آنالیز واریانس چندگانه یک طرفه One-way MANOVA با SPSS
آنالیز واریانس Analysis of Variance یا همان ANOVA یکی از مهمترین تحلیلهای آماری شناخته میشود. در این نوشتار ما قصد داریم درباره آنالیز واریانس چندگانه یک طرفه با نام One-way MANOVA صحبت کنیم.
در مبحث قبلی به آنالیز واریانس یک طرفه One way ANOVA پرداختیم. از اینجا میتوانید ویدئو و موضوعات مطرح شده آنالیز واریانس یک طرفه را مشاهده کنید.

تحلیل واریانس چندگانه یک طرفه یا One-way MANOVA هنگامی مورد استفاده قرار میگیرد که بخواهیم اندازههای بیش از یک کمیت وابسته Dependent Variable را در بین گروههای مستقل یک فاکتور Factor مورد مقایسه قرار دهیم. در شکل زیر میتوانید نحوه طراحی آنالیز واریانس چندگانه یک طرفه را مشاهده کنید.
سوال
چرا میگوییم آنالیز واریانس چندگانه یک طرفه؟
پاسخ ساده است. هنگامی که بیشتر از یک کمیت وابسته Dependent Variable با نام اختصاری D>1 و یک Factor با نام اختصاری F1 که در واقع همان Independent Variable نامیده میشود، داشته باشیم، مطالعه ما از نوع آنالیز واریانس چندگانه یک طرفه خواهد بود.
در این متن، تحلیل آنالیز واریانس چندگانه یک طرفه با استفاده از نرمافزار SPSS و روش مدل خطی عام General Linear Model و یا همان GLM انجام خواهد شد.
فایل دیتا و خروجی نرمافزار مثال را میتوانید از اینجا دانلود کنید. در تصویر زیر نیز توضیحاتی درباره فایل مثال آمده است.
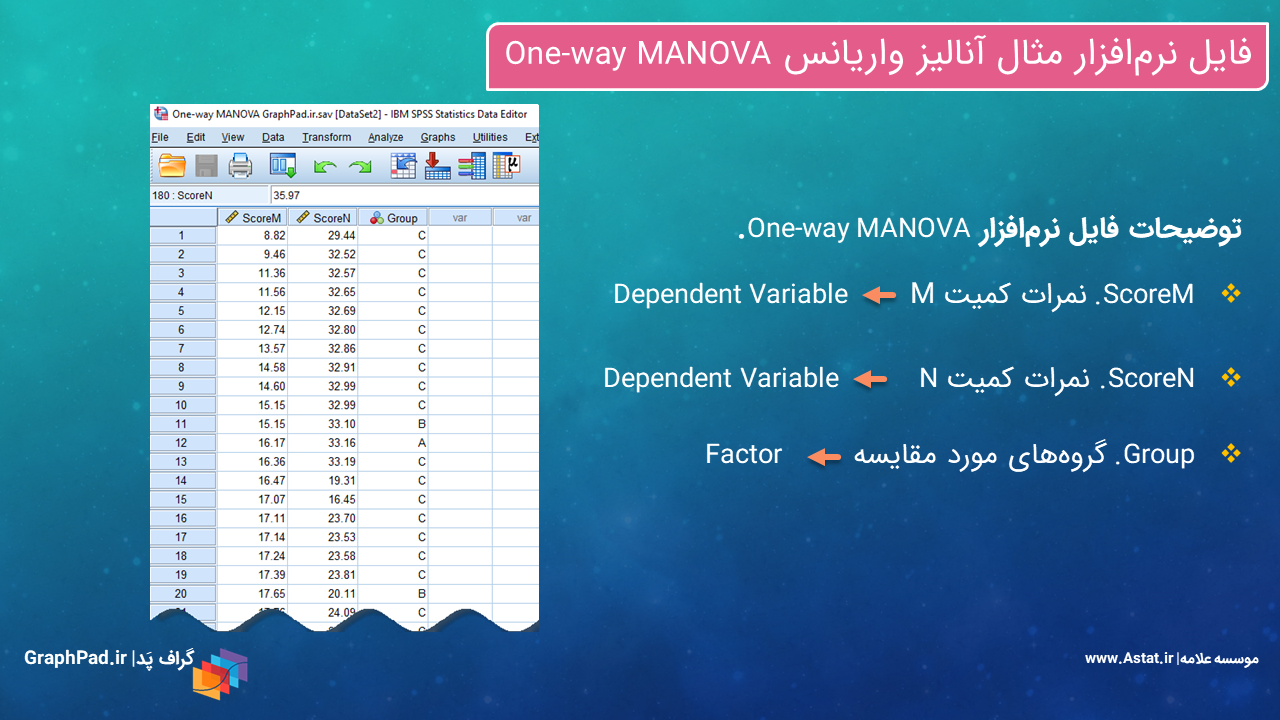
همانگونه که در تصویر بالا مشاهده میکنید، میخواهیم ScoreM و ScoreN را که در اینجا Dependent Variable به حساب میآید، در بین گروههای مختلف فاکتور Factor، مورد مقایسه قرار دهیم.
به نحوه ورود دادهها به نرمافزار SPSS دقت کنید. در ستونهای با نام ScoreM و ScoreN، همه اعداد و نمرات زیر هم نوشته میشود. Measure این ستونها از نوع Scale است و همانگونه که بیان کردیم نقش Dependent Variable را برعهده دارند.
در ستون دیگر که در این مثال با نام Group آمده است، به ازای هر کدام از نمرات M و N، گروه آن در سه سطح B ،A و C آمده است. Measure این ستون میتواند از نوع Ordinal و یا Nominal باشد. این ستون نقش Factor را در یک مطالعه MANOVA خواهد داشت.
حال بیایید به ارایه و انجام آنالیز واریانس چندگانه یک طرفه One-way MANOVA با استفاده از روش General Linear Model بپردازیم.
