Split File خرد کردن فایل دادهها در SPSS
در یک مطالعه، تحقیق و یا مجموعه دادهها بسیار اتفاق میافتد که بخواهیم تحلیلهای آماری خود را به تفکیک کمیت دیگر و به صورت جداگانه در سطوح مختلف یک Variable انجام دهیم. به عنوان مثال آنالیزهای آماری خود را به تفکیک زنان و مردان و یا به صورت جداگانه بر روی گروههای Case و Control انجام دهیم.
یک راه پردردسر و کمی پیچیده این است که بیاییم به ازای هر کدام از گروهها، فایل دیتا جداگاته داشته باشیم و بر روی هر کدام از فایلها آنالیز آماری انجام دهیم. این راهکار خوب است اما هنگامی که با تعداد ریاد گروهها روبهرو میشویم، تعداد فایلهای داده ما زیاد خواهد شد و همین موضوع امکان اشتباه را افزایش میدهد. به ویژه اینکه باید زمان زیادی را صرف کنیم و برای هر فایل، جداگانه آنالیز انجام دهیم.
با این حال حتماَ راه حل بهتری نیز وجود دارد. ما در این متن آموزشی به دنبال بیان این راهکار هستیم. با استفاده از این راهکار که Split کردن و یا همان خُرد کردن فایل دیتا گفته میشود، به سادگی میتوانیم فقط با یکبار اجرا و Run کردن آنالیز دلخواه خودمان، همه نتایج را به تفکیک و به صورت جداگانه بر مبنای کمیت Split شده به دست بیاوریم.
در این نوشتار آمورشی با استفاده از نرمافزار SPSS به بیان موضوع Split کردن فایل دیتا میپردازیم.
Split File با استفاده از SPSS
ابتدا بیایید با استفاده از نرمافزار SPSS، روش خُرد کردن و یا همان Split File را انجام دهیم.
دادههای فایل زیر را در نظر بگیرید. فایل دیتا و خروجی نرمافزار SPSS این مثال را میتوانید از اینجا دانلود کنید.
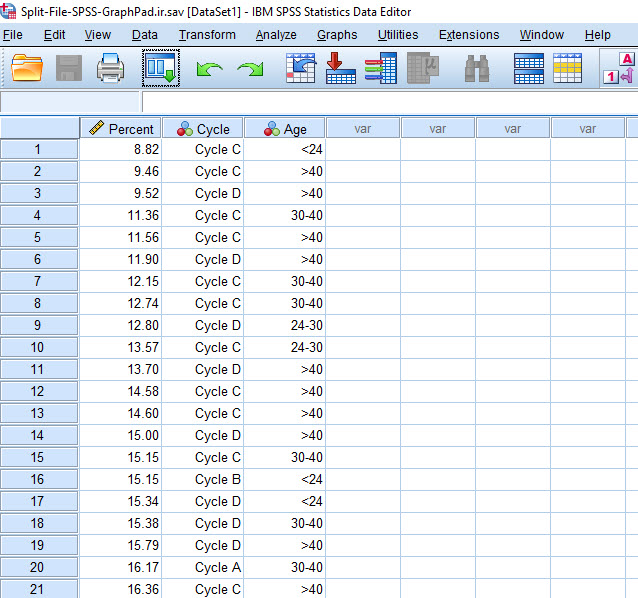
فرض کنید در این مثال میخواهیم درصد موفقیت Percent را در بین گروههای مختلف سیکل درمانی Cycle با یکدیگر مقایسه کنیم. میدانیم که این کار با استفاده از تحلیل آنالیز واریانس یک طرفه به سادگی انجام میشود. در این لینک میتوانید آموزش تحلیل واریانس را مشاهده کنید.
نکتهای که وجود دارد این است که میخواهیم تحلیل واریانس و مقایسه درصد موفقیت در هر سیکل با یکدیگر، به تفکیک گروههای سنی انجام دهد. به عبارت ساده یعنی اینکه در هر گروه سنی (مثلاَ کمتر از ۲۴ سال و یا بزرگتر از ۴۰ سال) به صورت جداگانه، آنالیز واریانس بین Percent و Cycle انجام شود.
راهکار این موضوع همان مطلبی است که میخواهیم در این متن به آن بپردازیم و به آن Split File گفته میشود.
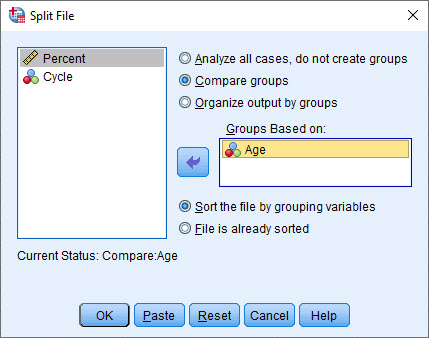
برای این منظور ابتدا در نوار ابزار بالای نرمافزار، Split File را انتخاب میکنیم.
