خوشه بندی سوالات Cluster Variables با نرمافزار Minitab
*** توضیحات خوشه بندی سوالات (Variables Clustering) برگرفته شده از کتاب روش های پیشرفته آماری و کاربردهای آن- انتشارات جامعهنگر***
هدف از خوشه بندی در این آموزش آن است که سوالات و یا همان Variableها را در گروههای همانند دستهبندی کنیم، به گونهای که کمیتها و سوالات هر گروه، بیشترین شباهت و کمیتهای گروههای مختلف، کمترین شباهت را با هم داشته باشند.

در این آموزش به چگونگی انجام تحلیل خوشه بندی Variables با استفاده از نرمافزار Minitab میپردازیم.
مثال آموزشی خوشه بندی سوالات (Variables)
در یک بررسی به منظور سنجش رضایت خریداران یک نوع ماشین، 750 نفر مورد پرسشگری قرار گرفتهاند. 24 سوال و یا همان Variable مربوط به خصوصیات و ویژگیهای فنی و ظاهری ماشین، از هر فرد پرسیده شده است. میخواهیم این سوالات را در چند گروه خوشه بندی کنیم. سوالات به شرح زیر هستند.
| V1 | نحوه باز و بسته شدن دربها | V13 | عملكرد ترمز دستی |
| V2 | كيفيت رنگ بدنه | V14 | عملكرد برف پاك كن و شيشه شوی |
| V3 | سكوت نسبی و آرامش داخل اتاق | V15 | عملكرد لوازم ايمنی داخل اتاق (كمربند ايمنی) |
| V4 | عدم نفوذ آب, باد و گرد و غبار | V16 | كيفيت صندليها (عملكرد، راحتی ) |
| V5 | قدرت و شتاب خودرو | V17 | كيفيت تايرها |
| V6 | تناسب مصرف سوخت | V18 | عملكرد و تنظيم نور چراغها |
| V7 | وضعيت موتور (صدای موتور، عدم روغنريزی ) | V19 | عملكرد بخاری |
| V8 | عملكرد سيستم فرمان | V20 | عملكرد كولر |
| V9 | عملكرد مجموعه كلاچ | V21 | عملكرد شيشه بالابرها |
| V10 | عملكرد مجموعه گيربكس | V22 | سيستم برق رسانی (باتری، دينام، استارتر) |
| V11 | عملكرد جلوبندی و كمك فنرها | V23 | عملکرد ادوات برقی ( آمپرها، بوق، فندک) |
| V12 | عملكرد ترمز (گيرايی) | V24 | عملکرد سيستم صوتی و تصويری |
فایل داده این آموزش را میتوانید از اینجا Cluster Variables Car دریافت کنید.
جهت خوشهبندی Variableها، ابتدا از مسیر زیر در نرمافزار Minitab استفاده میکنیم.
Stat → Multivariate → Cluster Variables
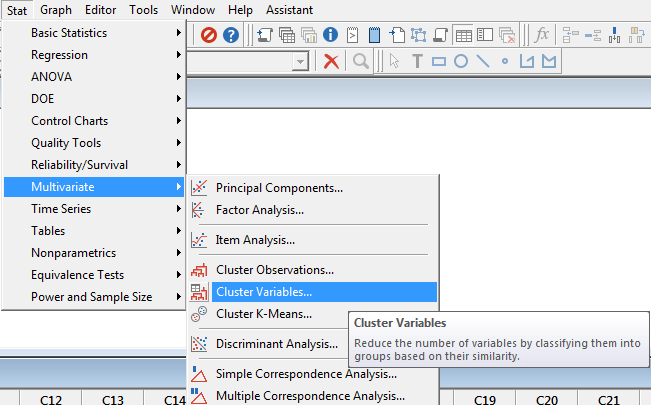
در این آموزش به تفکیک و با بیان جزئیات به شرح منوها و گزینههای نرمافزار Minitab جهت خوشهبندی Variableها میپردازیم.
تنظیمات خوشه بندی سوالات (Cluster Variables)
در پنجره باز شده، تمام کمیتها را انتخاب و در کادر Variables or distance matrix قرار دهید.
