نمودار احتمال P-P Plot در نرمافزار SPSS
Probability Plot
برای ما بسیار اهمیت دارد که بدانیم آیا مجموعهای از دادهها دارای توزیع آماری شناخته شدهای هستند یا خیر. با این مطلب بارها مواجه شدهایم که آیا دادههای ما نرمال هستند؟ آیا آنها دارای نظم ریاضی و از قبل شناخته شدهای با نام توزیع نرمال Normal Distribution (و یا هر توزیع آماری دیگری) میباشند؟
پاسخ به این سوال در محدوده روشها و تحلیلهایی با نام نیکویی برازش Goodness of Fit قرار دارد. ما در آنجا با استفاده از ابزارها و روشهایی که در اختیار داریم، آزمون میکنیم که آیا دادهها از یک توزیع آماری پیروی میکنند (فرض صفر) و یا فاقد آن توزیع آماری هستند (فرض مقابل).
به عنوان مثال در لینک (آزمون نرمال بودن داده ها Normality Test در نرم افزار SPSS) بررسی کردهایم که آیا دادهها دارای توزیع نرمال هستند یا فاقد این توزیع میباشند.
حال خوب است که ابزاری وجود داشته باشد که به جای کار با آزمونهای آماری به صورت سادهتری به ما در فهم این مطلب که آیا دادهها دارای توزیع آماری خاصی میباشند یا خیر، کمک کند. این کار با استفاده از گرافهایی با نام پلات احتمال Probability Plot که به آن P-P Plot نیز گفته میشود، انجام خواهد شد.
در این مقاله به دنبال بیان و نحوه به دست آوردن نمودار احتمال و روش کار با آنها با استفاده از نرم افزار SPSS هستم. همانگونه که بیان کردم با استفاده از این نمودارها میتوانیم دریابیم آیا دادههای ما توزیع آماری خاصی را دارند یا خیر.
Example
به دادههای این مثال که مربوط به اطلاعاتی درباره جنسیت، تحصیلات، حقوق و تجربه کاری 473 نفر از کارکنان یک کارخانه تولیدی است، توجه کنید. فایل دیتا این مقاله را میتوانید از اینجا Probability Plot دریافت کنید.
من در این دادهها به دنبال بررسی این مطلب هستم که آیا میتوان توزیعهای آماری خاصی را بر این دادهها در نظر گرفت یا خیر. به عنوان مثال و برای شروع کار در پی بررسی این مطلب هستم که آیا Variable با نام Beginning Salary که در ستون salbegin آمده است و به معنای حقوق ماه اول استخدام این افراد میباشد، دارای توزیع نرمال است یا خیر.
واضح است همانگونه که در این لینک (آزمون نرمال بودن داده ها Normality Test در نرم افزار SPSS) نوشتهام، با استفاده از آزمونی مانند One-Sample Kolmogorov-Smirnov Test میتوانیم نرمال بودن این دادهها را تست کنیم. با این حال من در این مقاله میخواهم این کار را با استفاده از نمودار و گرافی با نام P-P Plot انجام دهم.
برای انجام این کار در نرمافزار SPSS از مسیر زیر استفاده میکنیم.
Analyze → Descriptive Statistics → P-P Plots
تنظیمات نرمافزار
Setting
هنگامی که به مسیر بالا در نرمافزار SPSS میرویم، پنجره زیر با نام P-P Plots برای ما باز میشود.
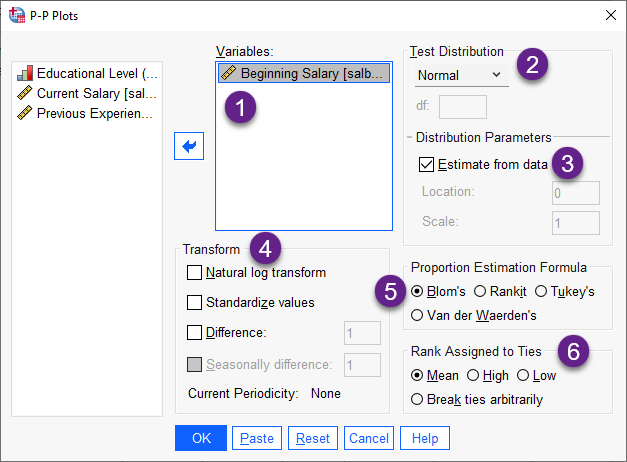
من بخشهای مختلف آن را شمارهگزاری کردهام و از روی همان شمارهها به توضیح پنجره P-P Plots و تنظیمات آن میپردازم.
