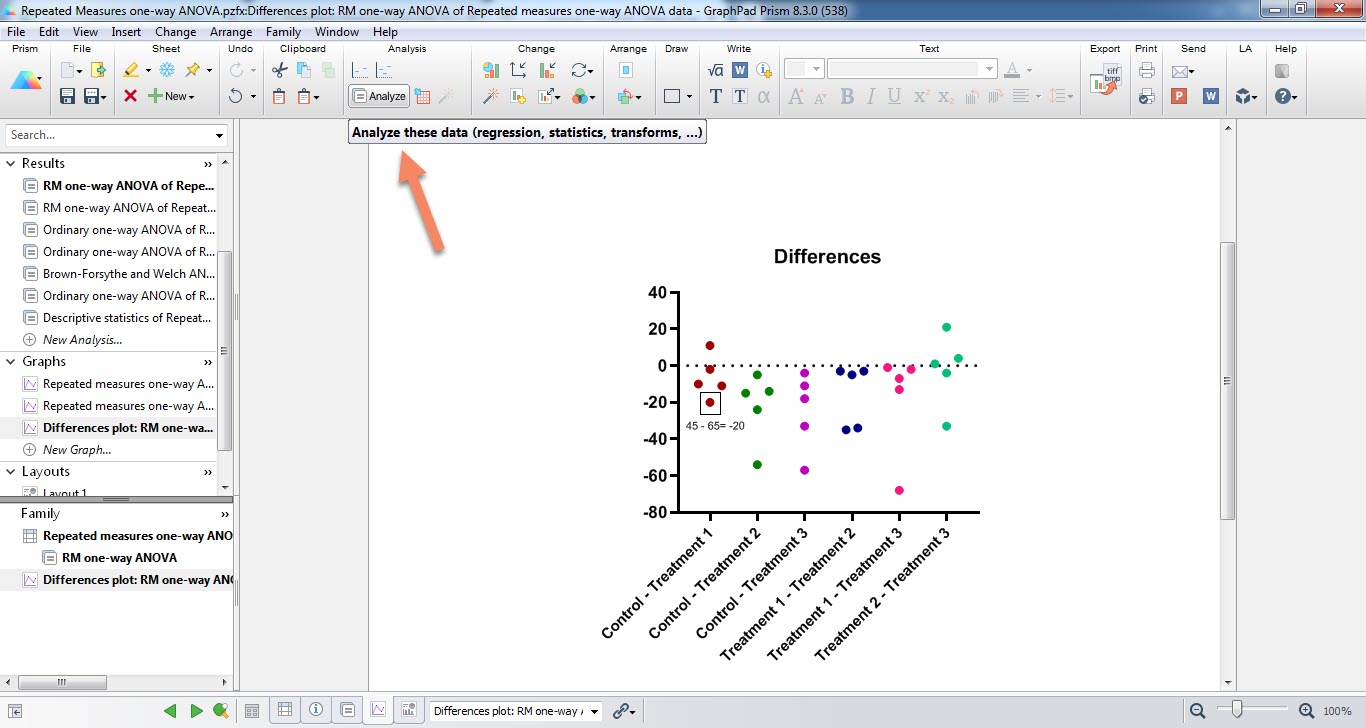
در پنجره Analyze Data باز شده خیلی ساده تحلیل One-way ANOVA and nonparamertic or mixed را انتخاب میکنیم. حتماً تا به حال متوجه شدهاید ما میخواهیم چه کاری انجام دهیم. هدف ما این است که از محیط آزمون ANOVA به انجام تحلیل برابری واریانسها اینبار برای دادههای اختلاف بین گروهها بپردازیم.
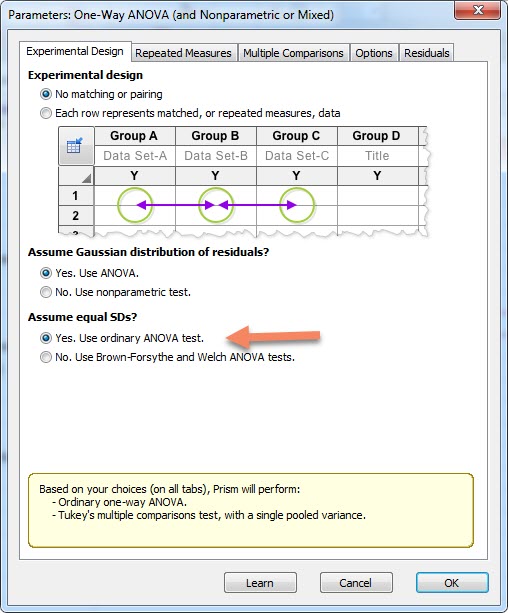
بار دیگر پنجره Parameters: One-way ANOVA and nonparametric or mixed برای ما باز میشود. تنظیمات را به صورت پیشفرض زیر قرار میدهیم.
