تشخیص هم خطی Collinearity Diagnostics در مدل های رگرسیونی
Collinearity
به هنگام بیان مدل رگرسیون خطی (رگرسیون خطی Linear Regression در نرمافزار SPSS) به مطلبی به نام هم خطی اشاره کردم. هم خطی (Collinearity) از مباحث مربوط به درهم تنیدگی Intertwined کمیتهای مستقل Xها در یکدیگر و زاید بودن Redundant آنها، میباشد. توضیح کوتاه اینکه همخطی به معنای وجود ارتباط قوی و همبستگی بالا در بین Xهای مدل است. هر چند همخطی در همه مدلهای رگرسیونی وجود دارد اما شدت آن، یک نقیصه به حساب میآید. زیرا وقتی دو یا چند X با یکدیگر همخطی بالایی دارند، دیگر لزومی به آمدن همه آنها در مدل رگرسیونی نیست و زاید هستند.

من در این مقاله به دنبال آن هستم که به بیان نحوه به دست آوردن هم خطی در یک مدل رگرسیونی و با استفاده از نرم افزار SPSS بپردازم. ما به این فرایند تشخیص هم خطی Collinearity Diagnostics میگوییم.
تشخیص هم خطی با استفاده از دو ابزار و آماره در نرمافزار SPSS انجام میشود. آنها عبارتند از Tolerance و فاکتور تورم واریانس Variance Inflation Factor (VIF). در ادامه دربارهی آنها بیشتر صحبت میکنیم.
مثال هم خطی در مدل رگرسیونی
Example
به دادههای این مثال که مربوط به متوسط آلودگی هوا در فصل پاییز برحسب واحد PSI در 21 شهر کشور است، توجه کنید. فایل دیتا این مقاله را میتوانید از اینجا Collinearity Diagnostics دریافت کنید.
در این بررسی چند عامل موثر در آلودگی هوای این شهرها مورد مطالعه قرار گرفته است. عواملی که مورد بررسی قرار گرفتهاند عبارتند از تعداد کارخانههای بزرگ (بیشتر از 25 کارگر)، کارخانههای کوچک (کمتر از 25 کارگر)، تعداد وسایل نقلیه و وضعیت سیستم حمل و نقل عمومی در این 21 شهر. به طور حتم عوامل تاثیرگذار دیگری نیز بر روی آلودگی هوا، وجود دارند. با اینحال ما بررسی خود را بر روی این چند عامل انجام دادهایم.
ما مدل رگرسیون خطی زیر را به دادهها برازش دادهایم. در این زمینه میتوانید لینک (رگرسیون خطی Linear Regression در نرمافزار SPSS) را ببینید.
$ \displaystyle y=42.91+12.77{{x}_{1}}+8.03{{x}_{2}}+4.59{{x}_{3}}-6.18{{x}_{4}}$
همانطور که بیان کردم، هدف من در این مقاله تشخیص وجود هم خطی در بین X های این مدل رگرسیونی است.
برای انجام این کار در نرمافزار SPSS از مسیر زیر استفاده میکنیم.
Analyze → Regression → Linear
تنظیمات نرمافزار
Setting
هنگامی که به مسیر بالا در نرمافزار SPSS میرویم، پنجره زیر با نام Linear Regression برای ما باز میشود.
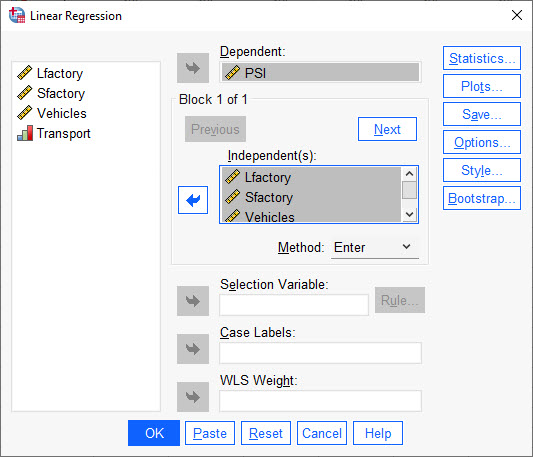
از آنجا که به دنبال پیشبینی میزان آلودگی هوا هستیم، آلودگی بر حسب PSI به عنوان کمیت وابسته Dependent و کمیتهای تعداد وسایل نقلیه، کارخانههای بزرگ، کارخانههای کوچک و وضعیت سیستم حمل و نقل عمومی، به عنوان کمیتهای مستقل Independent تعریف میشوند.