1- در این بخش کمیت یا کمیتهایی را که میخواهیم نمودار احتمال آنها را رسم کنیم، قرار میدهیم. به عنوان مثال من میخواهم برای Beginning Salary نمودار احتمال رسم کنم. بنابراین آن را در کادر Variables قرار میدهم.
2- بخش Test Distribution همان جایی است که انتخاب میکنیم که میخواهیم کدام توزیع آماری را بر دادههای خود، تست کنیم. در تصویر زیر میتوانید این کادر بازشو و انواع توزیعهای آماری موجود در آن را ببینید.
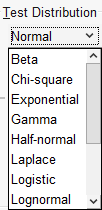
از آنجایی که من میخواهم نمودار احتمال نرمال را بر دادههای Beginning Salary رسم کنم، بنابراین گزینه Normal را انتخاب کردهام.
3- در قسمت Distribution parameters نرمافزار از ما پارامترهای توزیع انتخابی را میخواهد. به صورت پیشفرض گزینه Estimate from data انتخاب شده است. این به معنای آن است که نرمافزار جهت رسم نمودار احتمال توزیع انتخاب شده، از همان دادههای کمیت قرار داده شده در بخش Variables استفاده میکند.
در اینجا به معنای این است که نرمافزار جهت رسم نمودار احتمال نرمال برای دادههای Beginning Salary از میانگین و انحراف معیار همین دادهها استفاده خواهد کرد. چنانچه نخواهیم از دادهةای خودمان استفاده کنیم، میتوانیم تیک این گزینه را برداریم و پارامترهای دلخواه خود را قرار دهیم.
4- شاید علاقمند باشیم به جای رسم نمودار احتمال بر روی دادههای واقعی و نوشته شده در فایل دیتا، از دادههای تبدیل شده استفاده کنیم. در این صورت در بخش Transform میتوانیم یکی از گزینههای Natural log transform (به معنای اینکه دادهها را به LN خودشان تبدیل میکند) یا گزینه Standardize values (که دادهها را استاندارد میکند، یعنی میانگین دادهها صفر و انحراف معیار آنها یک میشود. این گزینه در دادههای سری زمانی کاربرد دارد.) و یا گزینه Difference (که از دادهها تفاضل میگیرد، عدد مرتبه تفاضل را میتوان در کادر روبهرو نوشت)، انتخاب کنیم.
یک نکته دربارهی تفاضلگیری اینکه دادهها با استفاده از رابطهی $ \displaystyle {{{y}’}_{t}}={{y}_{t}}-{{y}_{{t-1}}}$ به تفاضل مرتبه اول تبدیل میشوند. یا مثلاً بر مبنای رابطهی $ \displaystyle {{{y}’}_{t}}={{y}_{t}}-{{y}_{{t-m}}}$ به تفاضل مرتبه m خودشان تبدیل میشوند. این موضوعات بیشتر در مباحث سری زمانی و هنگامی که با دادههای از این نوع روبهرو هستیم، مطرح میشود.
با این حال ما معمولاً ترجیح میدهیم بر روی خود دادههای اصلی کار کنیم و نمودار احتمال آنها را رسم کنیم. به همین دلیل نرمافزار SPSS نیز به صورت پیشفرض هیچکدام از گزینهها را انتخاب نکرده است. ما نیز گزینههای تبدیلات را انتخاب نمیکنیم.
5- در بخش Proportion estimation formula میتوانید انواع فرمولهای براورد نسبت که در محاسبه و رسم نمودار احتمال مورد استفاده قرار میگیرد را مشاهده کنید. علاقمند بودید این لینک را ببینید. نرمافزار SPSS به صورت پیشفرض گزینه Blom’s را انتخاب کرده است، ما نیز همین گزینه را قرار میدهیم.
