کمیتهای ساختگی Dummy Variables در نرمافزار SPSS
Creating Dummy Variables
هنگامی که دادههای خود را با استفاده از رگرسیون چندگانه تحلیل میکنید و هر یک از کمیتهای مستقل شما در مقیاس اسمی Nominal یا رتبهای Ordinal اندازهگیری شدهاند، باید بدانید که چگونه کمیتهای ساختگی یا Dummy Variables، ایجاد و نتایج آنها را تفسیر کنید.
این مطلب، به این دلیل است که کمیتهای مستقل اسمی و رتبهای، نمیتوانند مستقیماً وارد یک تحلیل رگرسیون چندگانه شوند. بلکه باید به کمیتهای ساختگی تبدیل شوند. البته ما معمولاً کمیتهای رتبهای را میتوانیم به عنوان کمیت طبقهبندی شده Categorical Variable وارد مدل رگرسیونی خود کنیم. کمیتهای رتبهای همچنین میتوانند گاهی اوقات به عنوان کمیت مستقل پیوسته وارد مدل رگرسیون چندگانه شوند. در این صورت نیازی به تبدیل آنها به Dummy Variable نیست. معمولاً و بیشتر کمیتهای ساختگی بر روی Nominalها ایجاد میشوند.
در این راهنما نشان میدهیم که چگونه کمیتهای ساختگی را بر روی دیتا خود ایجاد کنید. فایل دیتای این مثال را میتوانید از اینجا دریافت کنید.
در تصویر زیر میتوانید بخشی از دادههای این مثال را مشاهده کنید.
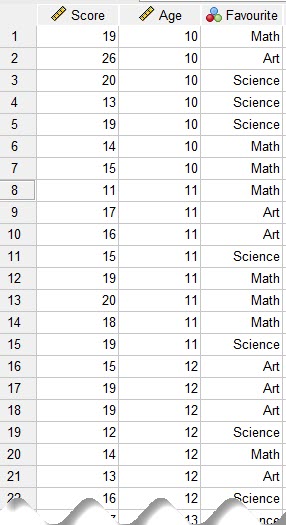
این مثال به بررسی ارتباط بین معدل تحصیلی، سن و علاقمندی 30 دانشآموز به کارهای علمی، هنری و ریاضی، میپردازد. ما به دنبال این هستیم با استفاده از یک مدل رگرسیونی ارتباط بین سن و علاقمندی به عنوان کمیتهای مستقل Independent Variables (IV) را با نمره معدل دانشآموزان به عنوان کمیت وابسته Dependent Variable (DV) به دست بیاوریم.
موضوعی که در این متن میخواهیم به آن بپردازیم این است که Favorite یک کمیت Nominal است و قرار گرفتن آن در مدل رگرسیونی، تفسیر نتایج و ضریب رگرسیونی به دست آمده را مشکل میکند. فرض کنید ضریب رگرسیونی آن، مثبت شده باشد. سوال این است از مثبت شدن این ضریب چه تفسیری ارایه دهیم؟ در اینجا که با اعداد و اندازههای حتی رتبهای روبهرو نیستیم. بلکه با تعدادی کد 1، 2 و 3 مواجهایم.
به همین دلیل است که در این مطالعات، طراحی و ساختن کمیتهای ساختگی، اهمیت پیدا میکند. کار ما این است که از روی Favorite، کمیتهایی به نام Dummy Variables میسازیم. سپس آنها را وارد مدل رگرسیونی خود میکنیم.
ابتدا بیایید چیزهای بیشتری درباره Dummy Variable بدانیم. در ادامه مسیر انجام این کار در نرمافزار SPSS را مشاهده میکنیم.