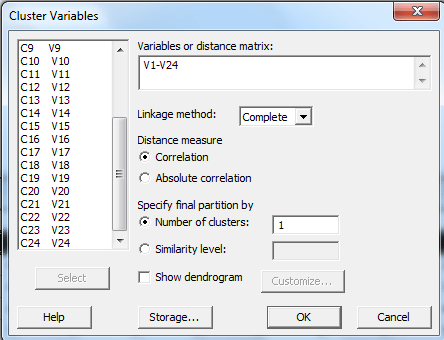
Linkage method روش خوشهبندی کمیتها و نحوه قرار گرفتن در هر خوشه را مشخص میکند.
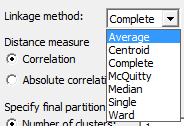
در جدول زیر به شرح گزینههای مختلف آن میپردازیم. گزینهها به فاصله بین دو خوشه اشاره میکنند.
| Average | Centroid | Complete | McQuitty | Median | Single | Ward |
| فاصله بین دو خوشه، میانگین فاصله بین یک سوال از یک خوشه، با سوال خوشه دیگر است. | فاصله بین دو خوشه، فاصله بین مرکز یا میانگین خوشهها است. | فاصله بین دو خوشه، ماکزیمم فاصله بین سوال در هر خوشه و سوال در خوشه دیگر. (روش دورترین همسایگی) | فاصله بین دو خوشه، نصف مجموع فاصله هر کدام از دو خوشه با خوشه سوم دیگر. | فاصله بین دو خوشه، میانه فاصله بین یک سوال از یک خوشه، با سوال خوشه دیگر است. | فاصله بین دو خوشه، مینیمم فاصله بین سوال در هر خوشه و سوال در خوشه دیگر. (روش نزدیکترین همسایگی) | فاصله بین دو خوشه، مجموع انحراف مربعات از نقاط مرکزی است. |
جهت به دست آوردن فرمول هر کدام از روابط میتوانید به لینک https://support.minitab.com/en-us/minitab/18/help-and-how-to/modeling-statistics/multivariate/how-to/cluster-variables/methods-and-formulas/linkage-methods/ مراجعه کنید.
تنظیمات بخش Distance measure در Cluster Variables
در بخش Distance measure نحوه انتخاب اندازه فاصله بین سوالات قرار دارد.

انتخاب دکمه Correlation سبب میشود، فاصله بین دو سوال i و j از رابطه زیر به دست آید.
dij = 1 – ρij
که در آن ρij ماتریس ضرایب همبستگی پیرسون بین variable به نام i و j است.
انتخاب دکمه Absolute correlation همان فرمول بالا را به صورت قدرمطلق ρij، معرفی میکند.
تنظیمات بخش Specify final partition by در Cluster Variables
در بخش Specify final partition by معیارهای مورد نظر برای تعیین گروهبندی نهایی را مشخص کنید.

گزینه Number of clusters به ما این امکان را میدهد تا تعداد خوشههای نهایی Variableها را خودمان انتخاب کنیم. به عنوان مثال اگر پیشفرض عدد یک نرمافزار را بپذیریم، در این مثال تمام 24 سوال در یک خوشه اصلی جمع میشوند.
گزینه Similarity level به ما امکان انتخاب تعداد خوشهها را بر مبنای مشابهت و اصطلاحاً سطح همانندی بین Variableها میدهد. توجه کنید که Similarity level میتواند همانند یک Cut off در خوشهبندی سوالات عمل کند. در این زمینه در ادامه بیشتر توضیح خواهیم داد.
گزینه Show dendrogram در Cluster Variables
در انتهای تنظیمات خوشهبندی با نرمافزار Minitab گزینه Show dendrogram وجود دارد.
![]()
انتخاب این گزینه سبب طراحی یک گراف درختی مفید از نحوه و فرایند گام به گام خوشهبندی Variableها خواهد شد.
به منظور اعمال برخی اصلاحات دلخواه میتوانید با دکمه Customize کار کنید.
حل مثال آموزشی خوشه بندی سوالات (Variables)
حال بیایید به مثال مطرح شده در این نوشتار بپردازیم. همانگونه که در ابتدا بیان کردیم 24 Variable مربوط به خصوصیات و ویژگیهای فنی و ظاهری ماشین، از 750 فرد پرسیده شده است. میخواهیم این سوالات را در چند گروه خوشه بندی کنیم. مراحل زیر را گام به گام طی میکنیم.