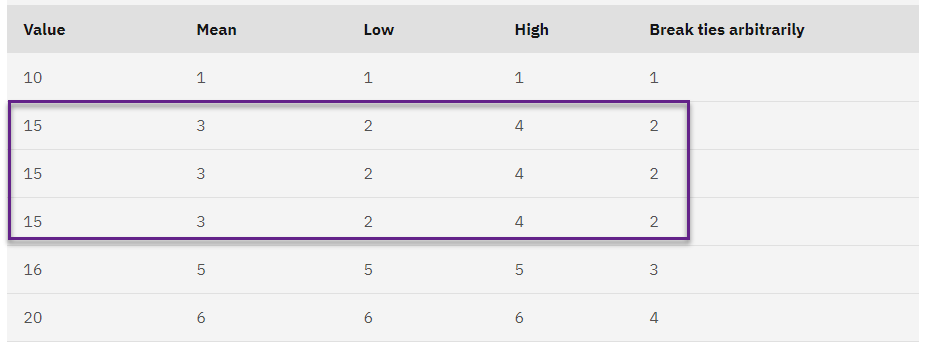
6- در بخش Rank assigned to ties میتوانید روشهای مختلف تبدیل گرهها (یعنی اعداد مساوی با هم) به رتبهها را مشخص کنید. به عنوان مثال جدول زیر نشان میدهد که چگونه روشهای مختلف، رتبهها را به مقادیر گره اختصاص میدهد.
نتایج نرم افزار
Output & Results
هنگامی که OK میکنیم، در پنجره Output میتوانیم خروجی و نتایج نرمافزار را مشاهده کنیم. در ابتدا جدول Estimated Distribution Parameters مشاهده میشود.

در این جدول پارامترهای مکان Location (همان میانگین) و مقیاس Scale (انحراف معیار) کمیت Beginning Salary به دست آمده است.
آنچه ما به دنبال آن بودیم یعنی نمودار احتمال (در اینجا توزیع نرمال) در ادامه نتایج نرمافزار آمده است. در تصویر زیر آن را ببینید.
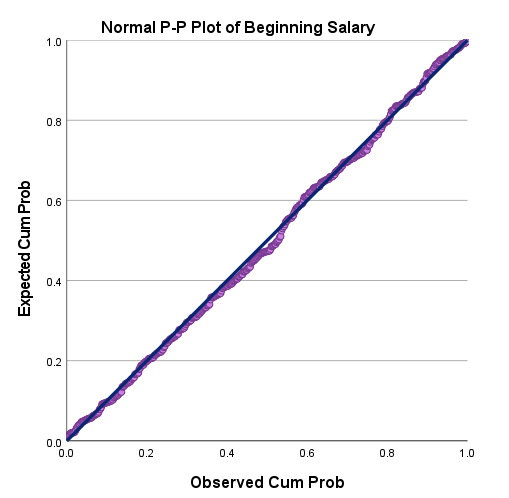
حال بیایید در ادامه دربارهی نمودار احتمال به دست آمده توضیح دهیم. در محور افقی که با نام Observed Cum Prob قرار دارد، احتمال تجمعی مشاهده شده قرار دارد. در واقع نرمافزار برای محاسبه این بخش، همه دادههای مشاهده شده (یعنی اعداد ستون Beginning Salary) را از کوچک به بزرگ مرتب میکند. سپس محاسبه میکند که کوچکترین عدد، صدک Percentile شماره چند است. به همین ترتیب برای هر عدد، صدک متناظر با آن را به دست می آورد و آن را در محور افقی قرار میدهد.
حال در محور عمودی که با نام Expected Cum Prob قرار دارد، احتمال تجمعی مورد انتظار (یعنی اگر قرار باشد دادهها دارای توزیع احتمال نرمال باشند) به دست میآید. در واقع در اینجا احتمال $ \displaystyle P\left( {X\le x} \right)$ محاسبه میشود.
