توزیع فراوانی Frequency distribution در گراف پد
این یک مثال ساده در گراف پد پریسم است. اصولاً هنگامی که میخواهیم آموزش نرمافزار را شروع کنیم از مثال Frequency Distribution شروع میکنیم.
با استفاده از این مثال به دنبال یافتن نحوه پراکندگی و توزیع دادهها، هستیم. در نرمافزار گراف پد مثالی با نام Frequency distribution در دسته تحلیلهای Column و در بخش Special uses of column tables صفحه ورودی نرمافزار گراف پد قرار دارد.
فایل مثال را میتوانید از اینجا دانلود کنید.
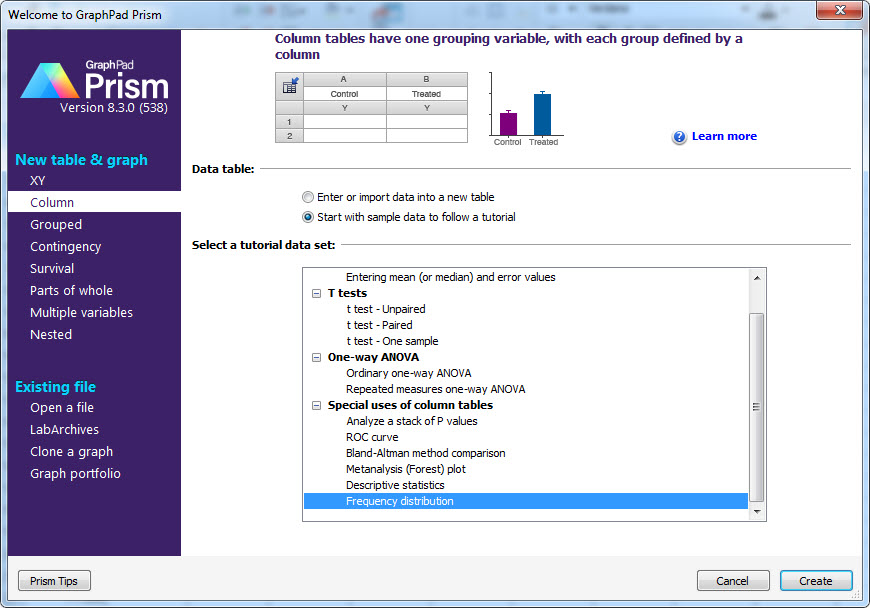
وقتی مثال را Create میکنیم با دادههای زیر روبهرو میشویم. همانگونه که مشاهده میکنید 50 داده در یک ستون با نام Frequency قرار گرفتهاند. میخواهیم پراکندگی دادهها را به دست آورده و برای آنها یک نمودار هیستوگرام، رسم کنیم. در این نمودار محور X مقادیر و محور Y فراوانی آنها قرار میگیرد.
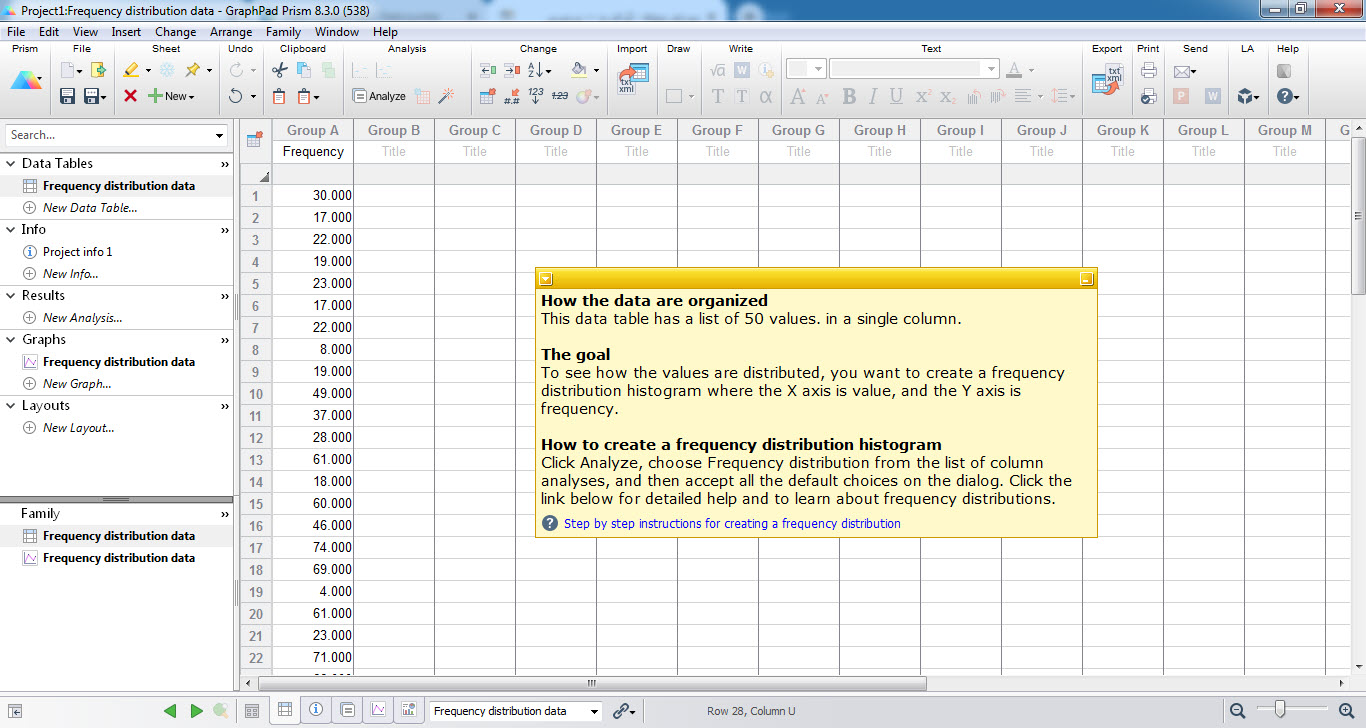
به این منظور و جهت مشاهده نتایج به دست آمده در همان شیت دادهها، بر روی دکمه Analyze کلیک میکنیم. در پنجره Analyze data باز شده، تحلیل Frequency distribution را انتخاب میکنیم.