تعداد کمیتهای ساختگی مورد نیاز
The number of dummy variables you need to create
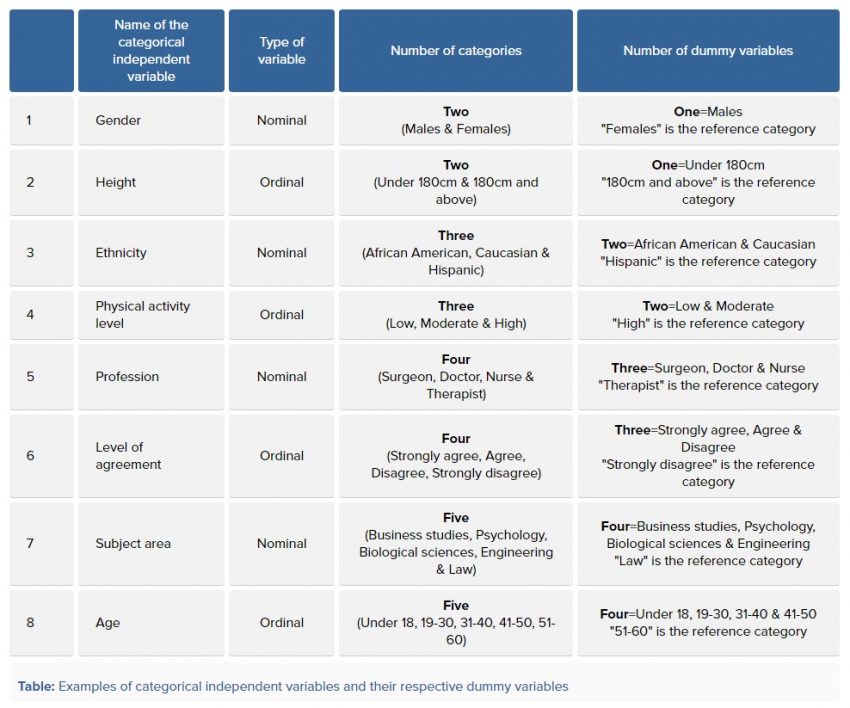
تعداد کمیتهای ساختگی به این بستگی دارد که کمیت مستقل گروهبندی شده، چند دسته و Level دارد. همواره تعداد کمیتهای ساختگی یکی کمتر از تعداد دستههای کمیت مستقل گروهبندی شده است.
به عنوان مثال، اگر یک کمیت مستقل طبقهبندی شده با سه دسته دارید (مثلاً درس مورد علاقه با سه دسته ریاضی، علوم و هنر)، به این ترتیب دو کمیت ساختگی ایجاد میکنید و یک دسته را به عنوان رفرنس Reference Category انتخاب میکنید. به عنوان مثال، ریاضی و علوم به کمیتهای ساختگی تبدیل میشوند و هنر به دسته رفرنس تبدیل میشود. در جدول زیر میتوانید چند مثال دربارهی تعداد کمیتهای ساختگی و دسته رفرنس آنها، مشاهده کنید.
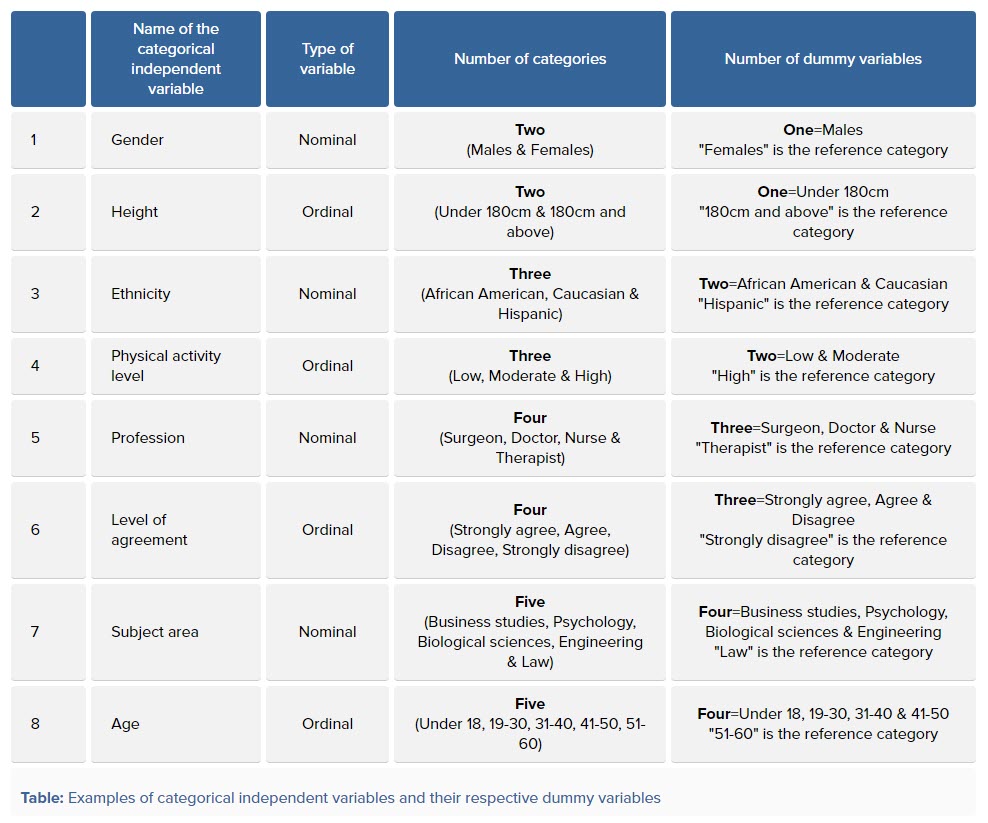
همانگونه که در جدول بالا مشاهده میکنید، به ازای مثالهای مختلف که کمیتهای Nominal یا Ordinal هستند، تعداد گروهبندیهای آنها بیان شده است. همچنین برای هر کدام از آنها تعداد کمیتهای ساختگی و گروه رفرنس پیشنهادی نیز آمده است.