به این ترتیب هر دایره در نمودار احتمال بالا، به معنای اعداد محور X یعنی احتمال تجمعی مشاهده شده و محور Y یعنی احتمال تجمعی مورد انتظار، به ازای هر کدام از مقادیر و اعداد ستون Beginning Salary است.
خب واضح است که اگر قرار باشد، دادهها دارای توزیع آماری خاصی باشند (در اینجا مثلاً توزیع نرمال داشته باشند) باید اعداد محور X و Y در نمودار احتمال با هم برابر باشند. به عبارت سادهتر باید دایرهها در اطراف و نزدیک به خط پررنگ نیمساز، قرار گرفته باشند.
هر چقدر که نقاط و دایرهها به خط نیمساز نزدیک باشند، به معنای نزدیک بودن دادهها، به توزیع مورد بررسی است و هر چقدر که از خط نیمساز فاصله داشته و از آن دور باشند، به معنای این است که دادهها فاقد آن توزیع هستند.
در این مثال، به نظر میرسد که نقاط در اطراف خط نیمساز قرار دارند. بنابراین میتوان دادههای ستون Beginning Salary را دارای توزیع مورد انتظار یعنی توزیع نرمال دانست.
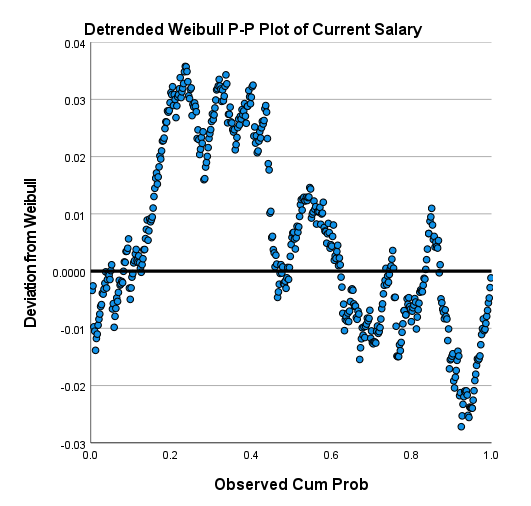
علاوه بر گراف احتمال، یک نمودار دیگر نیز توسط نرمافزار SPSS رسم شده است. در تصویر زیر آن را ببینید.
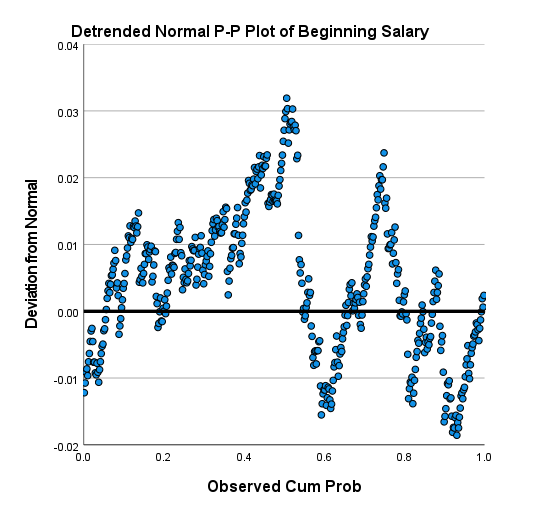
محور افقی در این گراف، همان احتمال تجمعی مشاهده شده است. با این حال محور عمودی اختلاف از توزیع نرمال را نشان میدهد. خط Y = 0 نیز که در گراف مشخص است، این گراف به عنوان یک ابزار قضاوت به منظور بررسی میزان انحراف از توزیع نرمال، ارایه شده است. هر چقدر دایرهها و نقاط بدون روند و به صورت تصادفی در اطراف این خط قرار گرفته باشند، به معنای تایید فرض نرمال بودن دادهها در نظر گرفته میشود.
چند مثال دیگر
More Examples
در دادههای این مقاله، Variableهای دیگری نیز وجود داشت. مانند تعداد سالهای تحصیل افراد، حقوق حال حاضر آنها و تعداد ماههای سابقه کاری. در ادامه میخواهیم چند آزمون و تست دیگر نیز انجام دهیم. آنها را ببینید.
