تحلیل نسبت Ratio Analysis در نرمافزار SPSS
Ratio Analysis
نسبتها که آن را با نام Ratio می شناسیم، میتوانند بخش مهمی در تحلیل دادهها قرار گیرند. همانگونه که از نام آنها بر میآید، ما در اینجا با یک کسر روبهرو هستیم. کسری که شامل صورت Numerator و مخرج Denominator است. در واقع Ratio از تقسیم دو عدد یا Variable از نوع Scale به دست میآید. یعنی ما اعداد یک کمیت را بر اعداد کمیت دیگر تقسیم میکنیم و کمیت Variable جدیدی میسازیم و سپس بر روی این کمیت جدید ساخته شده، تحلیل انجام دهیم.
کار ما در تحلیل نسبت Ratio Analysis این است که به تحلیل بر روی دادههای نسبت بپردازیم. من در این مقاله میخواهم به بررسی گزینه Ratio در نرمافزار SPSS بپردازم. خوب است بدانیم که SPSS تحلیلهای مبنی بر Ratio را از جمله آنالیزهای توصیفی میداند و آنها را در بخش Descriptive Statistics قرار داده است.
آنالیز و آمارههای Ratio معمولاً در مطالعات مالی، اقتصادی و در حالت کلیتر هر نوع آنالیزی که به بررسی برایند و نسبت بین Variableها میپردازد، استفاده میشود. من هم در این مقاله میخواهم از یک مثال مالی در بورس تهران استفاده کنم. دادههای این مقاله را میتوانید از اینجا Ratio Analysis دریافت کنید. در تصویر زیر بخشی از دادهها آمده است.
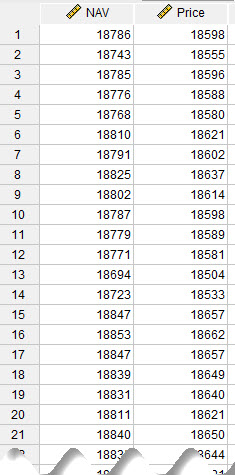
این دادهها به ارزش خالص دارایی Net Asset Value و قیمت فروش نماد صندوق سحرخیز در بورس تهران، به ازای هر روز اشاره میکند. یعنی در یک ستون ارزش دارایی NAV و در ستون دیگر قیمت Price نوشته شده است. من میخواهم با استفاده از تحلیل Ratio به بررسی نسبت بین این دو Variable بپردازم. نسبت در اینجا به صورت $ \displaystyle Ratio=\frac{{NAV}}{{{Price}}}$ تعریف میشود.
با استفاده از مسیر زیر در نرمافزار SPSS به انجام تحلیل نسبت اقدام میکنیم.
Analyze → Descriptive Statistics → Ratio
با رفتن به مسیر بالا، پنجره زیر با نام Ratio Statistics برای ما باز میشود.
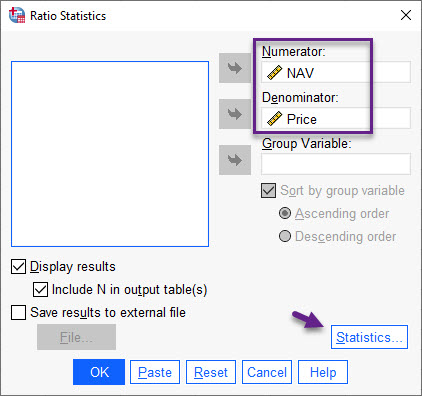
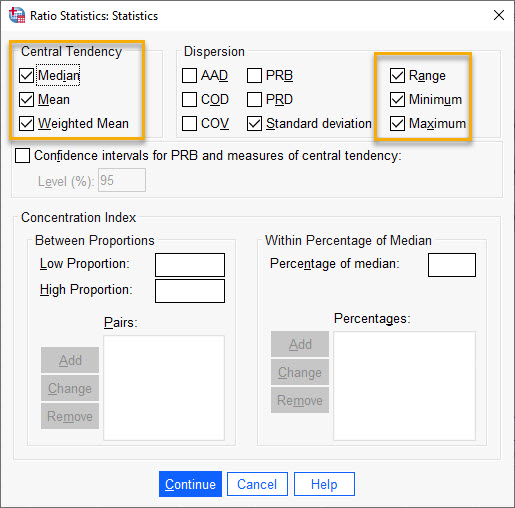
همانگونه که در توضیحات قبل بیان کردیم، در این پنجره NAV به عنوان Numerator و Price به عنوان Denominator تعریف میشود. بر روی تب Statistics بزنید تا وارد پنجره زیر شوید. در اینجا میتوانید انواع آمارههای مورد نیاز در تحلیل نسبت را مشاهده کنید.