روش تحلیل
General Linear Model , Multivariate
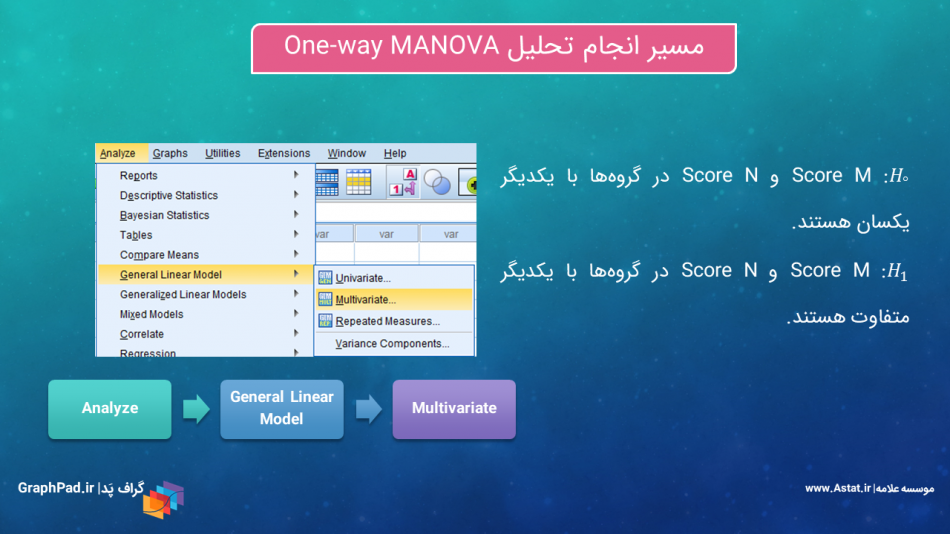
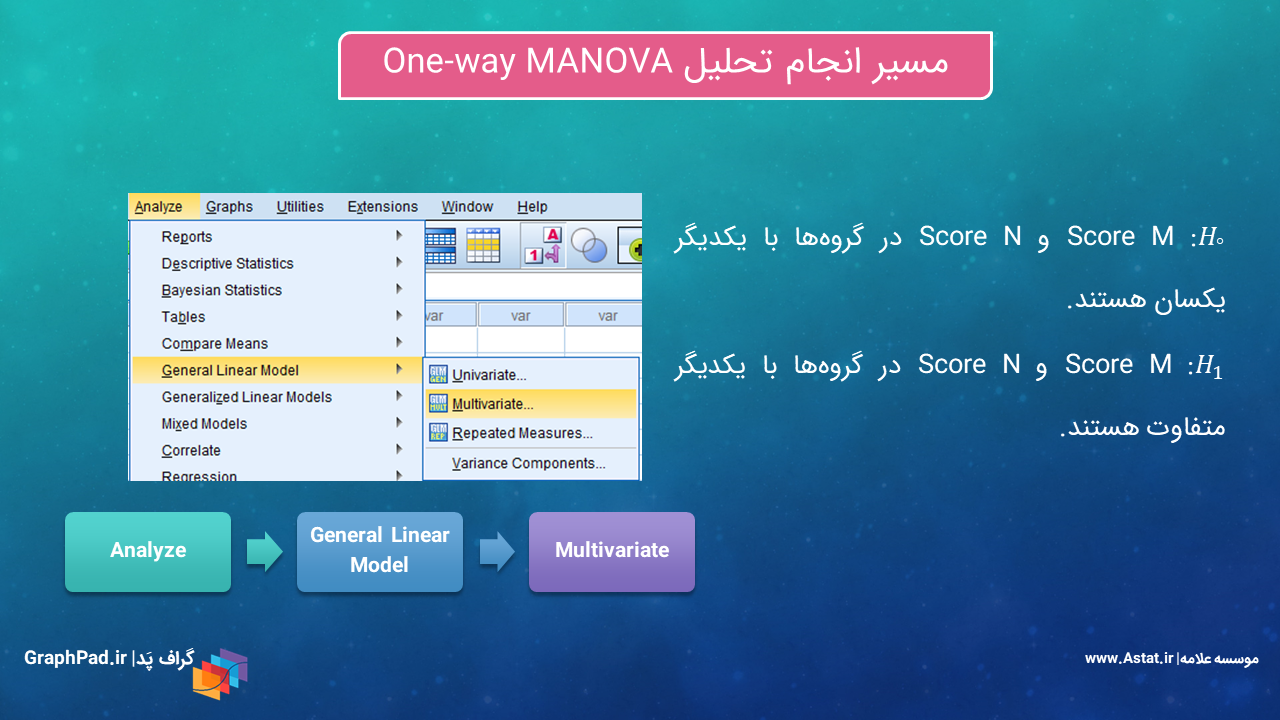
مسیر انجام آنالیز واریانس هنگامی که میخواهیم از روش General Linear Model استفاده کنیم، به صورت زیر خواهد بود.
مسیر نرمافزار
Analyze → General Linear Model → Multivariate
در شکل زیر مسیر و نحوه قرار گرفتن ستون دادهها در نرمافزار SPSS جهت انجام آنالیز واریانس چندگانه یک طرفه با استفاده از Multivariate روش GLM آمده است. همچنین میتوانید فرض صفر و فرض مقابل را مشاهده کنید. همانگونه که مشاهده میکنید فرض صفر بیان میکند که میانگین ScoreM و ScoreN در گروهها (به عنوان فاکتور مطالعه)، برابر است و فرض مقابل بر این نظر است که میانگین ScoreM و ScoreN در گروههای مختلف فاکتور متفاوت است. به این نکته توجه کنید که در یک تحلیل MANOVA آنالیز به تفکیک Dependent Variable ها انجام میشود.
با رفتن به این مسیر، پنجره با نام Multivariate باز میشود. ScoreM و ScoreN را در کادر Dependent Variables و Group را در کادر Fixed Factor(s) قرار میدهیم.
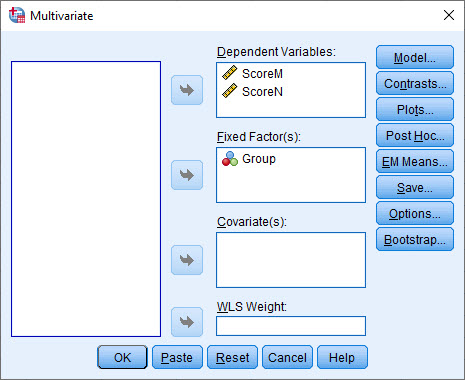
خوب است در همین جا این نکته را بیان کنیم که به دلیل اینکه در کادر Dependent Variables بیشتر از یک ستون قرار گرفته است مطالعه ما آنالیز واریانس چندگانه است. همچنین از آنجا که در کادر Fixed Factor(s) فقط یک ستون با نام Group قرار گرفته است، مطالعه ما آنالیز واریانس چندگانه یک طرفه One-way MANOVA میباشد.
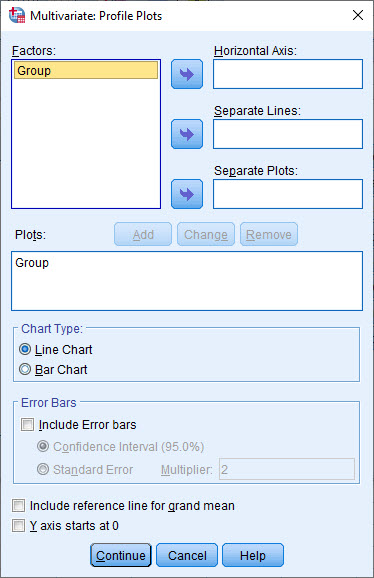
در پنجره Multivariate تبهای مختلفی دیده میشود. در تب Plot میتوانیم نمودار و گراف کمیتهای وابسته M و N به ازای سطوح مختلف فاکتور Group را مشاهده کنیم.
در تب Post Hoc انواع مقایسههای دوگانه بین گروههای مختلف Factor مشاهده میشود. با استفاده از این تب میتوانیم به صورت جداگانه هم ScoreM و هم ScoreN را بین سطوح مختلف Group با یکدیگر مقایسه کنیم. در تصویر زیر میتوانید انواع آزمونهای مقایسهای چندگانه برای میانگینهای مشاهده شده را ببینید.
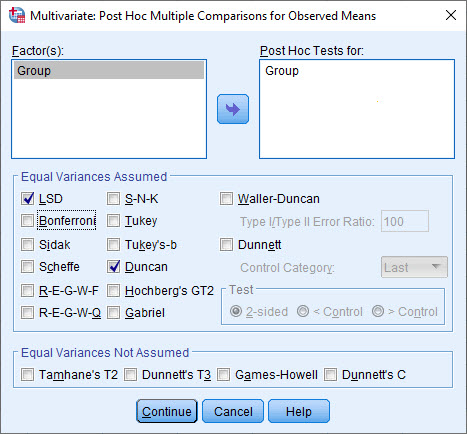
به عنوان مثال آزمونهای LSD و دانکن Duncan را انتخاب کردهایم.