![]() میخواهیم بدانیم آیا توزیع تعداد سالهای تحصیل افراد در این مطالعه، دارای توزیع یکنواخت Uniform است یا خیر، فاقد این توزیع آماری است. علاقمند بودید در این لینک میتوانید اطلاعاتی درباره توزیعهای آماری به دست بیاورید.
میخواهیم بدانیم آیا توزیع تعداد سالهای تحصیل افراد در این مطالعه، دارای توزیع یکنواخت Uniform است یا خیر، فاقد این توزیع آماری است. علاقمند بودید در این لینک میتوانید اطلاعاتی درباره توزیعهای آماری به دست بیاورید.
به منظور انجام این تست، در بخش Test Distribution پنجره P-P Plots گزینه ![]() را انتخاب میکنیم. با بقیه تنظیمات کاری نداریم و OK میکنیم. نتایج و گرافها در ادامه آمده است.
را انتخاب میکنیم. با بقیه تنظیمات کاری نداریم و OK میکنیم. نتایج و گرافها در ادامه آمده است.
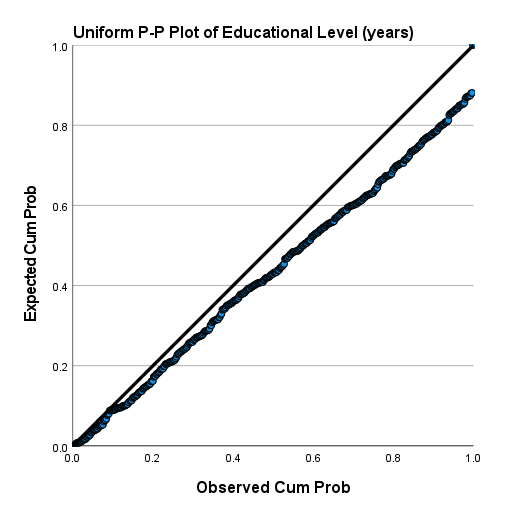
نتیجه به دست آمده نشان میدهد دادهها از توزیع یکنواخت انحراف دارند و به نظر نمیرسد تعداد سالهای تحصیل آنها دارای توزیع Uniform باشد. گراف Detrended Uniform P-P Plot این نظر را تایید میکند.
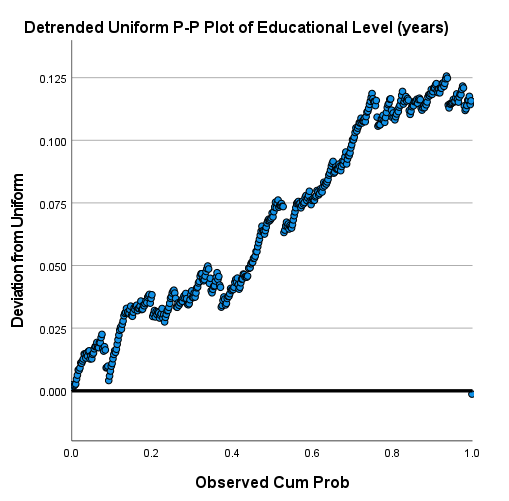
آنچه که واضح است این است که دادهها از توزیع یکنواخت، انحراف دارند و بنابراین نمیتوان سالهای تحصیل افراد را دارای توزیع یکنواخت دانست.
چند آزمون و تست دیگر نیز انجام دهیم. آنها را ببینید.
![]() به عنوان یک مثال دیگر میخواهیم بدانیم آیا توزیع حقوق حال حاضر افراد، دارای توزیع وایبل Weibull است یا خیر.
به عنوان یک مثال دیگر میخواهیم بدانیم آیا توزیع حقوق حال حاضر افراد، دارای توزیع وایبل Weibull است یا خیر.
به منظور انجام این تست، در بخش Test Distribution پنجره P-P Plots گزینه ![]() را انتخاب میکنیم. نتایج و گرافها در ادامه آمده است.