من در گام نخست تحلیل، از نرمافزار خواستهام چند آماره ساده مانند میانه، میانگین، میانگین وزندار، انحراف معیار، رنج، کمترین و بیشترین مقدار دادههای نسبت را به دست بیاورد. در گام بعد از نرمافزار اطلاعات بیشتری به ویژه آمارههای پراکندگی Dispersion خواهیم خواست. علاقمند بودید با استفاده از این لینک (نحوه محاسبه آمارههای نسبت Ratio در نرمافزار SPSS) میتوانید فرمول به دست آوردن هر کدام از این آمارهها را مشاهده کنید.
نتایج و خروجیها
Result & Output
در ادامه خروجیها و نتایج به دست امده از تحلیل نسبت، در Output نرمافزار به دست آمده است. من در حال حاضر فقط چند آماره ساده را انتخاب کردهام. در تصویر زیر جدول نتایج را ببینید.

نتایج مربوط به گزینههای انتخاب شده در جدول بالا به دست آمده است. فهم این آمارهها ساده است. نکته این است که این نتایج بر روی دادههای کمیت جدید ایجاد شده یعنی نسبت NAV به Price به دست میآید. به عنوان مثال عدد 1.016 میانگین نسبت را نشان میدهد. هر چقدر این عدد به یک نزدیکنر باشد، بیانگر نزدیک بودن NAV به Price است.
بقیه آمارهها را نیز میتوانید در جدول بالا مشاهده کنید. به عنوان مثال دیگر، انحراف معیار 0.004 که عدد کوچکی است، نشاندهنده نزدیک بودن قیمت و NAV به یکدیگر است. کمترین نسبت نیز 1.01 و بیشترین نسبت نیز 1.022 است.
نکته در این نتایج شاید میانگین وزندار Weighted Mean برای ما سوال باشد. پاسخ این است که میانگین وزندار به صورت زیر محاسبه میشود.
$ \displaystyle {{\bar{R}}_{w}}=\frac{{\bar{A}}}{{\bar{S}}}=\frac{{\sum\limits_{{i=1}}^{n}{{{{A}_{i}}}}}}{{\sum\limits_{{i=1}}^{n}{{{{S}_{i}}}}}}=\frac{{\sum\limits_{{i=1}}^{n}{{{{S}_{i}}{{R}_{i}}}}}}{{\sum\limits_{{i=1}}^{n}{{{{S}_{i}}}}}}$
به بیان ساده یعنی اینکه میانگین وزندار به صورت تقسیم میانگین ارزش دارایی (NAV) بر میانگین قیمت فروش، محاسبه میشود. به بیان دیگر این مطلب یعنی اینکه اعداد نسبت با استفاده از مقادیر قیمت وزن دار میشوند. به عبارت دیگر هر نسبت در قیمت فروش خودش ضرب میشود.
قبل از اینکه بخواهیم دربارهی شاخصها و آمارههای Dispersion صحبت کنیم (که البته یکی از اصلیترین موضوعات این مقاله است) بیایید دربارهی کادر Concentration Index در همان پنجره تب Statistics توضیح دهیم. تصویر زیر را ببینید.
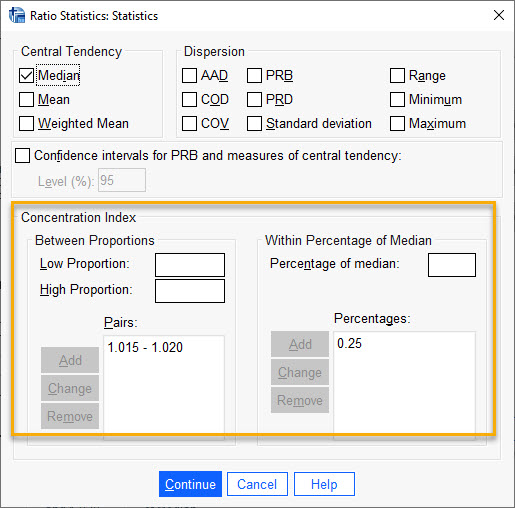
این کادر به دو بخش Between Proportions و Within Percentage of Median تقسیم شده است.