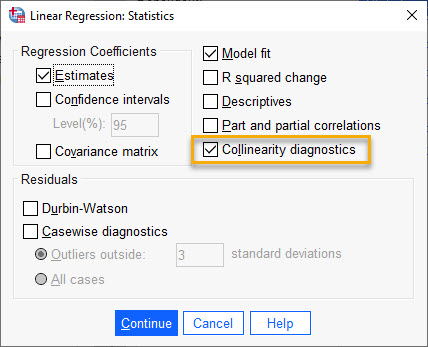
در پنجره Linear Regression تبها و گزینههای مختلفی وجود دارد، گزینه هم خطی در تب Statistics قرار دارد.
Statistics
در تب ![]() میتوانیم آمارهها و یافتههای مختلفی جهت بررسی مناسب بودن مدل رگرسیونی برازش شده و پارامترهای براورد شده، به دست بیاوریم. در تصویر زیر میتوانید آنها را ببینید.
میتوانیم آمارهها و یافتههای مختلفی جهت بررسی مناسب بودن مدل رگرسیونی برازش شده و پارامترهای براورد شده، به دست بیاوریم. در تصویر زیر میتوانید آنها را ببینید.
گزینه تشخیص هم خطی (Collinearity diagnostics) در این تب قرار دارد. من آن را در تصویر بالا مشخص کردهام. خب، حال Continue و سپس OK کنید. در ادامه نتایج نرمافزار به دست آمده است.
نتایج هم خطی
Output & Results
نرمافزار SPSS نتایج و خروجیهای زیادی در یک تحلیل رگرسیونی در اختیار ما قرار میدهد. با این حال من در این مقاله صرفاً میخواهم درباره هم خطی و آمارههای آن که با استفاده از SPSS به دست میآید، صحبت کنم.
میتوان بیان کرد که مهمترین یافته در تحلیل رگرسیون خطی، نتایج جدول Coefficients است. تصویر آن را در ادامه میبینید.
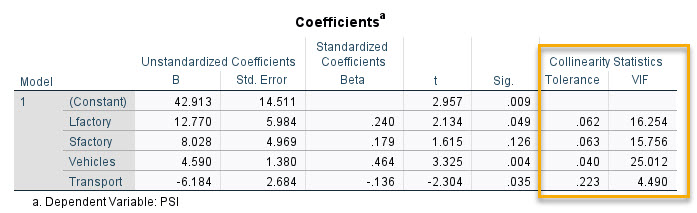
در جدول بالا من بخش Collinearity Statistics را مشخص کردهام. همانگونه که مشاهده میکنید ابن بخش با استفاده از آمارهها (ستونها) با نام Tolerance و VIF بیان شده است. من هر یک را توضیح میدهم.
- Variance Inflation Factor (VIF)
هم خطی با آمارهای به نام فاکتور تورم واریانس Variance Inflation Factor (VIF) سنجیده میشود. اندازه VIFها نشان میدهد با همبسته بودن کمیتها به یکدیگر، واریانس ضریب رگرسیونی براورد شده به چه میزان افزایش مییابد.
اگر VIF نزدیک به یک باشد، همخطی بین آن X با کمیتهای دیگر وجود ندارد، اما اگر VIFها از یک بزرگتر باشند، همخطی بین آن X با کمیتهای دیگر وجود دارد. وقتی VIF > 5 باشد، ضریب رگرسیونی به دست آمده برای آن جمله، مناسب نیست و معمولاً آن X را حذف میکنیم.
در جدول بالا کمیتهای Lfactory و Sfactory به همراه Vehicles دارای مقدار VIF بالایی هستند. به معنای اینکه همخطی شدیدی بین این Variableها با سایر Xها وجود دارد.