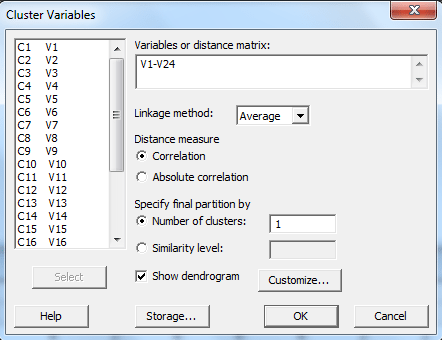
1- فایل آموزشی Cluster Variables Car را در نرمافزار Minitab باز کنید.
2- از مسیر زیر در نرمافزار Minitab استفاده میکنیم.
Stat → Multivariate → Cluster Variables
3- تمام کمیتها را انتخاب و در کادر Variables or distance matrix قرار دهید.
4- از کادر Linkage method گزینه Average را انتخاب کنید.
5- در بخش Distance measure گزینه Correlation را برگزینید.
6- فعلاً در این مرحله، تعداد 1 خوشه اصلی پیشفرض نرمافزار در بخش Number of clusters را بپذیرید.
7- گزینه Show dendrogram را به منظور نمایش گراف خوشه بندی سوالات انتخاب کنید.
تحلیل نتایج مثال آموزشی خوشه بندی سوالات (Variables)
هنگامی که تنظیمات نرمافزار را OK میکنید، نتایج زیر به دست میآید. ما به بررسی آنها میپردازیم.
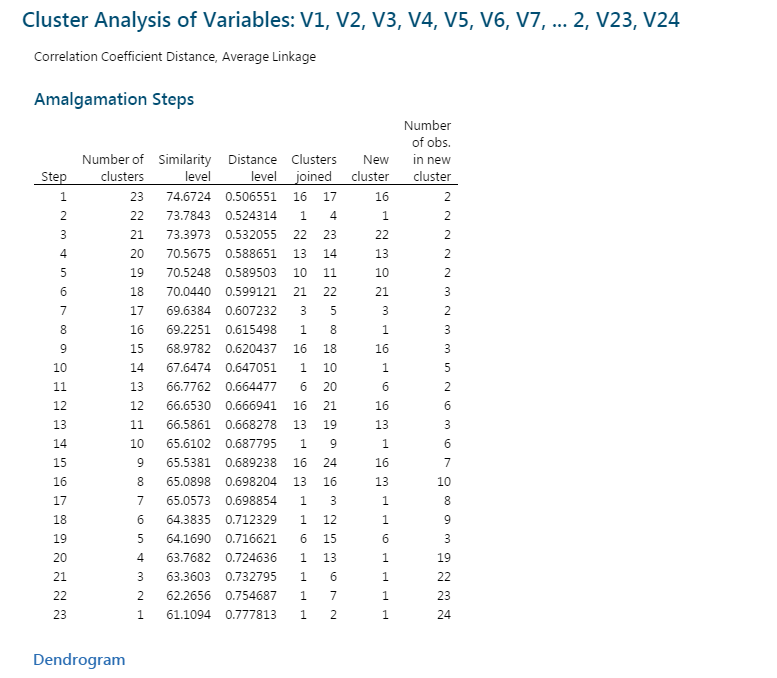 در خط اول، درباره سوالات و Variableهایی که بر روی آنها خوشه بندی انجام شده است، صحبت میکند.
در خط اول، درباره سوالات و Variableهایی که بر روی آنها خوشه بندی انجام شده است، صحبت میکند.
خط بعدی درباره گزینههای انتخاب شده Linkage method و Distance measure میباشد.
نتایج تحت عنوان جدولی به نام Amalgamation Steps بیان شده است. تفسیر آنها ساده و البته دقیق خواهد بود. در جدول زیر تفسیر نام ستونها را بیان کردهایم.