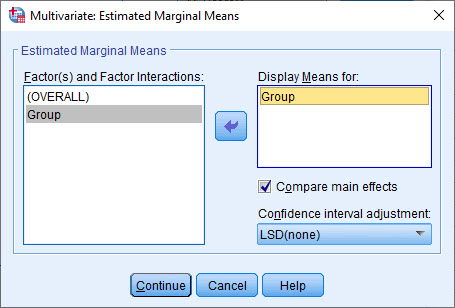
در تب EM Means میتوانیم میانگینهای حاشیهای به ازای هر کدام از گروههای Factor را به دست آوریم. با انتخاب گزینه Compare main effects میانگینهای حاشیهای قابل مقایسه با همدیگر هستند.
به همین ترتیب در تب Options آمارههای توصیفی، اندازه اثر effect size و توان power آزمون به همراه آزمونهای همگنی واریانسها را انتخاب میکنیم.

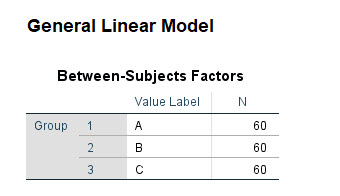
حال OK میکنیم. در فایل Output نرمافزار SPSS نتایج و خروجیهای زیر به دست میآید. به ترتیب آنها را بیان میکنیم. در ابتدا و در جدول Between-Subjects Factors اسامی گروههای هر کدام از Factor ها و تعداد هر گروه بیان شده است.
به همین ترتیب در جدول زیر که حاصل انتخاب گزینه Descriptive Statistics از تب Options در تنظیمات تحلیل Multivariate است، انواع آمارههای توصیفی نمرات M و N به ازای هر کدام از سطوح Group آمده است.

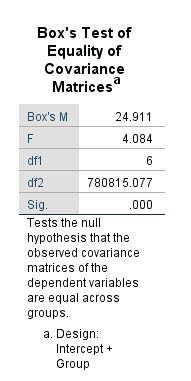
در یک تحلیل چندگانه Multivariate با آزمونی به نام Box’s M روبهرو هستیم. از این آزمون جهت بررسی فرضیه همگنی ماتریس کوواریانس، استفاده میکنیم. در جدول زیر میتوانیم نتیجه آزمون Box’s M را مشاهده کنیم. فرض صفر در این آزمون همگن بودن ماتریس کوواریانس است. نتیجه به دست آمده بیانگر رد فرض صفر و عدم همگن بودن ماتریس کوواریانس است.
با استفاده از نتایج آزمون Box’s M تصمیم میگیریم که در جدول Multivariate Tests از کدام آزمون استفاده کنیم. در جدول زیر نتایج این جدول آمده است.
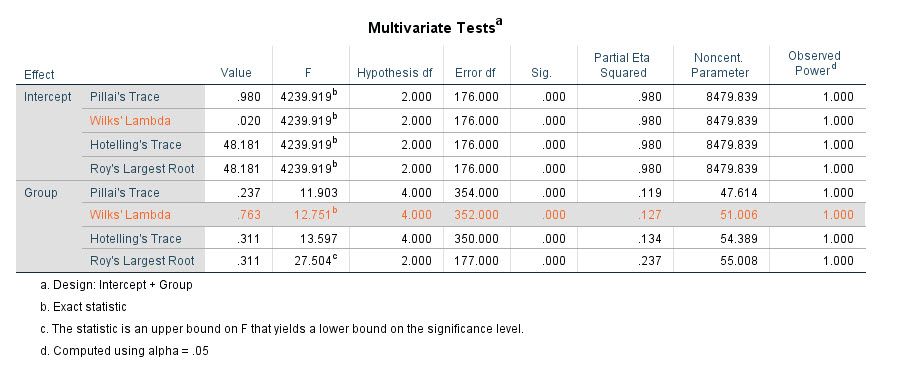
با توجه به رد فرضیه همگنی ماتریس کوواریانس، در جدول Multivariate Tests از آزمون Wilks’ Lambda استفاده میکنیم. نتیجه این آزمون نشاندهنده آن است که Group و سطوح مختلف آن به عنوان یک Independent Variable یک عامل موثر بر نمرات M و N به عنوان Dependent Variables است.
همچنین در جدول Levene’s Test of Equality of Error Variances آزمون لوین به منظور بررسی همگن بودن واریانس باقیماندههای مدل، آمده است. همانگونه که مشاهده میکنید به ازای هر کمیت وابسته یعنی Score M و Score N نتایج به صورت جداگانه به دست آمده است.
نتیجه به دست آمده نشان میدهد واریانس خطاها در ScoreM همگن نیست (P-value < 0.001) اما در ScoreN همگن است (P-value = 0.372).

به کلمه مدل دقت کنید. یک سوال دقیق میتواند این باشد،
سوال
کدام مدل؟ مگر ما قصد مقایسه Dependent Variable در سطوح مختلف Factor را نداریم؟ خب، این موضوع یک مبحث مقایسهای است و مدل یک موضوع رگرسیونی و ارتباط سنجی. این دو چه ارتباطی با هم دارند و چگونه میتوان از یک بررسی مقایسهای به مباحث مدلبندی و رگرسیونی رسید؟
موارد بالا سوالات بسیار دقیقی است و ما سعی میکنیم در ادامه به آنها پاسخ دهیم.