پنجره تنظیمات با نام Parameters: Frequency Distribution برای ما به صورت زیر باز میشود.
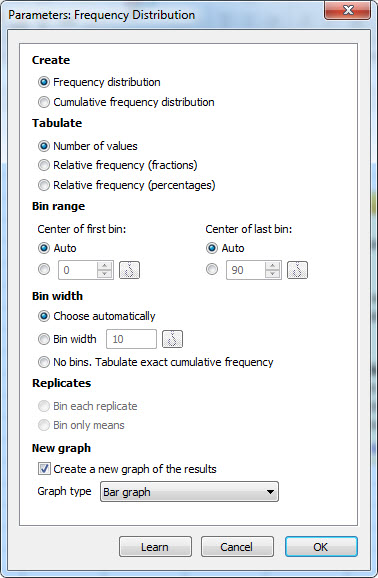
- Create.
در این بخش انتخاب میکنیم که توزیع فراوانی برای ما به دست بیاید و یا توزیع فراوانی تجمعی. همانگونه که میدانیم در توزیع فراوانی، تعداد در هر رده و دسته برای ما مشخص میشود و در توزیع فراوانی تجمعی، تعداد هر رده با ردههای قبل از خود جمع میشود.
- Tabulate.
نحوه نمایش تعداد مقادیر، به صورت فراوانی، کسری و یا درصدی باشد. در ادامه سعی میکنیم تمام این تنظیمات را در خروجیهای نرمافزار بیاوریم.
- Bin range.
هدف از توزیع فراوانی دادهها، گروهبندی و دستهبندی آنها به چند رده است. در این بخش مرکز اولین و آخرین رده، مشخص میشود. این کار میتواند به صورت اتوماتیک و توسط نرمافزار گراف پد و یا به صورت دستی و توسط کاربر انجام شود.
- Bin width.
طول هر رده چقدر باشد. به عبارت دیگر در هر رده فاصله بین کمترین عدد و بیشترین عدد، به چه اندازهای باشد. انتخاب گزینه No bins. Tabulate exact cumulative frequency سبب میشود که اصلاً بر روی دادهها گروهبندی انجام نشود و فراوانی برای خود مقادیر اصلی به دست بیاید.