به عنوان مثال اگر برای کمیتی با نام Level of agreement، چهار گروه رتبهای به صورت Strongly agree، Agree، Disagree و Strongly disagree آمده است، تعداد کمیتهای ساختگی آن سه تا و یکی از آنها مثلاً Strongly disagree به عنوان گروه رفرنس در نظر گرفته میشود.
مزایای استفاده از کمیتهای ساختگی
Advantages of using dummy variables
ایجاد و طراحی کمیتهای ساختگی برای هر دسته از کمیت مستقل طبقهبندی شده، به این دلیل سودمند است. الف) انعطافپذیرتر است و ب) امکان مقایسههای متعدد را فراهم میکند. در ادامه به اختصار به این مزایا میپردازیم.
- انعطافپذیرتر است.
هنگامی که یک Dummy Variable برای هر دسته از کمیت مستقل طبقهبندی شده ایجاد کردید، میتوانید هر کدام از دستهها را به عنوان گروه مرجع در نظر بگیرید.
در مثال ما، دسته هنر را به عنوان مرجع در نظر گرفتیم، به این معنی که ریاضی و علوم را به معادله رگرسیون چندگانه، وارد میکنیم. با این حال، اگر بعداً نظر خود را در مورد انتخاب دسته مرجع عوض کردیم، مثلاً اکنون میخواهیم دسته علوم را به عنوان مرجع در نظر بگیریم. میتوانیم کمیتهای ساختگی ریاضی و هنر را به معادله رگرسیون چندگانه وارد کنیم زیرا کمیت ساختگی هنر را نیز داریم.
- اجازه میدهد تا چندین مقایسه انجام شود.
ضریب یک Dummy Variable نشان دهنده تفاوت بین دستهای که کمیت ساختگی را نشان میدهد و دسته مرجع میباشد.
برای مثال، چنانچه هنر دسته مرجع باشد، ضریب کمیت ساختگی ریاضی نشاندهنده تفاوت در کمیت وابسته (یعنی معدل) بین دستههای هنر و ریاضی است.
البته به این نکته توجه کنید که با استفاده از این روش، ترکیب و مقایسه همه دستهها امکانپذیر نخواهد بود. این مشکل با استفاده از قرار دادن دستههای مرجع مختلف، قابل حل است.
طراحی کمیت ساختگی
How to create dummy variables and dummy coding
بیایید با در نظر گرفتن کمیت مستقل Nominal مثال، یعنی Favorite شروع کنیم که دارای سه دسته ریاضی، علوم و هنر است. از آنجایی که سه دسته وجود دارد، باید دو کمیت ساختگی، ایجاد شود و یک دسته مرجع که نشاندهنده Reference Category باشد.
به این نکته نیز توجه کنید که هدف ما برازش یک مدل رگرسیونی بر دادهها است. با این حال به دلیل اینکه یکی از Independent Variable ها یعنی Favorite که علاقمندی به رشتههای مختلف را نشان میدهد، کمیتی اسمی و Nominal است، جهت ورود این کمیت به مدل رگرسیونی، کمیتهای ساختگی یا همان Dummy Variableها را میسازیم. این کار با استفاده از سطوح و گروههای مختلف همان کمیت Favorite انجام میشود.
به عنوان مثال، اجازه دهید کمیت ساختگی شماره 1 نشاندهنده رده ریاضی و کمیت ساختگی شماره 2 نشاندهنده دسته علوم باشد. رده هنر را نیز به عنوان مرجع و رفرنس در نظر میگیریم.
به این نکته توجه کنید که این به دلخواه شماست که از کدام دسته به عنوان مرجع استفاده کنید. ما میتوانستیم علوم را به عنوان مرجع انتخاب کنیم. تنها دلیلی که ما این کار را نکردیم (هنر را به عنوان رفرنس برگزیدیم) این است که به طور پیشفرض SPSS از آخرین ردهای که در Value Labels کمیت Favorite کد قرار دادهاید به عنوان مرجع استفاده میکند. تصویر زیر را ببینید.