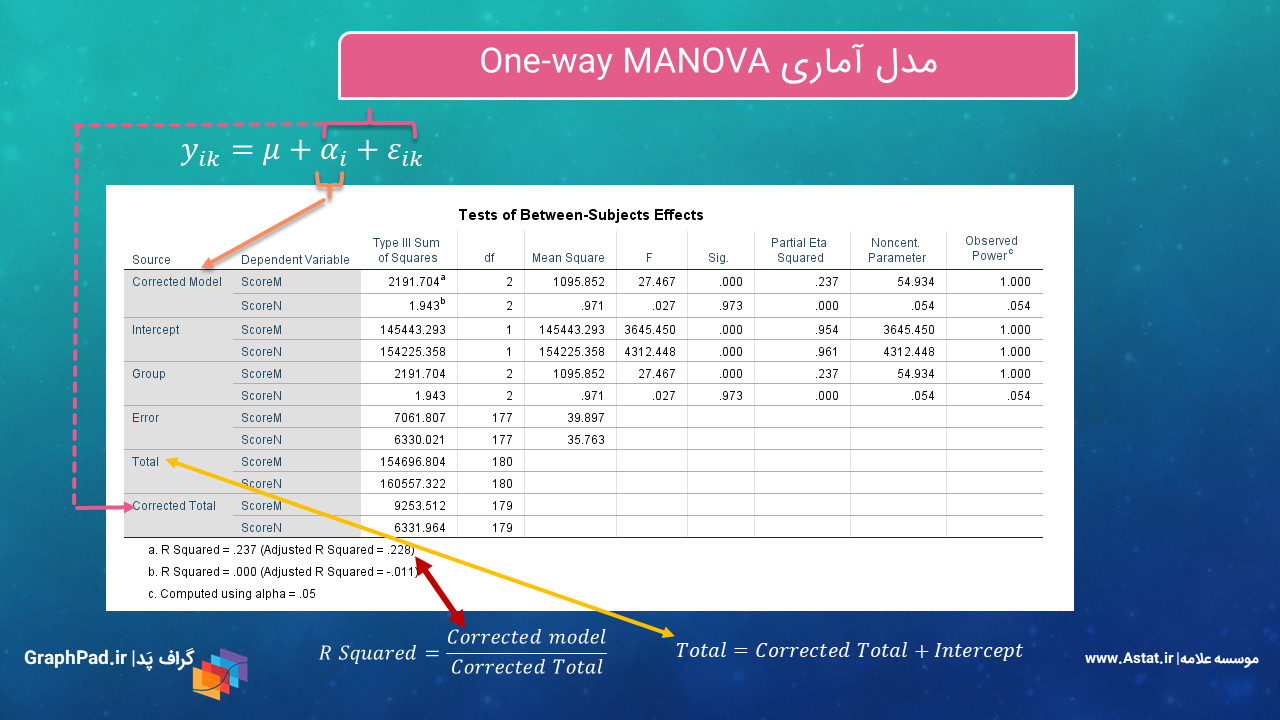
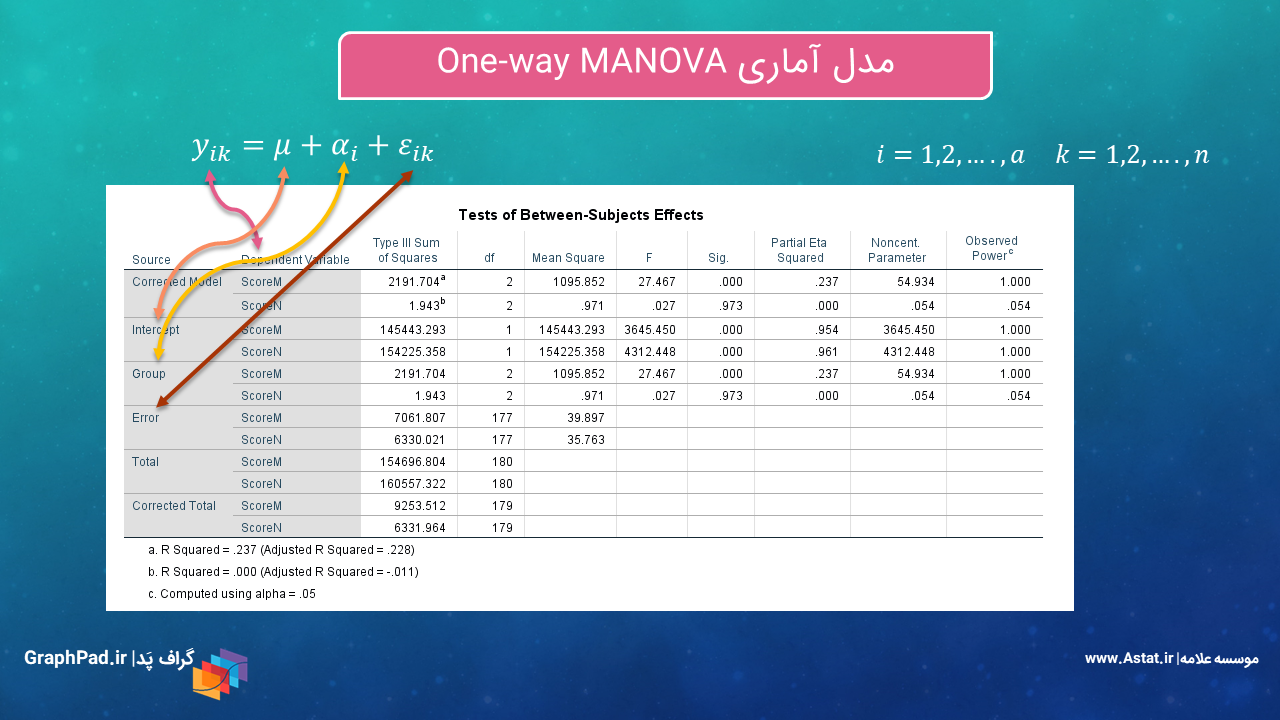
حال بیایید به بررسی نتایج جدول مهم Tests of Between-Subjects Effects بپردازیم. در شکل زیر برخی از توضیحات جدول آمده است. در ادامه بیشتر به آن میپردازیم.
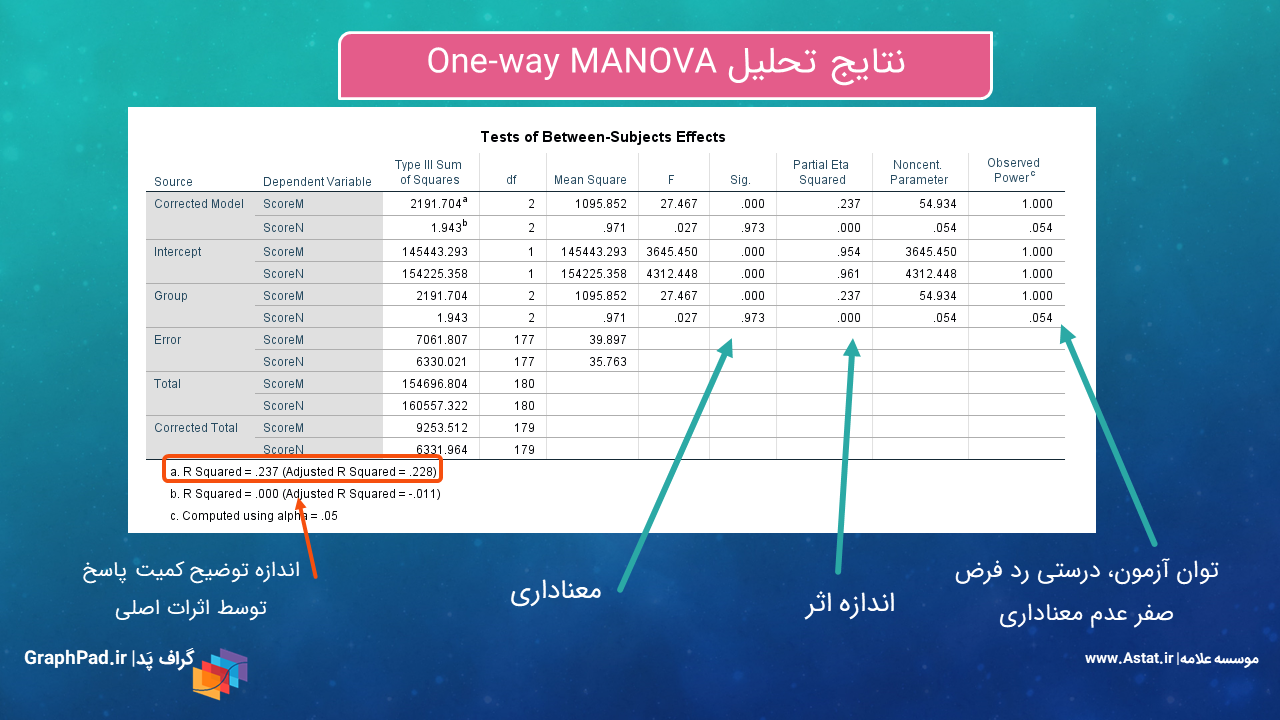
در جدول Tests of Between-Subjects Effects هنگامی که مطالعه ما One way MANOVA است، آزمون معناداری تاثیر فاکتور که نقش Independent Variable را دارد، بر روی هر کدام از Dependent Variableها به صورت جداگانه انجام میشود. بررسی میشود. در این مثال و از آنجا که ما به موضوع آنالیز واریانس چندگانه یک طرفه پرداختهایم، فاکتور Group در برابر ScoreM و ScoreN بررسی شده است.