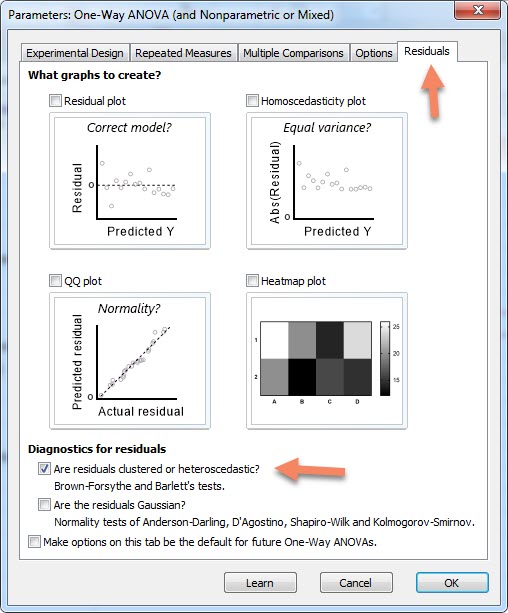
حال جهت انجام آزمون همگنی واریانس و یا همان فرضیه کرویت اختلافها، به تب Residuals میرویم و از بخش Diagnostics for residuals گزینه Are residuals clustered or heteroscedastic را فعال میکنیم.
با OK کردن، آزمون همگنی واریانس اختلافها نیز برای ما انجام شده است. این نتیجه را میتوانید در شیت جدید با نام Brown-Forsythe and Welch ANOVA tests of RM one-way ANOVA of Repeated measures on در فولدر Graphs پنجره راهبری مشاهده کنید.
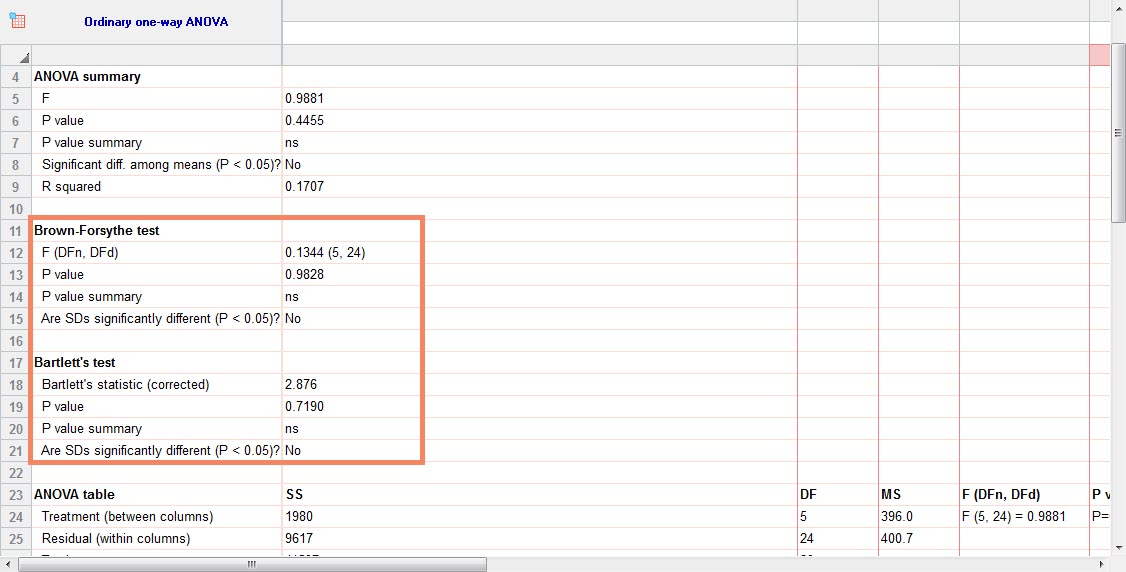
آزمون همگنی واریانسها با استفاده از دو روش به نامهای Brown-Forsythe test و Bartlett’s test انجام شده است. همانگونه که مشاهده میشود هر دو روش بیانگر عدم اختلاف معنادار واریانس اختلافها است. به این معنا که فرضیت کرویت پذیرفته میشود.