- Tolerance
در جدول بالا ستون دیگری با نام Tolerance دیده میشود. اعداد به دست آمده برای هر کمیت نشان میدهد که اگر آن X نقش Y را در یک مدل رگرسیونی داشته باشد و سپس بین آن X که دیگر Y شده است و سایر X ها یک مدل رگرسیونی برقرار کنیم، در آن صورت، ضریب تعیین R Square این مدل رگرسیونی چقدر خواهد بود.
در این زمینه رابطه زیر برقرار است.
$ \displaystyle Tolerance=1-{{R}^{2}}$
به عنوان مثال عدد 0.223 برای Transport بیان میکند که اگر یک مدل رگرسیونی بین Transport از یک طرف و سه Variable دیگر، برقرار کنیم، ضریب تعیین یا همان R2 این مدل رگرسیونی جدید 0.777 خواهد بود.
همانگونه که میدانیم $ \displaystyle {{R}^{2}}$ عددی بین صفر و یک است و هر چقدر به یک نزدیکتر باشد، نشاندهندهی وجود ارتباط قویتر بین کمیت پاسخ Y با سایر کمیتهای مستقل Xها میباشد.
در مدلهای رگرسیونی مطلوب آن است که بین Xها همخطی وجود نداشته باشد و اندازههای VIF آن نزدیک به یک و Tolerance در اطراف صفر باشد.
در ادامه نتایج نرمافزار SPSS، جدول دیگری با نام Collinearity Diagnostics به دست آمده است. در تصویر زیر آن را ببینید.
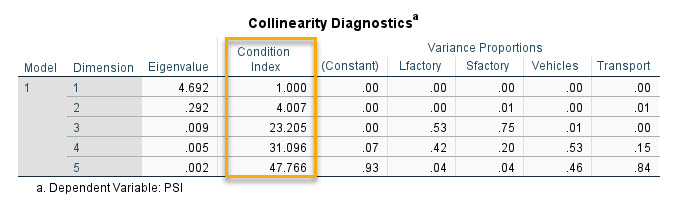
در نتایج این جدول به تعداد ضرایب رگرسیونی موجود در مدل، بُعد Dimension ساخته میشود. این کار تقریباً شبیه به تحلیل عاملی Principle Component Analysis (PCA) است.
معمولاً بیان میشود در سطرهایی که دارای مقادیر ویژه Eigenvalue نزدیک به صفر هستند، هم خطی وجود دارد. از آنجایی که عبارت “نزدیک به صفر” تا حدودی نامشخص است، بهتر است از ستون بعدی با نام شاخص وضعیت Condition Index برای تشخیص هم خطی استفاده شود.
صرفنظر از نحوه به دست آوردن اعداد و نتایج این ستون که میتوانید در این لینک ببینید، مقادیر بالای 15 میتواند مشکلات هم خطی را نشان دهد، مقادیر بالای 30 نشانه بسیار قوی برای مشکلات هم خطی هستند. برای تمام سطرهایی که در آنها مقادیر بالایی برای Condition Index وجود دارد، بهتر است ستونهای بعدی با نام نسبتهای واریانس Variance Proportions در نظر بگیرید.
همانگونه که مشاهده میکنید نتایج مربوط به ستونهای Variance Proportions به تفکیک هر X در مدل رگرسیونی به دست آمده است. برای هر ردیف با Index Condition بالا، مقادیر بالای 0.90 را در Variance Proportions جستجو کنید. اگر دو یا چند مقدار بالاتر از 0.90 در یک سطر پیدا کردید، میتوانید فرض کنید که یک مشکل هم خطی بین آن وجود دارد. اگر فقط یک پیش بینی در یک خط دارای مقدار بالاتر از 0.90 باشد، این نشانه ای برای چند خطی بودن نیست.
اگر در مطالعه خود هم خطی بین X ها مشاهده کردید، سعی کنید مشکلات همخطی را با اجرای مجدد رگرسیون با استفاده از امتیاز z یا Z-Scores از کمیتهای مستقل برطرف کنید. این کار با استفاده از روش تحلیل عاملی انجام میشود. علاقمند بودید این لینک را ببیند (انجام یک تحلیل رگرسیونی بر روی نمرات z)
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Collinearity Diagnostics in regression models. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/collinearity-diagnostics-spss.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Collinearity Diagnostics in regression models. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/collinearity-diagnostics-spss.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.