| Number of obs. in new cluster | New cluster | Clusters joined | Distance level | Similarity level | Number of clusters | Step |
| تعداد Variableهای موجود در خوشه ایجاد شده در هر گام. | خوشه جدید تشکیلشده در هر گام. این خوشه نماینده یکی از سوالات ترکیب شده با یکدیگر میباشد. | شماره Variableهایی که در هر گام با یکدیگر ترکیب شدهاند. | میزان سطح اختلاف خوشهها با یکدیگر در هرگام. با بیشتر شدن گامها این سطح افزایش مییابد. | میزان سطح تشابه خوشهها به یکدیگر در هر گام. با بیشتر شدن گامها این سطح کاهش مییابد. | تعداد خوشههای تشکیلشده در هر Step | شماره گام اجرای فرایند خوشه بندی سوالات. همواره برابر با تعداد Variableها منهای یک است. |
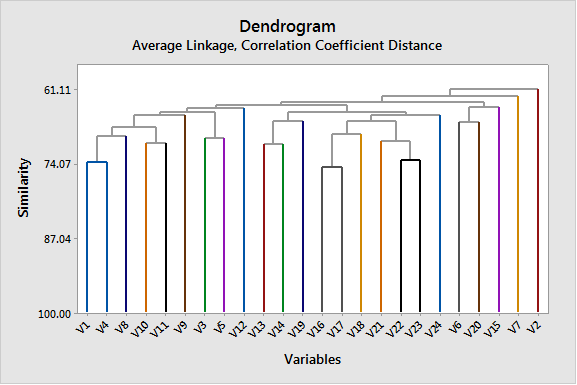
به عنوان مثال نتایج به دست امده نشان میدهد در گام 1، Variableهای 16 و 17 با یکدیگر ترکیب شده و یک خوشه جدید به نمایندگی V16 را ساختهاند. در این صورت 23 خوشه وجود دارد (22 سوال به همراه یک خوشه شامل سوالات V16 و V17). Similarity level در این خوشهها برابر با 74.67 و Distance level برابر با 0.506 است.
فرایند خوشه بندی سوالات ادامه پیدا کرده است تا در نهایت، یک خوشه کلی از تمام Variableها ساخته شده است.
سطح تشابه در این خوشه برابر با 61.1 درصد به دست آمده است.
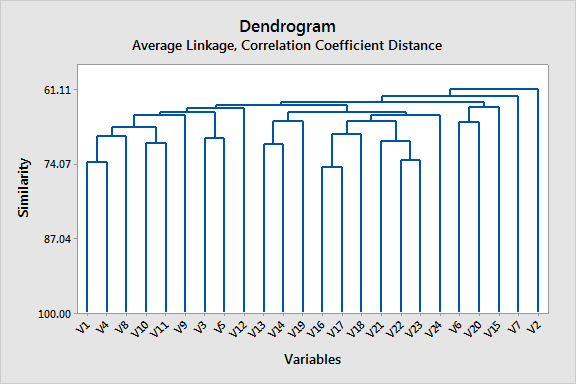
به همین ترتیب گراف Show dendrogram که نشاندهنده نحوه خوشهبندی سوالات است، دیده میشود.
تشکیل تعداد خوشههای بیشتر در Cluster Variables
حال فرض کنید بخواهیم به جای ترکیب تمام سوالات و Variableهای تحقیق در یک خوشه، آنها را در تعداد خوشههای بیشتری دستهبندی کنیم. برای انجام این کار در تنظیمات نرمافزار در بخش Number of clusters تعداد خوشهها را به عنوان مثال 3 انتخاب میکنیم.
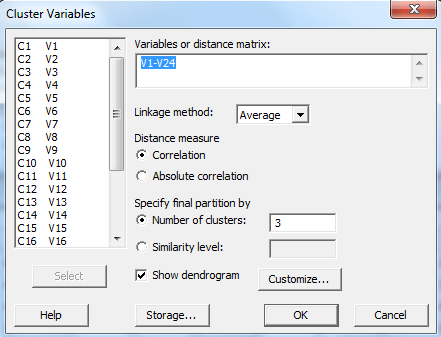
در این صورت نتایج به دست آمده همانند قبل خواهد بود، با این تفاوت که در خروجی نرمافزار یک بخش جدید با عنوان Final partition قرار گرفته است.
 همانگونه که در Final partition مشخص است، Variableها به همراه شماره آنها در سه خوشه قرار گرفتهاند.
همانگونه که در Final partition مشخص است، Variableها به همراه شماره آنها در سه خوشه قرار گرفتهاند.
گراف Show dendrogram نیز جایگاه سه خوشه و سوالات تشکیلدهنده آنها را نشان میدهد.