با انجام این کار، پنجره زیر با نام Split File برای ما باز می شود.
این پنجره شامل سه گزینه است.
- Analyze all cases, do not create groups
واضح است که این گزینه به معنای خاموش بودن گزینه Split File و انجام تحلیل بر روی همهی سطرها و ستونهای فایل داده است.
- Compare groups
همانگونه که در مثال گفتیم، میخواهیم تحلیل واریانس به تفکیک گروههای سنی انجام شود. بنابراین این گزینه را انتخاب کزده و در کادر Groups Based on کمیت Age را قرار میدهیم.
درباره گزینه سوم در ادامه و پس از مشاهدات نتایج انتخاب گزینه Compare groups صحبت خواهیم کرد.
حال OK میکنیم. جالب توجه است که در فایل دیتا و یا همان پنجره Data View اتفاقی نمیافتد و انگار نه انگار ما کاری کردهایم. با این حال در پنجره Output نرمافزار SPSS خروجی و متن زیر قرار گرفته است.
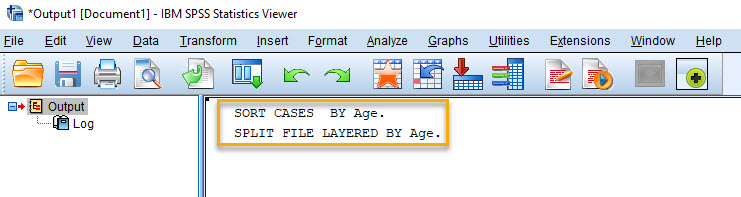
این فرمان به معنای آن است که فایل دیتا براساس گروههای Age، خرد و تفکیک شده است. بر این مبنا ما هر تحلیلی بر روی دادهها انجام دهیم، آنالیز به صورت جداگانه در هر گروه سنی انجام می شود.
برای مشاهده این اتفاق و نحوه Split شدن فایل دیتا، بیایید همان آنالیز واریانس بین Percent و Cycle را انجام بدهیم و نتیجه زا ببینیم. میدانیم که با استفاده از مسیر زیر در نرم افزار SPSS میتونیم تحلیل واریانس انجام دهیم.
Analyze → Compare Means → One-way ANOVA
در پنجره One-way ANOVA نیز به صورت زیر Variable ها را وارد میکنیم.
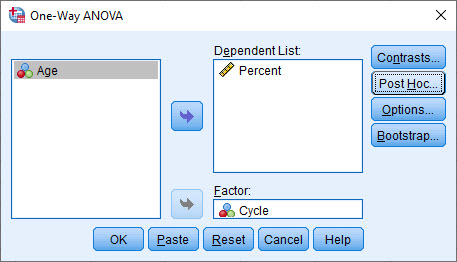
فرض کنید میخواهیم درصد موفقیت را در بین هر کدام از سیکلهای درمانی به صورت دو به دو نیز مقایسه کنیم. میدانیم که برای انجام این کار باید به تب Post Hoc برویم. در آنجا یکی از آزمونهای تعقیبی را به دلخواه انتخاب میکنیم. مثلا من آزمون Sidak را انتخاب کردهام.
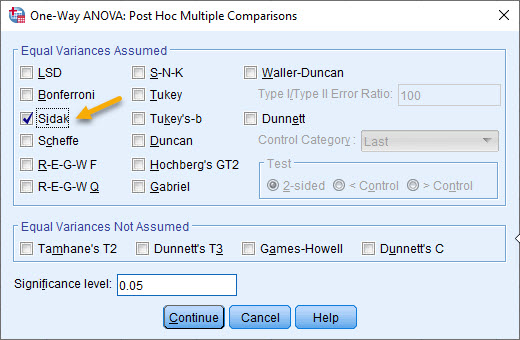
حال OK کرده و خیلی ساده بیایید نتایج آنالیز واریانس به دست آمده بر روی Percent و Cycle را مشاهده کنید. به خاطر داشته باشید که ما فایل دیتا را برحسب Age خُرد و Split کردهایم. در پنجره Output نرمافزار SPSS نتایج حاصل از آنالیز واریانس یک طرفه آمده است.
ابتدا جدول با نام ANOVA به صورت زیر دیده میشود.