- Replicates.
چنانچه در سطرها تکرار داشته باشیم، گروهبندی دادهها میتواند بر روی تکرارها نیز انجام شود. گزینه Bin each replicate سبب میشود تکرارها نیز در گروهبندی قرار گیرند. گزینه Bin only mean فقط میانگین تکرارها در هر سطر را به عنوان نماینده آن سطر در نظر گرفته و آن را در گروهبندی مشارکت میدهد.
- New graph.
با انتخاب این گزینه، نرمافزار برای ما یک گراف جدید از دادههای گروهبندی شده، رسم میکند. این نمودار میتواند به صورت میلهای، نقطهای و یا هیستوگرام باشد.
در ادامه سعی کردهایم با چندین بار OK کردن و انتخاب گزینههای مختلف در پنجره Parameters: Frequency Distribution نتایج مختلفی به دست بیاوریم.
در ابتدا تنظیمات پنجره Parameters: Frequency Distribution را به صورت پیشفرض زیر میپذیریم.
با OK کردن، شیت با نام Histogram of Frequency distribution data در فولدر Results پنجره سمت چپ نرمافزار گراف پد، به صورت زیر ساخته میشود.
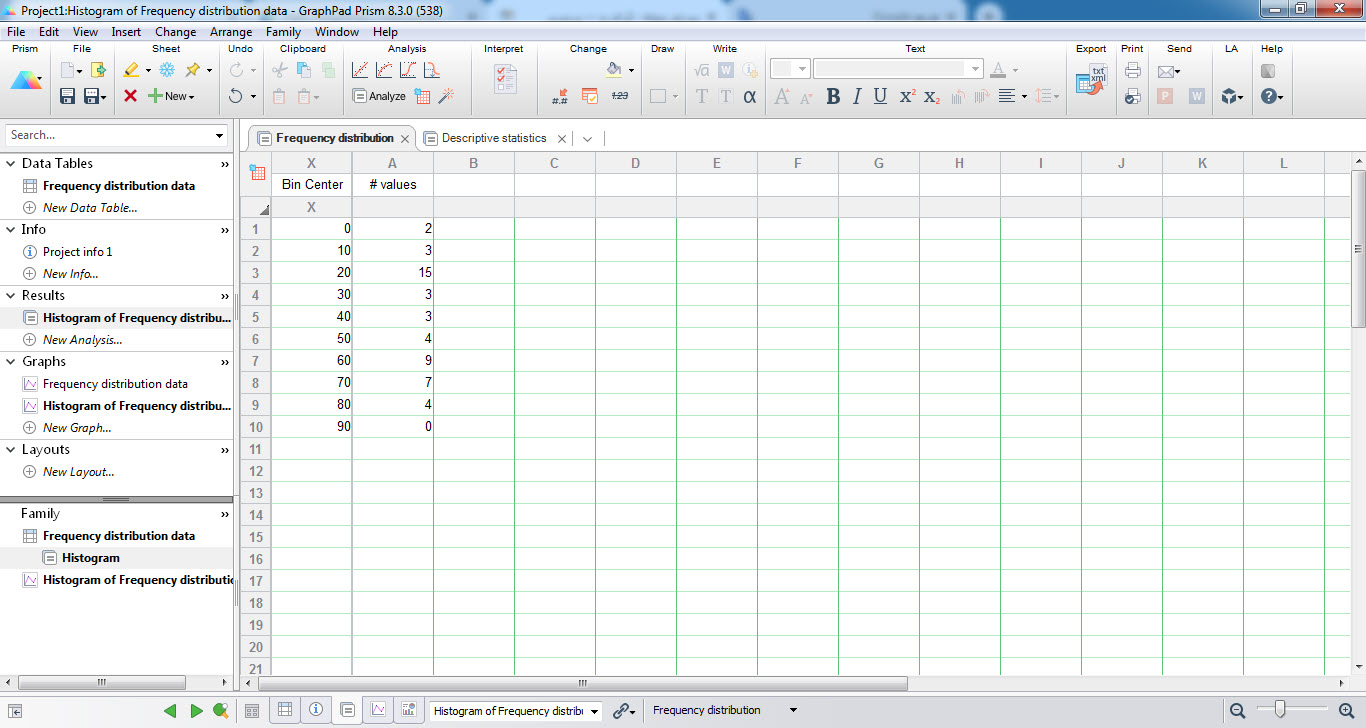
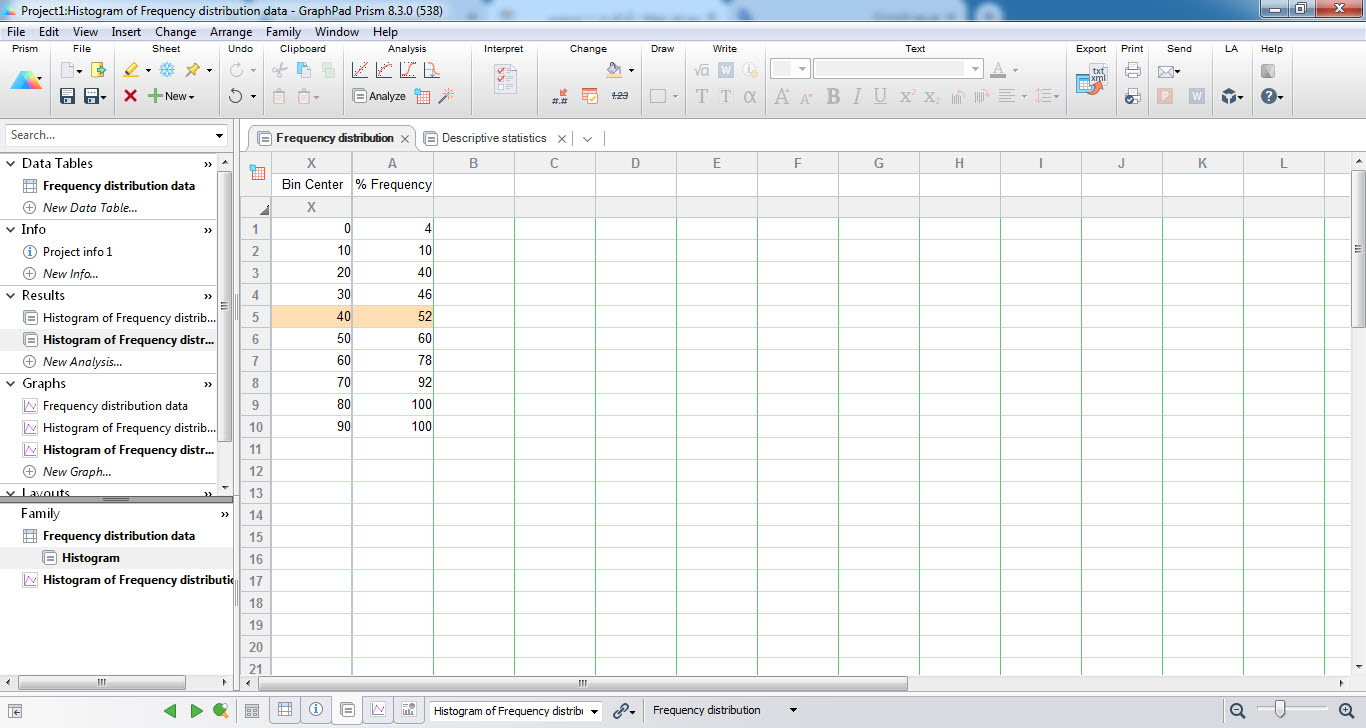
شیت نتایج در زبانههای با نامهای Frequency distribution و Descriptive statistics آمده است. در زبانه Frequency distribution به سادگی میتوان مرکز هر رده و فراوانی موجود در آن رده را مشاهده کرد.
به این نکته توجه کنید که اعداد نوشته شده در ستون Bin Center مرکز هر گروه میباشند. به عنوان مثال عدد 10 مرکز رده 5 تا 15 میباشد، ستون values # نشان میدهد در این رده 3 مقدار قرار دارند. به عنوان یک مثال دیگر عدد 60 مرکز رده 55 تا 65 بیانگر فراوانی 9 عدد در این گروه است و به همین ترتیب برای ردههای دیگر. به خاطر نیز دارید که در پنجره تنظیمات، طول هر رده، ده در نظر گرفته شده بود.