-
فاکتور Group
نتیجه جدول Tests of Between-Subjects Effects بیانگر وجود تاثیر معنادار فاکتور Group بر ScoreM است (P-value < 0.001). این مطلب به بیان دیگر به معنای آن است که میانگین نمرات M در گروههای مختلف، به صورت معنادار متفاوت است.
اندازه اثر این فاکتور بر ScoreM برابر با ۰.۲۳۷ به دست میآید. توضیح اینکه Partial Eta Squared عددی بین صفر تا یک است و مقادیر نزدیک به یک آن نشاندهنده تاثیر بیشتر آن فاکتور بر کمیت پاسخ است.
به همین ترتیب نتیجه به دست آمده از جدول Tests of Between-Subjects Effects نشان میدهد فاکتور Group بر ScoreN تاثیر معنادار ندارد (P-value = 0.973). به بیان این که میانگین نمرات N در گروههای مختلف، به صورت معنادار متفاوت نیست.
اندازه اثر این فاکتور بر ScoreN بسیار اندک و برابر با 0.001 > به دست میآید.
در پایین جدول نیز متنی به صورت R Squared = .237 (Adjusted R Squared = .228) برای ScoreM و R Squared < 0.001 (Adjusted R Squared = -0.011) برای ScoreN دیده میشود. چنانچه با مباحث رگرسیونی آشنا باشید این همان ضریب تعیین R Squared مدل رگرسیونی است. عدد ضریب تعیین نشان میدهد مدل به دست آمده چقدر میتواند کمیت پاسخ را توضیح دهد.
در این مثال به معنای اینکه مدل شامل اثر اصلی Group چقدر میتواند Dependent Variables و یا همان ScoreM یا ScoreN را توضیح دهد.
عدد ضریب تعیین برای ScoreM برابر با ۰.۲۳۷ شده است. به معنای اینکه مدل میتواند حدود ۲۴ نمرات M را براورد کند.
همچنین عدد ضریب تعیین برای ScoreN بسیار اندک و برابر با 0.001 > شده است. به معنای اینکه مدل توانایی براورد نمرات N را ندارد. دلیل اصلی این موضوع آن است که اثر اصلی Group بر ScoreN تاثیر معنادار نداشته است.
در بالا سوالی با عنوان کدام مدل؟ پرسیدیم و در اینجا داریم از مدل حرف میزنیم. خوب است حال به پاسخ این سوال بپردازیم و درباره مدل موجود در آنالیز واریانس چندگانه یک طرفه هنگامی که از روش مدل خطی عام یعنی General Linear Model استفاده میکنیم، صحبت کنیم.
در ابتدا تصویر زیر را مشاهده کنید. در این تصویر مدل آماری One-way MANOVA هنگامی که از روش Multiivariate, GLM استفاده میکنیم، آمده است.
در واقع مدل خطی آنالیز واریانس چندگانه یک طرفه به صورت زیر است.
yijk = µ + αi + εik
این مدل به ازای هر کدام از Dependent Variableها جداگانه ساخته میشود. در این مثال یعنی اینکه ما یکبار این مدل را برای ScoreM داریم و بار دیگر برای ScoreN.
در این مدل، همانند همه مدلهای آماری دیگر میخواهیم با استفاده از کمیتهای مستقل Independent Variable اندازههای کمیت وابسته Dependent Variable را به دست بیاوریم و میزان تاثیر کمیتهای مستقل بر وابسته را مورد ارزیابی قرار دهیم.
در مدل بالا y همان کمیت وابسته Dependent Variable است که در این مثال یکبار ScoreM اس و بار دیگر ScoreN. منظور از اندیس i گروه iام Factor آلفا (همان Group) است. همچنین منظور از اندیس k نفر kام مورد بررسی است. مثلاَ وقتی مینویسیم y۱۵ یعنی درصد نمره M و یا نمره N نفر پنجم سیکل درمانی ۱ یا همان سیکل درمانی A.
در ادامه و به ترتیب اجزای این مدل خطی را توضیح خواهیم داد.
-
اثر ثابت μ
بیایید برای فهم این مدل از μ شروع کنیم. همانگونه که در شکل بالا نشان داده شده است μ همان Intercept یا اثر ثابت مدل است. μ نشاندهنده این است که بدون در نظر گرفتن گروههای مختلف (همان فاکتور Group)، نمرات اعم از M یا N چقدر خواهد بود. در جدول Tests of Between-Subjects Effects آزمون وجود اثر معنادار μ بر ScoreM و ScoreN انجام شده است (P-value < 0.001). اندازه اثر μ نیز مقدار بالایی گزارش شده است (۰.۹۵۴ = η2) برای ScoreM و (۰.۹۶۱ = η2) برای ScoreN.
-
اثر اصلی فاکتور α
اما αi چیست؟ α به معنای Factor مورد بررسی (در این مثال گروه Group) در مدل خطی است. . اندیس i هم بیانگر شماره و نوع گروه است. مثلاَ α۱ یعنی سیکل A و یا α۳ یعنی سیکل C.
در واقع در مدل خطی تحلیل واریانس چندگانه یک طرفه، یک فاکتور خواهیم داشت. منتهی از آنجا که دو Dependent Variable بنابراین دو مدل خطی و دو α خواهیم داشت. یک α برای نمرات M و یک α برای نمرات N. در این مدلها به دنبال پاسخ به این سوال هستیم که آیا α و یا همان Factor بر y یا همان کمیت وابسته Dependent Variable تاثیر معنادار دارد یا خیر.
به کلمه تاثیر دقت کنید. به طور معمول ما در آنالیز واریانس به دنبال مقایسه گروههای مختلف با یکدیگر هستیم. اما در روش General Linear Model میخواهیم به بررسی تاثیر Factor بر Dependent Variable بپردازیم.
این دو یعنی مقایسه گروههای Factor با یکدیگر و بررسی تاثیر Factor بر روی کمیت وابسته در روش GLM، در امتداد و راستای یکدیگر هستند. در واقع هنگامی که بررسی میکنیم آیا Factor بر y اثر معنادار دارد یا خیر، به معنای این مفهوم است که آیا رفتار و عملکرد گروههای مختلف Factor در بررسی y با یکدیگر متفاوت است یا خیر.
به همین دلیل است که ANOVA در یک جا به مفهوم مقایسه بین گروههای Factor با یکدیگر و در جای دیگر به معنای بررسی وجود تاثیر گروهها بر کمیت وابسته است. چنانچه وجود این تاثیر، تایید شود به معنای این است که رفتار گروهها با یکدیگر متفاوت بوده و اگر وجود تاثیر، تایید نشود به معنای این است که رفتار گروهها با همدیگر همانند است.
در این مثال نتیجهای که از بررسی فاکتور Group به دست میآید این است که α یعنی همان فاکتور Group، هنگامی که نمرات M به عنوان کمیت وابسته بررسی میشوند یک عامل اثرگزار معنادار است (P-value < 0.001) و هنگامی که نمرات N به عنوان کمیت وابسته بررسی میشوند یک عامل اثرگزار معنادار نیست (P-value = 0.973).
-
جمله خطا ε
مدل GLM همانند هر مدل آماری دیگری دارای خطا و باقیمانده است. در εik بخش خطا بیان شده است. در جدول Tests of Between-Subjects Effects نتایج این بخش با نام Error قرار میگیرد. همانگونه که قبلاَ نیز گفتیم منظور از اندیس k نفر kام مورد بررسی است و منظور از اندیس i گروه iام Factor.