با استفاده از Between Proportions میتواند حجم متراکم شده و قرار گرفته از اعداد نسبت در بین دو اعدد انتخابی را مشاهده کنیم. به عنوان مثال من میخواهم بدانم چه درصدی از دادهها در بین اعداد 1.015 و 1.020 قرار گرفتهاند.
به همین ترتیب با استفاده از Within Percentage of Median میتوانیم حجم قرار گرفته از اعداد نسبت در فاصله یک درصد دلخواه از میانه را به دست بیاوریم. به عنوان مثال من میخواهم بدانم چه حجمی از دادهها در فاصله 0.25 درصدی از میانه قرار دارند. به عبارت سادهتر، چه درصدی از دادهها در فاصله 0.25 درصد کمتر از میانه و 0.25 درصد بزرگتر از میانه قرار دارند.
نتایج این بخش در جدول زیر آمده است. آن را ببینید.

نتیجه به دست آمده از جدول بالا نشان میدهد 14.1% دادههای نسبت در فاصله بین اعداد 1.015 و 1.0120 قرار دارند.
به همین ترتیب نتیجه میشود 55.7% دادههای نسبت در فاصله 0.25 درصدی از میانه قرار دارند. از آنجا که میانه عدد 1.014 به دست آمده است، بنابراین فاصله 0.25 درصدی از میانه میشود بین اعداد 1.01146 و 1.01653. که در این فاصله عددی، 55.7% دادههای نسبت قرار دارند.
خب حال بیایید در ادامه به موضوع اصلی این مقاله یعنی آمارههای پراکندگی Dispersion و نحوه به دست آوردن آنها در تحلیل نسبت، بپردازیم.
آمارههای پراکندگی در Ratio Analysis
Dispersion Statistics
در تحلیل نسبت و در پنجره Statistics آمارههای پراکندگی قرار دارند. آنها را در تصویر زیر ببینید.
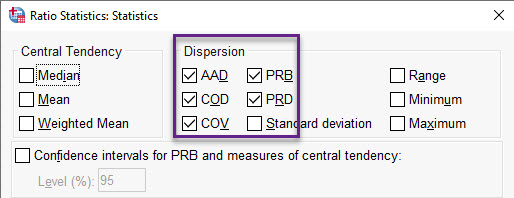
در ادامه میخواهم به تفکیک دربارهی هر کدام از این آمارهها توضیح دهم.
- AAD
آماره AAD مخفف Average Absolute Deviation یا میانگین قدرمطلق انحراف، تعریف میشود و از رابطهی زیر به دست میآید.
$\displaystyle AAD=\frac{{\sum\limits_{{i=1}}^{n}{{\left| {{{R}_{i}}-\bar{R}} \right|}}}}{n}$
همانگونه که از رابطه بالا مشخص است، هر عدد نسبت از میانگین نسبتها کم میشود، قدرمطلق گرفته شده و سپس همه قدرمطلقها با یکدیگر جمع میشوند. بنابراین AAD انحراف از میانگین، تفسیر میشود. هر چقدر این عدد بزرگتر باشد، به معنای تفاوت بیشتر نسبتها از میانگین و پراکندگی بیشتر آنها است.
در جدول زیر نتیجه AAD بر روی دادههای این مثال به دست آمده است.

عدد کوچک AAD = 0.003 نشاندهنده، پراکندگی کم دادههای نسبت و نزدیکی آنها به میانگین یعنی عدد 1.016 است.
- COD
به COD ضریب پراکندگی Coefficient of Dispersion گفته میشود. آن را میتوان از رابطه زیر به دست آورد.
$\displaystyle COD=\frac{{AAD}}{{\bar{R}}}=\frac{{\frac{{\sum\limits_{{i=1}}^{n}{{\left| {{{R}_{i}}-\bar{R}} \right|}}}}{n}}}{{\bar{R}}}=\frac{{\sum\limits_{{i=1}}^{n}{{\left| {{{R}_{i}}-\bar{R}} \right|}}}}{{n\bar{R}}}$
بر مبنای این رابطه عدد AAD به دست آمده بر میانگین نسبتها تقسیم میشود. در جدول زیر نتیجه COD بر روی دادههای این مثال به دست آمده است.

عدد کوچک COD = 0.003 نشاندهنده، پراکندگی کم دادههای نسبت و نزدیک بودن اعداد نسبت به یکدیگر است.
- COV
آماره COV مخفف Coefficient of Variation است و نوع دیگر اندازهگیری پراکندگی و پخش بودن دادههای نسبت را نشان میدهد. آن را میتوان از رابطه زیر به دست آورد.