همانگونه که در جدول ANOVA بالا دیده می شود، آنالیز واریانس بین درصد موفقیت و Cycle به تفکیک و به صورت جداگانه در هر کدام از گروههای سنی انجام شده است. به عنوان مثال تحلیل نشان میدهد در گروه سنی کمتر از ۲۴ سال و ۳۰-۲۴ سال، اختلاف معناداری در درصد موفقیت بین سیکلهای درمانی وجود ندارد، اما در گروههای سنی ۴۰-۳۰ سال و بالای ۴۰ سال، درصد موفقیت در سیکلهای درمانی متفاوت است و اختلاف معنادار دارد.
به همبن ترتیب در ادامه جدول Multiple Comparisons آمده است. همانگونه که میدانیم در جدول مقایسههای چندگانه، Dependent Variable (در این مثال Percent) در سطوح و گروههای مختلف فاکتور (در این مثال Cycle) مقایسه می شود. نتیجه زیر یک جدول طولانی و بزرگ است به دلیل اینکه آزمونهای تعقیبی (در اینجا Sidak) به ازای هر کدام از گروههای سنی به صورت جداگانه انجام شده است.
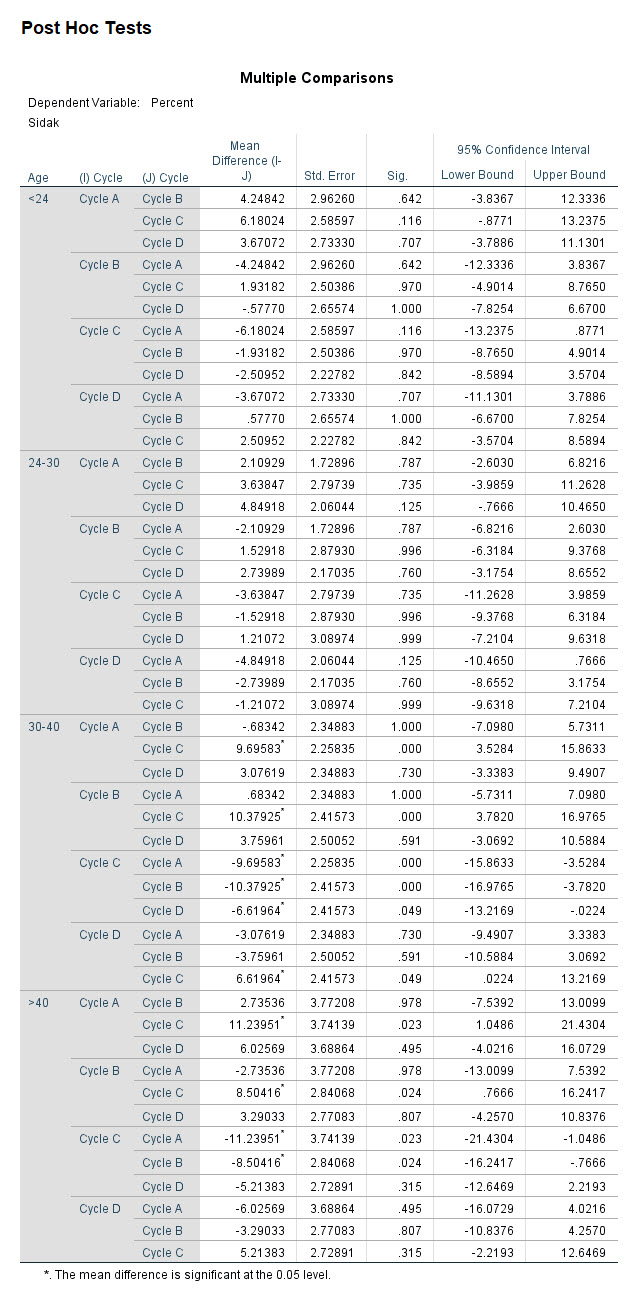
خب، حال بیایید به بیان گزینه سوم پنجره Split File که در بالا به آن اشاره کردیم، بپردازیم.
- Organize output by groups
فرض کنید در پنجره Split File گزینه Organize output by groups را انتخاب کنیم.
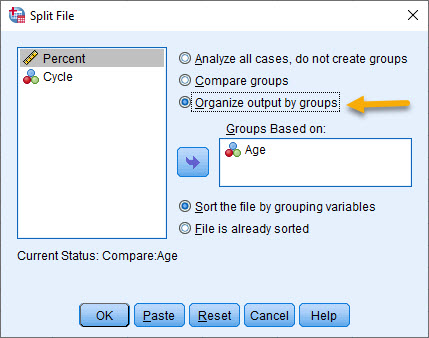
حال OK کنید و مطابق با توضیحات بالا، بار دیگر آنالیز واریانس یک طرفه را انجام دهید. نتایج در پنجره Output نرم افزار SPSS به صورت زیر خواهد بود.