بنابراین بار دیگر به شیت دادهها میرویم و در این مثال که به موضوع اندازهگیری مکرر پرداختیم پس از طی کردن مسیر انجام آزمون ANOVA در کادر Assume sphericity equal variability of differences گزینه Yes. No correction را به درستی انتخاب میکنیم.
یک نکته دیگر نیز در این میان اهمیت دارد. چگونه میتوان گروهها را دوبهدو با یکدیگر مقایسه کرد؟ یعنی در این مثال Control را با Treatmentهای مختلف و البته درمانها را با هم مقایسه کرد؟
انجام این کار با تب Multiple Comparisons در همین پنجره Parameters: One-way ANOVA and nonparametric or mixed امکانپذیر است. پس بر روی این تب کلیک میکنیم، پنجره زیر باز خواهد شد.
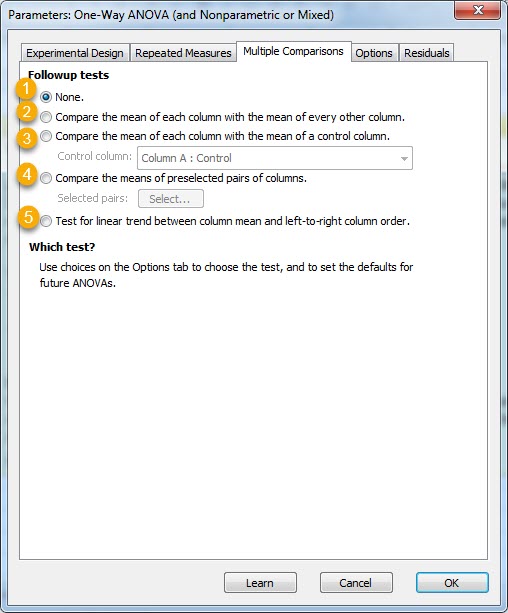
در اینجا میتوانید پنج گزینه مشاهده کنید، ما آنها را به ترتیب بیان میکنیم.
1- None. خُب، با انتخاب این گزینه هیچ آزمون دوبهدویی انجام نمیشود. با این انتخاب فقط یک آزمون کلی ANOVA بین همه گروهها انجام میشود.
2- Compare the mean of each column with the mean of every other column. با انتخاب این گزینه میانگین هر گروه با گروه دیگر مقایسه میشود. به صورت متداول معمولاً این گزینه انتخاب میشود، زیرا کاملترین نوع مقایسه است.
3- Compare the mean of each column with the mean of a control column. با انتخاب این گزینه میتوان میانگین هر ستون را با یک ستون از قبل انتخاب شده که نقش کنترل را بازی میکند، مقایسه کرد. در کادر باز شده به سادگی میتوان این گروه که قرار است بقیه گروهها با آن مقایسه شوند را انتخاب کرد.
4- Compare the means of preselected pairs of columns. با انتخاب این گزینه میتوان فقط مقایسه را به دو گروه انتخاب شده تقلیل داد. این دو گروه را میتوان در باکس Select انتخاب کرد.
5- Test for linear trend between column mean and left-to-right column order. این گزینه کمتر به کار میآید، با این حال با انتخاب این گزینه آزمون وجود روند خطی بین میانگین ستونها انجام میشود. اگر این گزینه را انتخاب کنیم در شیت نتایج میتوانیم خروجی زیر را ببینیم.