سطرهای دیگری نیز در جدول Tests of Between-Subjects Effects دیده میشود. در تصویر زیر درباره ارتباط بین این سطرها با مدل آماری GLM صحبت خواهیم کرد.
سطر Corrected Model یا مدل اصلاحشده، به فاکنورهای موجود در مدل اشاره میکند. از آنجا که مثال ما آنالیز واریانس چندگانه یک طرفه است، پس یک فاکتور داشتیم که با نام Group در دادهها نامگزاری شده بود و در مدل با علامت αi آن را نشان دادیم.
اگر در جدول Tests of Between-Subjects Effects دقت کنید، مقدار همه آمارههای Corrected Model مانند مجموع و میانگین مربعات، درجه آزادی، مقدار احتمال، اندازه اثر و توان، به ازای هر کدام از Dependent Variable های نوشته شده است.
از آنجا که ما با یک تحلیل یک طرفه روبهرو هستیم، چنانچه دقت کنید نتایج این سطر دقیقاَ برابر با سطر Group است. مقدار احتمال و یا همان Sig مربوط به این سطر، بیانگر آزمون معناداری مدل شامل α است. نتیجه به دست آمده نشاندهندهی معنادار بودن مدل خطی آنالیز واریانس چندگانه یک طرفه برای ScoreM است (P-value < 0.001). اندازه اثر مدل نیز در حالت کلی برابر با (۰.۲۳۷ = η2) گزارش شده است. اما نتایج برای ScoreN معنادار به دست نیامده است.
مجموع Corrected Model (فاکتور α) و جمله خطا εik با نام Corrected Total نامیده میشود. چنانچه مجموع مربعات آنها را با هم جمع کتید به همان عدد مجموع مربعات Corrected Total میرسید.
سطر Total نیز به وضوح به مجموع Corrected Total (که خودش مجموع Corrected Model و Error بود) و Intercept اشاره میکند. در واقع مجموع مربعات Total ترکیب مجموع مربعات همه اجزای مدل شامل، اثر ثابت با نام μ، فاکتورهای موجود در مدل که در این مثال فقط αi بود و جمله خطا با نام εik است.
به همین ترتیب R Squared یا ضریب تعیین که آن را میزان توضیح مدل توسط فاکتورها مینامیم، به صورت Corrected Model نقسیم بر Corrected Total تعریف میکنیم. واضح است هر چقدر R Squared بیشتر باشد به معنای توضیح بهتر و بیشتر کمیتهای وابسته Dependent Variable (در این مثال نمرات M و N) توسط فاکتورهای مدل است. برای بیشتر بودن ضریب تعیین باید جمله خطا و یا همان Error که در محرج فرمول ضریب تعیین قرار میگیرد، کمتر باشد.
تا اینجا سعی کردم درباره تمام اجزا و محتویات جدول Tests of Between-Subjects Effects به دلیل اهمیت آن بپردازم. در ادامه درباره سایر خروجیهای نرمافزار در تحلیل One-way MANOVA (Multivariate, GLM) صحبت میکنیم.
خاطرتان باشد در تنظیمات نرمافزار و در تب EM Means به دنبال آن بودیم که میانگینهای حاشیهای هر کدام از گروههای Factor را برحسب گروههای Factor دیگر به دست آوریم. همچنین با انتخاب گزینه Compare main effects میانگینهای حاشیهای گروهها را با یکدیگر مقایسه کنیم. منظور از حاشیهای نیز این است که آمارههای توصیفی یک Factor را برحسب Factor دیگر به دست بیاوریم.
نکته مهمی که در این زمینه وجود دارد این است که در یک تحلیل One-way یا یکطرفه، فقط یک فاکتور وجود دارد. بنابراین فاکتور دیگری وجود ندارد که ما بخواهیم آمارههای توصیفی این فاکتور را برحسب فاکتور دیگر به دست آوریم. این مطلب به معنای آن است که استفاده از میانگینهای حاشیهای در یک تحلیل یک طرفه چندان کاربرد ندارد و میانگینهای حاشیهای همان میانگینها و آمارههای توصیفی واقعی و مشاهده شده هستند که آنها را در جدول Descriptive Statistics مشاهده کردیم.
با این حال در ادامه سعی میکنم درباره نتایج این بخش نیز توضیح دهم. در ادامه خروجیهای نرمافزار، نتایج مربوط به تنظیمات تب EM Means آمده است.
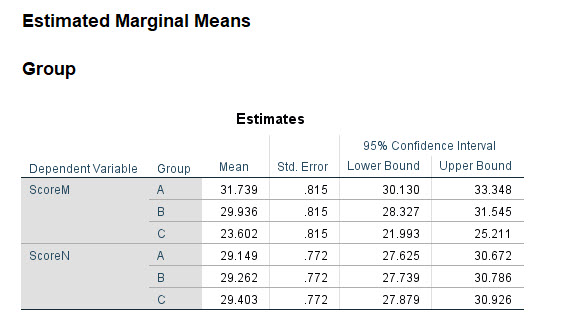
در این جدول آمارههای توصیفی حاشیهای Marginal مانند میانگین، خطای معیار و فواصل اطمینان ۹۵٪ برای ScoreM و ScoreN به ازای هر کدام از گروهها آمده است. همانگونه که در بالا توضیح دادم، از آنجا که مطالعه ما One-way است، بنابراین میانگین حاشیهای با میانگین حسابی برابر خواهد شد. در این زمینه، اسلاید زیر را ببینید.
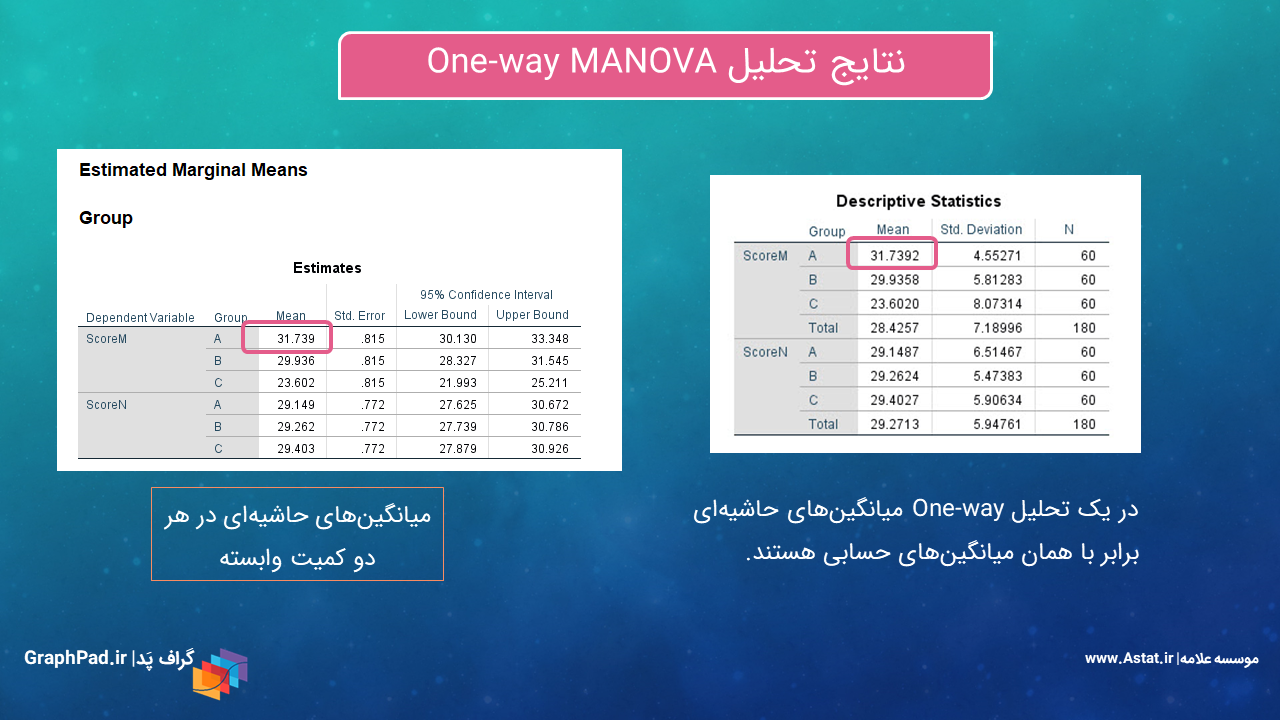
به عنوان مثال همانگونه که در جدول سمت راست اسلاید بالا میبینید، میانگین واقعی و مشاهده شده نمرات M برای گروه A عدد ۳۱.۷۳۹ است.