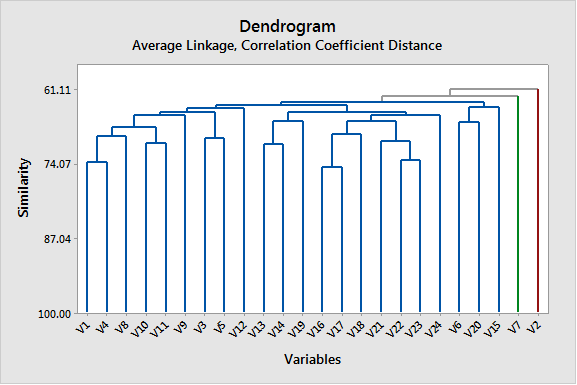
استفاده از گزینه Similarity level به عنوان Cut off در Cluster Variables
سطح تشابه و یا همان Similarity level درخوشه بندی سوالات، میتواند به عنوان یک Cut off به ما کمک کند چه تعداد خوشه در تحلیل خود داشته باشیم.
برای این منظور لازم است، یکبار نتایج را همانند مرحله اول همین مثال با یک خوشه به دست آوریم.
توجه به مقدار Similarity level که در کدام مرحله به یکباره و نسبت به گامهای دیگر، کاهش مییابد، کمک خواهد کرد آن مقدار سطح تشابه را به عنوان Cut off در تنظیمات و در مقابل کادر Similarity level وارد کنیم.
در نتایج خوشه بندی به دست آمده در مرحله اول این مثال مشاهده میشود که در گام شماره 4 مقدار Similarity level، نسبت به گامهای دیگر کاهش بیشتری دارد. سطح تشابه در این Step برابر با 70.56 درصد به دست آمده است.
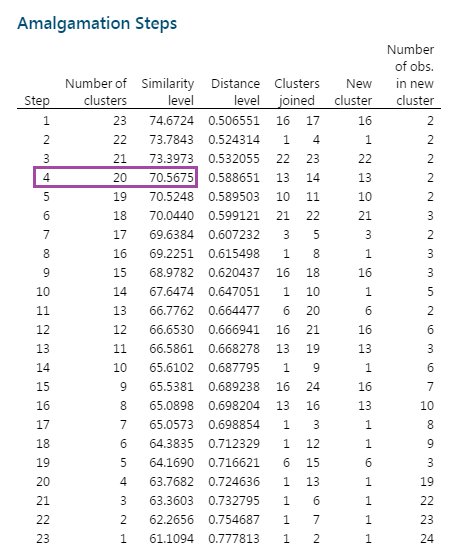
بنابراین پیشبینی میشود تعداد خوشههای صحیح در این مثال بین 20 تا 21 خوشه باشد.
برای این منظور در تنظیمات نرمافزار مقدار 71 را در برابر کادر Similarity level وارد میکنیم.
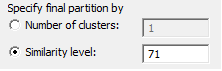
با OK کردن نتایج جدید در Final partition مشاهده میشود.

همانگونه که دیده میشود چنانچه مقدار 71 درصد را به عنوان Cut off در نظر بگیریم، تعداد 21 خوشه برای این مثال به دست میآید.
گراف Show dendrogram در این نحوه تحلیل جدید نیز خوشههای تشکیل شده را نشان میدهد.
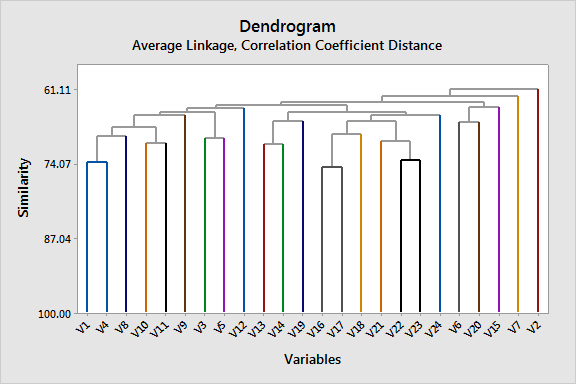
بنابراین با استفاده از نرمافزار Minitab به سادگی میتوانیم به خوشه بندی سوالات بپردازیم.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2018). Cluster Variables using Minitab. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/clustering-analysis-with-minitab/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2018). Cluster Variables using Minitab. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/clustering-analysis-with-minitab/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.