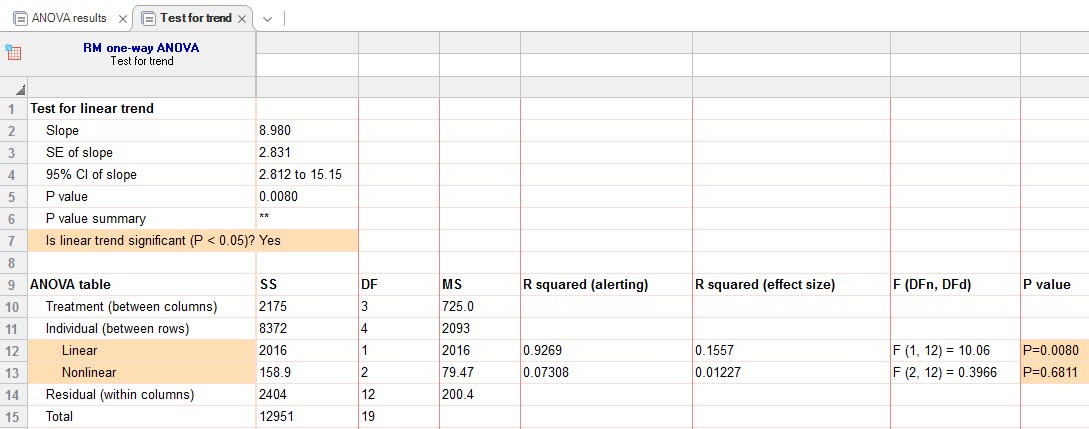
این نتیجه نشان میدهد در میانگین ستونها روند خطی وجود دارد (P-value = 0.0080).
ما در اینجا همان گزینه Compare the mean of each column with the mean of every other column را انتخاب میکنیم تا بتوانیم همه گروهها را با همدیگر مقایسه کنیم.
در اینجا خوب است به یک نکته دیگر نیز اشاره کنیم. به دست آوردن آمارههای توصیفی مانند میانگین، انحراف معیار و دامنه اعداد در هر گروه میتوانند یافتههای جالب توجهی باشند. به همین دلیل میتوان در تب Options از پنجره Parameters: One-way ANOVA and nonparametric or mixed و در کادر Additional results گزینه Descriptive statistics for each data set را انتخاب کرد. با انتخاب این گزینه میتوان در خروجی نتایج به دست آمده از گراف پد، انواع آمارههای توصیفی به ازای هر گروه را مشاهده کرد.
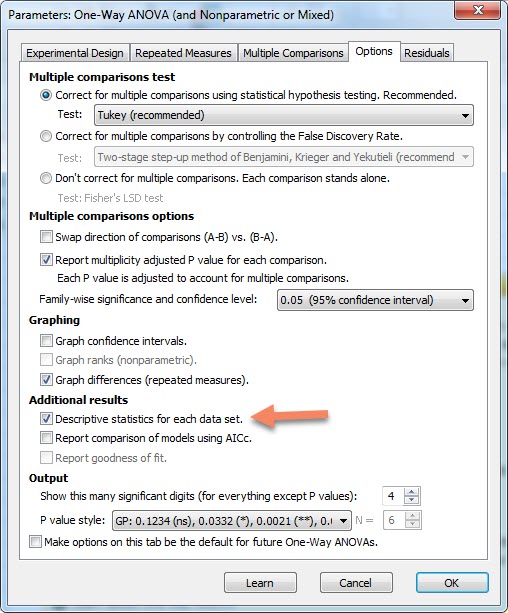
با دیگر تنظیمات کاری نداریم و OK میکنیم. نتایج در یک شیت جدید در بخش Results از پنجره سمت راست (Navigator Panel) با نام RM one-way ANOVA of Repeated measures one-way ANOVA data ارایه میشود.
این شیت دارای سه زبانه است. یکی با نام ANOVA results که به ارایه تحلیل مقایسه کلی بین گروهها پرداخته است، یک زبانه با نام Multiple comparisons که به مقایسه دوبهدو بین گروهها پرداخته است. زبانه دیگر با نام Descriptive statistics به ارایه و بیان آمارههای توصیفی هر گروه اشاره دارد.
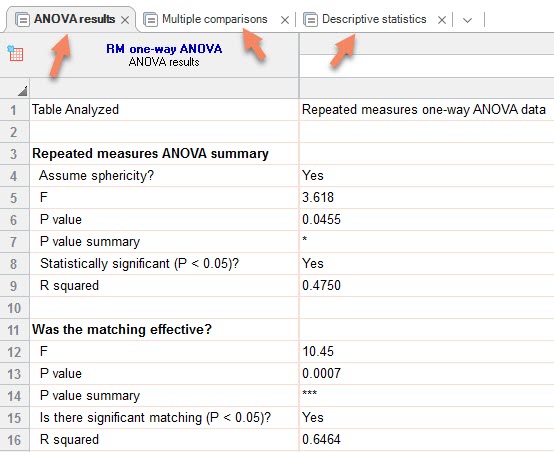
در ابتدا از تب ANOVA results شروع میکنیم. در بخش Repeated measures ANOVA summary نتیجه مقایسه بین گروهها آمده است و نشان میدهد بین گروهها اختلاف معنادار وجود دارد (P value = 0.0455). جدول زیر را مشاهده کنید.