حال به جدول سمت چپ اسلاید بالا نگاه کنید. میانگین حاشیهای نمرات M برای گروه A همان عدد ۳۱.۷۳۹ به دست آمده است. به بقیه میانگینهای این جدول نیز نگاه کنید، کاملاَ برابر با میانگینهای حسابی جدول سمت راست شده است.
یادتان باشد در تب EM Means با انتخاب گزینه Compare main effects از نرمافزار خواستیم که میانگینهای حاشیهای گروههای فاکتور را نیز با یکدیگر مقایسه کند. این کار با استفاده از آزمون LSD انجام شده است. نتایج آن را میتوانید در شکل زیر مشاهده کنید.
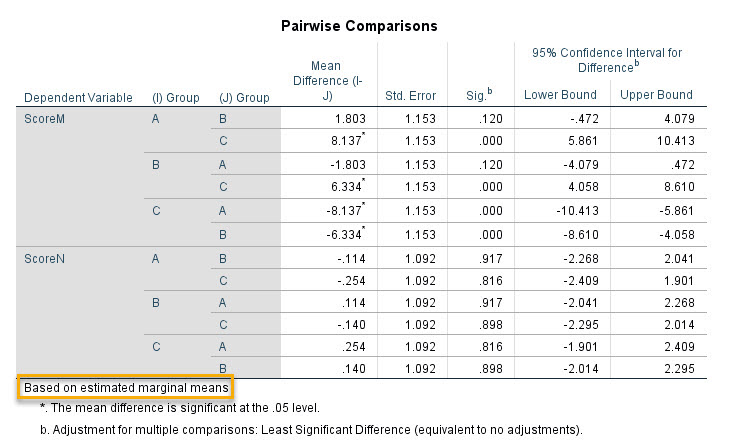
در جدول Pairwise Comparisons بالا که به مقایسه دو به دو میانگینهای حاشیهای گروههای مختلف فاکتور Group با یکدیگر پرداخته است، معناداری یا عدم معناداری این اختلافها به دست آمده است. از آنجا که مطالعه ما Multivariate است پس نتایج یکبار برای نمرات M و بار دیگر برای نمرات N به دست آمده است.
به عنوان مثال میتوانیم ببینیم که میانگینهای حاشیهای نمرات M در دو گروه A و B با یکدیگر اختلاف معنادار ندارند (P-value = 0.120) اما میانگینهای حاشیهای درصد موفقیت A و C با یکدیگر اختلاف معنادار دارند (P-value < 0.001). بقیه نتایج را نیز میتوانید در جدول بالا مشاهده کنید.
درباره ScoreN نیز قبلاَ بیان کردیم که فاکتور Group بر روی آن اثرگزار نیست. در جدول بالا نیز به وضوح میتوانید عدم وجود اختلاف معنادار بین هر دو گروه در نمرات N را مشاهده کنید. به این نکته نیز دقت کنید که این نتایج بر مبنای میانگین حاشیهای هر گروه به دست آمده است.
پس از جدول Pairwise Comparisons جدول دیگری با نام Multivariate Tests دیده میشود.
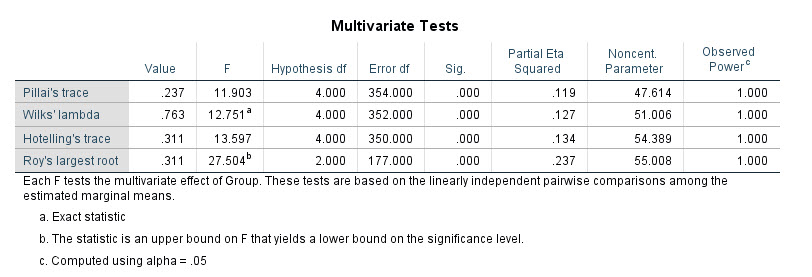
این جدول و نتایج آن همان نتایج بخش Group جدول Multivariate Tests در ابتدای خروجیهای نرمافزار است. بر مبنای این نتایج بیان کردیم که Factorدارای تاثیر معنادار بر Dependent Variables است.
در ادامه خروجیهای نرمافزار جدول دیگری با نام Univariate Tests دیده میشود. بررسی به تفکیک دو کمیت وابسته Score M و Score N انجام شده است.
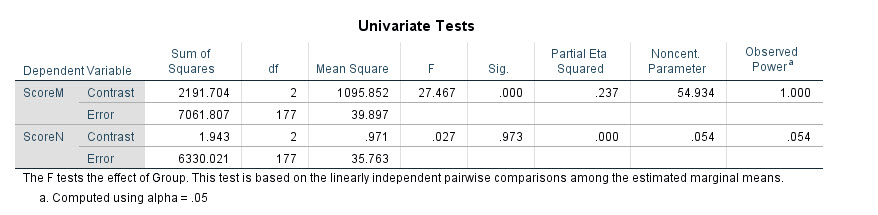
در این جدول دو سطر با نامهای Contrast و Error وجود دارد. منظور از Error همان جمله خطا در مدل خطی آنالیز واریانس چندگانه یک طرفه است که در متنهای بالاتر به آن اشاره شد. چنانچه دقت کتید آمارههای مربوط به این سطر دقیقاَ برابر با آمارههای سطر Error در جدول Tests of Between-Subjects Effects است.
سطر Contrast نیز به فاکتورهای موجود در مدل خطی اشاره میکند. از آنجا که در حال بررسی میانگینهای حاشیهای فاکتور Cycle هستیم، بنابراین آمارهها و نتایج مربوط به Contrast دقیقاَ برابر با نتایج سطر Group در جدول Tests of Between-Subjects Effects است. در بالا نیز درباره این نتایج و معنادار بودن یا نبودن آنها صحبت کردیم که بار دیگر تکرار نمیکنیم. تنها نکته اینکه از آنجا که ما در خروجیهای بخش Estimated Marginal Means هستیم، این نتایج و جدولها به همان دادههای میانگینهای حاشیهای مربوط است.
در جدول Univariate Tests پاسخ به این سوال که آیا میانگینهای حاشیهای گروهها مانند یکدیگر هستند، آمده است. بررسی به تفکیک دو کمیت وابسته Score M و Score N انجام شده است.
جواب برای Score M مثبت است. میانگینهای حاشیهای گروهها در Score M با یکدیگر متفاوت هستند.