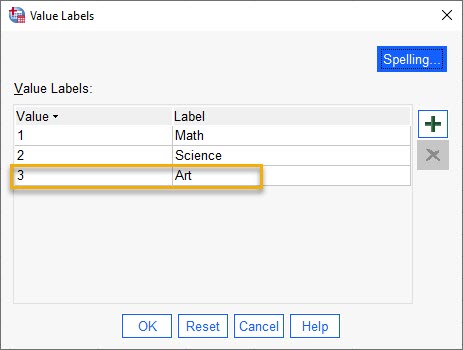
مطابق با تصویر بالا از آنجا که Art کد 3 و آخرین کد را گرفته است، به همین دلیل در پیشفرض نرمافزار به عنوان Reference Category در نظر گرفته میشود.
برای ایجاد کمیتهای ساختگی هنگامی که SPSS Statistics نسخه 22 یا بالاتر را دارید، گامهای 3 مرحلهای Create Dummy Variables زیر را دنبال کنید.

در ابتدا از مسیر زیر در نرمافزار SPSS استفاده میکنیم.
Transform→ Create Dummy Variables
با رفتن به این مسیر، پنجره زیر با نام Create Dummy Variables برای ما باز میشود.


در کادر Main Effect Dummy Variables و گزینهی Root Names یک نام دلخواه وارد کنید. این نام در ابتدای نام تمام کمیتهای ساختگی قرار میگیرد. به عنوان مثال من نام FS را قرار دادهام.
با سایر گزینهها کاری نداریم. به این ترتیب پنجره Create Dummy Variables را بار دیگر مشاهده کنید.
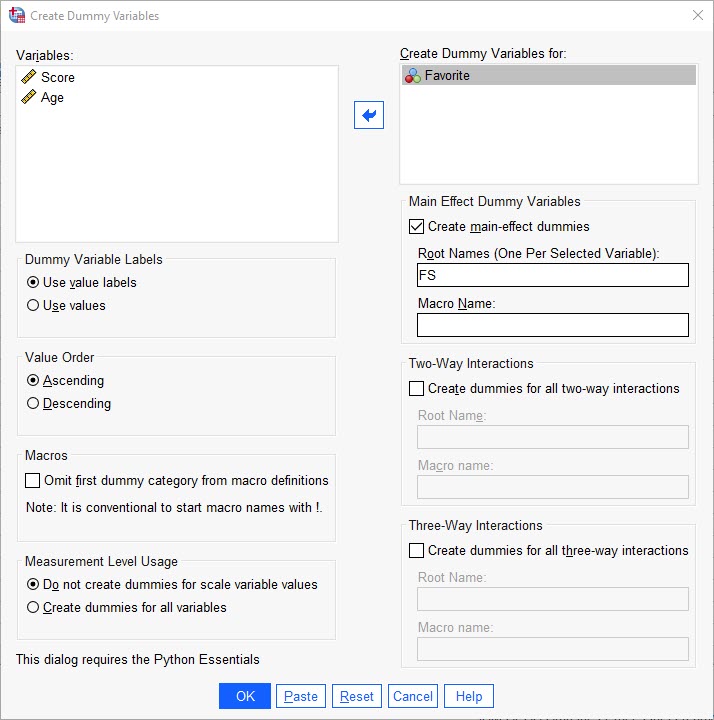
نرمافزار SPSS یک عدد متوالی (به عنوان مثال، 1، 2، 3، 4، و غیره) را به انتهای نام ریشهای که انتخاب میکنید برای نشان دادن کمیت مستقل طبقهبندی شده، اضافه میکند. به این ترتیب برای هر یک از کمیتهای ساختگی، یک عدد ترتیبی ایجاد میشود. به عنوان مثال اگر دو کمیت ساختگی دارید، اعداد 1 و 2 به انتهای نام ریشه اضافه میشود، یا اگر شش کمیت ساختگی داشته باشید اعداد 1، 2، 3، 4، 5 و 6 به انتهای نام ریشه اضافه میشود. به تصویر زیر نگاه کنید.