$ \displaystyle COV=\frac{s}{{\bar{R}}}\times \%100$
به معنای اینکه COV از تقسیم انحراف معیار بر میانگین دادهها به دست میآید. در جدول زیر میتوانید عدد COV دادههای مثال را مشاهده کنید.

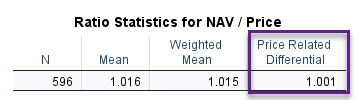
- PRD
آماره PRD مخفف عبارت Price Related Differential است که میتوان آن را تفاضل مرتبط با قیمت تعریف کرد. ابتدا بیایید فرمول محاسبه آن را ببینیم.
$\displaystyle PRD=\frac{{\bar{R}}}{{{{{\bar{R}}}_{w}}}}=\frac{{\bar{R}}}{{\frac{{\bar{A}}}{{\bar{S}}}}}=\frac{{\bar{S}\bar{R}}}{{\bar{A}}}=\frac{{\bar{S}}}{{\bar{A}}}\times \bar{R}$
این یعنی اینکه PRD از تقسیم میانگین بر میانگین وزندار به دست میآید. من فرمول بالا را بر مبنای تعریف میانگین وزندار که بالاتر در این مقاله بیان کردهام، بسط دادهام. در نهایت به این نتیجه میرسیم که PRD به صورت تقسیم میانگین قیمت فروش بر میانگین ارزش دارایی و سپس ضرب در میانگین نسبت به دست میآید.
در جدول زیر عدد PRD دادههای مثال را مشاهده کنید.
دربارهی مفهوم PRD باید گفت که عدد قابل قبول برای آن بین 0.98 تا 1.03 تعریف میشود. بر مبنای فرمول بالا اگر عدد به دست آمده برای PRD بزرگتر از 1.03 باشد به معنای این است که دارایی با نسبت کمتری به فروش، ارزیابی میشود. به این حالت ارزیابی کم براورد دارایی گفته میشود. به رابطهی زیر دقت کنید.
$ \displaystyle PRD>1\to \begin{array}{*{20}{c}} {} & {} \end{array}\frac{{\bar{R}}}{{{{{\bar{R}}}_{w}}}}>1\to \begin{array}{*{20}{c}} {} & {} \end{array}\bar{R}>{{\bar{R}}_{w}}\to \begin{array}{*{20}{c}} {} & {} \end{array}\bar{R}>\frac{{\bar{A}}}{{\bar{S}}}\to \begin{array}{*{20}{c}} {} & {} \end{array}\bar{R}\bar{S}>\bar{A}$
به همین ترتیب اگر PRD کمتر از 0.98 به دست بیاید، دارایی با نسبت بیشتری به فروش، ارزیابی میشود. به این حالت ارزیابی بیش براورد دارایی گفته میشود.
یکی از ایرادات PRD این است که نسبت به دادههای پرت بسیار حساس است و از آنها تاثیر میگیرد، به ویژه اینکه اگر تعداد نمونه نیز اندک باشد. به همین دلیل آماره و شاخص دیگری که از آن به نام PRB نام برده میشود، طراحی شده است. در ادامه دربارهی این شاخص صحبت میکنیم.
- PRB
آماره PRB مخفف عبارت Price Related Bias است که میتوان آن را سوگیری مرتبط با قیمت تعریف کرد. در جدول زیر عدد PRB دادههای مثال را مشاهده کنید.

همانگونه که در جدول بالا مشاهده میشود عدد PRB در این مثال برابر با 0.008- به دست میآید.
هنگامی که عدد PRB منفی است به معنای این است که دارایی به صورت کم براورد ارزیابی میشود و اگر عدد PRB مثبت باشد به معنای بیش براورد ارزیابی دارایی، خواهد بود.
جهت محاسبه PRB چند گام و مرحله در دیتا انجام میشود. البته نرمافزار SPSS این کارها را برای ما انجام میدهد و نیازی به انجام این مراحل از طرف ما نیست. با این حال من به دلیل فهم بهتر PRB آنها را بیان میکنم. هدف این است که دریابیم PRB چیست و چگونه محاسبه میشود.
در بالا اشاره کردیم که فایل دیتا شامل یک ستون ارزش دارایی NAV و در ستون دیگر قیمت Price میباشد. خود نرمافزار نیز ستون دیگری با نام Ratio برای ما میسازد (البته آن را نمیبینیم) و تحلیلهای نسبت را بر روی این ستون جدید انجام میدهد. حال بیایید ببینیم PRB چگونه به دست میآید. تصویر فایل دیتا را ببینید. به آن چند ستون اضافه شده است. من هر کدام را در ادامه توضیح دادهام.