جالب توجه است که در همین ابتدای کار، فرضیه کرویت Assume sphericity بیان شده است. ما در بخشهای بالا نشان دادیم که واریانس اختلاف بین گروهها همگن و برابر است و بنابراین درست این است که تحلیل را بر مبنای تایید فرضیه کرویت انجام دهیم.
در ادامه به بیان و تحلیل نتایج میپردازیم. خوب است در همین جا دربارهی ستارههای معناداری در نرمافزار گراف پد پریسم صحبت کنیم. در این نرمافزار با استفاده از ستارهها، قوت و شدت معناداری بیان میشود. در جدول زیر میتوانید مفهوم ستارههای معناداری را مشاهده کنید.

این جدول به معنای آن است که هر چه تعداد ستارهها افزایش یابد مقدار احتمال آزمون کمتر میشود.
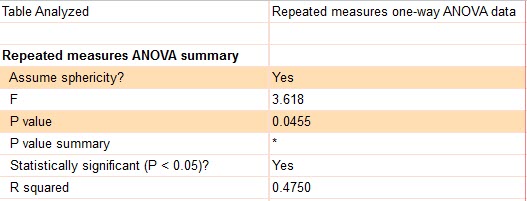
در کادر بعدی با نام Was the matching effective به بررسی اختلاف بین افراد (سطرها) چندبار اندازهگیری شده، پرداخته شده است. در این مثال نشان داده شده است که این اختلاف معنادار بوده است (P value = 0.0007). به بیان دیگر اینکه Subject ها که اسامی آنها در هر سطر آمده است، با یکدیگر فرق میکردهاند.
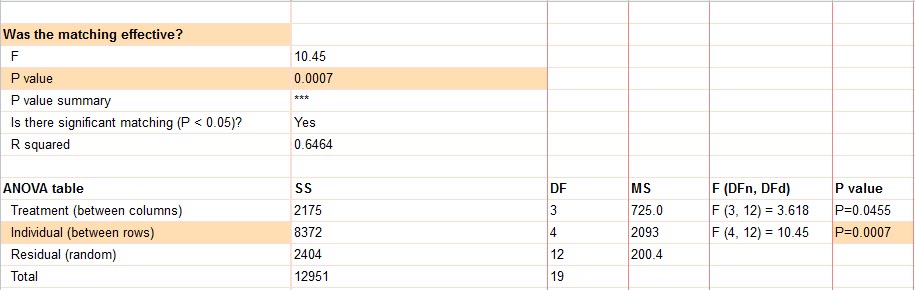
مواردی که در بالا مطرح کردیم دربارهی زبانه ANOVA results بود. مطلبی که همچنان باقی مانده درباره نحوه مقایسه دوبهدو بین گروهها است. این نتایج در زبانه Multiple comparisons آمده است. حال بیایید به توضیح آنها بپردازیم.
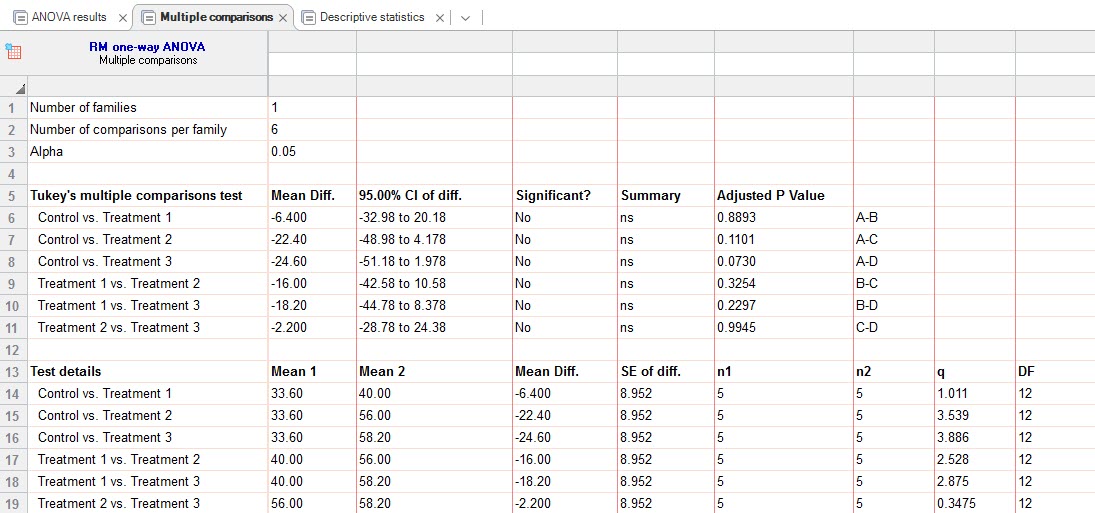
در ابتدا و همانگونه که مشاهده میکنید، مقایسههای دوگانه با استفاده از آزمون توکی Tukey انجام شده است. در این مقایسات هر گروه به صورت جداگانه با گروه دیگر مورد مقایسه قرار گرفته است. به عنوان مثال Control با Treatment 1 مقایسه شده و اختلاف بین آنها معنادار نبوده است (P value = 0.8893).