در زبانه Descriptive statistics میتوانید انواع آمارههای توصیفی، دادههای این مثال را مشاهده کنید.
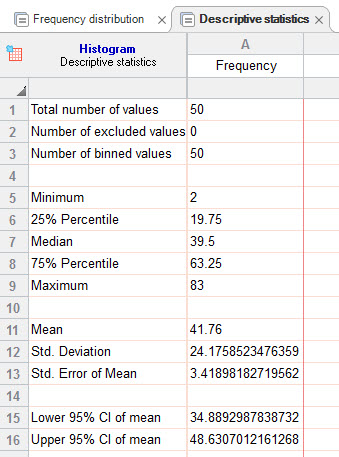
به عنوان مثال، میانگین 50 عدد مورد بررسی برابر با 41.76 و انحراف معیار آنها 24.17 به دست آمده است.
خوب است به فولدر Graphs نیز برویم و نمودار میلهای انتخاب شده در بخش New graph را مشاهده کنیم.

در این نمودار، مرکز هر رده به همراه فراوانی آن رده قابل مشاهده است.
همانگونه که قبلاً نیز گفتیم، خوب است با دیگر تنظیمات پنجره Parameters: Frequency Distribution نیز آشنا شده و نتایج به دست آمده از آنها را ببینیم. مثلاً علاقمند هستیم توزیع فراوانی تجمعی و درصد فراوانی از نتایج داشته باشیم.
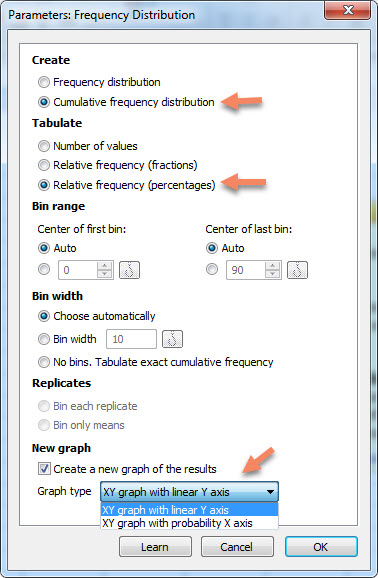
با این انتخاب، نوع نمودار قابل رسم در بحش New graph به صورت خطی و یا احتمالی، خواهد بود. هر دو نمودار را رسم خواهیم کرد.
با این تنظیمات بار دیگر OK کنید. نتایج و نمودار به دست آمده به صورت زیر خواهد بود.
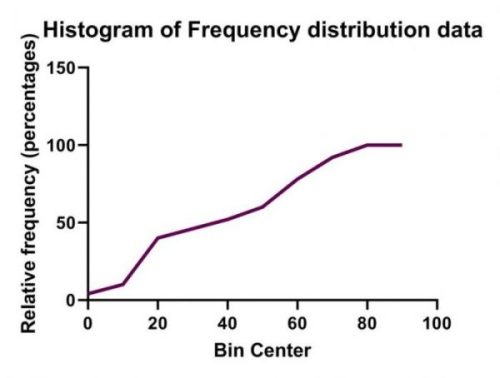
همان زبانههای Frequency distribution و Descriptive statistics دیده میشود. به عنوان مثال نتایج نشان میدهد در گروه 35 تا 45 که مرکز آن 40 است، تا 52 درصد دادهها قرار دارند. این مطلب به معنای آن است که 52 درصد دادهها کوچکتر مساوی عدد 45 هستند.
با نتایج زبانه Descriptive statistics کاری نداریم، زیرا ما بر روی دادهها اصلاح و ویرایشی انجام ندادهایم. نتایج این زبانه، همانند تنظیمات قبلی هستند.
در فولدر Graphs پنجره راهبری نرمافزار، یک شیت جدید ساخته شده است. نمودار رسم شده این شیت را میتوانید در شکل زیر ببینید.