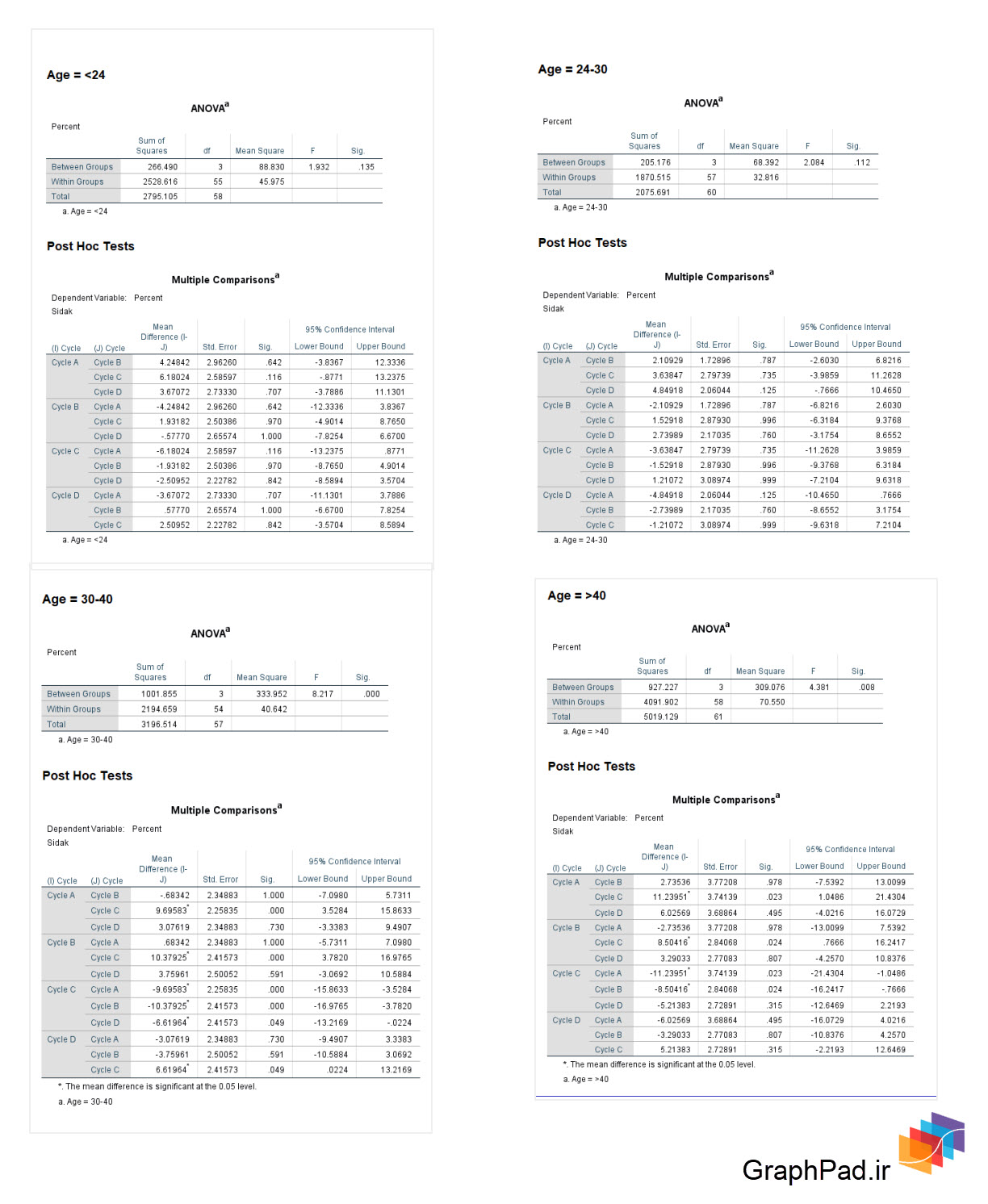
همانگونه که مشاهده میکنید از دیدگاه نتایج آنالیز واریانس به دست آمده، تفاوتی بین انتخاب گزینه Organize output by groups و Compare groups وجود ندارد. تنها تفاوت در نحوه خروجیها و کنار هم قرار گرفتن جداول است.
با انتخاب گزینه Compare groups همه نتایج حاصل از Split کردن در یک جدول و کنار هم قرار میگیرد و با انتخاب گزینه Organize output by groups هر رده گروه سنی دارای نتایج آنالیز واریانس جداگانه و جداول مجزا است.
به این ترتیب تفاوتی ندارد ما گزینه Organize output by groups را انتخاب کنیم و یا گزینه Compare groups. نتایج یکسان خواهد بود و فقط چینش و نحوه کنار هم قرار گرفتن جداول در پنجره Output متفاوت است.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2021). Split File in SPSS. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/split-file-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2021). Split File in SPSS. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/split-file-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.