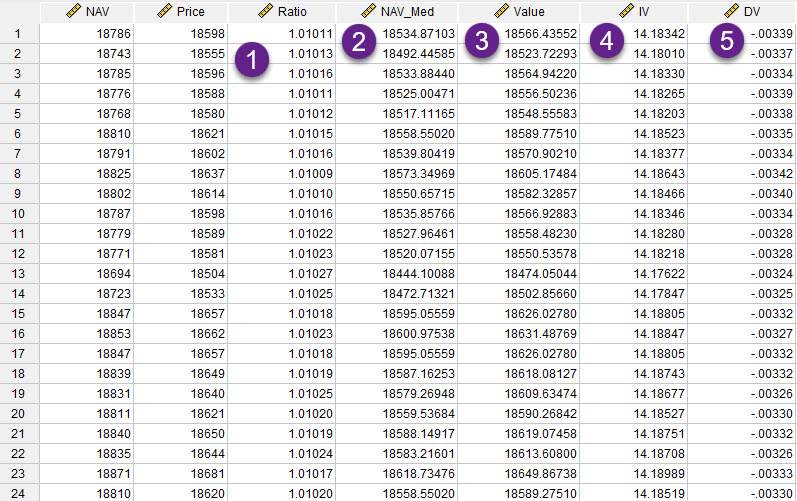
1 با ستون Ratio که آشنا هستیم. این ستون به سادگی از رابطهی

یعنی تقسیم NAV بر Price با استفاده از Compute Variable نرمافزار SPSS به دست میآید.
2 ستون با نام NAV_Med از رابطهی
به دست میآید. یعنی اینکه اعداد ستون NAV را بر میانه اعداد ستون Ratio که قبلا عدد آن را به دست آوردیم و برابر با 1.013549 شد، تقسیم میکنیم.
3 ستون Value از رابطهی
محاسبه میشود. به معنای اینکه حاصل میانگین وزنی (با وزن برابر 0.5) بین قیمت فروش و همان ستون NAV_Med است.
4 ستون IV که مخفف Independent Variable است از رابطهی
به دست میآید. یعنی از اعداد ستون Value به دست آمده در مرحلهی قبل، لگاریتم طبیعی LN گرفته میشود و سپس بر عدد 0.693 تقسیم میشود.
5 ستون DV که مخفف Dependent Variable است از رابطهبه دست میآید. یعنی هر مشاهده نسبت از میانه خود نسبتها که عدد 1.013549 است، کسر میشود و سپس بر همین میانه تقسیم میشود.
حال فهم آماره PRB ساده میشود. همانگونه که قبلاً بیان کردیم، PRB از یک مدل رگرسیونی به دست میآید. در اینجا بیان میکنیم که PRB در واقع همان ضریب رگرسیون خطی بین IV و DV است. یعنی ضریب رگرسیون خطی بین نسبتها که توسط میانه خودش تعدیل شده است (به عنوان کمیت وابسته DV) و Value (به عنوان کمیت مستقل IV)، همان عدد PRB خواهد بود.
من در جدول زیر معادله رگرسیونی بین آنها را آوردهام. در لینک (رگرسیون خطی Linear Regression با نرمافزار SPSS) میتوانید آموزش تحلیل رگرسیون خطی را مشاهده کنید.

ضریب رگرسیونی جدول بالا که در واقع همان PRB مطالعه ما است عدد 0.008- به دست آمده است. این عدد به معنای این است که اگر ارزش داراییها به اندازه 100 درصد افزایش یابد، نسبت تعدیل یافته (به میانه خودش) به اندازه 0.8 درصد کاهش خواهند یافت.
ضریب رگرسیونی تعریف شدن PRB این امکان را به ما میدهد که درک بهتری از نحوه ارزیابی دارایی به صورت کم براورد و یا بیش براورد داشته باشیم، علاوه بر اینکه نسبت به دادههای پرت مطالعه (برخلاف PRD) حساس نیست و از آنها تاثیر کمی میپذیرد. عدد مناسب برای PRB بین بازه 0.05- تا 0.05 مثبت بیان میشود.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2022). Ratio analysis in SPSS software. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/ratio-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2022). Ratio analysis in SPSS software. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/ratio-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.