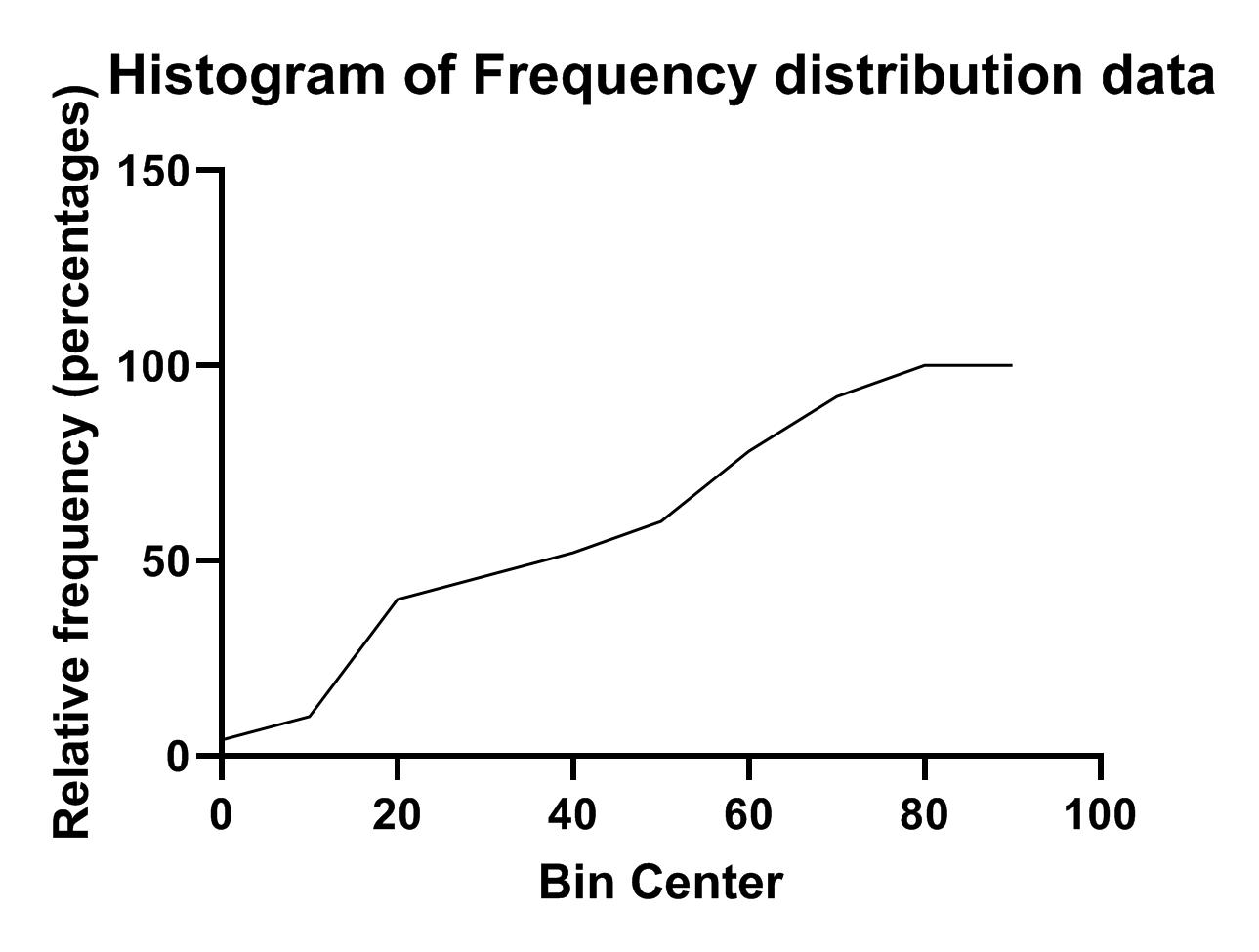
در این نمودار مرکز هر گروه در محور X و درصد فراوانی تجمعی هر گروه در محور Y آمده است. اگر در کادر Graph type بخش New graph پنجره تنظیمات Parameters: Frequency Distribution گزینه XY graph with probability X axis را انتخاب میکردیم، نمودار زیر برای ما به دست میآمد.