این موضوع شاید کمی گیجکننده باشد. زیرا ما در تب ANOVA results به این نتیجه رسیدیم که بین چهار گروه اختلاف معناداری وجود دارد اما هنگامی که به مقایسه دوبه دو بین گروهها میپردازیم، اختلاف معنادار نمیبینیم. در توجیه این مطلب باید دو نکته را توجه کرد. اول اینکه مقدار احتمال آزمون ANOVA اصطلاحاً لب مرزی است (P value = 0.0455) و نزدیک آلفای پنج درصد قرار دارد. نکته دیگر اینکه ما در آزمون ANOVA به مقایسه توام چهار گروه با هم پرداختهایم، در آنجا احتمال مشاهده اختلاف معنادار بیشتر میشود نسبت به زمانی که فقط دو گروه را صرفنظر از گروههای دیگر با هم مقایسه میکنیم. در اینجا دو راهکار کلی به شما پیشنهاد میکنیم.
1- اگر مقدار احتمال آزمون ANOVA کلی معنادار نبود، دیگر به دنبال معناداری در مقایسههای دوگانه بین گروهها نباشید، زیرا آنها نیز معنادار نیستند.
2- اگر مقدار احتمال آزمون ANOVA کلی معنادار بود، به بررسی معناداری در مقایسههای دوگانه بین گروهها بگردید. اگر P value آزمون ANOVA لب مرزی نباشد یعنی به آلفای پنج درصد نزدیک نباشد، حتما میتوانید یک یا چند اختلاف معنادار بین گروهها را کشف کنید. اگر این مقدار احتمال مانند مثال ما لب مرزی باشد، شاید بین گروهها اختلاف معنادار دیده نشود.
آنچه که در نهایت باقی میماند، مشاهده آمارههای توصیفی به دست آمده برای هر کدام از گروههای Control و درمان است. این مطلب را میتوانیم در زبانه Descriptive statistics ببینیم.
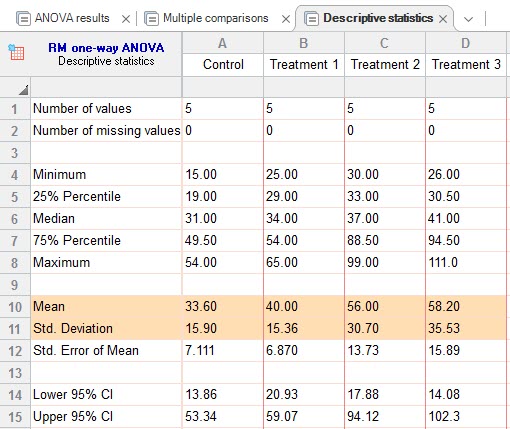
میانگین، انحراف معیار و سایر آمارههای توصیفی برای هر ستون در جدول بالا آمده است. نتیجه به دست آمده نشان میدهد میانگین Treatment 3 از بقیه گروهها بیشتر و در گروه کنترل کمترین میانگین دیده میشود. با این حال این اختلاف نیز معنادار به دست نیامده است. کمی فکر کنید چرا. همه چیز زیر سر انحراف معیارهای بزرگ گروهها است.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). Educational example Repeated Measures one-way ANOVA with GraphPad Prism Software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/repeated-measures-one-way-anova/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). Educational example Repeated Measures one-way ANOVA with GraphPad Prism Software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/repeated-measures-one-way-anova/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.