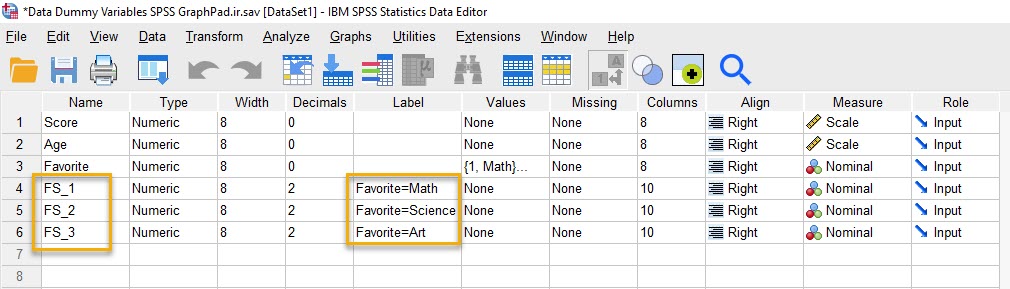
از آنجایی که کمیت مستقل طبقهبندی Favorite دارای سه سطح بود (ریاضی، علوم و هنر)، منوی Create Dummy Variables سه کمیت ساختگی ایجاد میکند. اسامی آنها در ستون Name آمده است.
“FS_1” برای ریاضی، “FS_2” برای علوم و “FS_3” برای هنر. می توانید بعداً نام آنها را ویرایش کنید تا معنی بیشتری پیدا کنند. ما فقط تصویر بالا را آوردیم تا بدانید کادر Root Names (One Per Selected Variable) چگونه کار میکند.

حال OK کنید. با انجام این کار، سه ستون جدید در فایل دیتا ایجاد میشود. به همان نامهای “FS_1” برای ریاضی، “FS_2” برای علوم و “FS_3” برای هنر که در بالا به آن اشاره کردیم. تصویر زیر را ببینید.
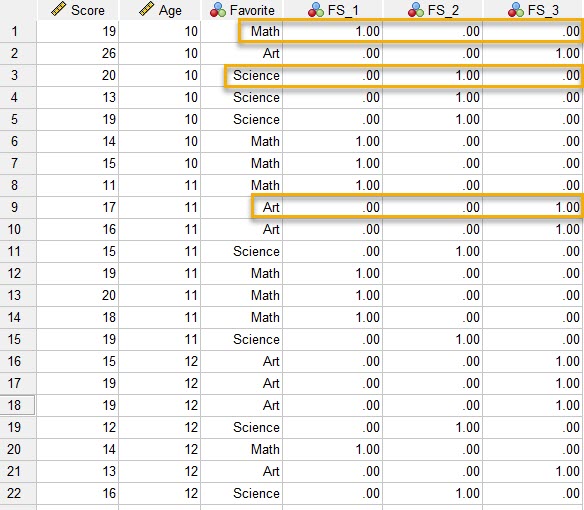
به ستونهای جدید ساخته شده نگاه کنید. آنها دارای کدهای صفر و یک هستند. کد صفر نشان میدهد فرد، علاقمندی به آن رشته را ندارد و کد یک بیانگر علاقمندی فرد به آن رشته است.
به عنوان مثال FS_1 را که Dummy Variable مربوط به Math است، نگاه کنید. هر کجا که فرد در ستون Favorite به ریاضی علاقمند بوده، کد 1 و هر کجا رشته دیگری مورد علاقه او بوده است، کد صفر به دست آمده است.
مثلاً سطر شماره 9 را نگاه کنید. در ستون Favorite علاقمندی به Art نوشته شده است. به همین دلیل در ستونهای FS_1 و FS_2 برای این فرد، کدهای صفر و در ستون FS_3 کد 1، ثبت شده است.
حال به فایل Output و خروجی نرمافزار بروید. جدول زیر را مشاهده میکنید.

این جدول به بیانی خیلی ساده تعاریف هر کدام از Dummy Variableها را آورده است. نکته خاصی ندارد.
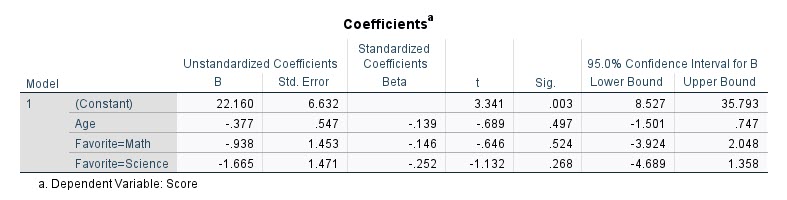
به عنوان مثال من جدول ضرایب یک مدل رگرسیون چندگانه که در آن Score به عنوان Dependent Variable قرار گرفته بود در حالی که Age و کمیتهای ساختگی Favorite یعنی FS_1 و FS_2 در مدل قرار دارند (FS_3 به عنوان رفرنس است و نتایج FS_1 و FS_2 نسبت به آن سنجیده میشوند) به عنوان Independent Variable در مدل حضور دارند را آوردهام.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Dummy Variables in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/dummy-variables-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Dummy Variables in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/dummy-variables-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.