خب، مواردی که در بالا گفتیم مربوط به میانگینهای حاشیهای یا همان Marginal Means بود. در ادامه دربارهی میانگینهای مشاهده شده Observed Means صحبت میکنیم.
در تنظیمات انجام One-way MANOVA و در تب Post Hoc به عنوان مثال آزمونهای LSD و دانکن Duncan را انتخاب کردیم. همانگونه که میدانیم با استفاده از این آزمونها میتوانیم به مقایسه دو به دو نمرات (البته بارها بیان کردیم چون مطالعه Multivariate است، پس به تفکیک هر کدام از Dependent Variable ها) در بین گروههای Factor بپردازیم.
در ادامه خروجیهای نرمافزار SPSS نتایج مربوط به این تنظیمات با نام Multiple Comparisons آمده است. به این نکته نیز توجه کنید که نتایج این بخش بر روی میانگینهای حسابی و مشاهده شده خود گروهها است و مانند بخش قبل بر مبنای میانگینهای حاشیهای نیست. بیشتر توصیه میشود جهت مقایسه بین گروهها فاکتورها از همین نوع مقایسات Post Hoc استفاده کنید، به ویژه هنگامی که مطالعه ما یک طرفه و One-way است.
در نتایج جدول زیر ما به مقایسه بین گروههای فاکتور Group پرداختهایم. از آزمون LSD نیز استفاده کردهایم.
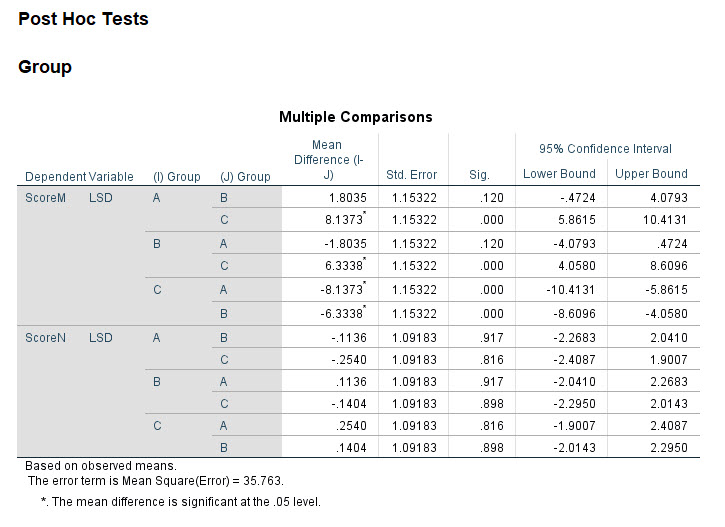
به عنوان مثال نتایج جدول بالا نشان میدهد که هر چند نمرات M در گروه A حدود ۱.۸ درصد از گروه B بیشتر است اما از دیدگاه تست آماری، آنها مشابه یکدیگر هستند (P-value = 0.120). با این حال مثلاَ گروه A حدود ۸.۱ درصد از گروه C درصد موفقیت بیشتری دارد و از دیدگاه آزمون اماری این بیشتر بودن معنادار نیز هست (P-value < 0.001). به همین ترتیب میتوانیم نتیجه مقایسه بین هر دو گروه را در جدول بالا مشاهده کنیم.
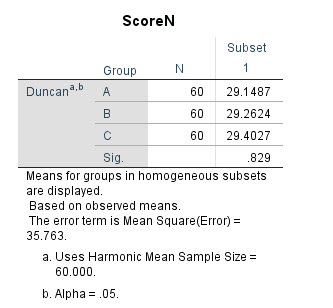
ما از آزمون دانکن نیز جهت به دست آوردن گروههای دارای نمرات مشابه و همانند یکدیگر، استفاده میکنیم. همانگونه که در جدول زیر میبینید، نتایج ابتدا مربوط به ScoreM است. نتایج به دست آمده از آزمون دانکن، تعداد گروههای این مثال را که ۳ گروه بوده است را به دو زیرگروه تقسیمبندی کرده است. در زیرگروه ۱، گروه C قرار دارد که با بقیه گروهها اختلاف معنادار دارد. در زیرگروه ۲، سیکلهای A و B قرار دارند که نمرات M آنها با یکدیگر از دیدگاه تست دانکن، مشابه است.
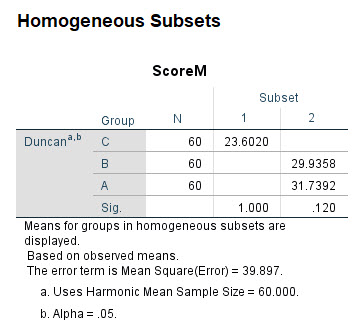
به همین ترتیب و در ادامه خروجیهای نرمافزار SPSS نتایج آزمون دانکن مربوط به ScoreN آمده است. همانگونه که قبلاَ نیز گفتیم نتایج این بخش بر مبنای میانگینهای مشاهده شده گروهها است و نشان میدهد ScoreN در گروهها با هم اختلاف معنادار ندارد.
در پایان خروجیهای نرمافزار SPSS میتوانید، نمودارها و گرافها را مشاهده کنید. به یاد داشته باشید ما در تنظیمات انجام تحلیل One-way MANOVA و در تب Plot از نرمافزار خواستیم نمودارهای خطی از ScoreM و ScoreN برای هر کدام از گروههای فاکتور، برای ما رسم کند. نتیجه را میتوانید در ادامه ببینید.
به این نکته توجه کنید که این نمودارها براساس میانگینهای حاشیهای که در بخشهای بالاتر به آنها اشاره کردیم، رسم شده است.
همانگونه که در گراف بالا میبینید نمودار خطی میانگین حاشیهای نمرات M برای هر کدام از گروههای فاکتور آمده است. گروه C با میانگین ۲۳.۶ کمترین نمره را داشته است. گروه C با بقیه گروهها اختلاف معنادار دارد و این مطلب در گراف بالا به وضوح دیده میشود. بیشترین نمره با عدد ۳۱.۷۴ به گروه A مربوط میشود که با گروه B اختلاف معنادار ندارد.
در شکل زیر نمودار میانگین حاشیهای نمرات N به ازای هر کدام از گروهها آمده است.

همانگونه که در این گراف دیده میشود، نمرات تقریباَ مشابه با یکدیگر است. ما در جدول Tests of Between-Subjects Effects نیز نشان دادیم که Group یک فاکتور اثرگزار بر ScoreN نیست.
خب، این هم از توضیحات روش آنالیز واریانس چندگانه یک طرفه که با استفاده از روش General Linear Model , Multivariate در نرم افزار SPSS به آن پرداختیم.
چگونه به این مقاله رفرنس دهیم
GraphPad Statistics (2020). One-way MANOVA with SPSS. Statistical tutorials and software guides. Retrieved Month, Day, Year, from https://graphpad.ir/general-linear-models-multivariate-one-way-manova-spss/.php
For example, if you viewed this guide on 12th January 2022, you would use the following reference
GraphPad Statistics (2020). One-way MANOVA with SPSS. Statistical tutorials and software guides. Retrieved January, 12, 2022, from https://graphpad.ir/general-linear-models-multivariate-one-way-manova-spss/.php
ارایه خدمات تحلیل و مشاوره آماری
گراف پد برای شما خدمات مشاوره و انجام انواع تحلیلهای آماری را ارایه میدهد. جهت دریافت نکات بیشتر بهتر است با ما تماس بگیرید.