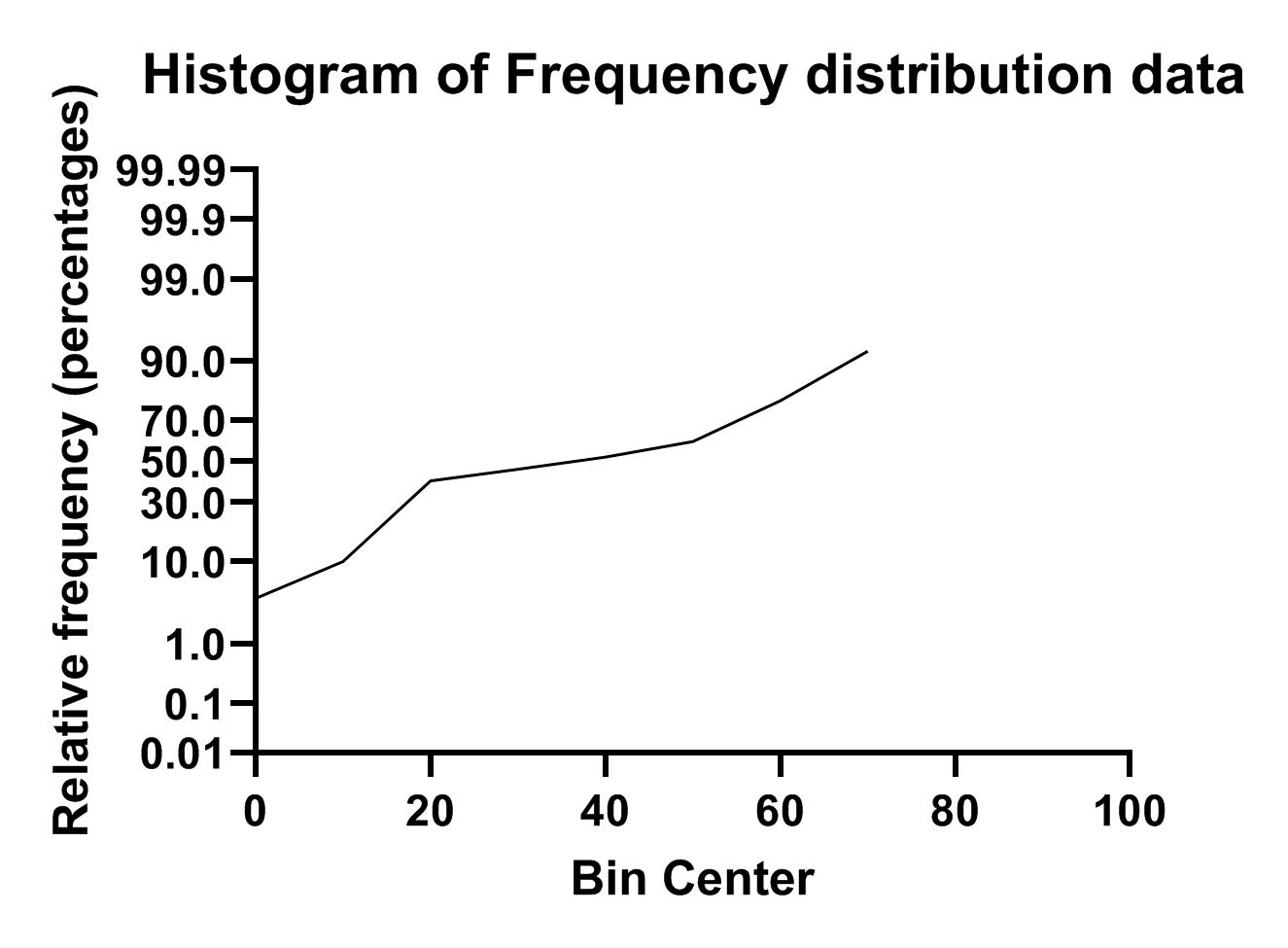
این نمودار همان نمودار خطی بالاتر است که محور Y در آن به صورت احتمالی از صفر تا صد، درجهبندی شده است. دادههای گرافها را میتوان در همان شیت نتایج و زبانه Frequency distribution مشاهده کرد.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). Frequency distribution in the GraphPad Prism Software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/frequency-distribution/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). Frequency distribution in the GraphPad Prism Software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/frequency-distribution/.php