را انتخاب میکنیم. نتایج و گرافها در ادامه آمده است.
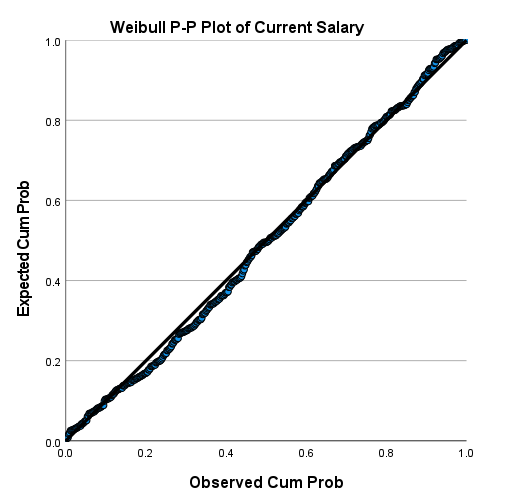
گراف به دست آمده نشان میدهد دادهها یعنی حقوق حال حاضر افراد تاحد زیادی دارای توزیع وایبل میباشند. گراف Detrended Weibull P-P Plot این نظر را تایید میکند.
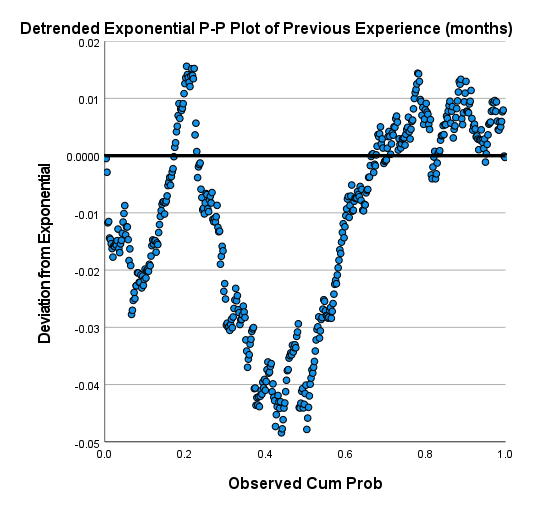
![]() به عنوان یک مثال دیگر میخواهیم بدانیم آیا توزیع ماههای تجربه کاری افراد، دارای توزیع نمایی Exponential است یا خیر.
به عنوان یک مثال دیگر میخواهیم بدانیم آیا توزیع ماههای تجربه کاری افراد، دارای توزیع نمایی Exponential است یا خیر.
به منظور انجام این تست، در بخش Test Distribution پنجره P-P Plots گزینه ![]() را انتخاب میکنیم. نتایج و گرافها در ادامه آمده است.
را انتخاب میکنیم. نتایج و گرافها در ادامه آمده است.
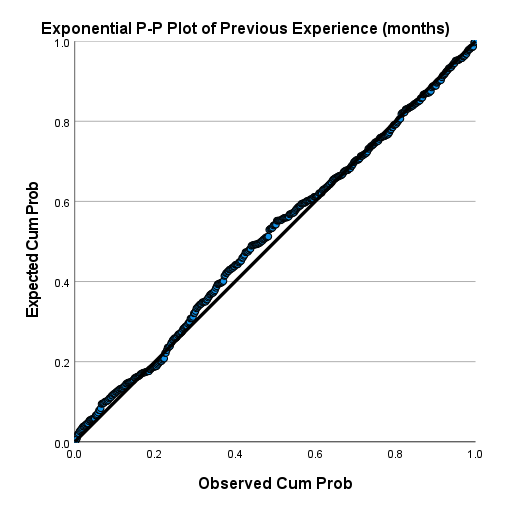
گراف به دست آمده نشان میدهد تعداد ماههای تجربه کاری، دارای توزیع نمایی میباشد. هر چند مقداری انحراف در آن دیده میشود. گراف Detrended Exponential P-P Plot این نظر را تایید میکند.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Probability Plot in SPSS Software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/p-p-plot-spss.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Probability Plot in SPSS Software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/p-p-plot-spss.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.